TKEStack 文档
- 1: 简介
- 2: 部署
- 3: 快速入门
- 3.1: 快速入门
- 3.2: 入门示例
- 3.2.1: 创建nginx服务
- 3.2.2: 编写HelloWorld程序
- 3.2.3: 如何构建Docker镜像
- 4: 产品使用指南
- 4.1: 切换控制台
- 4.2: 平台管理控制台
- 4.2.1: 概览
- 4.2.2: 集群管理
- 4.2.3: 业务管理
- 4.2.4: 扩展组件
- 4.2.4.1: TApp 介绍
- 4.2.4.2: CronHPA 介绍
- 4.2.4.3: 监控组件
- 4.2.4.4: LogAgent 介绍
- 4.2.4.5: GPUManager 介绍
- 4.2.4.6: CSIOperator 介绍
- 4.2.5: 组织资源
- 4.2.6: 访问管理
- 4.2.7: 监控&告警
- 4.2.8: 运维中心
- 4.3: 业务管理控制台
- 4.3.1: 应用管理
- 4.3.1.1: 命名空间
- 4.3.1.2: 工作负载
- 4.3.1.2.1: Deployment
- 4.3.1.2.2: StatefulSet
- 4.3.1.2.3: DaomonSet
- 4.3.1.2.4: Job
- 4.3.1.2.5: CronJob
- 4.3.1.2.6: TApp
- 4.3.1.2.7: 工作负载的请求与限制
- 4.3.1.3: 服务
- 4.3.1.4: 配置管理
- 4.3.1.5: 存储
- 4.3.1.5.1: PV和PVC
- 4.3.1.5.2: StorageClass
- 4.3.1.6: 事件
- 4.3.1.7: 日志
- 4.3.2: 业务管理
- 4.3.3: 组织资源
- 4.3.4: 监控与告警
- 4.3.5: 运维中心
- 4.3.6:
- 5: 特色功能
- 5.1: TAPP
- 5.2: Galaxy
- 5.3: CronHPA
- 5.4: GPU-Manager说明
- 5.5: LBCF说明
- 6: 最佳实践
- 6.1: K8S 版本升级说明
- 6.2: 自定义k8s版本升级
- 6.3: wx 私有化部署最佳实践
- 6.4: 使用存储的实践
- 6.5: 基于 Jenkins 的 CI/CD
- 7: 开发指引
- 7.1: API 使用指引
- 8: FAQ
- 8.1: 部署类
- 8.2: 平台类
- 8.3: 授权类
- 8.3.1: 如何接入LDAP&OIDC
- 8.3.2: 业务管理、平台管理的区别
- 8.3.3: 如何设置自定义策略
- 8.3.4: Docker login 权限错误
- 8.4: 事件类
- 8.4.1: 常见错误事件
- 8.5:
- 8.6:
- 8.7:
- 8.8:
- 9: Release Notes
1 - 简介

![]()
![]()

TKEStack 是一个开源项目,为在生产环境中部署容器的组织提供一个统一的容器管理平台。 TKEStack 可以简化部署和使用 Kubernetes,满足 IT 要求,并增强 DevOps 团队的能力。
特点
- 统一集群管理
- 提供 Web 控制台和命令行客户端,用于集中管理多个 Kubernetes 集群
- 可与现有的身份验证机制集成,包括 LDAP,Active Directory,front proxy 和 public OAuth providers(例如GitHub)
- 统一授权管理,不仅在集群管理级别,甚至在Kubernetes资源级别
- 多租户支持,包括团队和用户对容器、构建和网络通信的隔离
- 应用程序工作负载管理
- 提供直观的UI界面,以支持可视化、YAML导入、其他资源创建和编辑方法,使用户无需预先学习所有Kubernetes概念即可运行容器
- 抽象的项目级资源容器,以支持跨多个集群的多个名称空间管理和部署应用程序
- 运维管理
- 集成的系统监控和应用程序监控
- 支持对接外部存储,以实现持久化Kubernetes事件和审计日志
- 限制,跟踪和管理平台上的开发人员和团队
- 插件支持和管理
- Authentication identity provider 插件
- Authorization provider 插件
- 事件持久化存储插件
- 系统和应用程序日志持久化存储插件
2 - 部署
2.1 - 产品部署架构
总体架构
TKEStack 产品架构如下图所示:
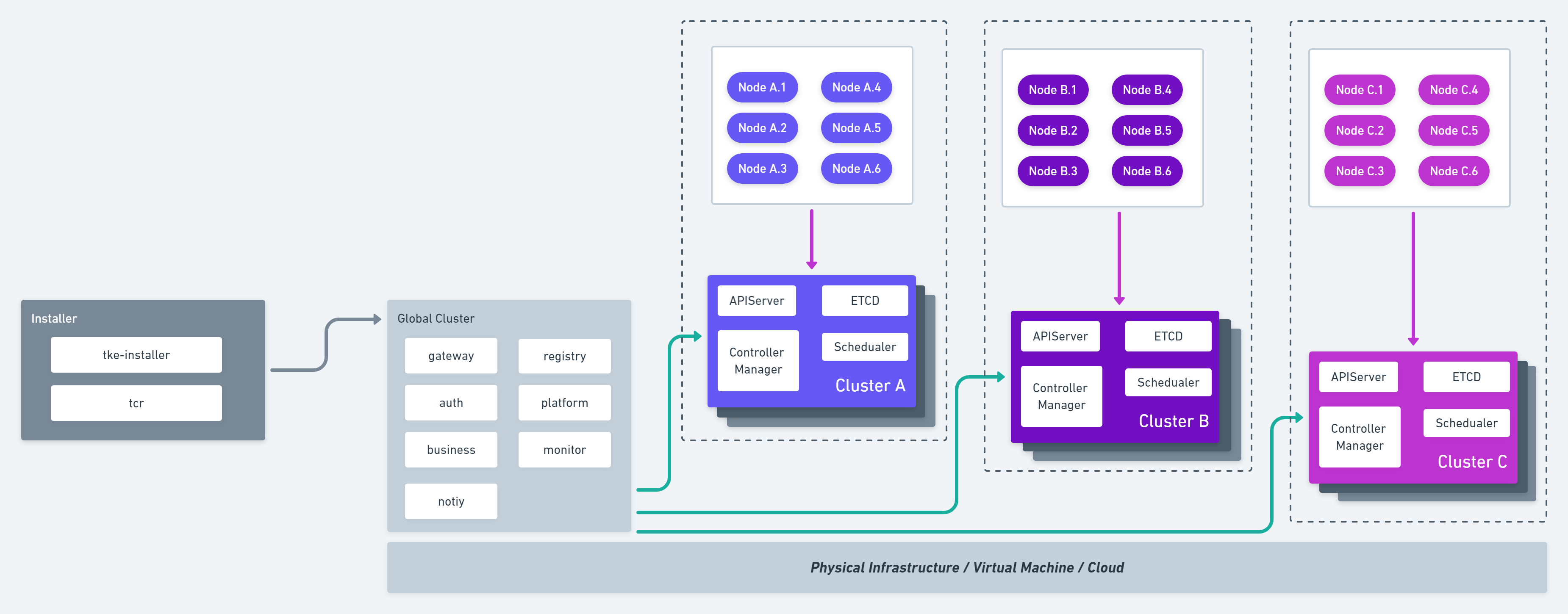
架构说明
TKEStack 采用了 Kubernetes on Kubernetes 的设计理念。即节点仅运行 Kubelet 进程,其他组件均采用容器化部署,由 Kubernetes 进行管理。
架构上分为 Global 集群和业务集群。Global 集群运行整个容器服务开源版平台自身所需要的组件,业务集群运行用户业务。在实际的部署过程中,可根据实际情况进行调整。
模块说明
- Installer: 运行 tke-installer 安装器的节点,用于提供 Web UI 指导用户在 Global 集群部署TKEStacl控制台;
- Global Cluster: 运行的 TKEStack 控制台的 Kubernetes 集群;
- Cluster: 运行业务的 Kubernetes 集群,可以通过 TKEStack 控制台创建或导入;
- Auth: 权限认证组件,提供用户鉴权、权限对接相关功能;
- Gateway: 网关组件,实现集群后台统一入口、统一鉴权相关的功能,并运行控制台的 Web 界面服务;
- Platform: 集群管理组件,提供 Global 集群管理多个业务集群相关功能;
- Business: 业务管理组件,提供平台业务管理相关功能的后台服务;
- Network Controller:网络服务组件,支撑 Galaxy 网络功能;
- Monitor: 监控服务组件,提供监控采集、上报、告警相关服务;
- Notify: 通知功能组件,提供消息通知相关的功能;
- Registry: 镜像服务组件,提供平台镜像仓库服务;
2.2 - 部署环境要求
硬件要求
特别注意:
安装的时候,至少需要一个 Installer 节点和一个作为 Global 集群的 master 节点共两个节点。 > > v1.3.0 之后的版本可直接使用 All-In-One 的安装模式,此时 Installer 节点也可以作为 Global 集群的节点。但注意:此时 Installer 的节点配置要以 Global 集群的节点配置为准,否则 Installer 节点配置太低很容易安装失败。另外该功能还不是很成熟,为避免安装失败,尽量将 Installer 节点和 Global 节点分开始用
Installer 节点:是单独的用作安装的节点,不能作为 Global 集群的节点使用。因为在安装 Global 集群时,需要多次重启 docker,此时如果 Global 集群里面有 Installer 节点,重启 docker 会中断 Global 集群的安装。该节点需要一台系统盘 100G 的机器,系统盘要保证剩余 50GB 可用的空间。 > > v1.3.0 之后 Installer 节点支持作为 Global 集群的节点使用,但注意此时 Installer 节点配置以 Global 集群的节点为准
Global 集群:至少需要一台 8核16G内存,100G系统盘的机器。
业务集群:业务集群是在部署完 Global 集群之后再添加的。
- 最小化部署硬件配置:
| 安装/业务集群 | 节点/集群 | CPU 核数 | 内存 | 系统盘 | 数量 |
|---|---|---|---|---|---|
| 安装 | Installer 节点 | 1 | 2G | 100G | 1 |
| TKEStack 控制台 | Global 集群 | 8 | 16G | 100G | 1 |
| 业务集群 | Master & ETCD | 4 | 8G | 100G | 1 |
| 业务集群 | Node | 8 | 16G | 100G | 3 |
- 推荐硬件配置:
| 安装/业务集群 | 节点/集群 | CPU 核数 | 内存 | 系统盘 | 数量 |
|---|---|---|---|---|---|
| 安装 | Installer 节点 | 1 | 2G | 100G | 1 |
| TKEStack 控制台 | Global 节点 | 8 | 16G | 100G SSD | 3 |
| 业务集群 | Master & ETCD | 16 | 32G | 300G SSD | 3 |
| 业务集群 | Node | 16 | 32G | 系统盘:100G 数据盘:300G (/var/lib/docker) | >3 |
注意:上表中的数据盘(/var/lib/docker)表示的是 docker 相关信息在主机中存储的位置,即容器数据盘,包括 docker 的镜像、容器、日志(如果容器的日志文件所在路径没有挂载 volume,日志文件会被写入容器可写层,落盘到容器数据盘里)等文件。建议给此路径挂盘,避免与系统盘混用,避免因容器、镜像、日志等 docker 相关信息导致磁盘压力过大。
软件要求
注意,以下要求针对集群中的所有节点
| 需求项 | 具体要求 | 命令参考 (以 CentOS 7.6为例) |
|---|---|---|
| 操作系统 | Ubuntu 16.04/18.04 LTS (64-bit) CentOS Linux 7.6 (64-bit) Tencent Linux 2.2 | cat /etc/redhat-release |
| kernel 版本 | >= Kernel 3.10.0-957.10.1.el7.x86_64 | uname -sr |
| ssh sudo yum CLI | 确保 Installer 节点及其容器、 Global 集群节点及其容器、 业务集群节点及其容器…之间能够 ssh 互联; 确保每个节点都有基础工具 | 1. 确保在添加所有节点时,IP 和密码输入正确。 2. 确保每个节点都有 sudo 或 root 权限 3. 如果是 CentOS,确保拥有 yum;其他操作系统类似,确保拥有包管理器 4. 确保拥有命令行工具 |
| Swap | 关闭。 如果不满足,系统会有一定几率出现 io 飙升,造成 docker 卡死。kubelet 会启动失败 (可以设置 kubelet 启动参数 –fail-swap-on 为 false 关闭 swap 检查) | sudo swapoff -asudo sed -i '/ swap / s/^\(.*\)$/#\1/g' /etc/fstab# 注意:如果 /etc/fstab有挂载 swap,必须要注释掉,不然重新开机时又会重新挂载 swap |
| 防火墙 | 关闭。 或者至少要放通22、80、8080、443、6443、2379、2380、10250-10255、31138 端口 | 可通过以下关闭防火墙systemctl stop firewalld && systemctl disable firewalld或者通过以下命令放通指定端口,例如只放通80端口 firewall-cmd --zone=public --add-port=80/tcp --permanent |
| SELinux | 关闭。 Kubernetes 官方要求,否则 kubelet 挂载目录时可能报错 Permission denied | setenforce 0sed -i "s/SELINUX=enforcing/SELINUX=disabled/g" /etc/selinux/config |
| 时区 | 所有服务器时区必须统一,建议设置为 Asia/Shanghai | timedatectl set-timezone Asia/Shanghai |
| 时间同步 | ETCD 集群各机器需要时间同步,可以利用 chrony 用于系统时间同步; 所有服务器要求时间必须同步,误差不得超过 2 秒 | yum install -y chronydsystemctl enable chronyd && systemctl start chronyd |
| 路由检查 | 有些设备可能会默认配置一些路由,这些路由可能与 TKEStack 冲突,建议删除这些路由并做相关配置 | ip link delete docker0ip link add name docker0 type bridgeip addr add dev docker0 172.17.0.1/16 |
| docker 检查 | 有些设备可能会默认安装 docker,该 docker 版本可能与 TKEStack 不一致, 建议在安装 TKEStack 之前删除docker | yum remove docker-ce containerd docker-ce-cli -y |
2.3 - 安装使用 GPU
安装使用步骤
安装使用步骤
限制条件
- 用户在安装使用GPU时,要求集群内必须包含GPU机型节点
- 该组件基于 Kubernetes DevicePlugin 实现,只能运行在支持 DevicePlugin 的 kubernetes版本(Kubernetes 1.10 之上的版本)
- GPU-Manager 将每张 GPU 卡视为一个有100个单位的资源:当前仅支持 0-1 的小数张卡,如 20、35、50;以及正整数张卡,如200、500等;不支持类似150、250的资源请求;显存资源是以 256MiB 为最小的一个单位的分配显存
TKEStack 支持的 GPU 类型
TKEStack目前支持两种GPU类型:
- vGPU:虚拟GPU类型(Virtual GPU),当选择安装此类型的GPU时,平台会自动安装组件GPUManager,对应在集群中部署的kubernetes资源对象如下:
| kubernetes 对象名称 | 类型 | 建议预留资源 | 所属 Namespaces |
|---|---|---|---|
| gpu-manager-daemonset | DaemonSet | 每节点1核 CPU, 1Gi内存 | kube-system |
| gpu-quota-admission | Deployment | 1核 CPU, 1Gi内存 | kube-system |
- pGPU: 物理GPU类型(Physical GPU),当选择安装此类型的GPU时,平台会自动安装组件Nvidia-k8s-device-plugin,对应的在集群中部署的kubernetes资源对象如下:
| kubernetes 对象名称 | 类型 | 建议预留资源 | 所属 Namespaces |
|---|---|---|---|
| nvidia-device-plugin-daemonset | DaemonSet | 每节点1核 CPU, 1Gi内存 | kube-system |
安装步骤
安装使用 vGPU
用户在新建独立集群时,勾选GPU选项,在下拉选项中选择 vGPU,如下图所示:

目标机器部分,勾选GPU选项,平台会自动为节点安装GPU驱动,如下图所示:

等待新建独立集群处于running状态后,可以通过登陆到集群节点通过kubectl查看在集群kube-system命名空间中部署了gpu-manager和gpu-quota-admission两个pod:
# kubectl get pods -n kube-system | grep gpu
gpu-manager-daemonset-2vvbm 1/1 Running 0 2m13s
gpu-quota-admission-76cfff49b6-vdh42 1/1 Running 0 3m2s
创建使用 vGPU 的工作负载
TKEStack创建使用GPU的工作负载支持两种方式:第一种是通过TKEStack前端页面创建,第二种是通过后台命令行的方式创建。
1、 通过前端控制台创建
在安装了 GPU-Manager 的集群中,创建工作负载时可以设置GPU限制,如下图所示:
注意:
- 卡数只能填写 0.1 到 1 之间的两位小数或者是所有自然数,例如:0、0.3、0.56、0.7、0.9、1、6、34,不支持 1.5、2.7、3.54
- 显存只能填写自然数 n,负载使用的显存为 n*256MiB

2、 通过后台命令行创建
使用 YAML 创建使用 GPU 的工作负载,需要在 YAML 文件中为容器设置 GPU 的使用资源。
- CPU 资源需要在 resource 上填写
tencent.com/vcuda-core - 显存资源需要在 resource 上填写
tencent.com/vcuda-memory
如下所示:创建一个使用 0.3 张卡、5GiB 显存的nginx应用(5GiB = 20*256MB)
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
resources:
limits:
tencent.com/vcuda-core: 30
tencent.com/vcuda-memory: 20
requests:
tencent.com/vcuda-core: 30
tencent.com/vcuda-memory: 20
# kubectl create -f nginx.yaml
pod/nginx created
注意:
- 如果pod在创建过程中出现CrashLoopBackOff 的状态,且error log如下所示:
failed to create containerd task: OCI runtime create failed: container_linux.go:380: starting container process caused: process_linux.go:545: container init caused: Running hook #0:: error running hook: exit status 1, stdout: , stderr: nvidia-container-cli: mount error: open failed: /sys/fs/cgroup/devices/system.slice/containerd.service/kubepods-besteffort-podfd3b355a_665c_4c95_8e7f_61fd2111689f.slice/devices.allow: no such file or directory: unknown需要在GPU主机上手动安装libnvidia-container-tools这个组件,首先需要添加repo源:添加repo源, 添加repo源后执行如下命令:
# yum install libnvidia-container-tools
- 如果pod在创建过程中出现如下error log:
failed to generate spec: lstat /dev/nvidia-uvm: no such file or directory需要在pod所在的主机上手动mount这个设备文件:
# nvidia-modprobe -u -c=0
查看创建的应用状态:
# kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx 1/1 Running 0 3s
查看GPU监控数据(需要提前安装socat):
# yum install socat
# kubectl port-forward svc/gpu-manager-metric -n kube-system 5678:5678
# curl http://127.0.0.1:5678/metric
结果如下
Handling connection for 5678
# HELP container_gpu_memory_total gpu memory usage in MiB
# TYPE container_gpu_memory_total gauge
container_gpu_memory_total{container_name="nginx",gpu_memory="gpu0",namespace="default",node="10.0.0.127",pod_name="nginx"} 0
container_gpu_memory_total{container_name="nginx",gpu_memory="total",namespace="default",node="10.0.0.127",pod_name="nginx"} 0
# HELP container_gpu_utilization gpu utilization
# TYPE container_gpu_utilization gauge
container_gpu_utilization{container_name="nginx",gpu="gpu0",namespace="default",node="10.0.0.127",pod_name="nginx"} 0
container_gpu_utilization{container_name="nginx",gpu="total",namespace="default",node="10.0.0.127",pod_name="nginx"} 0
# HELP container_request_gpu_memory request of gpu memory in MiB
# TYPE container_request_gpu_memory gauge
container_request_gpu_memory{container_name="nginx",namespace="default",node="10.0.0.127",pod_name="nginx",req_of_gpu_memory="total"} 5120
# HELP container_request_gpu_utilization request of gpu utilization
# TYPE container_request_gpu_utilization gauge
container_request_gpu_utilization{container_name="nginx",namespace="default",node="10.0.0.127",pod_name="nginx",req_of_gpu="total"} 0.30000001192092896
安装使用 pGPU
用户在新建独立集群时,勾选GPU选项,在下拉选项中选择pGPU,如下图所示:

目标机器部分,勾选GPU选项,平台会自动为节点安装GPU驱动,如下图所示:
等待新建独立集群处于running状态后,可以通过登陆到集群节点通过kubectl查看到,在集群kube-system命名空间中部署了nvidia-device-pluginpod:
# kubectl get pods -n kube-system | grep nvidia
nvidia-device-plugin-daemonset-frdh2 1/1 Running 0 64s
通过查看节点信息可以看到GPU资源和使用情况:
# kubectl describe nodes <nodeIP>
显示信息如下:
Capacity:
cpu: 8
ephemeral-storage: 154685884Ki
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 32779608Ki
nvidia.com/gpu: 1
pods: 256
Allocatable:
cpu: 7800m
ephemeral-storage: 142558510459
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 31653208Ki
nvidia.com/gpu: 1
pods: 256
创建使用vGPU的工作负载
通过控制台创建方式参考vGPU的创建步骤
通过命令行创建
通过如下YAML创建使用1个GPU的工作负载:
apiVersion: v1
kind: Pod
metadata:
name: gpu-operator-test
spec:
restartPolicy: OnFailure
containers:
- name: cuda-vector-add
image: "tkestack/cuda-vector-add:v0.1"
resources:
limits:
nvidia.com/gpu: 1
# kubectl create -f pod.yaml
pod/gpu-operator-test created
查看pod的状态和log:
# kubectl get pods
NAME READY STATUS RESTARTS AGE
gpu-operator-test 0/1 Completed 0 4m51s
# kubectl logs gpu-operator-test
[Vector addition of 50000 elements]
Copy input data from the host memory to the CUDA device
CUDA kernel launch with 196 blocks of 256 threads
Copy output data from the CUDA device to the host memory
Test PASSED
Done
通过再次查看节点信息可以看到GPU已经被分配使用:
kubectl describe nodes <nodeIP>
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 1137m (14%) 282m (3%)
memory 644Mi (2%) 1000Mi (3%)
ephemeral-storage 0 (0%) 0 (0%)
hugepages-1Gi 0 (0%) 0 (0%)
hugepages-2Mi 0 (0%) 0 (0%)
nvidia.com/gpu 1 1
添加节点使用GPU
在添加节点上使用GPU资源,需要在创建添加节点时勾选GPU选项,如下图所示:

2.5 - 安装步骤
安装步骤
安装步骤
1. 需求检查
仔细检查每个节点的硬件和软件需求:installation requirements
2. Installer安装
为了简化平台安装过程,容器服务开源版基于 tke-installer 安装器提供了一个向导式的图形化安装指引界面。
在您 Installer 节点的终端,执行如下脚本:
# amd64
arch=amd64 version=v1.3.1 && wget https://tke-release-1251707795.cos.ap-guangzhou.myqcloud.com/tke-installer-linux-$arch-$version.run{,.sha256} && sha256sum --check --status tke-installer-linux-$arch-$version.run.sha256 && chmod +x tke-installer-linux-$arch-$version.run && ./tke-installer-linux-$arch-$version.run
# arm64
arch=arm64 version=v1.3.1 && wget https://tke-release-1251707795.cos.ap-guangzhou.myqcloud.com/tke-installer-linux-$arch-$version.run{,.sha256} && sha256sum --check --status tke-installer-linux-$arch-$version.run.sha256 && chmod +x tke-installer-linux-$arch-$version.run && ./tke-installer-linux-$arch-$version.run
您可以查看 TKEStack Release 按需选择版本进行安装,建议您安装最新版本。
tke-installer 约为 7GB,包含安装所需的所有资源。
以上脚本执行完之后,终端会提示访问 http://[tke-installer-IP]:8080/index.html,使用本地主机的浏览器访问该地址,按照指引开始安装控制台,可参考下面的控制台安装。
注意:这里
tke-installer-IP地址默认为内网地址,如果本地主机不在集群内网,tke-installer-IP为内网地址所对应的外网地址。
3. 控制台安装
注意:控制台是运行在global集群之上,控制台安装就是在安装global集群。
- 填写 TKEStack 控制台基本配置信息
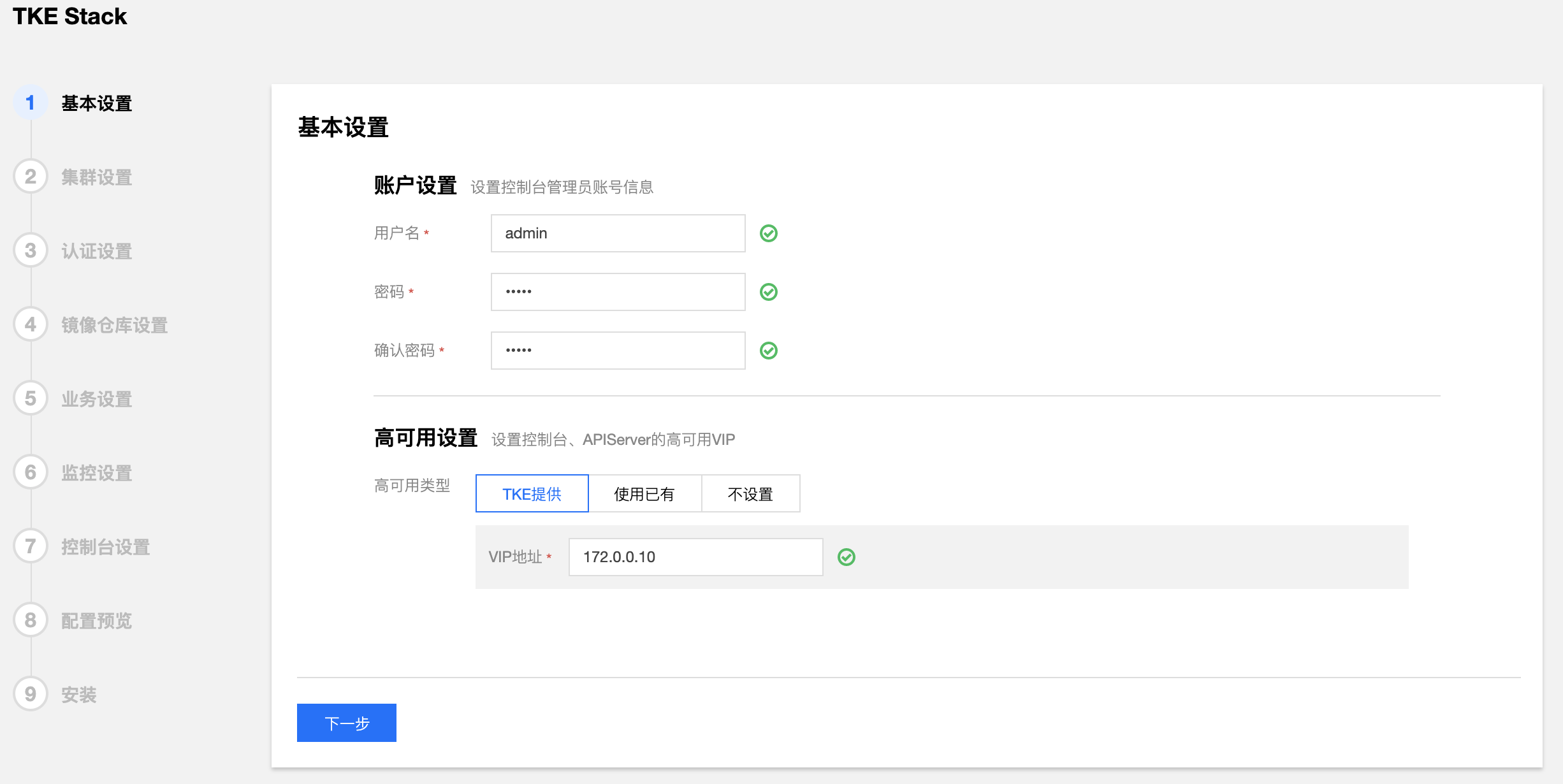
- 用户名:TKEStack 控制台管理员名称(例如:admin)
- 密码:TKEStack 控制台管理员密码
- 高可用设置(按需使用,可直接选择【不设置】)
- TKE提供:在所有 master 节点额外安装 Keepalived 完成 VIP 的配置与连接
- 使用已有:对接配置好的外部 LB 实例
- 不设置:访问第一台 master 节点 APIServer
- 填写 TKEStack 控制台集群设置信息
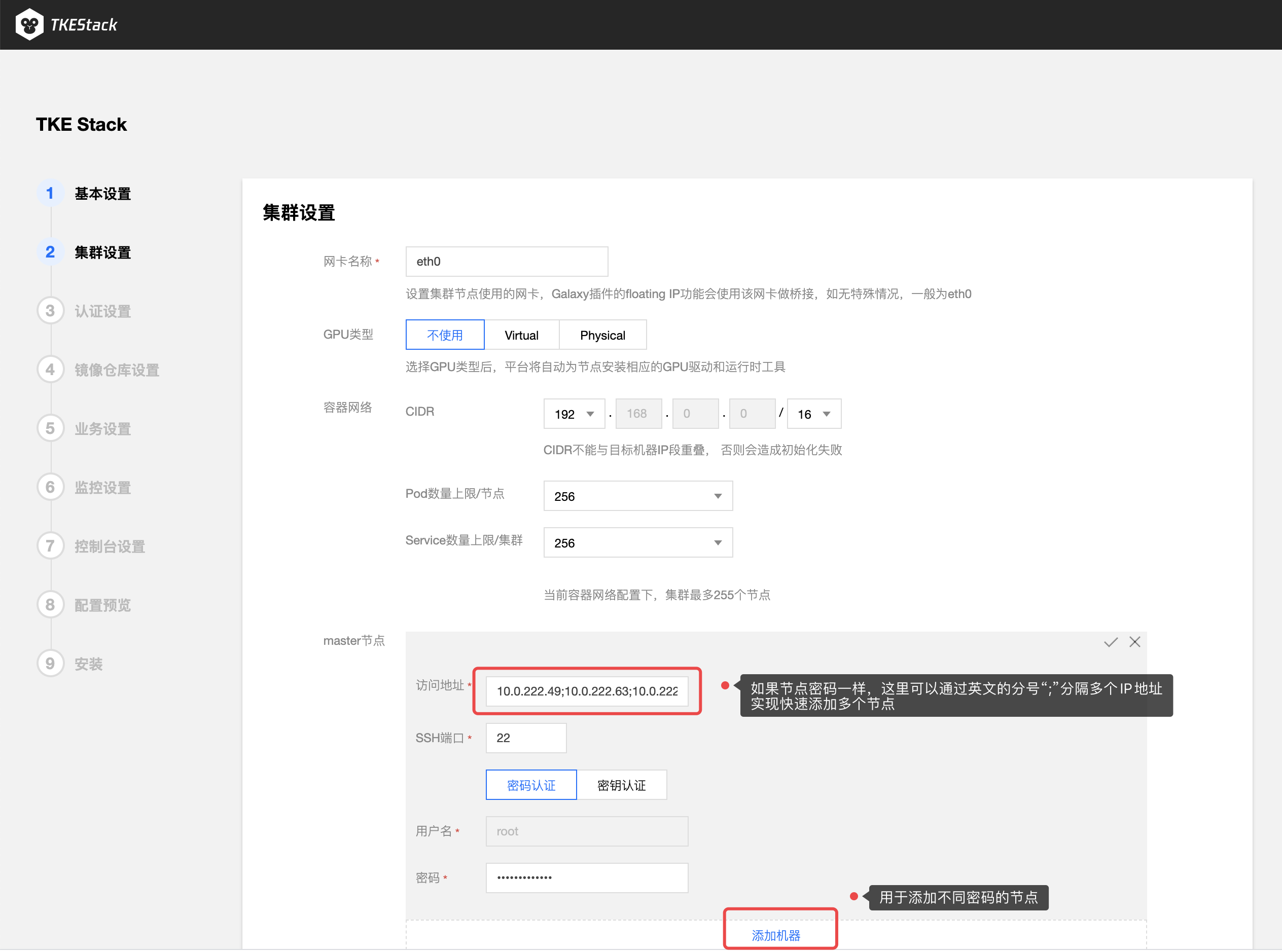
- 网卡名称:集群节点使用的网卡,根据实际环境填写正确的网卡名称,默认为eth0(建议使用默认值)
- GPU 类型:(按需使用,可直接选择【不设置】)
- 不使用:不安装 Nvidia GPU 相关驱动
- Virtual:平台会自动为集群安装 GPUManager 扩展组件
- Physical:平台会自动为集群安装 Nvidia-k8s-device-plugin
- 容器网络: 将为集群内容器分配在容器网络地址范围内的 IP 地址,您可以自定义三大私有网段作为容器网络, 根据您选择的集群内服务数量的上限,自动分配适当大小的 CIDR 段用于 Kubernetes service;根据您选择 Pod 数量上限/节点,自动为集群内每台服务器分配一个适当大小的网段用于该主机分配 Pod 的 IP 地址(建议使用默认值)
- CIDR: 集群内 Sevice、 Pod 等资源所在网段
- Pod数量上限/节点: 决定分配给每个 Node 的 CIDR 的大小
- Service数量上限/集群:决定分配给 Sevice 的 CIDR 大小
- master 节点: 输入目标机器信息后单击保存,若保存按钮是灰色,单击网页空白处即可变蓝
- 访问地址: Master 节点内网 IP,请配置至少 8 Cores & 16G内存 及以上的机型,否则会部署失败
- SSH 端口:请确保目标机器安全组开放 SSH 端口和 ICMP 协议,否则无法远程登录和 PING 服务器(建议使用22)
- 用户名和密码: 均为添加的节点的用户名和密码
- 可以通过节点下面的【添加机器】蓝色字体增加master节点(按需添加)
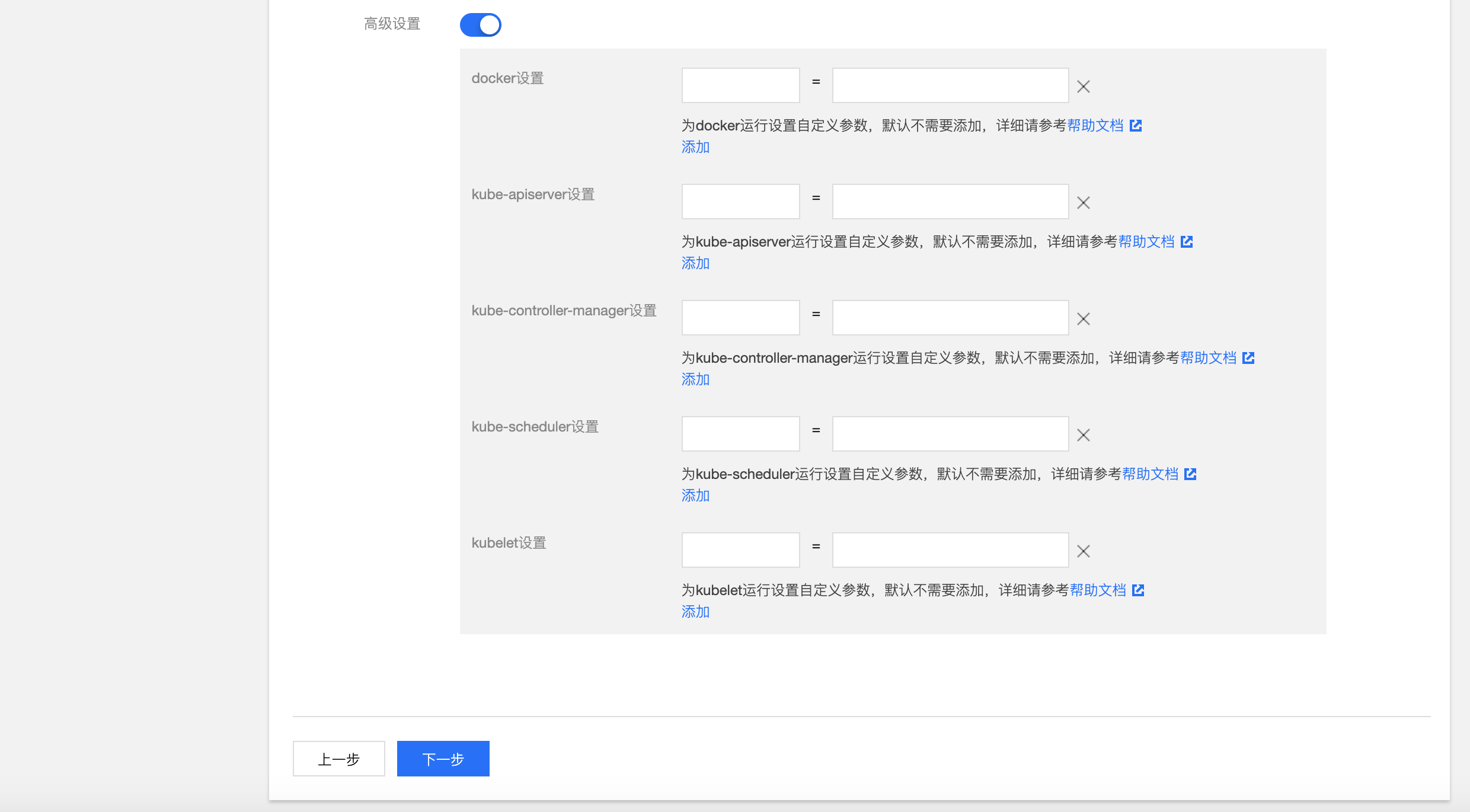
- 高级设置(非必须):可以自定义 Global 集群的 Docker、kube-apiserver、kube-controller-manager、kube-scheduler、kubelet 运行参数
- 填写 TKEStack 控制台认证信息。(建议使用TKE提供)
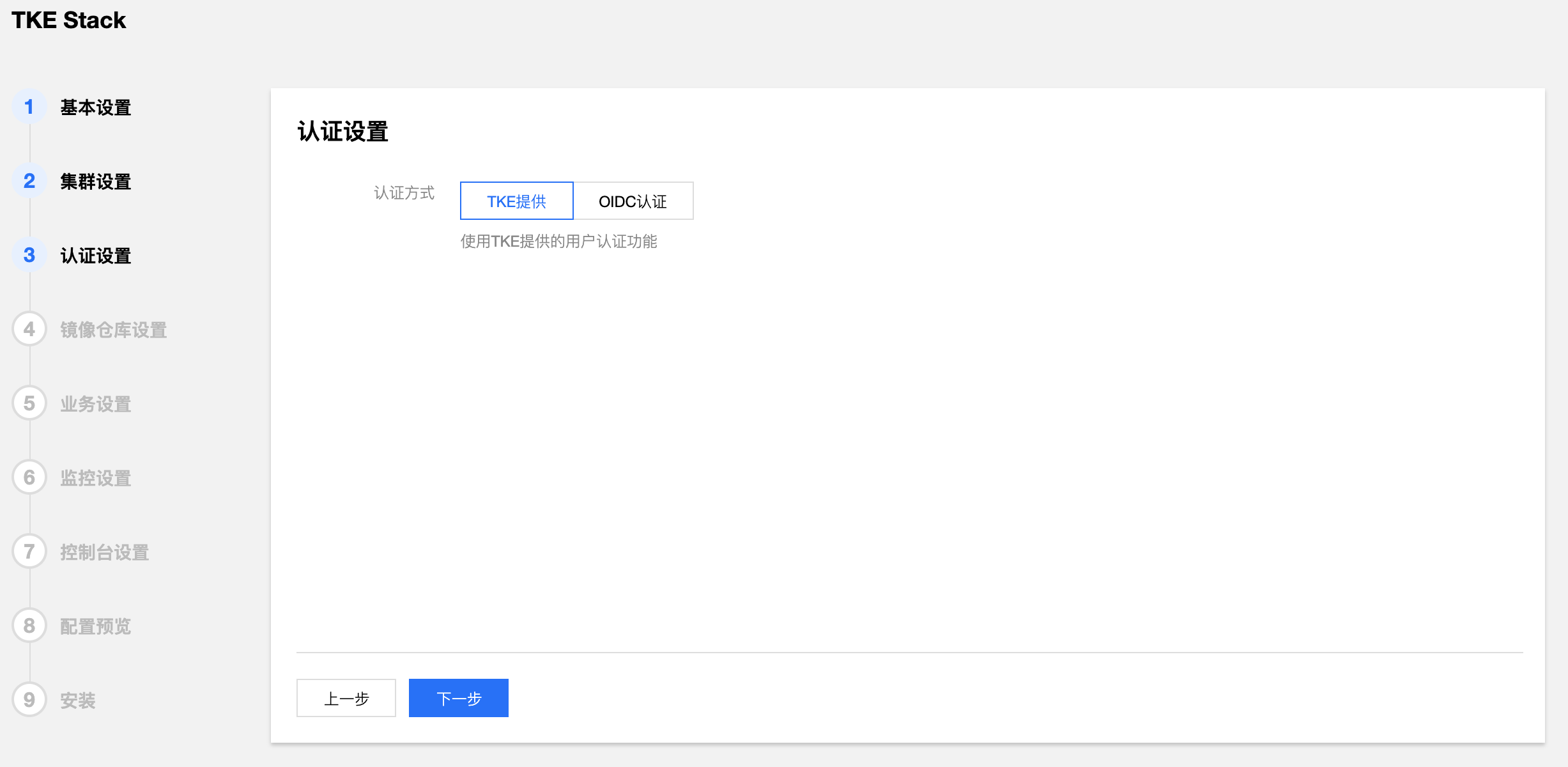
- 认证方式:
- TKE提供:使用 TKE 自带的认证方式
- OIDC:使用 OIDC 认证方式,详见 OIDC
- 填写 TKEStack 控制台镜像仓库信息。(建议使用TKE提供)
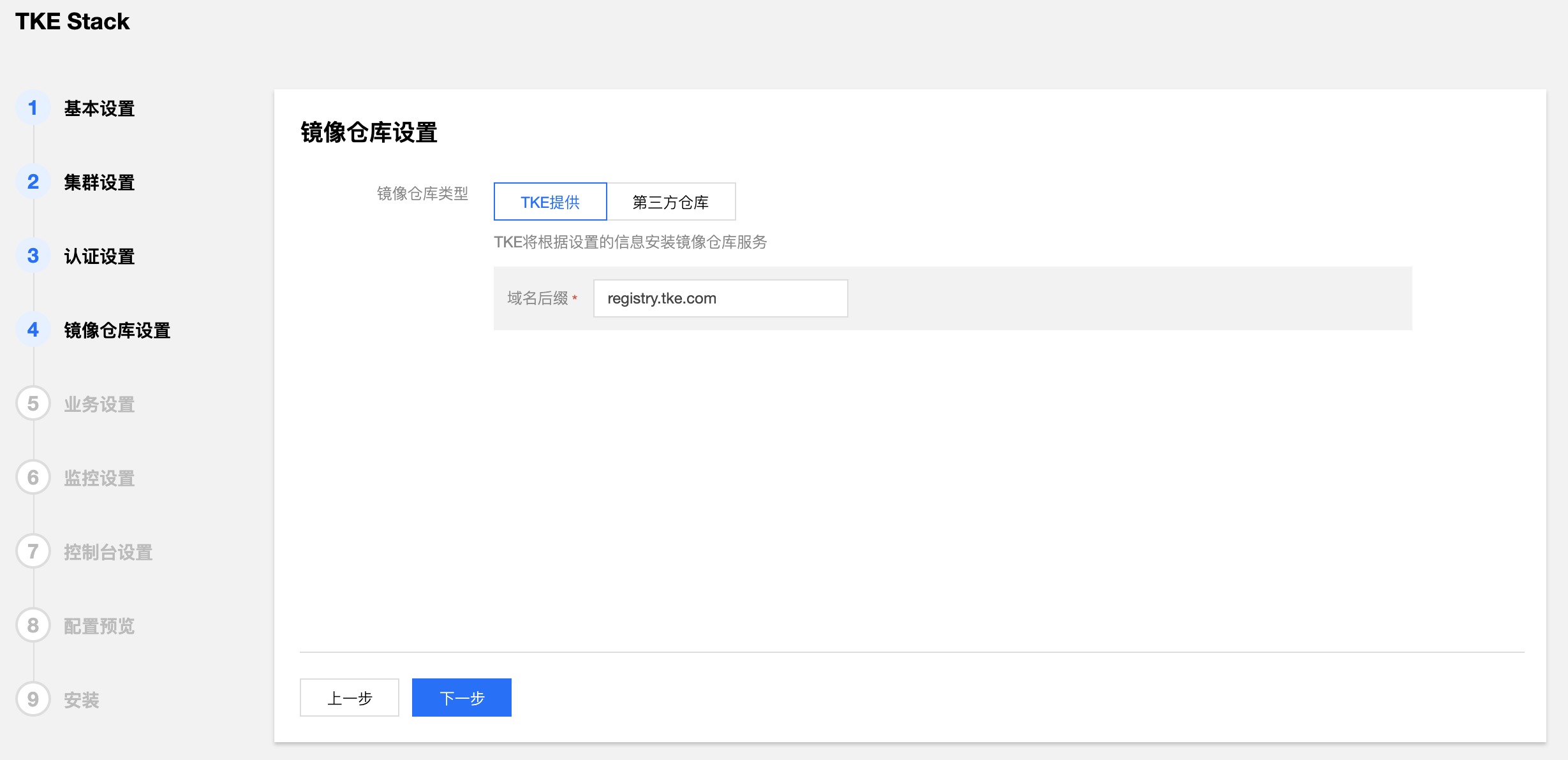
- 镜像仓库类型:
- TKE提供:使用 TKE 自带的镜像仓库
- 第三方仓库:对接配置好的外部镜像仓库,此时,TKEStack 将不会再安装镜像仓库,而是使用您提供的镜像仓库作为默认镜像仓库服务
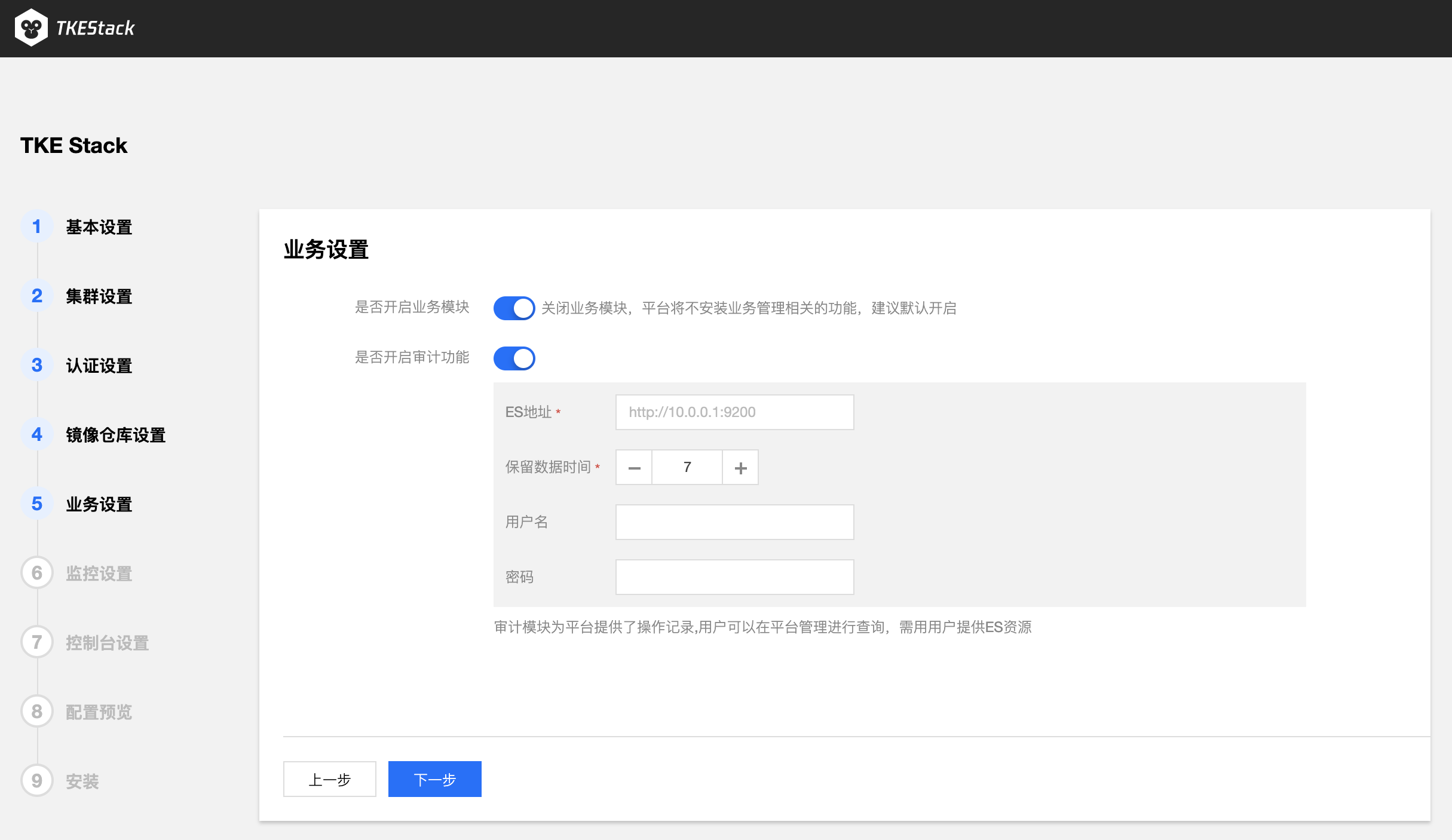
- 业务设置
- 确认是否开启 TKEStack 控制台业务模块。(建议开启)
- 确实是否开启平台审计功能,审计模块为平台提供了操作记录,用户可以在平台管理进行查询,需用用户提供ES资源。(按需使用,可不开启)
- 选择 TKEStack 控制台监控存储类型。(建议使用TKE提供)
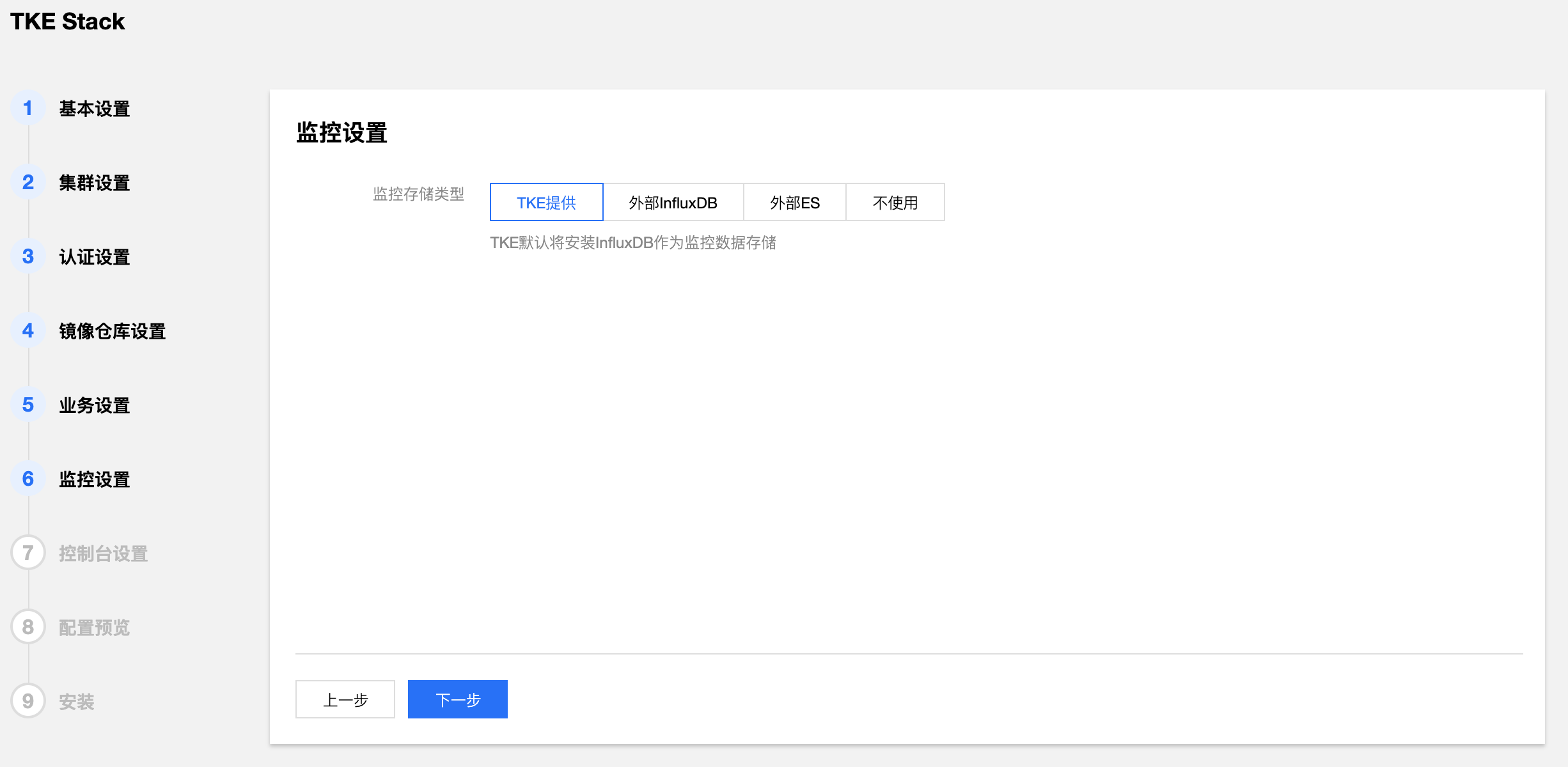
- 监控存储类型:
- TKE提供:使用 TKE 自带的 Influxdb 作为存储
- 外部 Influxdb:对接外部的 Influxdb 作为存储
- 外部 ES:对接外部的 Elasticsearch作为存储
- 不使用:不使用监控
- 确认是否开启 TKEStack 控制台,选择开启则需要填写控制台域名及证书。(建议使用默认值)
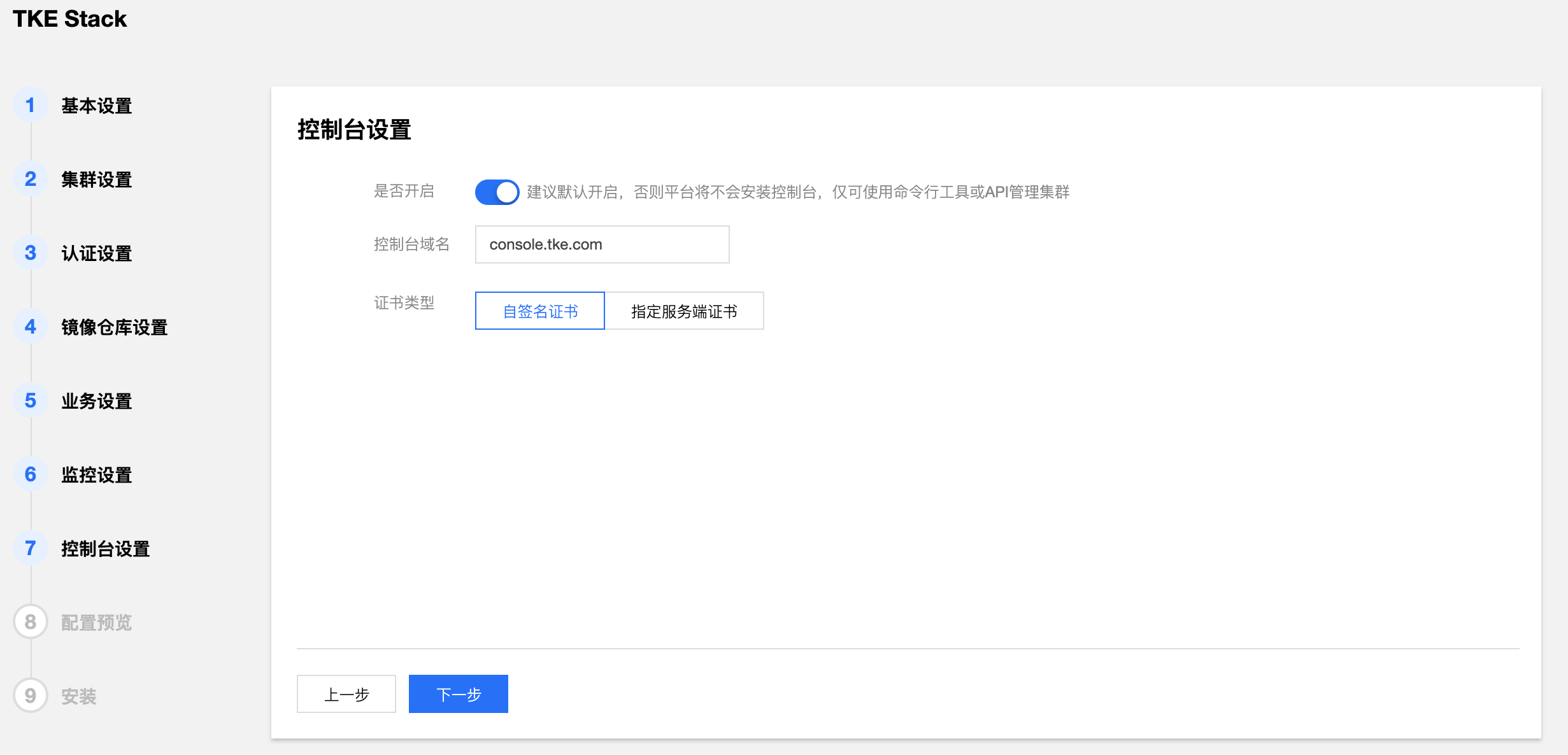
- 监控存储类型:
- 自签名证书:使用 TKE 带有的自签名证书
- 指定服务器证书:填写已备案域名的服务器证书
- 确认 TKEStack 控制台所有配置是否正确。
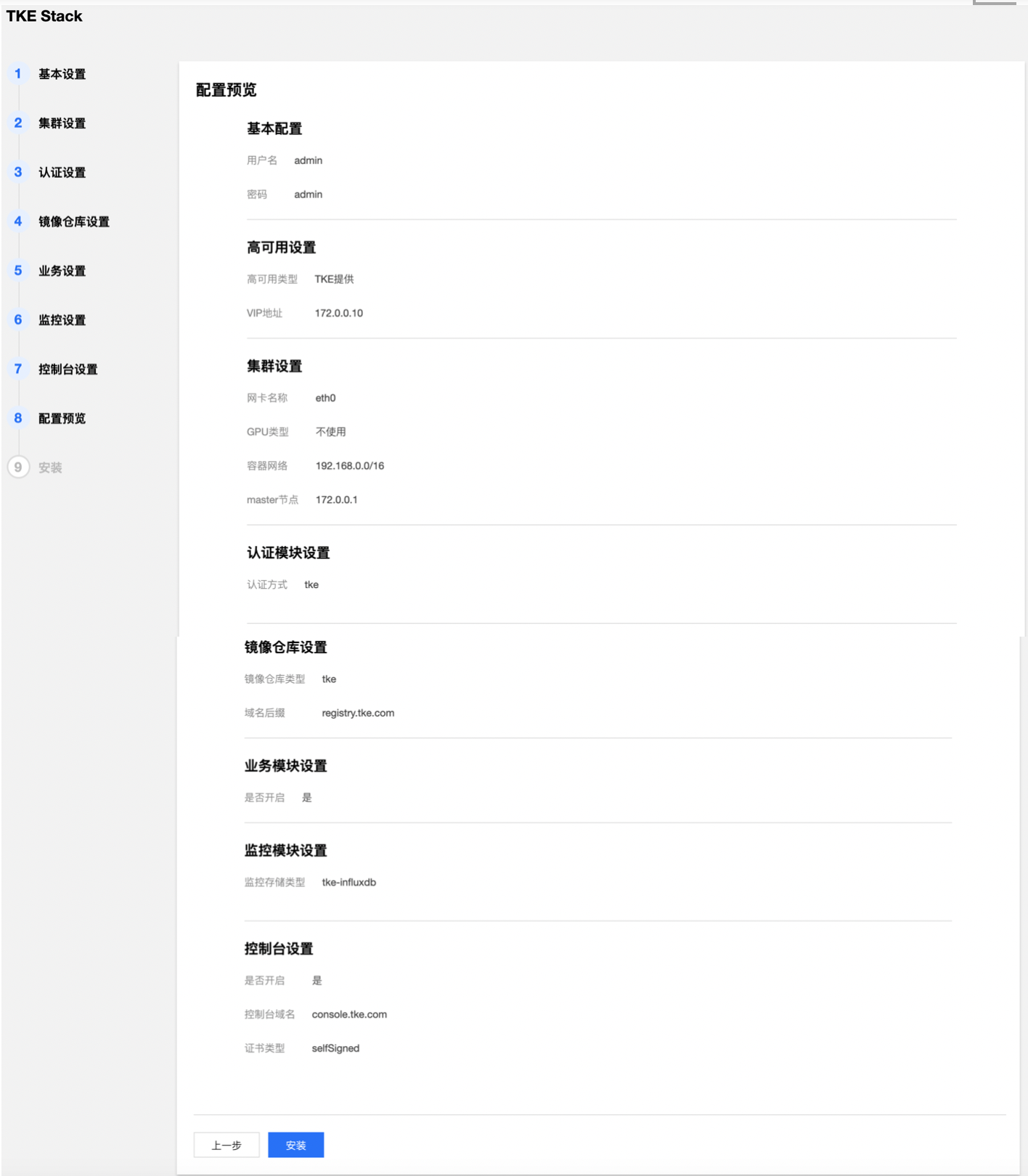
- 开始安装 TKEStack 控制台,安装成功后界面如下,最下面出现【查看指引】的按钮。
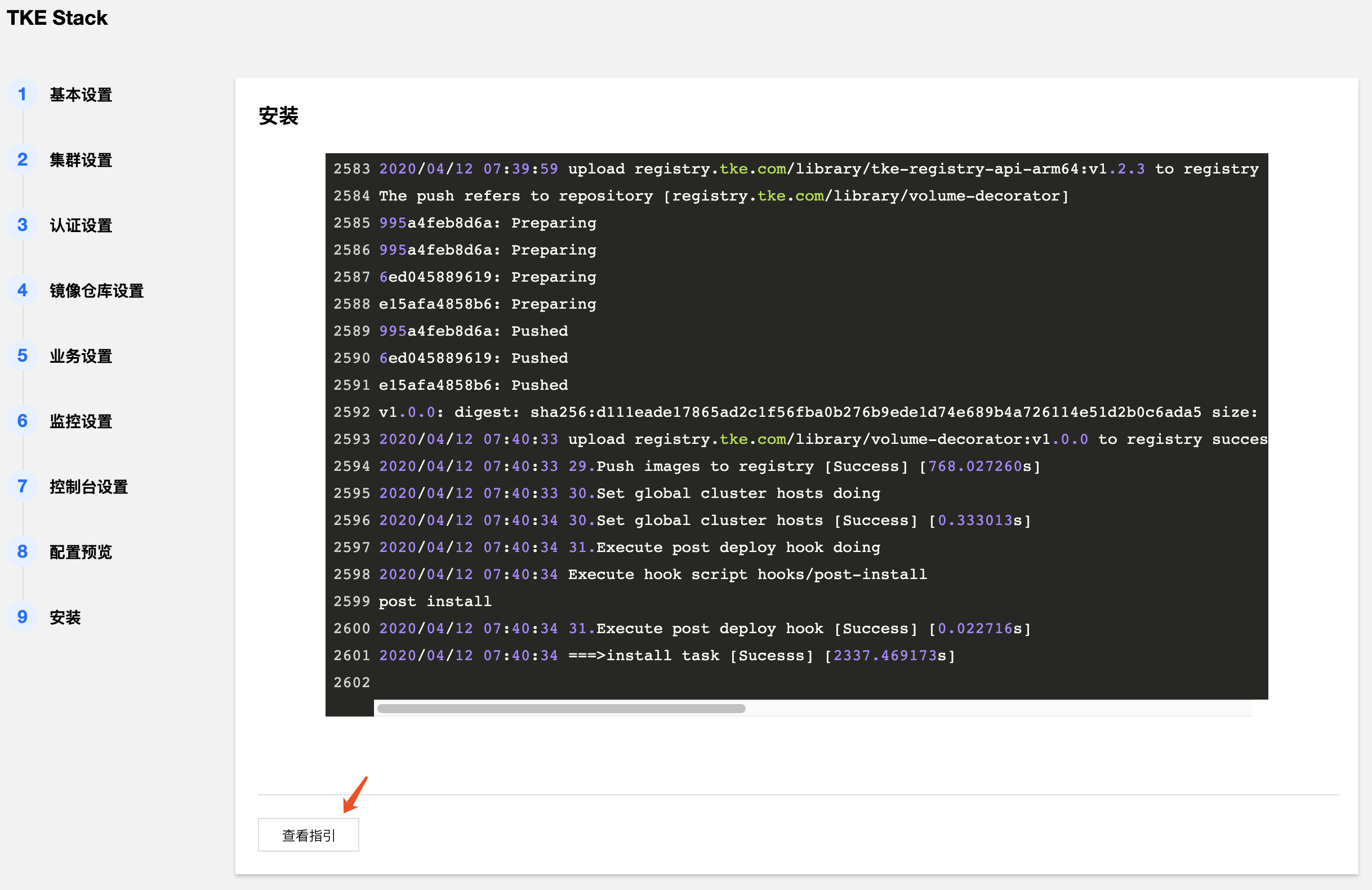
- 点击【查看指引】,按照指引,在本地主机上添加域名解析,以访问 TKEStack 控制台。
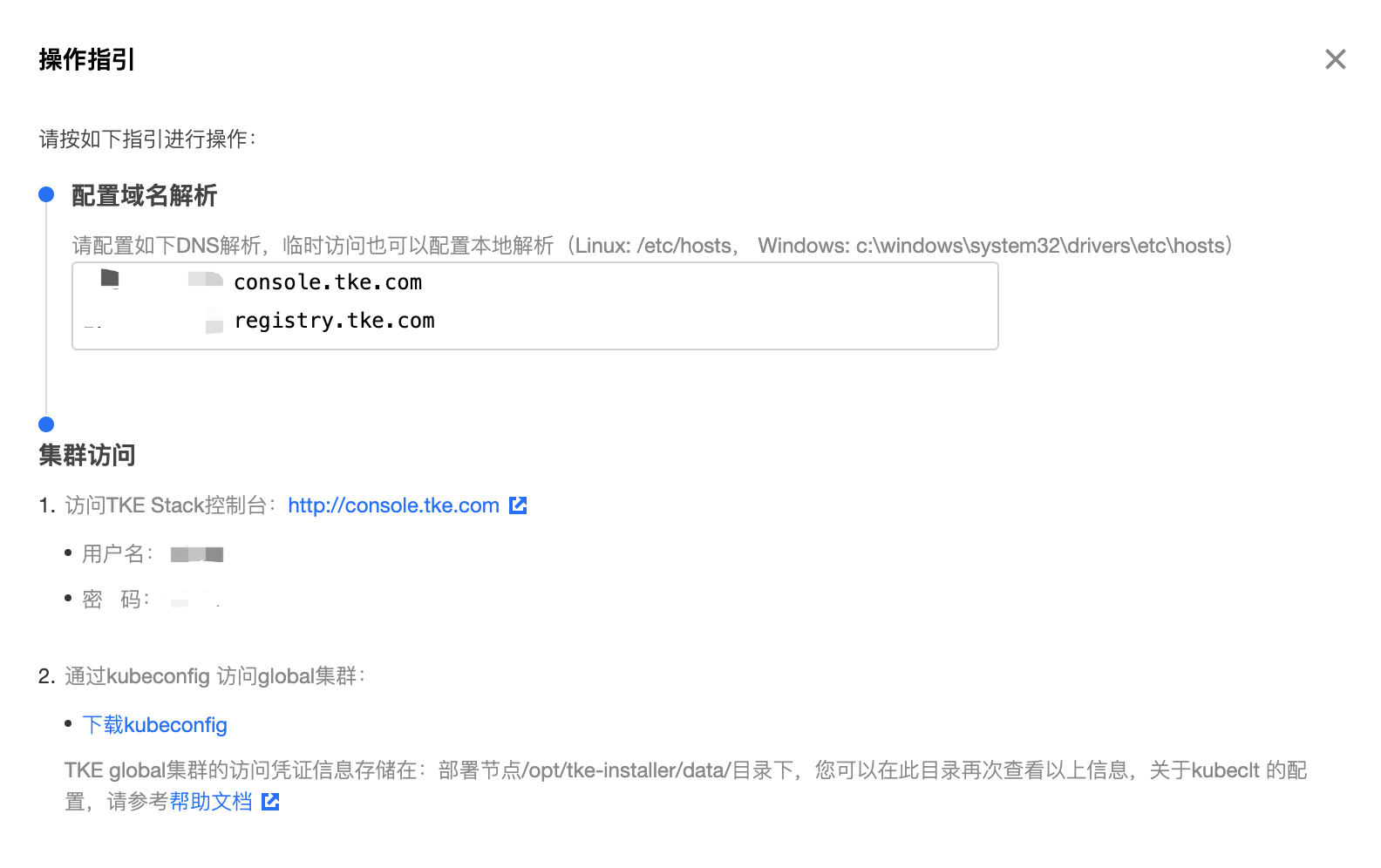
以Linux/MacOS为例: 在
/etc/hosts文件中加入以下两行域名解析- 【IP】 console.tke.com
- 【IP】 registry.tke.com
注意:这里域名的【IP】地址默认为内网地址,如果本地主机不在集群内网,域名的IP地址应该填该内网地址所对应的外网地址。
4. 访问控制台
在本地主机的浏览器地址输入http://console.tke.com,可访问Global集群的控制台界面,输入控制台安装创建的用户名和密码后即可使用TKEStack。
安装常见问题
安装失败请首先检查硬件和软件需求:installation requirements
可参考FAQ installation获得更多帮助。
2.6 -
readme
Because we can not find resources online with static folder,so use this folder to store image.
If we fix this issue in the future, then we use static folder rather than this folder.
3 - 快速入门
3.1 - 快速入门
教程介绍
TKEStack 是一款面向私有化环境的开源容器编排引擎。在本教程中,您将了解如何创建 TKEStack 控制台,并使用控制台创建和管理容器集群,在集群内快速、弹性地部署您的服务。
操作步骤
平台安装
集群
平台安装之后,可在【平台管理】控制台的【集群管理】中看到 global 集群。如下图所示:

TKEStack 还可以另外新建独立集群以及导入已有集群实现多集群的管理。
注意:新建独立集群和导入已有集群都属于TKEStack 架构中的业务集群。
新建独立集群
- 登录 TKEStack,右上角会出现当前登录的用户名,示例为 admin。
- 切换至【平台管理】控制台。
- 在“集群管理”页面中,单击【新建独立集群】。如下图所示:

- 在“新建独立集群”页面,填写集群的基本信息。新建的集群需满足installation requirements的需求,在满足需求之后,TKEStack 的集群添加非常便利。如下图所示,只需填写【集群名称】、【目标机器】、【密码】,其他保持默认即可添加新的集群。
注意:若【保存】按钮是灰色,单击附近空白处即可变蓝

集群名称**:** 支持**中文**,小于 60 字符即可
Kubernetes 版本**:** 选择合适的 kubernetes 版本,各版本特性对比请查看 Supported Versions of the Kubernetes Documentation。(**建议使用默认值**)
网卡名称: 最长 63 个字符,只能包含小写字母、数字及分隔符(' - ‘),且必须以小写字母开头,数字或小写字母结尾。(建议使用默认值 eth0)
VIP :高可用 VIP 地址。(按需使用)
GPU:选择是否安装 GPU 相关依赖。(按需使用)
pGPU:平台会自动为集群安装 GPUManager 扩展组件
vGPU:平台会自动为集群安装 Nvidia-k8s-device-plugin
容器网络 :将为集群内容器分配在容器网络地址范围内的 IP 地址,您可以自定义三大私有网段作为容器网络, 根据您选择的集群内服务数量的上限,自动分配适当大小的 CIDR 段用于 kubernetes service;根据您选择 Pod 数量上限/节点,自动为集群内每台云服务器分配一个适当大小的网段用于该主机分配 Pod 的 IP 地址。(建议使用默认值)
CIDR: 集群内 Sevice、 Pod 等资源所在网段。
Pod 数量上限/节点: 决定分配给每个 Node 的 CIDR 的大小。
Service 数量上限/集群 :决定分配给 Sevice 的 CIDR 大小。
目标机器 :
目标机器:节点的内网地址。(建议: Master&Etcd 节点配置4 核及以上的机型)
SSH 端口: 请确保目标机器安全组开放 22 端口和 ICMP 协议,否则无法远程登录和 PING 云服务器。(建议使用默认值 22)
主机 label:给主机设置 Label,可用于指定容器调度。(按需使用)
认证方式:连接目标机器的方式
- 密码认证:
- 密码:目标机器密码
- 密钥认证:
- 私钥:目标机器秘钥
- 私钥密码:目标机器私钥密码,可选填
- 密码认证:
GPU: 使用 GPU 机器需提前安装驱动和 runtime。(按需使用)
输入以上信息后单击【保存】后还可继续添加集群的节点
提交: 集群信息填写完毕后,【提交】按钮变为可提交状态,单击即可提交。
导入已有集群
- 登录 TKEStack。
- 切换至【平台管理】控制台。
- 在“集群管理”页面,单击【导入集群】。如下图所示:

- 在“导入集群”页面,填写被导入的集群信息。如下图所示:

- 名称: 被导入集群的名称,最长 60 字符
- API Server:
- 被导入集群的 API server 的域名或 IP 地址,注意域名不能加上 https://
- 端口,此处用的是 https 协议,端口应填 443。
- CertFile: 输入被导入集群的 cert 文件内容
- Token: 输入被导入集群创建时的 token 值
- 单击最下方 【提交】 按钮 。
创建业务
注:业务可以实现跨集群资源的使用
- 登录 TKEStack。
- 在【平台管理】控制台的【业务管理】中,单击 【新建业务】。如下图所示:

- 在“新建业务”页面,填写业务信息。如下图所示:
- 业务名称:不能超过 63 个字符,这里以
my-business为例 - 业务成员: 【访问管理】中【用户管理】中的用户,这里以
admin例,即这该用户可以访问这个业务。 - 集群:
- 【集群管理】中的集群,这里以
gobal集群为例 - 【填写资源限制】可以设置当前业务使用该集群的资源上限(可不限制)
- 【新增集群】可以添加多个集群,此业务可以使用多个集群的资源(按需添加)
- 上级业务:支持多级业务管理,按需选择(可不选)
8 .单击最下方 【完成】 按钮即可创建业务。
创建业务下的命名空间
- 登录 TKEStack。
- 在【平台管理】控制台的【业务管理】中,单击【业务 id】。如下图所示:

- 单击【Namespace 列表】。如下图标签 1 所示:
该页面可以更改业务名称、成员、以及业务下集群资源的限制。

- 单击【新建 Namespace】。如下图所示:

- 在“新建 Namespace”页面中,填写相关信息。如下图所示:

- 名称:不能超过 63 个字符,这里以
new-ns为例 - 集群:
my-business业务中的集群,这里以global集群为例 - 资源限制:这里可以限制当前命名空间下各种资源的使用量,可以不设置。
创建业务下的 Deployment
- 登录 TKEStack,点击【平台管理】选项旁边的切换按钮,可以切换到【业务管理】控制台。
注意:因为当前登录的是 admin 用户,【业务管理】控制台只包含在创建业务中成员包含 admin 的业务,如果切换到【业务管理】控制台没有看见任何业务,请确认【平台管理】中【业务管理】中的相关业务的成员有没有当前用户,如没有,请添加当前用户。
- 点击左侧导航栏中的【应用管理】,如果当前用户被分配了多个业务,可通过下图中标签 3 的选择框选择合适的业务。
- 点击【工作负载】,点击下图标签 4 的【Deployment】,此时进入“Deployment”页面,可通过下图中的标签 5 选择 Deployment 的【命名空间】:

- 单击上图标签 6【新建】,进入“新建 Workload ”页面。根据实际需求,设置 Deployment 参数。这里参数很多,其中必填信息已用红框标识:

- 工作负载名:输入自定义名称,这里以
my-dep为例 - 描述:给工作负载添加描述,可不填
- 标签:给工作负载添加标签,通过工作负载名默认生成
- 命名空间:根据实际需求进行选择
- 类型:选择【Deployment(可扩展的部署 Pod)】
- 数据卷(选填):为容器提供存储,目前支持临时路径、主机路径、云硬盘数据卷、文件存储 NFS、配置文件、PVC,还需挂载到容器的指定路径中。如需指定容器挂载至指定路径时,单击【添加数据卷】
- 实例内容器:根据实际需求,为 Deployment 的一个 Pod 设置一个或多个不同的容器。如下图所示:
- 名称:自定义,这里以
my-container为例 - 镜像:根据实际需求进行选择,这里以
nginx为例- 镜像版本(Tag):根据实际需求进行填写,不填默认为
latest - CPU/内存限制:可根据 Kubernetes 资源限制 进行设置 CPU 和内存的限制范围,提高业务的健壮性(建议使用默认值)
- GPU 限制:如容器内需要使用 GPU,此处填 GPU 需求
- 环境变量:用于设置容器内的变量,变量名只能包含大小写字母、数字及下划线,并且不能以数字开头
- 新增变量:自己设定变量键值对
- 引用 ConfigMap/Secret:引用已有键值对
- 高级设置:可设置 “工作目录”、“运行命令”、“运行参数”、“镜像更新策略”、“容器健康检查”和“特权级”等参数。这里介绍一下镜像更新策略。
镜像更新策略:提供以下 3 种策略,请按需选择
若不设置镜像拉取策略,当镜像版本为空或
latest时,使用 Always 策略,否则使用 IfNotPresent 策略- Always:总是从远程拉取该镜像
- IfNotPresent:默认使用本地镜像,若本地无该镜像则远程拉取该镜像
- Never:只使用本地镜像,若本地没有该镜像将报异常
- 镜像版本(Tag):根据实际需求进行填写,不填默认为
- 名称:自定义,这里以


- 实例数量:根据实际需求选择调节方式,设置实例数量。
- 手动调节:直接设定实例个数
- 自动调节:根据设定的触发条件自动调节实例个数,目前支持根据 CPU、内存利用率和利用量出入带宽等调节实例个数
- 显示高级设置

imagePullSecrets:镜像拉取密钥,用于拉取用户的私有镜像,使用私有镜像首先需要新建 Secret
节点调度策略:根据配置的调度规则,将 Pod 调度到预期的节点。
- 不使用调度策略:k8s 自动调度
- 自定义调度规则:通过节点的 Label 来实现
- 强制满足条件:调度期间如果满足亲和性条件则调度到对应 node,如果没有节点满足条件则调度失败。
- 尽量满足条件:调度期间如果满足亲和性条件则调度到对应 node,如果没有节点满足条件则随机调度到任意节点。
注释(Annotations):给 deployment 添加相应 Annotation,如用户信息等
网络模式:选择 Pod 网络模式
- OverLay(虚拟网络):基于 IPIP 和 Host Gateway 的 Overlay 网络方案
- FloatingIP(浮动 IP):支持容器、物理机和虚拟机在同一个扁平面中直接通过 IP 进行通信的 Underlay 网络方案。提供了 IP 漂移能力,支持 Pod 重启或迁移时 IP 不变
- NAT(端口映射):Kubernetes 原生 NAT 网络方案
- Host(主机网络):Kubernetes 原生 Host 网络方案
创建 Service(可选):
Service:勾选【启用】按钮,配置负载端口访问
注意:如果不勾选【启用】则不会创建 Service
服务访问方式:选择是【仅在集群内部访问】该负载还是集群外部通过【主机端口访问】该负载
- 仅在集群内访问:使用 Service 的 ClusterIP 模式,自动分配 Service 网段中的 IP,用于集群内访问。数据库类等服务如 MySQL 可以选择集群内访问,以保证服务网络隔离
- 主机端口访问:提供一个主机端口映射到容器的访问方式,支持 TCP、UDP、Ingress。可用于业务定制上层 LB 转发到 Node
- Headless Service:不创建用于集群内访问的 ClusterIP,访问 Service 名称时返回后端 Pods IP 地址,用于适配自有的服务发现机制。解析域名时返回相应 Pod IP 而不是 Cluster IP
端口映射:输入负载要暴露的端口并指定通信协议类型(容器和服务端口建议都使用 80)
Session Affinity: 点击【显示高级设置】出现,会话保持,设置会话保持后,会根据请求 IP 把请求转发给这个 IP 之前访问过的 Pod。默认 None,按需使用
单击【创建 Workload】,完成创建。
当“运行/期望 Pod 数量”相等时,即表示 Deployment 下的所有 Pod 已创建完成。
- 如果在第 5 步中有创建 Service,则可以再【服务】下的【Service】看到与刚刚创建的 Deployment 同名的 Service
删除资源
在本节中,启动了my-business业务下的 Deployment 和 Service 两种资源,此步骤介绍如何清除所有资源。
删除 Deployment
- 登录 TKEStack,切换到【业务管理】控制台,选择左侧导航栏中的【应用管理】。
- 展开【工作负载】下拉项,进入 “Deployment” 管理页面,选择需要删除【Deployment】的业务下相应的【命名空间】,点击要删除的 Deployment 最右边的【更多】,点击【删除】。如下图所示:
- 在弹出框中单击【确定】,即可删除 Deployment。
删除 Service
- 登录 TKEStack,切换到【业务管理】控制台,选择左侧导航栏中的【应用管理】。
- 展开【服务】下拉项,进入 “Service” 管理页面,选择需要删除【Service】的业务下相应的【命名空间】,点击要删除的 Service 最右边的【删除】。如下图所示:
- 在弹出框中单击【确定】,即可删除 Service。
3.2 - 入门示例
3.2.1 - 创建nginx服务
本文档旨在帮助大家了解如何快速创建一个容器集群内的 nginx 服务。
前提条件
- 已部署 TKEStack 控制台。
- 已创建集群。如没有另外创建集群,可以先使用global集群。如要尝试创建新集群,请参见 创建集群。
操作步骤
创建 Nginx 服务
- 登录TKEStack 控制台 。

- 单击左侧导航栏中【集群管理】,进入“集群管理”页面,单击需要创建服务的集群 ID。

- 进入【工作负载】的【 Deployment 】中,选择【新建】。如下图所示:

- 在“新建Workload”页面,只需输入下图中红框的参数即可。



注意:服务所在集群的安全组需要放通节点网络及容器网络,同时需要放通30000 - 32768端口,否则可能会出现容器服务无法使用问题。
- 单击上图中的【创建Workload】,完成创建。如下图所示:
注意:当运行/期望Pod数量一致时,负载完成创建。

- 如果在第5步中有创建Service,则可以在【服务】下的【Service】看到与刚刚创建的Deployment同名的Service

访问 Nginx 服务
可通过以下两种方式访问 nginx 服务。
通过主机节点端口访问 nginx 服务
在本地主机的浏览器地址栏输入集群任意节点IP:30000 端口,例如10.0.0.1:30000即可访问服务。如果服务创建成功,访问服务时直接进入 nginx 服务器的默认欢迎页。如下图所示:
注意:如果本地主机在集群内网中,输入节点的内网IP地址即可;如果本地主机不在集群内网中,需要输入节点的外网IP地址

通过服务名称访问 nginx 服务
集群内的其他服务或容器可以直接通过服务名称访问。
3.2.2 - 编写HelloWorld程序
操作场景
本文档旨在帮助大家了解如何快速创建一个容器集群内的 Hello World 的 Node.js 版的服务。
前提条件
- 已部署 TKEStack 控制台。
- 已创建集群。如没有另外创建集群,可以先使用global集群。如要尝试创建新集群,请参见 创建集群。
操作步骤
编写代码制作镜像
编写应用程序
以CentOS 7.6为例
安装node.js,然后依次执行以下命令,创建并进入 hellonode 的文件夹。
yum install -y nodejs mkdir hellonode cd hellonode/执行以下命令,新建并打开 server.js 文件。
vim server.js按 “i” 或 “insert” 切换至编辑模式,将以下内容输入 server.js。
var http = require('http'); var handleRequest = function(request, response) { console.log('Received request for URL: ' + request.url); response.writeHead(200); response.end('Hello World!'); }; var www = http.createServer(handleRequest); www.listen(80);按 “Esc”,输入 “:wq”,保存文件并返回。
执行以下命令,执行 server.js 文件。
node server.js测试 Hello World 程序,有以下两种办法。 1. 另起一个终端,再次登录节点,执行以下命令。
curl 127.0.0.1:80 # 终端会输出一下信息 Hello World!打开本地主机的浏览器,以
IP地址:端口的形式访问,端口为80。 网页出现Hello world!说明 Hello World 程序运行成功。注意:如果本地主机不在该节点所在的内网,IP地址应该是该节点的外网地址
创建 Docker 镜像
在 hellonode 文件夹下,创建 Dockerfile 文件。
[root@VM_1_98_centos hellonode]# vim Dockerfile按 “i” 或 “insert” 切换至编辑模式,将以下内容输入 Dockerfile 文件。
FROM node:4.4 EXPOSE 80 COPY server.js . CMD node server.js按 “Esc”,输入 “:wq”,保存文件并返回。
执行以下命令,构建镜像。
docker build -t hello-node:v1 .执行以下命令,查看构建好的 hello-node 镜像。
docker images显示结果如下,则说明 hello-node 镜像已成功构建,记录其 IMAGE ID。如下图所示:

上传该镜像到镜像仓库
依次执行以下命令,上传镜像到 qcloud 仓库。
sudo docker login -u tkestack -p 【访问凭证】 default.registry.tke.com
sudo docker tag 【IMAGEID】 default.registry.tke.com/【命名空间】/helloworld:v1
sudo docker push default.registry.tke.com/【命名空间】/helloworld:v1
- 请将命令中的 【访问凭证】 替换为 已创建的访问凭证。
- 请将命令中的 【IMAGEID】 替换为 你自己创建镜像的ID,示例中的ID如上图158204134510。
- 请将命令中的 【命名空间】 替换为 已创建的命名空间。
显示以下结果,则说明镜像上传成功。

在镜像仓库命名空间中进行确认

通过该镜像创建 Hello World 服务
登录 TKEStack 控制台。
单击左侧导航栏中【集群管理】,进入“集群管理”页面。
单击需要创建服务的集群 ID,进入工作负载 “Deployment” 详情页,选择【新建】。如下图所示:

在“新建Workload”页面,仅输入以下红框内容即可:



注意:
- 镜像,地址要填全:default.registry.tke.com/【命名空间】/【镜像名】,例如:default.registry.tke.com/test/helloworld
- 服务所在集群的安全组需要放通节点网络及容器网络,同时需要放通30000 - 32768端口,否则可能会出现容器服务无法使用问题。
单击【创建Workload】,完成 Hello World 服务的创建。
访问 Hello World 服务
可通过以下两种方式访问 Hello World 服务。
通过主机节点端口访问 Hello World 服务
选择【服务】>【Service】,在“Service”管理页面,看到与名为helloworld的Deployment同名的 helloworld Service已经运行,如下图所示:

在本地主机的浏览器地址栏输入
集群任意节点IP:30000 端口,例如10.0.0.1:30000即可访问服务。如果服务创建成功,访问服务时页面会返回Hello World!注意:如果本地主机在集群内网中,输入节点的内网IP地址即可;如果本地主机不在集群内网中,需要输入节点的外网IP地址
通过服务名称访问 Hello World 服务
集群内的其他服务或容器可以直接通过服务名称访问。
更多关于Docker 镜像请参见 如何构建 Docker 镜像 。
3.2.3 - 如何构建Docker镜像
说明
DockerHub 提供了大量的镜像可用,详情可查看 DockerHub 官网。
Docker 容器的设计宗旨是让用户在相对独立的环境中运行独立的程序。
Docker 容器程序在镜像内程序运行结束后会自动退出。如果要令构建的镜像在服务中持续运行,需要在创建服务页面指定自身持续执行的程序,如:业务主程序,main 函数入口等。
由于企业环境的多样性,并非所有应用都能在 DockerHub 找到对应的镜像来使用。 您可以通过以下教程了解到如何将应用打包成Docker镜像。
Docker 生成镜像目前有两种方式:
- 通过 Dockerfile 自动构建镜像;
- 通过容器操作,并执行 Commit 打包生成镜像。
Dockerfile 自动编译生成(推荐使用)
以 Dockerhub 官方提供的 WordPress 为例,转到 github 查看详情 >>
其 Dockfile 源码如下:
FROM php:5.6-apache
# install the PHP extensions we need
RUN apt-get update && apt-get install -y libpng12-dev libjpeg-dev && rm -rf /var/lib/apt/lists/* \
&& docker-php-ext-configure gd --with-png-dir=/usr --with-jpeg-dir=/usr \
&& docker-php-ext-install gd mysqli opcache
# set recommended PHP.ini settings
# see https://secure.php.net/manual/en/opcache.installation.php
RUN { \
echo 'opcache.memory_consumption=128'; \
echo 'opcache.interned_strings_buffer=8'; \
echo 'opcache.max_accelerated_files=4000'; \
echo 'opcache.revalidate_freq=2'; \
echo 'opcache.fast_shutdown=1'; \
echo 'opcache.enable_cli=1'; \
} > /usr/local/etc/php/conf.d/opcache-recommended.ini
RUN a2enmod rewrite expires
VOLUME /var/www/html
ENV WORDPRESS_VERSION 4.6.1
ENV WORDPRESS_SHA1 027e065d30a64720624a7404a1820e6c6fff1202
RUN set -x \
&& curl -o wordpress.tar.gz -fSL "https://wordpress.org/wordpress-${WORDPRESS_VERSION}.tar.gz" \
&& echo "$WORDPRESS_SHA1 *wordpress.tar.gz" | sha1sum -c - \
# upstream tarballs include ./wordpress/ so this gives us /usr/src/wordpress
&& tar -xzf wordpress.tar.gz -C /usr/src/ \
&& rm wordpress.tar.gz \
&& chown -R www-data:www-data /usr/src/wordpress
COPY docker-entrypoint.sh /usr/local/bin/
RUN ln -s usr/local/bin/docker-entrypoint.sh /entrypoint.sh # backwards compat
# ENTRYPOINT resets CMD
ENTRYPOINT ["docker-entrypoint.sh"]
CMD ["apache2-foreground"]
通过上述 Dockerfile 文件可以了解到,内置执行了许多的 Linux 命令来安装和部署软件。
操作步骤
在终端创建一个名为worldpress的文件夹,在该文件夹下创建 Dockerfile 文件,文件内容即以上代码。通过 docker build ./命令来构建镜像。
[root@VM_1_98_centos ~]# mkdir worldpress
[root@VM_1_98_centos ~]# ls
worldpress
[root@VM_1_98_centos ~]# cd worldpress/
[root@VM_1_98_centos worldpress]# vi Dockerfile
[root@VM_1_98_centos worldpress]# ls
Dockerfile
[root@VM_1_98_centos worldpress]# docker build ./
Sending build context to Docker daemon 3.072kB
Step 1/12 : FROM php:5.6-apache
5.6-apache: Pulling from library/php
5e6ec7f28fb7: Pull complete
cf165947b5b7: Pull complete
7bd37682846d: Pull complete
······
通过 docker images 命令即可查看到构建完成的镜像。
[root@VM_88_88_centos worldpress]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
worldpress latest 9f0b470b5ddb 12 minutes ago 420 MB
docker.io/php 5.6-apache eb8333e24502 5 days ago 389.7 MB
使用 Dockerfile 来构建镜像有以下建议: 1. 尽量精简,不安装多余的软件包。 2. 尽量选择 Docker 官方提供镜像作为基础版本,减少镜像体积。 3. Dockerfile 开头几行的指令应当固定下来,不建议频繁更改,有效利用缓存。 4. 多条 RUN 命令使用''连接,有利于理解且方便维护。 5. 通过 -t 标记构建镜像,有利于管理新创建的镜像。 6. 不在 Dockerfile 中映射公有端口。 7. Push 前先在本地运行,确保构建的镜像无误。
执行 Commit 实现打包生成镜像
通过 Dockerfile 可以快速构建镜像,而通过 commit 生成镜像可以解决应用在部署过程中有大量交互内容以及难以通过 Dockerfile 构建的问题。
通过 commit 构建镜像操作如下: 1. 运行基础镜像容器,并进入console。
[root@VM_88_88_centos ~]# docker run -i -t centos
[root@f5f1beda4075 /]#
安装需要的软件,并添加配置。
[root@f5f1beda4075 /]# yum update && yum install openssh-server Loaded plugins: fastestmirror, ovl base | 3.6 kB 00:00:00 extras | 3.4 kB 00:00:00 updates | 3.4 kB 00:00:00 (1/4): base/7/x86_64/group_gz | 155 kB 00:00:00 (2/4): extras/7/x86_64/primary_db | 166 kB 00:00:00 (3/4): base/7/x86_64/primary_db | 5.3 MB 00:00:00 (4/4): updates/7/x86_64/primary_db ...... ...... ...... Dependency Installed: fipscheck.x86_64 0:1.4.1-5.el7 fipscheck-lib.x86_64 0:1.4.1-5.el7 openssh.x86_64 0:6.6.1p1-25.el7_2 tcp_wrappers-libs.x86_64 0:7.6-77.el7 Complete!配置完成后打开新终端保存该镜像。
shell [root@VM_88_88_centos ~]# docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES f5f1beda4075 centos "/bin/bash" 8 minutes ago Up 8 minutes hungry_kare [root@VM_88_88_centos ~]# docker commit f5f1beda4075 test:v1.0 sha256:65325ffd2af9d574afca917a8ce81cf8a710e6d1067ee611a87087e1aa88e4a4 [root@VM_88_88_centos ~]# [root@VM_88_88_centos ~]# docker images REPOSITORY TAG IMAGE ID CREATED SIZE test v1.0 65325ffd2af9 11 seconds ago 307.8 MB
4 - 产品使用指南
4.1 - 切换控制台
概念
这里用户可以自由切换控制面和业务面。
注意:只有当【平台管理】控制台中创建的业务的成员包含当前登录的用户,当前用户才会出现并可以切换至【业务管理】控制台,如下图所示。

操作步骤
- 登录 TKEStack,默认显示【平台管理】控制台,鼠标移动到【平台管理】旁,会出现切换提示,如下图:

- 如果当前显示的是【业务管理】控制台,鼠标移动到【业务管理】旁,会出现切换提示,如下图:

- 点击【 切换图标】 即可实现【平台管理】和【业务管理】控制台切换。
4.2 - 平台管理控制台
4.2.1 - 概览
平台概览页面,可查看TKEStack控制台管理资源的概览。
如下图所示,在【平台管理】页面点击【概览】,此处可以展现:
- 平台的资源概览
- 集群的资源状态
- 快速入口
- 实用提示

4.2.2 - 集群管理
概念
在这里可以管理你的 Kubernetes 集群

平台安装之后,可在【平台管理】控制台的【集群管理】中看到 global 集群,如下图所示: 
TKEStack还可以另外新建独立集群以及导入已有集群实现多集群的管理
注意:新建独立集群和导入已有集群都属于TKEStack架构中的业务集群。
新建独立集群
登录 TKEStack,右上角会出现当前登录的用户名,示例为admin
切换至【平台管理】控制台
在“集群管理”页面中,单击【新建独立集群】,如下图所示:

在“新建独立集群”页面,填写集群的基本信息。新建的集群节点需满足部署环境要求,在满足需求之后,TKEStack的集群添加非常便利。如下图所示,只需填写【集群名称】、【目标机器】、【SSH端口】(默认22)、【密码】,其他保持默认即可添加新的集群。
注意:若【保存】按钮是灰色,单击页面空白处即可变蓝

集群名称: 支持中文,小于60字符即可
Kubernetes版本: 选择合适的kubernetes版本,各版本特性对比请查看 Supported Versions of the Kubernetes Documentation(建议使用默认值)
网卡名称: 可以通过 ifconfig 查看设备的网卡名称,一般默认都是 eth0。但有一些特殊情况:如果非 eth0 一定要填入正确的网卡名称,否则跨设备通信容易出现问题
高可用类型 :高可用 VIP 地址(按需使用)
注意:如果使用高可用,至少需要三个 master 节点才可组成高可用集群,否则会出现 脑裂 现象。
- 不设置:第一台 master 节点的 IP 地址作为 APIServer 地址
TKE 提供:用户只需提供高可用的 IP 地址。TKE 部署 Keepalive,配置该 IP 为 Global 集群所有 Master 节点的VIP,以实现 Global 集群和控制台的高可用,此时该 VIP 和所有 Master 节点 IP 地址都是 APIServer 地址
- 使用已有:对接配置好的外部 LB 实例。VIP 绑定 Global 集群所有 Master 节点的 80(TKEStack 控制台)、443(TKEStack 控制台)、6443(kube-apiserver 端口)、31138(tke-auth-api 端口)端口,同时确保该 VIP 有至少两个 LB 后端(Master 节点),以避免 LB 单后端不可用风险
GPU:选择是否安装 GPU 相关依赖。(按需使用)
注意:使用 GPU 首先确保节点有物理 GPU 卡,选择 GPU 类型后,平台将自动为节点安装相应的 GPU 驱动和运行时工具
- pGPU:平台会自动为集群安装 GPUManager 扩展组件,此时可以给负载分配任意整数张卡
- vGPU:平台会自动为集群安装 Nvidia-k8s-device-plugin,此时GPU可以被虚拟化,可以给负载分配非整数张GPU卡,例如可以给一个负载分配0.3个GPU
容器网络 :将为集群内容器分配在容器网络地址范围内的 IP 地址,您可以自定义三大私有网段作为容器网络, 根据您选择的集群内服务数量的上限,自动分配适当大小的 CIDR 段用于 kubernetes service;根据您选择 Pod 数量上限/节点,自动为集群内每台云服务器分配一个适当大小的网段用于该主机分配 Pod 的 IP 地址。(建议使用默认值)
- CIDR: 集群内 Sevice、 Pod 等资源所在网段,注意:CIDR不能与目标机器IP段重叠, 否则会造成初始化失败
- Pod数量上限/节点: 决定分配给每个 Node 的 CIDR 的大小
- Service数量上限/集群:决定分配给 Sevice 的 CIDR 大小
Master :输入目标机器信息后单击保存,若保存按钮是灰色,单击网页空白处即可变蓝
注意:如果在之前选择了高可用,至少需要三个 master 节点才可组成高可用集群,否则会出现 脑裂 现象。
目标机器:Master 节点内网 IP,请配置至少 8 Cores & 16G 内存 及以上的机型,否则会部署失败。注意:如上图所示,如果节点密码一样,这里可以通过英文的分号“;”分隔多个 IP 地址实现快速添加多个节点
SSH 端口: 请确保目标机器安全组开放 22 端口和 ICMP 协议,否则无法远程登录和 ping 通云服务器。(建议使用默认值22)
主机label:给主机设置 Label,可用于指定容器调度。(按需使用)
认证方式:连接目标机器的方式
- 密码认证:
- 密码:目标机器密码
- 密钥认证:
- 密码:目标机器密码
- 证书:目标机器登陆证书
- 密码认证:
GPU: 使用 GPU 机器需提前安装驱动和 runtime。(按需使用)
添加机器:可以通过节点下面的**【添加】**蓝色字体增加不同密码的master节点(**按需添加**)
提交: 集群信息填写完毕后,【提交】按钮变为可提交状态,单击即可提交。
导入已有集群
- 登录 TKEStack
- 切换至【平台管理】控制台
- 在“集群管理”页面,单击【导入集群】,如下图所示:

- 在“导入集群”页面,填写被导入的集群信息,如下图所示:

名称: 被导入集群的名称,最长60字符
API Server: 被导入集群的 API Server 的域名或 IP 地址
CertFile: 输入被导入集群的 CertFile 文件内容
Token: 输入被导入集群创建时的 token 值
注意:若不清楚集群的这些信息如何获取,可以参照下面导入 TKE/ACK/RKE 的方式导入自己的集群。
- 单击最下方 【提交】 按钮
TKEStack 导入腾讯的 TKE 集群
首先需要在 TKE 控制台所要导入的集群“基本信息”页里开启内/外网访问

APIServer 地址:即上图中的访问地址,也可以根据上图中 kubeconfig 文件里的“server”字段内容填写。
CertFile:集群证书,kubeconfig 中“certificate-authority-data”字段内容。
Token:由于目前 TKE 没有自动创建具有 admin 权限的 token,这里需要手动创建,具体方式如下:
生成 kubernetes 集群最高权限 admin 用户的 token
cat <<EOF | kubectl apply -f - kind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1beta1 metadata: name: admin annotations: rbac.authorization.kubernetes.io/autoupdate: "true" roleRef: kind: ClusterRole name: cluster-admin apiGroup: rbac.authorization.k8s.io subjects: - kind: ServiceAccount name: admin namespace: kube-system --- apiVersion: v1 kind: ServiceAccount metadata: name: admin namespace: kube-system labels: kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile EOF创建完成后获取 secret 中 token 的值
# 获取admin-token的secret名字 $ kubectl -n kube-system get secret|grep admin-token admin-token-nwphb kubernetes.io/service-account-token 3 6m # 获取token的值 $ kubectl -n kube-system describe secret admin-token-nwphb | grep token Name: admin-token-w4wcd Type: kubernetes.io/service-account-token token: 非常长的字符串
TKEStack 中导入 Rancher 的 RKE 集群
特别注意:RKE 集群的 kubeconfig 中 clusters 字段里面的第一个 cluster 一般都是 Rancher 平台,而不是 RKE 集群。输入以下信息时,要确定选择正确的集群。
获取 RKE 的 kubeconfig 文件
APIServer 地址:获取文件里面的“cluster”字段下“server”的内容。注意是引号里的全部内容
CertFile:集群证书,在上面的“server”地址的正下方,有集群证书字段“certificate-authority-data”。
注意,Rancher 的 kubeconfig 这里的字段内容默认有“\”换行符,需要手动把内容里的换行符和空格全部去除。
Token:在“user”字段里面拥有用户的 token
TKEStack 中导入阿里的 ACK 集群
- 和 TKE 一样,需要获取开启外网访问的 ACK 的 kubeconfig 文件
- APIServer 地址:获取文件里面的“cluster”字段下“server”的内容
- CertFile:集群证书,在上面的“server”地址正下方有集群证书字段“certificate-authority-data”
- Token:获取方式同 TKE,需要手动创建
对集群的操作
基本信息
登录 TKEStack
切换至【平台管理】控制台
在“集群管理”页面中,点击要操作的集群ID,如下图“global”所示:

点击【基本信息】,可查看集群基础信息

- 基本信息
- 集群名称:用户自定义,可以通过第3步“集群列表页”中 “ID/名称” 下的笔型图案修改
- 集群 ID :TKEStack 自动给每个集群一个唯一的 ID 标识符
- 状态:集群运行状态,Running 表示正常运行
- Kubernetes 版本:当前集群的 Kubernetes 版本
- 网卡名称:当前集群的网卡名称,默认为 eth0
- 容器网络:当前集群的容器网络
- 集群凭证:可以在本地配置 Kubectl 连接 当前 Kubernetes 集群
- 超售比:Kubernetes 对象在申请资源时,如果申请总额大于硬件配置,则无法申请,但是很多时候部分对象并没有占用这么多资源,因此可以设置超售比来扩大资源申请总额,以提高硬件资源利用率
- 创建时间:当前集群的创建时间
- 组件信息:这里可以开启或关闭集群的 日志采集 和 监控告警 功能
- 基本信息
节点管理
节点是容器集群组成的基本元素。节点取决于业务,既可以是虚拟机,也可以是物理机。每个节点都包含运行 Pod 所需要的基本组件,包括 Kubelet、Kube-proxy 等。
添加节点
登录 TKEStack
切换至【平台管理】控制台
在“集群管理”页面中,点击要操作的集群ID,如下图“global”所示:

点击【节点管理】中的【节点】,可查看当前集群的“节点列表”

点击蓝色【添加节点】按钮可增加当前集群的 Worker 节点
- 目标机器:建议内网地址,要求添加的节点和当前集群的其他机器在同一内网。注意:如果节点密码一样,这里可以通过英文的分号“;”分隔多个 IP 地址实现快速添加多个节点
- SSH端口:默认 22
- 主机label:按需添加,给主机设置 Label,可用于指定容器调度
- 认证方式:连接目标机器的方式,根据实际情况设置
- 用户名:默认 root
- 密码:目标机器用户名为 root 的密码
- GPU:按需选择,使用 GPU 机器需提前安装驱动和 runtime
- 添加机器:可以通过节点下面的**【添加】**蓝色字体增加不同密码的节点(按需添加)
节点监控
点击上图中的蓝色【监控】按钮可监控节点,可以从Pod、CPU、内存、硬盘、网络等维度监控。
前提:在集群的 基本信息 页里开启了 监控告警
节点操作
对节点的可以的操作如下图所示:

移出:仅针对 worker 节点,将节点移出集群
驱逐:节点驱逐后,将会把节点内的所有 Pod(不包含 DaemonSet 管理的 Pod)从节点中驱逐到集群内其他节点,并将节点设置为封锁状态
注意:本地存储的 Pod 被驱逐后数据将丢失,请谨慎操作
编辑标签:编辑节点标签
编辑 Taint:编辑 Taint 后,新的 pod 不能被调度到该节点,但可以通过编辑 pod 的 toleration 使其可以调度到具有匹配的 taint 节点上
封锁:封锁节点后,将不接受新的Pod调度到该节点,需要手动取消封锁的节点
节点 Pod 管理
点击其中一个节点名,例如上图中的【172.19.0.154】,可以看到该节点更多的信息,具体包括:

- Pod 管理:可查看当前节点下的 pod
- 销毁重建:销毁该 pod,重新新建该 pod
- 远程登录:登录到该 pod 里
- 事件:关于该节点上资源的事件,资源事件只在 ETCD 里保存最近1小时内发生的事件,请尽快查阅
- 详情:包括节点主机信息以及 Kubernetes 信息
- YAML:此处可以查看节点的 YAML 文件,点击【编辑YAML】可以手动修改节点的 YAML 文件
其他操作
注意:由于【平台管理】控制台下对集群的大多数操作与【业务管理】控制台完全一致,因此除了集群的【基本信息】和【节点管理】之外,其他栏目(包括 命名空间、负载、服务、配置、存储、日志、事件)请参考【业务管理】控制台下【应用管理】的相应部分。
4.2.3 - 业务管理
概念
在这里用户可以管理线上业务。
操作步骤
新建业务
注:业务可以实现跨集群资源的使用
登录 TKEStack。
在【平台管理】控制台的【业务管理】中,单击 【新建业务】。如下图所示:

在“新建业务”页面,填写业务信息。如下图所示:

业务名称:不能超过63个字符,这里以
my-business为例业务成员: 【访问管理】中【用户管理】中的用户,这里以
admin例,即该用户可以访问这个业务。集群:
- 【集群管理】中的集群,这里以
gobal集群为例 - 【填写资源限制】可以设置当前业务使用该集群的资源上限(可不限制)
- 【新增集群】可以添加多个集群,此业务可以使用多个集群的资源(按需添加)
- 【集群管理】中的集群,这里以
上级业务:支持多级业务管理,按需选择(可不选)
单击最下方 【完成】 按钮即可创建业务。
添加业务成员
登录 TKEStack。
切换至 【平台管理】控制台,点击【业务管理】。
在“业务管理”页面中,可以看到已创建的业务列表。鼠标移动到要修改的业务上(无需点击),成员列会出现修改图标按钮。如下图所示:

注意:修改业务成员仅限状态为Active的业务,这里可以新建和删除成员。
查看业务监控
登录 TKEStack。
切换至 【管理】控制台,点击【业务管理】。
在“业务管理”页面中,可以看到已创建的业务列表。点击监控按钮,如下图所示:

在右侧弹出窗口里查看业务监控情况,如下图所示:

删除业务
登录 TKEStack。
切换至 【平台管理】控制台,点击【业务管理】。
在“业务管理”页面中,可以看到已创建的业务列表。点击删除按钮,如下图所示:

注意:删除业务成员仅限状态为Active的业务
对业务的操作
登录 TKEStack。
在【平台管理】控制台的【业务管理】中,单击【业务id】。如下图所示:

a. 业务信息: 在这里可以对业务名称、关联的集群、关联集群的资源进行限制等操作。

b. 成员列表: 在这里可以对业务名称、关联的集群、关联集群的资源进行限制等操作。

c. 子业务: 在这里可以新建本业务的子业务或通过导入子业务将已有业务变成本业务的子业务

d. 业务下Namespace列表: 这里可以管理业务下的Namespace

单击【新建Namespace】。在“新建Namespace”页面中,填写相关信息。如下图所示:

名称:不能超过63个字符,这里以
new-ns为例 集群:
my-business业务中的集群,这里以global集群为例 资源限制*:这里可以限制当前命名空间下各种资源的使用量,可以不设置。
4.2.4 - 扩展组件
扩展组件
概念
这里用户可以管理集群扩展组件。
操作步骤
创建组件
- 登录 TKEStack。
- 切换至 【平台管理】控制台,选择【扩展组件】页面。
- 选择需要安装组件的集群,点击【新建】按钮。如下图所示:

注意:此页面右边的【删除】按钮可以删除安装了的组件
- 在弹出的扩展组件列表里,选择要安装的组件。如下图所示:

注意:如果选择的是PersistentEvent,需要在下方输入地址和索引。
- 单击【完成】。
4.2.4.1 - TApp 介绍
TApp 介绍
Kubernetes 现有应用类型(如:Deployment、StatefulSet等)无法满足很多非微服务应用的需求。比如:操作(升级、停止等)应用中的指定 Pod;应用支持多版本的 Pod。如果要将这些应用改造为适合于这些 Workload 的应用,需要花费很大精力,这将使大多数用户望而却步。
为解决上述复杂应用管理场景,TKEStack 基于 Kubernetes CRD 开发了一种新的应用类型 TApp,它是一种通用类型的 Workload,同时支持 service 和 batch 类型作业,满足绝大部分应用场景,它能让用户更好的将应用迁移到 Kubernetes 集群。
TApp 架构
TAPP 其结构定义见 TAPP struct。TApp Controller 是 TApp 对应的Controller/operator,它通过 kube-apiserver 监听 TApp、Pod 相关的事件,根据 TApp 的 spec 和 status 进行相应的操作:创建、删除pod等。

TApp 使用场景
Kubernetes 凭借其强大的声明式 API、丰富的特性和可扩展性,逐渐成为容器编排领域的霸主。越来越多的用户希望使用 Kubernetes,将现有的应用迁移到 Kubernetes 集群,但 Kubernetes 现有 Workload(如:Deployment、StatefulSet等)无法满足很多非微服务应用的需求,比如:操作(升级、停止等)应用中的指定 Pod、应用支持多版本的 Pod。如果要将这些应用改造为适合于这些 Workload的应用,需要花费很大精力,这将使大多数用户望而却步。
腾讯有着多年的容器编排经验,基于 Kuberentes CRD(Custom Resource Definition,使用声明式API方式,无侵入性,使用简单)开发了一种新的 Workload 类型 TApp,它是一种通用类型的 Workload,同时支持 service 和 batch 类型作业,满足绝大部分应用场景,它能让用户更好的将应用迁移到 Kubernetes 集群。如果用 Kubernetes 的 Workload 类比,TAPP ≈ Deployment + StatefulSet + Job ,它包含了 Deployment、StatefulSet、Job 的绝大部分功能,同时也有自己的特性,并且和原生 Kubernetes 相同的使用方式完全一致。经过这几年用户反馈, TApp 也得到了逐渐的完善。
TApp 特点
- 同时支持 service 和 batch 类型作业。通过 RestartPolicy 来对这两种作业进行区分。RestartPolicy值有三种:RestartAlways、Never、OnFailure
- RestartAlways:表示 Pod 会一直运行,如果结束了也会被重新拉起(适合 service 类型作业)
- Never:表示 Pod 结束后就不会被拉起了(适合 batch 类型作业)
- OnFailure:表示 Pod 结束后,如果 exit code 非0,将会被拉起,否则不会(适合 batch 类型作业)
- 固定ID:每个实例(Pod)都有固定的 ID(0, 1, 2 … N-1,其中N为实例个数),它们的名字由 TApp 名字+ID 组成,因此名字也是唯一的。 有了固定的ID和名字后,我们便可以实现如下能力:
- 将实例用到的各种资源(将实例用到的存储资源(如:云硬盘),或者是IP)和实例一一对应起来,这样即使实例发生迁移,实例对应的各种资源也不会变
- 通过固定 ID,我们可以为实例分配固定的 IP(float ip)。
- 唯一的实例名字还可用来跟踪实例完整的生命周期,对于同一个实例,可以由于机器故障发生了迁移、重启等操作,虽然不是一个 Pod 了,但是我们用实例 ID 串联起来,就获得了实例真正的生命周期的跟踪,对于判断业务和系统是否正常服务具有特别重要的意义
- 操作指定实例:有了固定的 ID,我们就能操作指定实例。我们遵循了 Kubernetes 声明式的 API,在 spec 中 statuses 记录实例的目标状态, instances 记录实例要使用的 template,用于停止、启动、升级指定实例。
- 支持多版本实例:在 TApp spec 中,不同的实例可以指定不同的配置(image、resource 等)、不同的启动命令等,这样一个应用可以存在多个版本实例。
- 原地更新(in place update):Kubernetes 的更新策略是删除旧 Pod,新建一个 Pod,然后调度等一系列流程,才能运行起来,而且 Pod原先的绑定的资源(本地磁盘、IP 等)都会变化。TApp 对此进行了优化:如果只修改了 container 的 image,TApp 将会对该 Pod 进行本地更新,原地重启受影响的容器,本地磁盘不变,IP 不变,最大限度地降低更新带来的影响,这能极大地减少更新带来的性能损失以及服务不可用。
- 云硬盘:云硬盘的底层由分布式存储 Ceph 支持,能很好地支持有状态的作业。在实例发生跨机迁移时,云硬盘能跟随实例一起迁移。TApp 提供了多种云硬盘类型供选择。
- 多种升级发布方式:TApp除了支持常规的蓝绿布署、滚动发布、金丝雀部署等升级发布方式,还有其特有的升级发布方式:用户可以指定升级任意的实例。
- 自动扩缩容:根据 CPU/MEM/用户自定义指标对 TAPP 进行自动扩缩容。 除了自动扩缩容,我们还开发了周期性扩缩容 CronHPA 支持对 TApp 等(包括 Kubernetes 原生的 Deployment 和 StatefulSet)进行周期性扩缩容,支持 CronTab 语法格式,满足对资源使用有周期性需求的业务。
- Gang scheduling:有些应用必须要等到获取到资源能运行的实例达到一定数量后才开始运行,TApp 提供的 Gang scheduling 正是处理这种情况的。

部署在集群内 kubernetes 对象
在集群内部署 TApp Add-on , 将在集群内部署以下 kubernetes 对象
| kubernetes 对象名称 | 类型 | 默认占用资源 | 所属Namespaces |
|---|---|---|---|
| tapp-controller | Deployment | 每节点1核CPU, 512MB内存 | kube-system |
| tapps.apps.tkestack.io | CustomResourceDefinition | / | / |
| tapp-controller | ServiceAccount | / | kube-system |
| tapp-controller | Service | / | kube-system |
| tapp-controller | ClusterRoleBinding(ClusterRole/cluster-admin) | / | / |
TApp 使用方法
安装 TApp 组件
- 登录 TKEStack
- 切换至 平台管理 控制台,选择扩展组件页面
- 选择需要安装组件的集群,点击【新建】按钮。如下图所示:

- 在弹出的扩展组件列表里,滑动列表窗口找到tapp组件。如下图所示:

单击【完成】
安装完成后会在刚刚安装了 TApp 扩展组件的集群里 【工作负载】下面出现【TApp】,如下图所示:

使用 TApp 组件
在 TKEStack 控制台上使用 TApp 使用请参考:TApp Workload
对 TApp 架构和命令行使用请参考:TApp Repository
参考
手动部署 TApp
git clone https://github.com/tkestack/tapp.git
cd tapp
make build
bin/tapp-controller --kubeconfig=$HOME/.kube/config
原地升级
修改 spec.templatePool.{templateName}.spec.containers.image 的值实现原地升级。
挂在存储卷后的 Pod 依旧在 image 升级的时候没有任何影响,同时 PVC 也没有改变,唯一改变的只有镜像本身。
部分关键字解释
| 关键字 | 作用 |
|---|---|
| spec.templatePool | 模版池 |
| spec.templates | 以键值对(Pod 序号:模板池中的模板名)的形式具体声明每一个 Pod 的状态 |
| spec.template 等价于 spec.DefaultTemplateName | 默认模板(在spec.templates中没有定义的 Pod 序号将使用该模板) |
| updateStrategy.inPlaceUpdateStrategy | 原地升级策略 |
| spec.updateStrategy | 保留旧版本 Pod 的数量,默认为 0,类似于灰度发布 |
| spec.updateStrategy.template | 要设置 maxUnavailable 值的 template 名 |
| spec.updateStrategy.maxUnavailable | 最大的不可用 Pod 数量(默认为1,可设置成一个自然数,或者一个百分比,例如 50%) |
| spec.statuses | 明确 Pod 的状态,TApp 会实现该状态 |
apiVersion: apps.tkestack.io/v1
kind: TApp
metadata:
name: example-tapp
spec:
replicas: 3
# 默认模板
template:
metadata:
labels:
app: example-tapp
spec:
containers:
- name: nginx
image: nginx:latest
# 模板池
templatePool:
# 模板池中的模板
"test2":
metadata:
labels:
app: example-tapp
spec:
containers:
- name: nginx
image: nginx:1.7.9
# 要使用模板池中模板的 Pod
templates:
# Pod 序号:模板池中的模板
"1": "test2"
"2": "test2"
# 更新策略
updateStrategy:
# 更新指定模板。test2该模板有过修改,或者是在模板池里新增的,都可以通过 updateStrategy 设置模板来进行滚动更新
template: test2
# 使用该模板的 Pod 在更新时最大不可用的数量
maxUnavailable: 1
# 明确 Pod 的状态,TApp 会实现该状态
statuses:
# 编号为1的 Pod 将被 Kill
"1": "Killed"
4.2.4.2 - CronHPA 介绍
CronHPA 介绍
Cron Horizontal Pod Autoscaler(CronHPA) 可让用户利用 CronTab 实现对负载(Deployment、StatefulSet、TApp 这些支持扩缩容的资源对象)定期自动扩缩容。
CronTab 格式说明如下:
# 文件格式说明
# ——分钟(0 - 59)
# | ——小时(0 - 23)
# | | ——日(1 - 31)
# | | | ——月(1 - 12)
# | | | | ——星期(0 - 6)
# | | | | |
# * * * * *
CronHPA 定义了一个新的 CRD,cron-hpa-controller 是该 CRD 对应的 Controller/operator,它解析 CRD 中的配置,根据系统时间信息对相应的工作负载进行扩缩容操作。
CronHPA 使用场景
以游戏服务为例,从星期五晚上到星期日晚上,游戏玩家数量暴增。如果可以将游戏服务器在星期五晚上扩大规模,并在星期日晚上缩放为原始规模,则可以为玩家提供更好的体验。这就是游戏服务器管理员每周要做的事情。
其他一些服务也会存在类似的情况,这些产品使用情况会定期出现高峰和低谷。CronHPA 可以自动化实现提前扩缩 Pod,为用户提供更好的体验。
部署在集群内 kubernetes 对象
在集群内部署 CronHPA Add-on , 将在集群内部署以下 kubernetes 对象:
| kubernetes 对象名称 | 类型 | 默认占用资源 | 所属 Namespaces |
|---|---|---|---|
| cron-hpa-controller | Deployment | 每节点1核 CPU, 512MB内存 | kube-system |
| cronhpas.extensions.tkestack.io | CustomResourceDefinition | / | / |
| cron-hpa-controller | ClusterRoleBinding(ClusterRole/cluster-admin) | / | / |
| cron-hpa-controller | ServiceAccount | / | kube-system |
CronHPA 使用方法
安装 CronHPA
- 登录 TKEStack
- 切换至【平台管理】控制台,选择【扩展组件】页面
- 选择需要安装组件的集群,点击【新建】按钮,如下图所示:

- 在弹出的扩展组件列表里,滑动列表窗口找到 CronHPA 组件
- 单击【完成】
在控制台上使用 CronHPA
TKEStack 已经支持在页面多处位置为负载配置 CronHPA
- 新建负载页(负载包括Deployment、StatefulSet、TApp)这里新建负载时将会同时新建与负载同名的 CronHPA 对象:

每条触发策略由两条字段组成
- Crontab :例如 “0 23 * * 5"表示每周五23:00,详见crontab
- 目标实例数 :设置实例数量
- 自动伸缩的 CronHPA 列表页。此处可以查看/修改/新建 CronHPA:

通过 YAML 使用 CronHPA
创建 CronHPA 对象
示例1:指定 Deployment 每周五20点扩容到60个实例,周日23点缩容到30个实例
apiVersion: extensions.tkestack.io/v1
kind: CronHPA
metadata:
name: example-cron-hpa # CronHPA 名
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment # CronHPA 操作的负载类型
name: demo-deployment # CronHPA 操作的负载类型名
crons:
- schedule: "0 20 * * 5" # Crontab 语法格式
targetReplicas: 60 # 负载副本(Pod)的目标数量
- schedule: "0 23 * * 7"
targetReplicas: 30
示例2:指定 Deployment 每天8点到9点,19点到21点扩容到60,其他时间点恢复到10
apiVersion: extensions.tkestack.io/v1
kind: CronHPA
metadata:
name: web-servers-cronhpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: web-servers
crons:
- schedule: "0 8 * * *"
targetReplicas: 60
- schedule: "0 9 * * *"
targetReplicas: 10
- schedule: "0 19 * * *"
targetReplicas: 60
- schedule: "0 21 * * *"
targetReplicas: 10
查看已有 CronHPA
# kubectl get cronhpa
NAME AGE
example-cron-hpa 104s
# kubectl get cronhpa example-cron-hpa -o yaml
apiVersion: extensions.tkestack.io/v1
kind: CronHPA
...
spec:
crons:
- schedule: 0 20 * * 5
targetReplicas: 60
- schedule: 0 23 * * 7
targetReplicas: 30
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: demo-deployment
删除已有 CronHPA
kubectl delete cronhpa example-cron-hpa
CronHPA 项目请参考 CronHPA Repository
4.2.4.3 - 监控组件
Prometheus
良好的监控环境为 TKEStack 高可靠性、高可用性和高性能提供重要保证。您可以方便为不同资源收集不同维度的监控数据,能方便掌握资源的使用状况,轻松定位故障。
TKEStack 使用开源的 Prometheus 作为监控组件,免去您部署和配置 Prometheus 的复杂操作,TKEStack 提供高可用性和可扩展性的细粒度监控系统,实时监控 CPU,GPU,内存,显存,网络带宽,磁盘 IO 等多种指标并自动绘制趋势曲线,帮助运维人员全维度的掌握平台运行状态。
TKEStack 使用 Prometheus 的架构和原理可以参考 Prometheus 组件
指标具体含义可参考:监控 & 告警指标列表

TKEStack 通过 Prometheus 组件监控集群状态,Prometheus 组件通过 addon 扩展组件自动完成安装和配置,使用 InfluxDB,ElasticSearch 等存储监控数据。监控数据和指标融入到平台界面中以风格统一图表的风格展示,支持以不同时间,粒度等条件,查询集群,节点,业务,Workload 以及容器等多个层级的监控数据,全维度的掌握平台运行状态。
同时针对在可用性和可扩展性方面,支持使用 Thanos 架构提供可靠的细粒度监控和警报服务,构建具有高可用性和可扩展性的细粒度监控能力。
安装 Prometheus
Prometheus 为 TKEStack 扩展组件,需要在集群的 【基本信息】 页下面开启 “监控告警”。

集群监控
- 登录 TKEStack
- 切换至【平台管理】控制台,选择【集群管理】
- 点击【监控】图标,如下图所示:

- 监控数据展示
- 通过下图中的1可以选择监控数据时间段
- 通过下图中的2可以选择统计粒度,以下图中“APIServer时延”为例,下图中的每个数据表示前1分钟“APIServer时延”平均数

- 上下滑动曲线图可以获得更多监控指标
- 点击曲线图,会弹出具体时间点的具体监控数据

指标具体含义可参考:监控 & 告警指标列表
节点监控
- 登录 TKEStack
- 切换至【平台管理】控制台,选择【集群管理】
- 点击【集群 ID】 -> 【节点管理】->【节点】->【监控】图标,如下图所示:

具体查看方式和集群监控完全一致
指标具体含义可参考:监控 & 告警指标列表
此处还可以查看节点下的 Pod 监控
- 如下图所示,对比维度可选择 节点 或 Pod
- 选择 Pod ,需要在其右侧选择 Pod 所属节点

节点下的 Pod & Container 监控
有两种方式
- 节点监控 下选择 Pod 进行监控
- 在节点列表里,点击节点名,进入节点的 Pod 管理页,如下图所示,点击上方的【监控】按钮,实现对节点下的 Pod 监控

注意:此处还可以查看节点下的 Container 监控
- 如下图所示,对比维度可选择 Pod 或 Container
- 选择 Container ,需要在其右侧选择 Container 所属 Pod

指标具体含义可参考:监控 & 告警指标列表
负载监控
登录 TKEStack
切换至【平台管理】控制台,选择【集群管理】
点击【集群 ID】 -> 【工作负载】->【选择一种负载,例如 Deployment】->【监控】图标,如下图所示:
具体查看方式和集群监控完全一致
指标具体含义可参考:监控 & 告警指标列表
负载下 Pod & Container 监控
- 登录 TKEStack
- 切换至【平台管理】控制台,选择【集群管理】
- 点击【集群 ID】 -> 【工作负载】->【选择一种负载】,例如 Deployment】->【点击一个负载名】->【监控】图标,如下图所示:

注意:此处还可以查看负载下的 Container 监控
- 如下图所示,对比维度可选择 Pod 或 Container
- 选择 Container ,需要在其右侧选择 Container 所属 Pod 指标具体含义可参考:监控 & 告警指标列表

TKEStack 使用 Prometheus 的架构和原理可以参考 Prometheus 组件
4.2.4.4 - LogAgent 介绍
日志采集
LogAgent 介绍
TKESTack 通过 logagent 提供的集群内日志采集功能,支持将集群内服务或集群节点特定路径文件的日志发送至 Kafka、Elasticsearch 等消费端,支持采集容器标准输出日志,容器内文件日志以及主机内文件日志。更提供事件持久化、审计等功能,实时记录集群事件及操作日志记录,帮助运维人员存储和分析集群内部资源生命周期、资源调度、异常告警等情况。

TKEStack 老版本日志使用 LogCollector 扩展组件。LogAgent 用于替换 LogCollector,新版本统一用 LogAgent 完成日志采集功能。
日志收集功能需要为每个集群手动开启。日志收集功能开启后,日志收集组件 logagent 会在集群内以 Daemonset 的形式运行。用户可以通过日志收集规则配置日志的采集源和消费端,日志收集 Agent 会从用户配置的采集源进行日志收集,并将日志内容发送至用户指定的消费端。需要注意的是,使用日志收集功能需要您确认 Kubernetes 集群内节点能够访问日志消费端。
- 采集容器标准输出日志 :采集集群内指定容器的 Stderr 和 Stdout 日志。,采集到的日志信息将会以 JSON 格式输出到用户指定的消费端,并会自动附加相关的 Kubernetes metadata, 包括容器所属 Pod 的 label 和 annotation 等信息。
- 采集容器内文件日志 :采集集群内指定容器内文件路径的日志,用户可以根据自己的需求,灵活的配置所需的容器和路径,采集到的日志信息将会以 JSON 格式输出到用户指定的消费端, 并会附加相关的 Kubernetes metadata,包括容器所属 Pod 的 label 和 annotation 等信息。
- 采集主机内文件日志 :采集集群内所有节点的指定主机文件路径的日志,logagent 会采集集群内所有节点上满足指定路径规则的文件日志,以 JSON 格式输出到用户指定的输出端, 并会附加用户指定的 metadata,包括日志来源文件的路径和用户自定义的 metadata。
部署在集群内 kubernetes 对象
在集群内部署 logagent Add-on , 将在集群内部署以下 kubernetes 对象
| kubernetes 对象名称 | 类型 | 默认占用资源 | 所属Namespaces |
|---|---|---|---|
| logagent | DaemonSet | 每节点0.3核 CPU, 250MB 内存 | kube-system |
| logagent | ServiceAccount | kube-system |
使用日志采集服务
注意:日志采集对接外部 Kafka 或 Elasticsearch,该功能需要额外开启,位置在集群 基本信息 下面,点击开启“日志采集”服务。

业务管理侧
- 登录 TKEStack
- 切换至【业务管理】控制台,选择 【运维中心】->【日志采集】
- 选择相应【业务】和【命名空间】,单击【新建】按钮,如下图所示:

- 在“新建日志采集”页面填写日志采集信息,如下图所示:

- 收集规则名称: 输入规则名,1~63字符,只能包含小写字母、数字及分隔符("-"),且必须以小写字母开头,数字或小写字母结尾
- 业务: 选择所属业务(业务管理侧才会出现)
- 集群: 选择所属集群(平台管理侧才会出现)
- 类型: 选择采集类型
- 容器标准输出: 容器 Stderr 和 Stdout 日志信息采集
- 日志源: 可以选择所有容器或者某个 Namespace 下的所有容器/工作负载
- 所有容器: 所有容器
- 指定容器: 某个 Namespace 下的所有容器或者工作负载
- 日志源: 可以选择所有容器或者某个 Namespace 下的所有容器/工作负载
- 容器文件路径: 容器内文件内容采集
日志源: 可以采集具体容器内的某个文件路径下的文件内容
- 工作负载选项: 选择某个 Namespace 下的某种工作负载类型下的某个工作负载
- 配置采集路径: 选择某个容器下的某个文件路径
- 文件路径若输入
stdout,则转为容器标准输出模式 - 可配置多个路径。路径必须以
/开头和结尾,文件名支持通配符(*)。文件路径和文件名最长支持63个字符 - 请保证容器的日志文件保存在数据卷,否则收集规则无法生效,详见指定容器运行后的日志目录
- 节点文件路径: 收集节点上某个路径下的文件内容,不会重复采集,因为采集器会记住之前采集过的日志文件的位点,只采集增量部分
- 日志源: 可以采集具体节点内的某个文件路径下的文件内容
- 收集路径: 节点上日志收集路径。路径必须以
/开头和结尾,文件名支持通配符(*)。文件路径和文件名最长支持63个字符 - metadata: key:value 格式,收集的日志会带上 metadata 信息上报给消费端
- 收集路径: 节点上日志收集路径。路径必须以
- 日志源: 可以采集具体节点内的某个文件路径下的文件内容
- 容器标准输出: 容器 Stderr 和 Stdout 日志信息采集
- 消费端: 选择日志消费端
- Kafka:
- 访问地址: Kafka IP 和端口
- 主题(Topic): Kafka Topic 名
- Elasticsearch:
Elasticsearch 地址: ES 地址,如:http://190.0.0.1:200
注意:当前只支持未开启用户登录认证的 ES 集群
索引: ES索引,最长60个字符,只能包含小写字母、数字及分隔符("-"、"_"、"+"),且必须以小写字母开头
- Kafka:
- 单击【完成】按钮
平台管理侧
在平台管理侧也支持日志采集规则的创建,创建方式和业务管理处相同。详情可点击平台侧的日志采集。
指定容器运行后的日志目录
LogAgent 除了支持日志规则的创建,也支持指定容器运行后的日志目录,可实现日志文件展示和下载。
前提:需要在创建负载时挂载数据卷,并指定日志目录

创建负载以后,在容器内的/data/logdir目录下的所有文件可以展示并下载,例如我们在容器的/data/logdir下新建一个名为a.log的文件,如果有内容的话,也可以在这里展示与下载:

4.2.4.5 - GPUManager 介绍
GPUManager 介绍
GPUManager 提供一个 All-in-One 的 GPU 管理器, 基于 Kubernets Device Plugin 插件系统实现,该管理器提供了分配并共享 GPU,GPU 指标查询,容器运行前的 GPU 相关设备准备等功能,支持用户在 Kubernetes 集群中使用 GPU 设备。
GPU-Manager 包含如下功能:
- 拓扑分配:提供基于 GPU 拓扑分配功能,当用户分配超过1张 GPU 卡的应用,可以选择拓扑连接最快的方式分配GPU设备
- GPU 共享:允许用户提交小于1张卡资源的的任务,并提供 QoS 保证
- 应用 GPU 指标的查询:用户可以访问主机的端口(默认为5678)的
/metrics路径,可以为 Prometheus 提供 GPU 指标的收集功能,/usage路径可以提供可读性的容器状况查询
GPU-Manager 使用场景
在 Kubernetes 集群中运行 GPU 应用时,可以解决 AI 训练等场景中申请独立卡造成资源浪费的情况,让计算资源得到充分利用。
GPU-Manager 限制条件
该组件基于 Kubernetes DevicePlugin 实现,只能运行在支持 DevicePlugin 的 kubernetes版本(Kubernetes 1.10 之上的版本)
使用 GPU-Manager 要求集群内包含 GPU 机型节点
TKEStack 的 GPU-Manager 将每张 GPU 卡视为一个有100个单位的资源
特别注意:
- 当前仅支持 0-1 的小数张卡,如 20、35、50;以及正整数张卡,如200、500等;不支持类似150、250的资源请求
- 显存资源是以 256MiB 为最小的一个单位的分配显存
部署在集群内 kubernetes 对象
在集群内部署 GPU-Manager,将在集群内部署以下 kubernetes 对象:
| kubernetes 对象名称 | 类型 | 建议预留资源 | 所属 Namespaces |
|---|---|---|---|
| gpu-manager-daemonset | DaemonSet | 每节点1核 CPU, 1Gi内存 | kube-system |
| gpu-quota-admission | Deployment | 1核 CPU, 1Gi内存 | kube-system |
GPU-Manager 使用方法
安装 GPU-Manager
集群部署阶段选择 vGPU,平台会为集群部署 GPU-Manager ,如下图新建独立集群所示,Global 集群的也是如此安装。

在节点安装 GPU 驱动
集群部署阶段添加 GPU 节点时有勾选 GPU 选项,平台会自动为节点安装 GPU 驱动,如下图所示:
注意:如果集群部署阶段节点没有勾选 GPU,需要自行在有 GPU 的节点上安装 GPU 驱动

工作负载使用 GPU
通过控制台使用
在安装了 GPU-Manager 的集群中,创建工作负载时可以设置 GPU 限制,如下图所示:
注意:
- 卡数只能填写 0.1 到 1 之间的两位小数或者是所有自然数,例如:0、0.3、0.56、0.7、0.9、1、6、34,不支持 1.5、2.7、3.54
- 显存只能填写自然数 n,负载使用的显存为 n*256MiB

通过 YAML 使用
如果使用 YAML 创建使用 GPU 的工作负载,提交的时候需要在 YAML 为容器设置 GPU 的使用资源。
- CPU 资源需要在 resource 上填写
tencent.com/vcuda-core - 显存资源需要在 resource 上填写
tencent.com/vcuda-memory
例1:使用1张卡的 Pod
apiVersion: v1
kind: Pod
...
spec:
containers:
- name: gpu
resources:
limits:
tencent.com/vcuda-core: 100
requests:
tencent.com/vcuda-core: 100
例2,使用 0.3 张卡、5GiB 显存的应用(5GiB = 20*256MB)
apiVersion: v1
kind: Pod
...
spec:
containers:
- name: gpu
resources:
limits:
tencent.com/vcuda-core: 30
tencent.com/vcuda-memory: 20
requests:
tencent.com/vcuda-core: 30
tencent.com/vcuda-memory: 20
GPU 监控数据查询
通过控制台查询
前提:在集群的【基本信息】页里打开“监控告警”
可以通过集群多个页面的监控按钮里查看到 GPU 的相关监控数据,下图以 集群管理 页对集群的监控为例:

通过后台手动查询
手动获取 GPU 监控数据方式(需要先安装 socat):
kubectl port-forward svc/gpu-manager-metric -n kube-system 5678:5678 &
curl http://127.0.0.1:5678/metric
结果示例:

GPUManager 项目请参考:GPUManager Repository
4.2.4.6 - CSIOperator 介绍
CSIOperator
CSIOperator 介绍
Container Storage Interface Operator(CSIOperator)用于部署和更新 Kubernetes 集群中的 CSI 驱动和外部存储组件。
CSIOperator 使用场景
CSIOperator 用于支持集群方便的使用存储资源,当前支持的存储插件包括 RBD、CephFS、TencentCBS 和 TencentCFS(TencentCFS 正在测试中)
- 其中 RBD 和 CephFS 主要用于部署在 IDC 环境的集群
- TencentCBS 和 TencentCFS 用于部署在腾讯云环境的集群
部署在集群内 kubernetes 对象
在集群内部署 CSIOperator,将在集群内部署以下 kubernetes 对象
| kubernetes 对象名称 | 类型 | 默认占用资源 | 所属 Namespaces |
|---|---|---|---|
| csi-operator | Deployment | 每节点0.2核 CPU, 256MB内存 | kube-system |
CSIOperator 使用方法
安装 CSIOperator
- 登录 TKEStack
- 切换至 【平台管理】控制台,选择 【扩展组件】 页面
- 选择需要安装组件的集群,点击【新建】按钮。如下图所示:

- 在弹出的扩展组件列表里,滑动列表窗口找到 CSIOperator
- 单击【完成】进行安装
通过 CSIOperator 使用腾讯云存储资源
- 登录 TKEStack
- 切换至 【平台管理】控制台,选择 【集群管理】 页面,如下图1所示:
- 点击安装了 CSIOperator 组件的【集群ID】,进入要管理的集群,如下图2所示:
- 点击【YAML创建资源】,如下图3所示:

文件中指定各自存储插件镜像的名称,这里以
tencentcbs的 YAML 为例:(前提:需要拥有腾讯云账号)apiVersion: storage.tkestack.io/v1 kind: CSI metadata: name: tencentcbsv1 namespace: kube-system spec: driverName: com.tencent.cloud.csi.cbs version: "v1" parameters: secretID: "xxxxxx" secretKey: "xxxxxx"- secretID、secretKey 来源于 腾讯云控制台 -> 账号中心 -> 访问管理 -> 访问秘钥 -> API密钥管理
创建完 CSIOperator 的 CRD 对象,同时会为每个存储插件创建默认的 StorageClass 对象(tencentcbs 的 StorageClass 对象名为 cbs-basic-prepaid),如下图:

其 YAML 如下:

tencentcbs 的 provisioner 名称指定为:
com.tencent.cloud.csi.cbstencentcfs 的 provisioner 名称指定为:
com.tencent.cloud.csi.cfs,tencentcfs 仍在测试中,目前仅支持 tencentcbs对于磁盘类型(在 StorageClass 的
diskType中指定)和大小的限制:- 普通云硬(
CLOUD_BASIC)盘提供最小 100 GB 到最大 16000 GB 的规格选择,支持 40-100MB/s 的 IO 吞吐性能和 数百-1000 的随机 IOPS 性能 - 高性能云硬盘(
CLOUD_PREMIUM)提供最小 50 GB 到最大 16000 GB 的规格选择 - SSD 云硬盘(
CLOUD_SSD)提供最小 100 GB 到最大 16000 GB 的规格选择,单块 SSD 云硬盘最高可提供 24000 随机读写IOPS、260MB/s吞吐量的存储性能
- 普通云硬(
默认创建的磁盘类型为普通云硬盘,如果用户希望使用该 StorageClass,可以直接创建使用了该 StorageClass 的 PVC 对象:
apiVersion: v1 kind: PersistentVolumeClaim metadata: name: test-tencentcbs namespace: kube-system spec: accessModes: - ReadWriteOnce storageClassName: cbs-basic-prepaid resources: requests: storage: 10Gi
详情请见 CSIOperator Example
4.2.5 - 组织资源
组织资源
概念
这里用户可以管理镜像仓库和凭据。
4.2.5.1 - 镜像仓库管理
镜像仓库管理
镜像仓库概述
镜像仓库:用于存放 Docker 镜像,Docker 镜像可用于部署容器服务,每个镜像有特定的唯一标识(镜像的 Registry 地址+镜像名称+镜像 Tag)
镜像类型:目前镜像支持 Docker Hub 官方镜像和用户私有镜像
镜像生命周期:主要包含镜像版本的生成、上传和删除
新建命名空间
- 登录 TKEStack
- 切换至【平台管理】控制台,选择 【组织资源】->【镜像仓库管理】
- 点击【新建】按钮,如下图所示:

- 在弹出的“新建命名空间”页面,填写命名空间信息,如下图所示:

- 名称: 命名空间名字,不超过63字符
- 描述: 命名空间描述信息(可选)
- 权限类型: 选择命名空间权限类型
- 公有: 所有人均可访问该命名空间下的镜像
- 私有: 个人用户命名空间
- 单击【确认】按钮
删除命名空间
- 登录 TKEStack
- 切换至 【平台管理】控制台,选择 【组织资源】->【镜像仓库管理】。点击列表最右侧【删除】按钮,如下图所示:

镜像上传
- 登录 TKEStack
- 切换至 【平台管理】控制台,选择 【组织资源】->【镜像仓库管理】,查看命名空间列表,点击列表中命名空间【名称】,如下图所示:

此时进入了“镜像列表”页面,点击【镜像上传指引】按钮,如下图所示:
注意:此页面可以通过上传的镜像最右边的【删除】按钮来删除上传的镜像

- 根据指引内容,在物理节点上执行相应命令,如下图所示:

4.2.5.2 - Helm模板
应用功能是 TKEStack 集成的 Helm 3.0 相关功能,为您提供创建 helm chart、容器镜像、软件服务等各种产品和服务的能力。已创建的应用将在您指定的集群中运行,为您带来相应的能力。
模板
- 登录 TKEStack
- 切换至 【平台管理】控制台,选择 【组织资源】->【 Helm模板】,点击【模板】

- 所有模板:包含下列所有模板
- 用户模板:权限范围为“指定用户”的仓库下的所有模板
- 业务模板:权限范围为“指定业务”的仓库下的所有模板
- 公共模板:权限范围为“公共”的仓库下的所有模板
仓库
- 登录 TKEStack
- 切换至 【平台管理】控制台,选择 【组织资源】->【 Helm模板】,点击【仓库】
- 点击【新建】按钮,如下图所示:

- 在弹出的 “新建仓库” 页面,填写 仓库 信息,如下图所示:

仓库名称: 仓库名字,不超过60个字符
权限访问
- 指定用户:选择当前仓库可以被哪些平台的用户访问
- 指定业务:选择当前仓库可以被哪些平台的业务访问,业务下的成员对该仓库的访问权限在【业务管理】中完成
- 公共:平台所有用户都能访问该仓库
导入第三方仓库: 若已有仓库想导入 TKEStack 中使用,请勾选
- 第三方仓库地址:请输入第三方仓库地址
- 第三方仓库用户名:若第三方仓库开启了鉴权,需要输入第三方仓库的用户名
- 第三方仓库密码:若第三方仓库开启了鉴权,需要输入第三方仓库的密码
仓库描述: 请输入仓库描述,不超过255个字符
单击【确认】按钮
删除仓库
登录 TKEStack
切换至 【平台管理】控制台,选择 【组织资源】-> 【 Helm 模板】,点击【仓库】,查看 “helm模板仓库”列表
点击列表最右侧【删除】按钮,如下图所示:

Chart 上传指引
- 登录 TKEStack
- 切换至 【平台管理】控制台,选择 【组织资源】-> 【 Helm模板】,点击【仓库】,查看 “helm模板仓库”列表
- 点击列表最右侧【上传指引】按钮,如下图所示:

- 根据指引内容,在物理节点上执行相应命令,如下图所示:

同步导入仓库
- 登录 TKEStack
- 切换至 【平台管理】控制台,选择 【组织资源】->【 Helm模板】,点击【仓库】
- 点击导入仓库的【同步仓库】按钮,如下图所示:

4.2.5.3 - 访问凭证
访问凭证
这里用户可以管理自己的凭据,用来登陆平台创建的镜像仓库和应用仓库。
新建访问凭证
- 登录 TKEStack
- 切换至 【平台管理】控制台,选择 【组织资源】下的【访问凭证】,点击【新建】按钮,如下图所示:

- 在弹出创建访问凭证页面,填写凭证信息,如下图所示:

- 凭证描述: 描述当前凭证信息
- 过期时间: 填写过期时间,选择小时/分钟为单位
- 单击【确认】按钮
使用指引
- 登录 TKEStack
- 切换至 【平台管理】控制台,选择 【组织资源】下的【访问凭证】,点击【新建】按钮,如下图所示:

- 根据指引内容,在物理节点上执行相应命令
停用/启用/删除访问凭证
登录 TKEStack
切换至 【平台管理】控制台,选择 【组织资源】-> 【访问凭证】,查看“访问凭证”列表,单击列表右侧【禁用】/【启用】/【删除】按钮。如下图所示:
注意:点击【禁用】之后,【禁用】按钮就变成了【启用】

- 单击【确认】按钮
4.2.6 - 访问管理
4.2.6.1 - 策略管理
策略管理
平台策略
新建策略
- 登录 TKEStack
- 切换至【平台管理】控制台,选择【访问管理】->【策略管理】
- 点击【新建】按钮,如下图所示:

- 在弹出的新建策略窗口输入策略信息。如下图所示:

- 策略名称: 长度需要小于256个字符
- 效果: 策略动作,允许/拒绝
- 服务: 选择策略应用于哪项服务
- 操作: 选择对应服务的各项操作权限
- 资源: 输入资源label,支持模糊匹配,策略将应用于匹配到的资源
- 描述: 输入策略描述
- 单击【保存】按钮
关联用户和用户组
- 登录 TKEStack
- 切换至【平台管理】控制台,选择【访问管理】->【策略管理】,查看策略列表
- 点击列表中最右侧【关联用户】或【关联用户组】按钮,如下图所示:

- 在弹出的关联用户窗口选择用户或用户组,这里以用户组为例。如下图所示:

- 单击【确定】按钮
编辑策略基本信息
- 登录 TKEStack
- 切换至【平台管理】控制台,选择【访问管理】->【策略管理】,查看策略列表
- 点击列表中的策略名称,如下图所示:

- 在策略基本信息页面,单击 “基本信息” 旁的【编辑】按钮,如下图所示:

- 在弹出的信息框内编辑策略名称和描述
- 单击【保存】按钮
业务策略
新建策略
- 登录 TKEStack
- 切换至【平台管理】控制台,选择【访问管理】->【策略管理】->【业务策略】
- 点击【新建】按钮,如下图所示:

- 在弹出的新建策略窗口输入策略信息,如下图所示:

- 策略名称: 长度需要小于256个字符
- 效果: 策略动作,允许/拒绝
- 服务: 选择策略应用于哪项服务
- 操作: 选择对应服务的各项操作权限
- 资源: 输入资源label,支持模糊匹配,策略将应用于匹配到的资源
- 描述: 输入策略描述
- 单击【保存】按钮
编辑策略基本信息
- 登录 TKEStack
- 切换至【平台管理】控制台,选择【访问管理】->【策略管理】,查看策略列表
- 点击列表中的策略名称,如下图所示:

- 在策略基本信息页面,单击 “基本信息” 旁的【编辑】按钮,如下图所示:

- 在弹出的信息框内编辑策略名称和描述
- 单击【保存】按钮
- 此页面还可以编辑策略语法
4.2.6.2 - 用户管理
用户管理
用户
新建用户
- 登录 TKEStack
- 切换至【平台管理】控制台,选择【访问管理】->【用户管理】
- 点击【新建】按钮,如下图所示:

- 在弹出的添加用户窗口填写用户信息,如下图所示:

- 用户账号: 长度3~32位字符,小写字母或数字开头结尾,中间包含小写字母、数字、-
- 用户名称: 长度需小于256字符,用户名称会显示在页面右上角
- 用户密码: 10~16位字符,需包括大小写字母及数字
- 确认密码: 再次输入密码
- 手机号: 输入用户手机号
- 邮箱: 输入用户邮箱
- 平台角色:
- 管理员: 平台预设角色,允许访问和管理所有平台和业务的功能和资源
- 平台用户: 平台预设角色,允许访问和管理大部分平台功能,可以新建集群及业务
- 租户: 平台预设角色,不绑定任何平台权限,仅能登录
- 自定义: 通过勾选下面的策略给用户自定义独立的权限
- 单击【保存】按钮
修改密码
- 登录 TKEStack
- 切换至【平台管理】控制台,选择【访问管理】->【用户管理】,查看用户列表
- 点击用户列表最右侧的【修改密码】按钮,如下图所示:

- 在弹出的修改密码窗口里输入新的密码并确认,如下图所示:

- 单击【保存】按钮
编辑用户基本信息
- 登录 TKEStack
- 切换至【平台管理】控制台,选择【访问管理】->【用户管理】,查看用户列表
- 点击列表中的用户名称,如下图所示:

- 在用户基本信息页面,单击 基本信息 旁的【编辑】按钮,如下图所示:

- 在弹出的用户信息框内编辑用户信息
- 单击【保存】按钮
- 此页面下面可以查看当前用户的 已管理策略、已关联用户组 和 已关联角色
用户组
新建用户组
- 登录 TKEStack
- 切换至【平台管理】控制台,选择【访问管理】->【用户管理】-> 【用户组】
- 点击【新建】按钮,如下图所示:

- 在弹出的添加用户窗口填写用户信息,如下图所示:

- 用户组名称: 长度需小于60位字符,小写字母或数字开头结尾,中间包含小写字母、数字、-
- 用户组描述: 长度需小于255字符
- 关联用户: 点按用户ID/名称前面的方框可以关联相应的用户,支持全选和按住shift键多选
- 平台角色:
- 管理员: 平台预设角色,允许访问和管理所有平台和业务的功能和资源
- 平台用户: 平台预设角色,允许访问和管理大部分平台功能,可以新建集群及业务
- 租户: 平台预设角色,不绑定任何平台权限,仅能登录
- 自定义: 通过勾选下面的策略给用户自定义独立的权限
- 单击【提交】按钮
编辑用户组基本信息
- 登录 TKEStack
- 切换至【平台管理】控制台,选择【访问管理】->【用户组管理】,查看用户组列表
- 点击列表中的用户组名称,如下图1所示:

此界面也可以更改关联用户,如上图中的2所示,和 新建用户组 ->添加用户组 中一样的步骤来关联用户
- 在用户组基本信息页面,单击 基本信息 旁的【编辑】按钮,如下图1所示:

在弹出的信息框内可以编辑 用户组名称 和 用户组描述,此时会出现【提交】按钮,点击后可更改用户组基本信息。
如上图中的2所示,此界面也可以更改关联用户,点击蓝色【关联用户】按钮后,和 新建用户组 ->添加用户组 中一样的操作来关联用户。这里还可以点击查看【已关联角色】和【已关联策略】
删除用户组
- 登录 TKEStack
- 切换至【平台管理】控制台,选择【访问管理】->【用户组管理】,查看用户组列表
- 点击用户组列表最右侧的【删除】按钮,如下图所示:

- 在弹出的确认删除窗口,单击【确认】
4.2.7 - 监控&告警
4.2.7.1 - 告警记录
概念
这里可以查看历史告警记录
查看历史告警记录
- 登录 TKEStack
- 切换至【平台管理】控制台,选择 【监控&告警】->【告警记录】查看“历史告警记录”列表,如下图所示:

4.2.7.2 - 通知设置
通知设置
概念
这里用户配置平台通知
通知渠道
新建通知渠道
- 登录 TKEStack
- 切换至【平台管理】控制台,选择 【监控&告警】->【通知设置】->【通知渠道】,查看“通知渠道”列表
- 点击【新建】按钮,如下图所示:

- 在“新建通知渠道”页面填写渠道信息,如下图所示:

- 名称: 填写渠道名称
- 渠道: 选择渠道类型,输入渠道信息
- 邮件: 邮件类型
- email: 邮件发送放地址
- password: 邮件发送方密码
- smtpHost: smtp IP 地址
- smtpPort: smtp 端口
- tls: 是否使用tls加密
- 短信: 短信方式
- appKey: 短信发送方的 appKey
- sdkAppID: sdkAppID
- extend: extend 信息
- 微信公众号: 微信公众号方式
- appID: 微信公众号 appID
- appSecret: 微信公众号 appSecret
- Webhook: Webhook 方式
- URL:Webhook 的 URL
- Headers: 自定义 Header
- 邮件: 邮件类型
- 单击【保存】按钮
编辑通知渠道
- 登录 TKEStack
- 切换至【平台管理】控制台,选择 【监控&告警】->【通知设置】->【通知渠道】,查看“通知渠道”列表
- 单击渠道名称,如下图所示:

- 在“基本信息”页面,单击【基本信息】右侧的【编辑】按钮,如下图所示:

- 在“更新渠道通知”页面,编辑渠道信息
- 单击【保存】按钮
删除通知渠道
- 登录 TKEStack
- 切换至【平台管理】控制台,选择 【监控&告警】->【通知设置】->【通知渠道】,查看“通知渠道”列表
- 选择要删除的渠道,点击【删除】按钮,如下图所示:

- 单击删除窗口的【确定】按钮
通知模板
新建通知模版
- 登录 TKEStack
- 切换至【平台管理】控制台,选择 【监控&告警】->【通知设置】->【通知模板】,查看“通知模板”列表
- 点击【新建】按钮,如下图所示:

- 在“新建通知模版”页面填写模版信息,如下图所示:

- 名称: 模版名称
- 渠道: 选择已创建的渠道
- body: 填写消息 body
- header: 填写消息 header
- 单击【保存】按钮
编辑通知模版
- 登录 TKEStack
- 切换至【平台管理】控制台,选择 【监控&告警】->【通知设置】->【通知模板】,查看“通知模板”列表
- 单击模版名称,如下图所示:

- 在基本信息页面,单击【基本信息】右侧的【编辑】按钮,如下图所示:

- 在“更新通知模版”页面,编辑模版信息
- 单击【保存】按钮
删除通知模版
- 登录 TKEStack
- 切换至【平台管理】控制台,选择 【监控&告警】->【通知设置】->【通知模板】,查看"通知模板"列表
- 选择要删除的模版,点击【删除】按钮,如下图所示:

- 单击删除窗口的【确定】按钮
接收人
新建接收人
- 登录 TKEStack
- 切换至【平台管理】控制台,选择 【监控&告警】->【通知设置】->【接收人】,查看"接收人"列表
- 点击【新建】按钮,如下图所示:

- 在“新建接收人”页面填写模版信息,如下图所示:

- 显示名称: 接收人显示名称
- 用户名: 接收人用户名
- 移动电话: 手机号
- 电子邮件: 接收人邮箱
- 微信OpenID: 接收人微信ID
- 单击【保存】按钮
编辑接收人信息
- 登录 TKEStack
- 切换至【平台管理】控制台,选择 【监控&告警】->【通知设置】->【接收人】,查看“接收人”列表
- 单击接收人名称,如下图所示:

- 在“基本信息”页面,单击【基本信息】右侧的【编辑】按钮,如下图所示:

- 在“更新接收人”页面,编辑接收人信息
- 单击【保存】按钮
删除接收人
- 登录 TKEStack
- 切换至【平台管理】控制台,选择 【监控&告警】->【通知设置】->【接收人】,查看“接收人”列表
- 选择要删除的接收人,点击【删除】按钮,如下图所示:

- 单击删除窗口的【确定】按钮
接收组
新建接收组
- 登录 TKEStack
- 切换至【平台管理】控制台,选择 【监控&告警】->【通知设置】->【接收组】,查看“接收组”列表
- 点击【新建】按钮,如下图所示:

- 在“新建接收组”页面填写模版信息,如下图所示:

- 名称: 接收组显示名称
- 接收组: 从列表里选择接收人。如没有想要的接收人,请在接收人里创建
- 单击【保存】按钮
编辑接收组信息
- 登录 TKEStack
- 切换至【平台管理】控制台,选择 【监控&告警】->【通知设置】->【接收组】,查看“接收组”列表
- 单击接收组名称,如下图所示:

- 在“基本信息”页面,单击【基本信息】右侧的【编辑】按钮,如下图所示:

- 在“更新接收组”页面,编辑接收组信息
- 单击【保存】按钮
删除接收组
- 登录 TKEStack
- 切换至【平台管理】控制台,选择 【监控&告警】->【通知设置】->【接收组】,查看“接收组”列表
- 选择要删除的接收组,点击【删除】按钮,如下图所示:

- 单击删除窗口的【确定】按钮
4.2.7.3 - 告警设置
告警设置
概念
这里用户配置平台告警
前提条件
需要设置告警的集群应该先在其 基本信息 页里开启监控告警
新建告警设置
- 登录 TKEStack
- 切换至【平台管理】控制台,选择 【监控&告警】下的【告警设置】,查看“告警设置”列表
- 选择相应【集群】,点击【新建】按钮,如下图所示:

- 在“新建策略”页面填写告警策略信息,如下图所示:

- 告警策略名称: 输入告警策略名称,最长60字符
- 策略类型: 选择告警策略应用类型
- 集群: 集群监控告警
- Pod: Pod 监控告警
- 告警对象: 选择 Pod 相关的告警对象,支持对 namespace 下不同的 deployment、stateful和daemonset 进行监控报警
- 按工作负载选择: 选择 namespace 下的某个工作负载
- 全部选择: 不区分 namespace,全部监控
- 告警对象: 选择 Pod 相关的告警对象,支持对 namespace 下不同的 deployment、stateful和daemonset 进行监控报警
- 节点: 节点监控告警
- 统计周期: 选择数据采集周期,支持1、2、3、4、5分钟
- 指标: 选择告警指标,支持对监测值与指标值进行【大于/小于】比较,选择结果持续周期,如下图。指标具体含义可参考:[监控&告警指标含义](../../../../FAQ/Platform/alert&monitor-metrics)

- 接收组: 选择接收组,当出现满足条件当报警信息时,向组内人员发送消息。接收组需要先在 用户管理 创建
- 通知方式: 选择通知渠道和消息模版。通知渠道 和 消息模版需要先在 通知设置 创建
- 添加通知方式 :如需要添加多种通知方式,点击该按钮
- 单击【提交】按钮
复制告警设置
- 登录 TKEStack
- 切换至【平台管理】控制台,选择 【监控&告警】下的【告警设置】,查看“告警设置”列表
- 选择相应【集群】,点击告警设置列表最右侧的【复制】按钮,如下图所示:

- 在“复制策略”页面,编辑告警策略信息
- 单击【提交】按钮
编辑告警设置
- 登录 TKEStack
- 切换至【平台管理】控制台,选择 【监控&告警】下的【告警设置】,查看“告警设置”列表
- 选择相应【集群】,点击【告警名称】,如下图所示:

- 在“告警策略详情”页面,单击【基本信息】右侧的【编辑】按钮,如下图所示:

- 在“更新策略”页面,编辑策略信息
- 单击【提交】按钮
删除告警设置
- 登录 TKEStack
- 切换至【平台管理】控制台,选择 【监控&告警】下的【告警设置】,查看“告警设置”列表
- 选择相应【集群】,点击列表最右侧的【删除】按钮,如下图所示:

- 在弹出的删除告警窗口,单击【确定】按钮
批量删除告警设置
- 登录 TKEStack
- 切换至【平台管理】控制台,选择 【监控&告警】下的【告警设置】,查看“告警设置”列表
- 选择相应【集群】,选择多个告警策略,单击告警设置下方的【删除】按钮。如下图所示:

- 在弹出的删除告警窗口,单击【确定】按钮
4.2.8 - 运维中心
运维中心
概念
这里用户可以管理 Helm 应用、日志和集群事件持久化。
4.2.8.1 - Helm应用
应用功能是 TKEStack 集成的 Helm 3.0 相关功能,为您提供创建 helm chart、容器镜像、软件服务等各种产品和服务的能力。已创建的应用将在您指定的集群中运行,为您带来相应的能力。
新建 Helm 应用
- 登录 TKEStack
- 切换至【平台管理】控制台,选择【运维中心】->【 Helm 应用】
- 选择相应【集群】,单击【新建】按钮,如下图所示:

- 在“新建 Helm 应用”页面填写Helm应用信息,如下图所示:

- 应用名称: 输入应用名,1~63字符,只能包含小写字母、数字及分隔符("-"),且必须以小写字母开头,数字或小写字母结尾
- 运行集群: 选择应用所在集群
- 命名空间: 选择应用所在集群的命名空间
- 类型: 当前仅支持 HelmV3
- Chart: 选择需要部署的 chart
- Chart版本: 选择 chart 的版本
- 参数: 更新时如果选择不同版本的 Helm Chart,参数设置将被覆盖
- 拟运行: 会返回模板渲染清单,即最终将部署到集群的 YAML 资源,不会真正执行安装
- 单击【完成】按钮
删除 Helm 应用
- 登录 TKEStack
- 切换至【平台管理】控制台,选择【运维中心】->【 Helm 应用】
- 点击【删除】

查看 Helm 应用资源列表
- 登录 TKEStack
- 切换至【平台管理】控制台,选择【运维中心】->【 Helm 应用】
- 点击【应用名】后,点击【资源列表】,可查看该应用所有 Kubernetes 资源对象
查看 Helm 应用详情
- 登录 TKEStack
- 切换至【平台管理】控制台,选择【运维中心】->【 Helm 应用】
- 点击【应用名】后,点击【应用详情】

查看 Helm 应用版本历史
- 登录 TKEStack
- 切换至【平台管理】控制台,选择【运维中心】->【 Helm 应用】
- 点击【应用名】后,点击【版本历史】,可查看该应用所部署的历史版本。可以通过选择不同的版本进行参数对比查看其版本区别

4.2.8.2 - 日志采集
日志采集
概念
TKESTack 提供的集群内日志采集功能,支持将集群内服务或集群节点特定路径文件的日志发送至 Kafka、Elasticsearch 等消费端,支持采集容器标准输出日志,容器内文件日志以及主机内文件日志。更提供事件持久化、审计等功能,实时记录集群事件及操作日志记录,帮助运维人员存储和分析集群内部资源生命周期、资源调度、异常告警等情况。

日志收集功能需要为每个集群手动开启。日志收集功能开启后,日志收集组件 logagent 会在集群内以 Daemonset 的形式运行。用户可以通过日志收集规则配置日志的采集源和消费端,日志收集 Agent 会从用户配置的采集源进行日志收集,并将日志内容发送至用户指定的消费端。需要注意的是,使用日志收集功能需要您确认 Kubernetes 集群内节点能够访问日志消费端。
- 采集容器标准输出日志 :采集集群内指定容器的标准输出日志,采集到的日志信息将会以 JSON 格式输出到用户指定的消费端,并会自动附加相关的 Kubernetes metadata, 包括容器所属 pod 的 label 和 annotation 等信息。
- 采集容器内文件日志 :采集集群内指定 pod 内文件的日志,用户可以根据自己的需求,灵活的配置所需的容器和路径,采集到的日志信息将会以 JSON 格式输出到用户指定的消费端, 并会附加相关的 Kubernetes metadata,包括容器所属 pod 的 label 和 annotation 等信息。
- 采集主机内文件日志 :采集集群内所有节点的指定主机路径的日志,logagent 会采集集群内所有节点上满足指定路径规则的文件日志,以 JSON 格式输出到用户指定的输出端, 并会附加用户指定的 metadata,包括日志来源文件的路径和用户自定义的 metadata。
注意:日志采集对接外部 Kafka 或 Elasticsearch,该功能需要额外开启,位置在集群 基本信息 下面,点击开启“日志采集”服务。

新建日志采集规则
- 登录 TKEStack
- 切换至【平台管理】控制台,选择 【运维中心】->【日志采集】
- 选择相应【集群】和【命名空间】,单击【新建】按钮,如下图所示:

- 在“新建日志采集”页面填写日志采集信息,如下图所示:

- 收集规则名称: 输入规则名,1~63字符,只能包含小写字母、数字及分隔符("-"),且必须以小写字母开头,数字或小写字母结尾
- 所属集群: 选择所属集群
- 类型: 选择采集类型
- 容器标准输出: 容器Stdout信息采集
- 日志源: 可以选择所有容器或者某个namespace下的所有容器/工作负载
- 所有容器: 所有容器
- 指定容器: 某个Namespace下的所有容器或者工作负载
- 日志源: 可以选择所有容器或者某个namespace下的所有容器/工作负载
- 容器文件路径: 容器内文件内容采集
- 日志源: 可以采集具体容器内的某个文件路径下的文件内容
- 工作负载选项: 选择某个namespace下的某种工作负载类型下的某个工作负载
- 配置采集路径: 选择某个容器下的某个文件路径
- 日志源: 可以采集具体容器内的某个文件路径下的文件内容
- 节点文件路径: 收集节点上某个路径下的文件内容
- 日志源:
- 收集路径: 节点上日志收集路径
- metadata: key:value格式,收集的日志会带上metadata信息上报给消费端
- 日志源:
- 容器标准输出: 容器Stdout信息采集
- 消费端: 选择日志消费端
Kafka:
- 访问地址: kafka ip 和端口
- 主题(Topic): kafka topic 名
Elasticsearch:
注意:当前只支持未开启用户登录认证的 ES 集群
- Elasticsearch地址: ES 地址,如:http://190.0.0.1:200
- 索引: ES索引,最长60个字符,只能包含小写字母、数字及分隔符("-"、"_"、"+"),且必须以小写字母开头
- 单击【完成】按钮
指定容器运行后的日志目录
LogAgent 除了支持日志规则的创建,也支持指定容器运行后的日志目录,可实现日志文件展示和下载。
前提:需要在创建负载时挂载数据卷,并指定日志目

创建负载以后,在/data/logdir目录下的所有文件可以展示并下载,不仅是日志文件,例如我们在容器的/data/logdir下新建一个名为a.log的文件,如果有内容的话,也可以在这里展示与下载

4.2.8.3 - 审计记录
简介
TKEStack 集群审计是基于 Kubernetes Audit 对 kube-apiserver 产生的可配置策略的 JSON 结构日志的记录存储及检索功能。本功能记录了对 kube-apiserver 的访问事件,会按顺序记录每个用户、管理员或系统组件影响集群的活动。
功能优势
集群审计功能提供了区别于 metrics 的另一种集群观测维度。开启 TKEStack 集群审计后,会在集群里的 tke 命名空间下生成 tke-audit-api 的 Deployment,Kubernetes 可以记录每一次对集群操作的审计日志。每一条审计日志是一个 JSON 格式的结构化记录,包括元数据(metadata)、请求内容(requestObject)和响应内容(responseObject)三个部分。其中元数据(包含了请求的上下文信息,例如谁发起的请求、从哪里发起的、访问的 URI 等信息)一定会存在,请求和响应内容是否存在取决于审计级别。通过日志可以了解到以下内容:
- 集群里发生的活动
- 活动的发生时间及发生对象。
- 活动的触发时间、触发位置及观察点
- 活动的结果以及后续处理行为
阅读审计日志
{
"kind":"Event",
"apiVersion":"audit.k8s.io/v1",
"level":"RequestResponse",
"auditID":0a4376d5-307a-4e16-a049-24e017******,
"stage":"ResponseComplete",
// 发生了什么
"requestURI":"/apis/apps/v1/namespaces/default/deployments",
"verb":"create",
// 谁发起的
"user":{
"username":"admin",
"uid":"admin",
"groups":[
"system:masters",
"system:authenticated"
]
},
// 从哪里发起
"sourceIPs":[
"10.0.6.68"
],
"userAgent":"kubectl/v1.16.3 (linux/amd64) kubernetes/ald64d8",
// 发生了什么
"objectRef":{
"resource":"deployments",
"namespace":"default",
"name":"nginx-deployment",
"apiGroup":"apps",
"apiVersion":"v1"
},
// 结果是什么
"responseStatus":{
"metadata":{
},
"code":201
},
// 请求及返回具体信息
"requestObject":Object{...},
"responseObject":Object{...},
// 什么时候开始/结束
"requestReceivedTimestamp":"2020-04-10T10:47:34.315746Z",
"stageTimestamp":"2020-04-10T10:47:34.328942Z",
// 请求被接收/拒绝的原因是什么
"annotations":{
"authorization.k8s.io/decision":"allow",
"authorization.k8s.io/reason":""
}
}
前提条件
在 Installer 安装页面的控制台安装的第5步中,如下图所示,已经开启平台审计功能,并配置好 ElasticSearch:
查看审计
- 登录 TKEStack
- 切换至【平台管理】控制台,选择 【运维中心】->【审计记录】,查看审计列表:

参考
TKEStack 关于审计的相关配置:
# kube-apiserver 地址:/etc/kubernetes/manifests/kube-apiserver.yaml
--audit-policy-file=/etc/kubernetes/audit-policy.yaml # 审计策略
--audit-webhook-config-file=/etc/kubernetes/audit-api-client-config.yaml # 指定 Webhook backend 的配置文件
# 获取 TKEStack 审计组件的详细信息
kubectl describe deploy -ntke tke-audit-api
# 获取 TKEStack 审计的相关配置
kubectl describe cm -ntke tke-audit-api
4.2.8.4 - 事件持久化
PersistentEvent
PersistentEvent 介绍
Kubernetes Events 包括了 Kuberntes 集群的运行和各类资源的调度情况,对维护人员日常观察资源的变更以及定位问题均有帮助。TKEStack 支持为您的所有集群配置事件持久化功能,开启本功能后,会将您的集群事件实时导出到 ElasticSearch 的指定索引。
PersistentEvent 使用场景
Kubernetes 事件是集群内部资源生命周期、资源调度、异常告警等情况产生的记录,可以通过事件深入了解集群内部发生的事情,例如调度程序做出的决策或者某些pod从节点中被逐出的原因。
kubernetes 默认仅提供保留一个小时的 kubernetes 事件到集群的 ETCD 里。 PersistentEvent 提供了将 Kubernetes 事件持久化存储的前置功能,允许您通过PersistentEvent 将集群内事件导出到您自有的存储端。
PersistentEvent 限制条件
- 注意:当前只支持版本号为5的 ElasticSearch,且未开启 ElasticSearch 集群的用户登录认证
- 安装 PersistentEvent 将占用集群0.2核 CPU,100MB 内存的资源
- 仅在1.8版本以上的 kubernetes 集群支持
部署在集群内kubernetes对象
在集群内部署PersistentEvent Add-on , 将在集群内部署以下kubernetes对象
| kubernetes对象名称 | 类型 | 默认占用资源 | 所属Namespaces |
|---|---|---|---|
| tke-persistent-event | deployment | 0.2核CPU,100MB内存 | kube-system |
PersistentEvent 使用方法
在 扩展组件 里使用
登录 TKEStack
切换至【平台管理】控制台,选择 【扩展组件】,选择需要安装事件持久化组件的集群,安装 PersistentEvent 组件,注意安装 PersistentEvent 时需要在页面下方指定 ElasticSearch 的地址和索引
注意:当前只支持版本号为5,且未开启用户登录认证的 ES 集群
在 运维中心 里使用
- 登录 TKEStack
- 切换至【平台管理】控制台,选择 【运维中心】->【事件持久化】,查看事件持久化列表
- 单击列表最右侧【设置】按钮,如下图所示:

- 在“设置事件持久化”页面填写持久化信息
事件持久化存储: 是否进行持久化存储
注意:当前只支持版本号为5,且未开启用户登录认证的 ES 集群
Elasticsearch地址: ES 地址,如:http://190.0.0.1:200
索引: ES索引,最长60个字符,只能包含小写字母、数字及分隔符("-"、"_"、"+"),且必须以小写字母开头
- 单击【完成】按钮
4.3 - 业务管理控制台
业务管理控制台
4.3.1 - 应用管理
应用管理
4.3.1.1 - 命名空间
Namespaces 是 Kubernetes 在同一个集群中进行逻辑环境划分的对象, 您可以通过 Namespaces 进行管理多个团队多个项目的划分。在 Namespaces 下,Kubernetes 对象的名称必须唯一。您可以通过资源配额进行可用资源的分配,还可以进行不同 Namespaces 网络的访问控制。
使用方法
- 通过 TKEStack 控制台使用:TKEStack 控制台提供 Namespaces 的增删改查功能。
- 【业务管理】平台下不支持对命名空间的直接操作,需在【平台管理】下【业务管理】中指定业务通过“创建业务下的命名空间”来实现。
- 通过 Kubectl 使用:更多详情可查看 Kubernetes 官网文档。
相关知识
通过 ResourceQuota 设置 Namespaces 资源的使用配额
一个命名空间下可以拥有多个 ResourceQuota 资源,每个 ResourceQuota 可以设置每个 Namespace 资源的使用约束。可以设置 Namespaces 资源的使用约束如下:
- 计算资源的配额,例如 CPU、内存。
- 存储资源的配额,例如请求存储的总存储。
- Kubernetes 对象的计数,例如 Deployment 个数配额。
不同的 Kubernetes 版本,ResourceQuota 支持的配额设置略有差异,更多详情可查看 Kubernetes ResourceQuota 官方文档。 ResourceQuota 的示例如下所示:
apiVersion: v1
kind: ResourceQuota
metadata:
name: object-counts
namespace: default
spec:
hard:
configmaps: "10" ## 最多10个 ConfigMap
replicationcontrollers: "20" ## 最多20个 replicationcontroller
secrets: "10" ## 最多10个 secret
services: "10" ## 最多10个 service
services.loadbalancers: "2" ## 最多2个 Loadbanlacer 模式的 service
cpu: "1000" ## 该 Namespaces 下最多使用1000个 CPU 的资源
memory: 200Gi ## 该 Namespaces 下最多使用200Gi的内存
4.3.1.2 - 工作负载
工作负载
4.3.1.2.1 - Deployment
Deployment 声明了 Pod 的模板和控制 Pod 的运行策略,适用于部署无状态的应用程序。您可以根据业务需求,对 Deployment 中运行的 Pod 的副本数、调度策略、更新策略等进行声明。
Deployment 控制台操作指引
创建 Deployment
- 登录TKEStack,切换到【业务管理】控制台,选择左侧导航栏中的【应用管理】。
- 选择需要创建Deployment的【业务】下相应的【命名空间】,展开【工作负载】下拉项,进入【Deployment】管理页面。如下图所示:

- 单击【新建】,进入 “新建Workload” 页面。根据实际需求,设置 Deployment 参数。关键参数信息如下,其中必填项为工作负载名、实例内容器的名称和镜像:
- 工作负载名:输入自定义名称。
- 标签:给工作负载添加标签
- 命名空间:根据实际需求进行选择。
- 类型:选择【Deployment(可扩展的部署 Pod)】。
- 数据卷:根据需求,为负载添加数据卷为容器提供存,目前支持临时路径、主机路径、云硬盘数据卷、文件存储NFS、配置文件、PVC,还需挂载到容器的指定路径中
- 临时目录:主机上的一个临时目录,生命周期和Pod一致
- 主机路径:主机上的真实路径,可以重复使用,不会随Pod一起销毁
- NFS盘:挂载外部NFS到Pod,用户需要指定相应NFS地址,格式:127.0.0.1:/data
- ConfigMap:用户在业务Namespace下创建的ConfigMap
- Secret:用户在业务namespace下创建的Secret
- PVC:用户在业务namespace下创建的PVC
- 实例内容器:根据实际需求,为 Deployment 的一个 Pod 设置一个或多个不同的容器。

- 名称:自定义
- 镜像:根据实际需求进行选择
镜像版本(Tag):根据实际需求进行填写,不填默认为
latestCPU/内存限制:可根据 Kubernetes 资源限制 进行设置 CPU 和内存的限制范围,提高业务的健壮性(建议使用默认值)
GPU限制:如容器内需要使用GPU,此处填GPU需求
环境变量:用于设置容器内的变量,变量名只能包含大小写字母、数字及下划线,并且不能以数字开头
新增变量:自己设定变量键值对
引用ConfigMap/Secret:引用已有键值对
高级设置:可设置 “工作目录”、“运行命令”、“运行参数”、“镜像更新策略”、“容器健康检查”和“特权级”等参数。这里介绍一下镜像更新策略。
镜像更新策略:提供以下3种策略,请按需选择
若不设置镜像拉取策略,当镜像版本为空或
latest时,使用 Always 策略,否则使用 IfNotPresent 策略- Always:总是从远程拉取该镜像
- IfNotPresent:默认使用本地镜像,若本地无该镜像则远程拉取该镜像
- Never:只使用本地镜像,若本地没有该镜像将报异常
- 实例数量:根据实际需求选择调节方式,设置实例数量。

- 手动调节:直接设定实例个数
- 自动调节:根据设定的触发条件自动调节实例个数,目前支持根据CPU、内存利用率和利用量出入带宽等调节实例个数
- 定时调节:根据Crontab 语法周期性设置实例个数
- imagePullSecrets:镜像拉取密钥,用于拉取用户的私有镜像
- 节点调度策略:根据配置的调度规则,将Pod调度到预期的节点。支持指定节点调度和条件选择调度
- 注释(Annotations):给Deployment添加相应Annotation,如用户信息等
- 网络模式:选择Pod网络模式
- OverLay(虚拟网络):基于 IPIP 和 Host Gateway 的 Overlay 网络方案
- FloatingIP(浮动 IP):支持容器、物理机和虚拟机在同一个扁平面中直接通过IP进行通信的 Underlay 网络方案。提供了 IP 漂移能力,支持 Pod 重启或迁移时 IP 不变
- NAT(端口映射):Kubernetes 原生 NAT 网络方案
- Host(主机网络):Kubernetes 原生 Host 网络方案
- Service:勾选【启用】按钮,配置负载端口访问

服务访问方式:选择是【仅在集群内部访问】该负载还是集群外部通过【主机端口访问】该负载
- 仅在集群内访问:使用 Service 的 ClusterIP 模式,自动分配 Service 网段中的 IP,用于集群内访问。数据库类等服务如 MySQL 可以选择集群内访问,以保证服务网络隔离
- 主机端口访问:提供一个主机端口映射到容器的访问方式,支持 TCP、UDP、Ingress。可用于业务定制上层 LB 转发到 Node
- Headless Service:不创建用于集群内访问的ClusterIP,访问Service名称时返回后端Pods IP地址,用于适配自有的服务发现机制。解析域名时返回相应 Pod IP 而不是 Cluster IP
端口映射:输入负载要暴露的端口并指定通信协议类型(容器和服务端口建议都使用80)
Session Affinity: 点击【显示高级设置】出现,会话保持,设置会话保持后,会根据请求IP把请求转发给这个IP之前访问过的Pod。默认None,按需使用
单击【创建Workload】,完成创建。如下图所示:
当“运行/期望Pod数量”相等时,即表示 Deployment 下的所有 Pod 已创建完成。

更新 Deployment
更新 YAML
- 登录TKEStack,切换到【业务管理】控制台,选择左侧导航栏中的【应用管理】。
- 选择需要更新的【业务】下相应的【命名空间】,展开【工作负载】列表,进入【Deployment】管理页面。如下图所示:

- 在需要更新 YAML 的 Deployment 行中,单击【更多】>【编辑YAML】,进入“更新 Deployment” 页面。如下图所示:

- 在 “更新Deployment” 页面,编辑 YAML,单击【完成】,即可更新 YAML。如下图所示:

回滚 Deployment
- 登录 TKEStack,切换到【业务管理】控制台,选择左侧导航栏中的【应用管理】。
- 选择要变更的业务下相应的【命名空间】,展开【工作负载】列表,进入【 Deployment】 管理页面,点击进入要回滚的 Deployment 详情页面,单击【修订历史】。如下图所示:

- 选择合适版本进行回顾。
- 在弹出的 “回滚资源” 提示框中,单击【确定】即可完成回滚。
调整 Pod 数量
- 登录 TKEStack,切换到【业务管理】控制台,选择左侧导航栏中的【应用管理】。
- 选择要变更的业务下相应的命名空间,展开工作负载列表,进入 Deployment 管理页面。
- 点击 Deployment 列表操作栏的【更新实例数量】按钮。如下图所示:

- 根据实际需求调整 Pod 数量,单击【更新实例数目】即可完成调整。
查看Deployment监控数据
- 登录 TKEStack,切换到【业务管理】控制台,选择左侧导航栏中的【应用管理】,。
- 选择要变更的业务下相应的【命名空间】,点击进入 【Deployment】 管理页面。
- 单击【监控】按钮,在弹出的工作负载监控页面选择工作负载查看监控信息。如下图所示:

Kubectl 操作 Deployment 指引
YAML 示例
apiVersion: apps/v1beta2
kind: Deployment
metadata:
name: nginx-deployment
namespace: default
labels:
app: nginx-deployment
spec:
replicas: 3
selector:
matchLabels:
app: nginx-deployment
template:
metadata:
labels:
app: nginx-deployment
spec:
containers:
- name: nginx
image: nginx:latest
ports:
- containerPort: 80
- kind:标识 Deployment 资源类型。
- metadata:Deployment 的名称、Namespace、Label 等基本信息。
- metadata.annotations:对 Deployment 的额外说明,可通过该参数设置腾讯云 TKE 的额外增强能力。
- spec.replicas:Deployment 管理的 Pod 数量。
- spec.selector:Deployment 管理 Seletor 选中的 Pod 的 Label。
- spec.template:Deployment 管理的 Pod 的详细模板配置。
更多参数详情可查看 Kubernetes Deployment 官方文档。
Kubectl 创建 Deployment
参考 YAML 示例,准备 Deployment YAML 文件。
安装 Kubectl,并连接集群。操作详情请参考 通过 Kubectl 连接集群。
执行以下命令,创建 Deployment YAML 文件。
kubectl create -f 【Deployment YAML 文件名称】例如,创建一个文件名为 nginx.Yaml 的 Deployment YAML 文件,则执行以下命令:
kubectl create -f nginx.yaml执行以下命令,验证创建是否成功。
kubectl get deployments返回类似以下信息,即表示创建成功。
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE first-workload 1 1 1 0 6h ng 1 1 1 1 42m
Kubectl 更新 Deployment
通过 Kubectl 更新 Deployment 有以下三种方法。其中,方法一 和 方法二 均支持 Recreate 和 RollingUpdate 两种更新策略。
- Recreate 更新策略为先销毁全部 Pod,再重新创建 Deployment。
- RollingUpdate 更新策略为滚动更新策略,逐个更新 Deployment 的 Pod。RollingUpdate 还支持暂停、设置更新时间间隔等。
方法一
执行以下命令,更新 Deployment。
kubectl edit deployment/【name】
此方法适用于简单的调试验证,不建议在生产环境中直接使用。您可以通过此方法更新任意的 Deployment 参数。
方法二
执行以下命令,更新指定容器的镜像。
kubectl set image deployment/【name】 【containerName】=【image:tag】
建议保持 Deployment 的其他参数不变,业务更新时,仅更新容器镜像。
方法三
执行以下命令,滚动更新指定资源。
kubectl rolling-update 【NAME】 -f 【FILE】
更多滚动更新可参见 滚动更新说明。
Kubectl 回滚 Deployment
执行以下命令,查看 Deployment 的更新历史。
kubectl rollout history deployment/【name】执行以下命令,查看指定版本详情。
kubectl rollout history deployment/【name】 --revision=【REVISION】执行以下命令,回滚到前一个版本。
kubectl rollout undo deployment/【name】如需指定回滚版本号,可执行以下命令。
kubectl rollout undo deployment/【name】 --to-revision=【REVISION】
Kubectl 调整 Pod 数量
手动更新 Pod 数量
执行以下命令,手动更新 Pod 数量。
kubectl scale deployment 【NAME】 --replicas=【NUMBER】
自动更新 Pod 数量
前提条件
开启集群中的 HPA 功能。TKE 创建的集群默认开启 HPA 功能。
操作步骤
执行以下命令,设置 Deployment 的自动扩缩容。
kubectl autoscale deployment 【NAME】 --min=10 --max=15 --cpu-percent=80
Kubectl 删除 Deployment
执行以下命令,删除 Deployment。
kubectl delete deployment 【NAME】
4.3.1.2.2 - StatefulSet
StatefulSet 主要用于管理有状态的应用,创建的 Pod 拥有根据规范创建的持久型标识符。Pod 迁移或销毁重启后,标识符仍会保留。 在需要持久化存储时,您可以通过标识符对存储卷进行一一对应。如果应用程序不需要持久的标识符,建议您使用 Deployment 部署应用程序。
StatefulSet 控制台操作指引
创建 StatefulSet
- 登录TKEStack,切换到【业务管理】控制台,选择左侧导航栏中的【应用管理】。
- 选择需要创建StatefulSet的【业务】下相应的【命名空间】,展开【工作负载】下拉项,进入【StatefulSet】管理页面。如下图所示:

单击【新建】,进入 “新建Workload” 页面。根据实际需求,设置 StatefulSet 参数。
关键参数信息如下,其中必填项为工作负载名、实例内容器的名称和镜像:
- 工作负载名:输入自定义名称。
- 标签:给工作负载添加标签
- 命名空间:根据实际需求进行选择。
- 类型:选择【StatefulSet】。
- 数据卷:根据需求,为负载添加数据卷为容器提供存,目前支持临时路径、主机路径、云硬盘数据卷、文件存储NFS、配置文件、PVC,还需挂载到容器的指定路径中
- 临时目录:主机上的一个临时目录,生命周期和Pod一致
- 主机路径:主机上的真实路径,可以重复使用,不会随Pod一起销毁
- NFS盘:挂载外部NFS到Pod,用户需要指定相应NFS地址,格式:127.0.0.1:/data
- ConfigMap:用户在业务Namespace下创建的ConfigMap
- Secret:用户在业务namespace下创建的Secret
- PVC:用户在业务namespace下创建的PVC
- 实例内容器:根据实际需求,为 StatefulSet的一个 Pod 设置一个或多个不同的容器。
- 名称:自定义
- 镜像:根据实际需求进行选择
- 镜像版本(Tag):根据实际需求进行填写,不填默认为
latest - CPU/内存限制:可根据 Kubernetes 资源限制 进行设置 CPU 和内存的限制范围,提高业务的健壮性(建议使用默认值)
- GPU限制:如容器内需要使用GPU,此处填GPU需求
- 环境变量:用于设置容器内的变量,变量名只能包含大小写字母、数字及下划线,并且不能以数字开头
- 新增变量:自己设定变量键值对
- 引用ConfigMap/Secret:引用已有键值对
- 高级设置:可设置 “工作目录”、“运行命令”、“运行参数”、“镜像更新策略”、“容器健康检查”和“特权级”等参数。这里介绍一下镜像更新策略。
镜像更新策略:提供以下3种策略,请按需选择
若不设置镜像拉取策略,当镜像版本为空或
latest时,使用 Always 策略,否则使用 IfNotPresent 策略- Always:总是从远程拉取该镜像
- IfNotPresent:默认使用本地镜像,若本地无该镜像则远程拉取该镜像
- Never:只使用本地镜像,若本地没有该镜像将报异常
- 镜像版本(Tag):根据实际需求进行填写,不填默认为
- 实例数量:根据实际需求选择调节方式,设置实例数量。
- 手动调节:直接设定实例个数
- 自动调节:根据设定的触发条件自动调节实例个数,目前支持根据CPU、内存利用率和利用量出入带宽等调节实例个数
- 定时调节:根据Crontab 语法周期性设置实例个数
- imagePullSecrets:镜像拉取密钥,用于拉取用户的私有镜像
- 节点调度策略:根据配置的调度规则,将Pod调度到预期的节点。支持指定节点调度和条件选择调度
- 注释(Annotations):给StatefulSet添加相应Annotation,如用户信息等
- 网络模式:选择Pod网络模式
- OverLay(虚拟网络):基于 IPIP 和 Host Gateway 的 Overlay 网络方案
- FloatingIP(浮动 IP):支持容器、物理机和虚拟机在同一个扁平面中直接通过IP进行通信的 Underlay 网络方案。提供了 IP 漂移能力,支持 Pod 重启或迁移时 IP 不变
- NAT(端口映射):Kubernetes 原生 NAT 网络方案
- Host(主机网络):Kubernetes 原生 Host 网络方案
- Service:勾选【启用】按钮,配置负载端口访问
注意:如果不勾选【启用】则不会创建Service
服务访问方式:选择是【仅在集群内部访问】该负载还是集群外部通过【主机端口访问】该负载
- 仅在集群内访问:使用 Service 的 ClusterIP 模式,自动分配 Service 网段中的 IP,用于集群内访问。数据库类等服务如 MySQL 可以选择集群内访问,以保证服务网络隔离
- 主机端口访问:提供一个主机端口映射到容器的访问方式,支持 TCP、UDP、Ingress。可用于业务定制上层 LB 转发到 Node
- Headless Service:不创建用于集群内访问的ClusterIP,访问Service名称时返回后端Pods IP地址,用于适配自有的服务发现机制。解析域名时返回相应 Pod IP 而不是 Cluster IP
端口映射:输入负载要暴露的端口并指定通信协议类型(容器和服务端口建议都使用80)
Session Affinity: 点击【显示高级设置】出现,会话保持,设置会话保持后,会根据请求IP把请求转发给这个IP之前访问过的Pod。默认None,按需使用
单击【创建Workload】,完成创建。
更新 StatefulSet
更新 YAML
- 登录TKEStack,切换到【业务管理】控制台,选择左侧导航栏中的【应用管理】。
- 选择需要更新的【业务】下相应的【命名空间】,展开【工作负载】列表,进入【StatefulSet】管理页面。
- 在需要更新 YAML 的 StatefulSet 行中,选择【更多】>【编辑YAML】,进入更新 StatefulSet 页面。
- 在 “更新StatefulSet” 页面编辑 YAML,并单击【完成】即可更新 YAML。
Kubectl 操作 StatefulSet 指引
YAML 示例
apiVersion: v1
kind: Service ## 创建一个 Headless Service,用于控制网络域
metadata:
name: nginx
namespace: default
labels:
app: nginx
spec:
ports:
- port: 80
name: web
clusterIP: None
selector:
app: nginx
---
apiVersion: apps/v1
kind: StatefulSet ### 创建一个 Nginx的StatefulSet
metadata:
name: web
namespace: default
spec:
selector:
matchLabels:
app: nginx
serviceName: "nginx"
replicas: 3 # by default is 1
template:
metadata:
labels:
app: nginx
spec:
terminationGracePeriodSeconds: 10
containers:
- name: nginx
image: nginx:latest
ports:
- containerPort: 80
name: web
volumeMounts:
- name: www
mountPath: /usr/share/nginx/html
volumeClaimTemplates:
- metadata:
name: www
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "cbs"
resources:
requests:
storage: 10Gi
- kind:标识 StatefulSet 资源类型。
- metadata:StatefulSet 的名称、Label等基本信息。
- metadata.annotations:对 StatefulSet 的额外说明,可通过该参数设置腾讯云 TKE 的额外增强能力。
- spec.template:StatefulSet 管理的 Pod 的详细模板配置。
- spec.volumeClaimTemplates:提供创建 PVC&PV 的模板。
更多参数详情可查看 Kubernetes StatefulSet 官方文档。
创建 StatefulSet
参考 YAML 示例,准备 StatefulSet YAML 文件。
安装 Kubectl,并连接集群。操作详情请参考 通过 Kubectl 连接集群。
执行以下命令,创建 StatefulSet YAML 文件。
kubectl create -f StatefulSet YAML 文件名称例如,创建一个文件名为 web.yaml 的 StatefulSet YAML 文件,则执行以下命令:
kubectl create -f web.yaml执行以下命令,验证创建是否成功。
kubectl get StatefulSet返回类似以下信息,即表示创建成功。
NAME DESIRED CURRENT AGE test 1 1 10s
更新 StatefulSet
执行以下命令,查看 StatefulSet 的更新策略类型。
kubectl get ds/<daemonset-name> -o go-template='{{.spec.updateStrategy.type}}{{"\n"}}'
StatefulSet 有以下两种更新策略类型:
- OnDelete:默认更新策略。该更新策略在更新 StatefulSet 后,需手动删除旧的 StatefulSet Pod 才会创建新的 StatefulSet Pod。
- RollingUpdate:支持 Kubernetes 1.7或更高版本。该更新策略在更新 StatefulSet 模板后,旧的 StatefulSet Pod 将被终止,并且以滚动更新方式创建新的 StatefulSet Pod(Kubernetes 1.7或更高版本)。
方法一
执行以下命令,更新 StatefulSet。
kubectl edit StatefulSet/[name]
此方法适用于简单的调试验证,不建议在生产环境中直接使用。您可以通过此方法更新任意的 StatefulSet 参数。
方法二
执行以下命令,更新指定容器的镜像。
kubectl patch statefulset <NAME> --type='json' -p='[{"op": "replace", "path": "/spec/template/spec/containers/0/image", "value":"<newImage>"}]'
建议保持 StatefulSet 的其他参数不变,业务更新时,仅更新容器镜像。
如果更新的 StatefulSet 是滚动更新方式的策略,可执行以下命令查看更新状态:
kubectl rollout status sts/<StatefulSet-name>
删除 StatefulSet
执行以下命令,删除 StatefulSet。
kubectl delete StatefulSet [NAME] --cascade=false
–cascade=false 参数表示 Kubernetes 仅删除 StatefulSet,且不删除任何 Pod。如需删除 Pod,则执行以下命令:
kubectl delete StatefulSet [NAME]
更多 StatefulSet 相关操作可查看 Kubernetes官方指引。
4.3.1.2.3 - DaomonSet
DaomonSet
DaemonSet 主要用于部署常驻集群内的后台程序,例如节点的日志采集。DaemonSet 保证在所有或部分节点上均运行指定的 Pod。 新节点添加到集群内时,也会有自动部署 Pod;节点被移除集群后,Pod 将自动回收。
调度说明
若配置了 Pod 的 nodeSelector 或 affinity 参数,DaemonSet 管理的 Pod 将按照指定的调度规则调度。若未配置 Pod 的 nodeSelector 或 affinity 参数,则将在所有的节点上部署 Pod。
DaemonSet 控制台操作指引
创建 DaemonSet
- 登录TKEStack,切换到【业务管理】控制台,选择左侧导航栏中的【应用管理】。
- 选择需要创建DaemonSet的【业务】下相应的【命名空间】,展开【工作负载】下拉项,进入【DaemonSet】管理页面。如下图所示:

单击【新建】,进入 “新建Workload” 页面。
根据实际需求,设置 DaemonSet 参数。关键参数信息如下:
- 工作负载名:输入自定义名称。
- 标签:给工作负载添加标签
- 命名空间:根据实际需求进行选择。
- 类型:选择【DaemonSet】。
- 数据卷:根据需求,为负载添加数据卷为容器提供存,目前支持临时路径、主机路径、云硬盘数据卷、文件存储NFS、配置文件、PVC,还需挂载到容器的指定路径中
- 临时目录:主机上的一个临时目录,生命周期和Pod一致
- 主机路径:主机上的真实路径,可以重复使用,不会随Pod一起销毁
- NFS盘:挂载外部NFS到Pod,用户需要指定相应NFS地址,格式:127.0.0.1:/data
- ConfigMap:用户在业务Namespace下创建的ConfigMap
- Secret:用户在业务namespace下创建的Secret
- PVC:用户在业务namespace下创建的PVC
- 实例内容器:根据实际需求,为 DaemonSet 的一个 Pod 设置一个或多个不同的容器。
- 名称:自定义。
- 镜像:根据实际需求进行选择。
- 镜像版本(Tag):根据实际需求进行填写。
- CPU/内存限制:可根据 Kubernetes 资源限制 进行设置 CPU 和内存的限制范围,提高业务的健壮性。
- GPU限制:如容器内需要使用GPU,此处填GPU需求
- 环境变量:用于设置容器内的变量,变量名只能包含大小写字母、数字及下划线,并且不能以数字开头
新增变量:自己设定变量键值对
引用ConfigMap/Secret:引用已有键值对
高级设置:可设置 “工作目录”、“运行命令”、“运行参数”、“镜像更新策略”、“容器健康检查”和“特权级”等参数。这里介绍一下镜像更新策略。
镜像更新策略:提供以下3种策略,请按需选择
若不设置镜像拉取策略,当镜像版本为空或
latest时,使用 Always 策略,否则使用 IfNotPresent 策略- Always:总是从远程拉取该镜像
- IfNotPresent:默认使用本地镜像,若本地无该镜像则远程拉取该镜像
- Never:只使用本地镜像,若本地没有该镜像将报异常
- imagePullSecrets:镜像拉取密钥,用于拉取用户的私有镜像
- 节点调度策略:根据配置的调度规则,将Pod调度到预期的节点。支持指定节点调度和条件选择调度
- 注释(Annotations):给DaemonSet添加相应Annotation,如用户信息等
- 网络模式:选择Pod网络模式
- OverLay(虚拟网络):基于 IPIP 和 Host Gateway 的 Overlay 网络方案
- FloatingIP(浮动 IP):支持容器、物理机和虚拟机在同一个扁平面中直接通过IP进行通信的 Underlay 网络方案。提供了 IP 漂移能力,支持 Pod 重启或迁移时 IP 不变
- NAT(端口映射):Kubernetes 原生 NAT 网络方案
- Host(主机网络):Kubernetes 原生 Host 网络方案
单击【创建Workload】,完成创建。
更新 DaemonSet
更新 YAML
- 登录TKEStack,切换到【业务管理】控制台,选择左侧导航栏中的【应用管理】。
- 选择需要更新的【业务】下相应的命名空间,展开【工作负载】列表,进入【DaemonSet】管理页面。
- 在需要更新 YAML 的 DaemonSet 行中,选择【更多】>【编辑YAML】,进入更新 DaemonSet 页面。
- 在 “更新DaemonSet” 页面编辑 YAML,并单击【完成】即可更新 YAML。
Kubectl 操作 DaemonSet 指引
YAML 示例
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd-elasticsearch
namespace: kube-system
labels:
k8s-app: fluentd-logging
spec:
selector:
matchLabels:
name: fluentd-elasticsearch
template:
metadata:
labels:
name: fluentd-elasticsearch
spec:
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
containers:
- name: fluentd-elasticsearch
image: k8s.gcr.io/fluentd-elasticsearch:1.20
resources:
limits:
memory: 200Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
!以上 YAML 示例引用于
https://kubernetes.io/docs/concepts/workloads/controllers/daemonset, 创建时可能存在容器镜像拉取不成功的情况,仅用于本文介绍 DaemonSet 的组成。
- kind:标识 DaemonSet 资源类型。
- metadata:DaemonSet 的名称、Label等基本信息。
- metadata.annotations:DaemonSet 的额外说明,可通过该参数设置腾讯云 TKE 的额外增强能力。
- spec.template:DaemonSet 管理的 Pod 的详细模板配置。
更多可查看 Kubernetes DaemonSet 官方文档。
Kubectl 创建 DaemonSet
参考 YAML 示例,准备 DaemonSet YAML 文件。
安装 Kubectl,并连接集群。操作详情请参考 通过 Kubectl 连接集群。
执行以下命令,创建 DaemonSet YAML 文件。
kubectl create -f DaemonSet YAML 文件名称例如,创建一个文件名为 fluentd-elasticsearch.yaml 的 DaemonSet YAML 文件,则执行以下命令:
kubectl create -f fluentd-elasticsearch.yaml执行以下命令,验证创建是否成功。
kubectl get DaemonSet返回类似以下信息,即表示创建成功。
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE frontend 0 0 0 0 0 app=frontend-node 16d
Kubectl 更新 DaemonSet
执行以下命令,查看 DaemonSet 的更新策略类型。
kubectl get ds/<daemonset-name> -o go-template='{{.spec.updateStrategy.type}}{{"\n"}}'
DaemonSet 有以下两种更新策略类型:
- OnDelete:默认更新策略。该更新策略在更新 DaemonSet 后,需手动删除旧的 DaemonSet Pod 才会创建新的DaemonSet Pod。
- RollingUpdate:支持 Kubernetes 1.6或更高版本。该更新策略在更新 DaemonSet 模板后,旧的 DaemonSet Pod 将被终止,并且以滚动更新方式创建新的 DaemonSet Pod。
方法一
执行以下命令,更新 DaemonSet。
kubectl edit DaemonSet/[name]
此方法适用于简单的调试验证,不建议在生产环境中直接使用。您可以通过此方法更新任意的 DaemonSet 参数。
方法二
执行以下命令,更新指定容器的镜像。
kubectl set image ds/[daemonset-name][container-name]=[container-new-image]
建议保持 DaemonSet 的其他参数不变,业务更新时,仅更新容器镜像。
Kubectl 回滚 DaemonSet
执行以下命令,查看 DaemonSet 的更新历史。
kubectl rollout history daemonset /[name]执行以下命令,查看指定版本详情。
kubectl rollout history daemonset /[name] --revision=[REVISION]执行以下命令,回滚到前一个版本。
kubectl rollout undo daemonset /[name]如需指定回滚版本号,可执行以下命令。
kubectl rollout undo daemonset /[name] --to-revision=[REVISION]
Kubectl 删除 DaemonSet
执行以下命令,删除 DaemonSet。
kubectl delete DaemonSet [NAME]
4.3.1.2.4 - Job
Job
Job 控制器会创建 1-N 个 Pod,这些 Pod 按照运行规则运行,直至运行结束。Job 可用于批量计算、数据分析等场景。通过设置重复执行次数、并行度、重启策略等满足业务述求。 Job 执行完成后,不再创建新的 Pod,也不会删除 Pod,您可在 “日志” 中查看已完成的 Pod 的日志。如果您删除了 Job,Job 创建的 Pod 也会同时被删除,将查看不到该 Job 创建的 Pod 的日志。
Job 控制台操作指引
创建 Job
登录TKEStack,切换到【业务管理】控制台,选择左侧导航栏中的【应用管理】。
选择需要创建 Job 的【业务】下相应的【命名空间】,展开【工作负载】下拉项,进入【 Job】 管理页面。
单击【新建】,进入 “新建Workload” 页面。如下图所示:

根据实际需求,设置 Job 参数。关键参数信息如下:
工作负载名:输入自定义名称。
标签:给工作负载添加标签
命名空间:根据实际需求进行选择。
类型:选择【Job(单次任务)】。
Job设置
- 重复执行次数:Job 管理的 Pod 需要重复执行的次数。
- 并行度:Job 并行执行的 Pod 数量。
- 失败重启策略:Pod下容器异常推出后的重启策略。
- Never:不重启容器,直至 Pod 下所有容器退出。
- OnFailure:Pod 继续运行,容器将重新启动。
数据卷:根据需求,为负载添加数据卷为容器提供存,目前支持临时路径、主机路径、云硬盘数据卷、文件存储NFS、配置文件、PVC,还需挂载到容器的指定路径中
临时目录:主机上的一个临时目录,生命周期和Pod一致
主机路径:主机上的真实路径,可以重复使用,不会随Pod一起销毁
NFS盘:挂载外部 NFS 到 Pod,用户需要指定相应 NFS 地址,格式:127.0.0.1:/data
ConfigMap:用户在业务Namespace下创建的ConfigMap
Secret:用户在业务namespace下创建的Secret
PVC:用户在业务namespace下创建的PVC
实例内容器:根据实际需求,为 Job 的一个 Pod 设置一个或多个不同的容器。
- 名称:自定义。
- 镜像:根据实际需求进行选择。
- 镜像版本(Tag):根据实际需求进行填写。
- CPU/内存限制:可根据 Kubernetes 资源限制 进行设置 CPU 和内存的限制范围,提高业务的健壮性。
- GPU限制:如容器内需要使用GPU,此处填GPU需求
- 环境变量:用于设置容器内的变量,变量名只能包含大小写字母、数字及下划线,并且不能以数字开头
新增变量:自己设定变量键值对
引用ConfigMap/Secret:引用已有键值对
高级设置:可设置 “工作目录”、“运行命令”、“运行参数”、“镜像更新策略”、“容器健康检查”和“特权级”等参数。这里介绍一下镜像更新策略。
镜像更新策略:提供以下3种策略,请按需选择
若不设置镜像拉取策略,当镜像版本为空或
latest时,使用 Always 策略,否则使用 IfNotPresent 策略- Always:总是从远程拉取该镜像
- IfNotPresent:默认使用本地镜像,若本地无该镜像则远程拉取该镜像
- Never:只使用本地镜像,若本地没有该镜像将报异常
imagePullSecrets:镜像拉取密钥,用于拉取用户的私有镜像
节点调度策略:根据配置的调度规则,将Pod调度到预期的节点。支持指定节点调度和条件选择调度
注释(Annotations):给Pod添加相应Annotation,如用户信息等
网络模式:选择Pod网络模式
- OverLay(虚拟网络):基于 IPIP 和 Host Gateway 的 Overlay 网络方案
- FloatingIP(浮动 IP):支持容器、物理机和虚拟机在同一个扁平面中直接通过IP进行通信的 Underlay 网络方案。提供了 IP 漂移能力,支持 Pod 重启或迁移时 IP 不变
- NAT(端口映射):Kubernetes 原生 NAT 网络方案
- Host(主机网络):Kubernetes 原生 Host 网络方案
单击【创建Workload】,完成创建。
查看 Job 状态
登录 TKEStack,切换到【业务管理】控制台,选择左侧导航栏中的【应用管理】。
选择需要创建 Job 的业务下相应的【命名空间】,展开【工作负载】下拉项,进入【 Job 】管理页面。
单击需要查看状态的【 Job 名称】,即可查看 Job 详情。
删除 Job
Job 执行完成后,不再创建新的 Pod,也不会删除 Pod,您可在【业务管理】控制台下的【应用管理】下的 【日志】 中查看已完成的 Pod 的日志。如果您删除了 Job,Job 创建的 Pod 也会同时被删除,将查看不到该 Job 创建的 Pod 的日志。
Kubectl 操作 Job 指引
YAML 示例
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
completions: 2
parallelism: 2
template:
spec:
containers:
- name: pi
image: perl
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: Never
backoffLimit: 4
- kind:标识 Job 资源类型。
- metadata:Job 的名称、Label等基本信息。
- metadata.annotations:Job 的额外说明,可通过该参数设置腾讯云 TKE 的额外增强能力。
- spec.completions:Job 管理的 Pod 重复执行次数。
- spec.parallelism:Job 并行执行的 Pod 数。
- spec.template:Job 管理的 Pod 的详细模板配置。
创建 Job
参考 YAML 示例,准备 Job YAML 文件。
安装 Kubectl,并连接集群。操作详情请参考 通过 Kubectl 连接集群。
创建 Job YAML 文件。
kubectl create -f Job YAML 文件名称例如,创建一个文件名为 pi.yaml 的 Job YAML 文件,则执行以下命令:
kubectl create -f pi.yaml执行以下命令,验证创建是否成功。
kubectl get job返回类似以下信息,即表示创建成功。
NAME DESIRED SUCCESSFUL AGE job 1 0 1m
删除 Job
执行以下命令,删除 Job。
kubectl delete job [NAME]
4.3.1.2.5 - CronJob
CronJob
一个 CronJob 对象类似于 crontab(cron table)文件中的一行。它根据指定的预定计划周期性地运行一个 Job,格式可以参考 Cron。 Cron 格式说明如下:
# 文件格式说明
# ——分钟(0 - 59)
# | ——小时(0 - 23)
# | | ——日(1 - 31)
# | | | ——月(1 - 12)
# | | | | ——星期(0 - 6)
# | | | | |
# * * * * *
CronJob 控制台操作指引
创建 CronJob
登录TKEStack,切换到【业务管理】控制台,选择左侧导航栏中的【应用管理】。
选择需要创建CronJob的业务下相应的【命名空间】,展开【工作负载】下拉项,进入【CronJob】管理页面。如下图所示:

单击【创建】按钮,进入 新建Workload页面。
根据实际需求,设置 CronJob 参数。关键参数信息如下:
- 工作负载名:输入自定义名称。
- 标签:给工作负载添加标签
- 命名空间:根据实际需求进行选择。
- 类型:选择【CronJob(按照Cron的计划定时运行)】。
- 执行策略:根据 Cron 格式设置任务的定期执行策略。
- Job设置
- 重复执行次数:Job 管理的 Pod 需要重复执行的次数。
- 并行度:Job 并行执行的 Pod 数量。
- 失败重启策略:Pod下容器异常推出后的重启策略。
- Never:不重启容器,直至 Pod 下所有容器退出。
- OnFailure:Pod 继续运行,容器将重新启动。
- 数据卷:根据需求,为负载添加数据卷为容器提供存,目前支持临时路径、主机路径、云硬盘数据卷、文件存储NFS、配置文件、PVC,还需挂载到容器的指定路径中
- 临时目录:主机上的一个临时目录,生命周期和Pod一致
- 主机路径:主机上的真实路径,可以重复使用,不会随Pod一起销毁
- NFS盘:挂载外部NFS到Pod,用户需要指定相应NFS地址,格式:127.0.0.1:/data
- ConfigMap:用户在业务Namespace下创建的ConfigMap
- Secret:用户在业务namespace下创建的Secret
- PVC:用户在业务namespace下创建的PVC
- 实例内容器:根据实际需求,为 CronJob 的一个 Pod 设置一个或多个不同的容器。
- 名称:自定义。
- 镜像:根据实际需求进行选择。
- 镜像版本(Tag):根据实际需求进行填写。
- CPU/内存限制:可根据 Kubernetes 资源限制 进行设置 CPU 和内存的限制范围,提高业务的健壮性。
- GPU限制:如容器内需要使用GPU,此处填GPU需求
- 环境变量:用于设置容器内的变量,变量名只能包含大小写字母、数字及下划线,并且不能以数字开头
新增变量:自己设定变量键值对
引用ConfigMap/Secret:引用已有键值对
高级设置:可设置 “工作目录”、“运行命令”、“运行参数”、“镜像更新策略”、“容器健康检查”和“特权级”等参数。这里介绍一下镜像更新策略。
镜像更新策略:提供以下3种策略,请按需选择
若不设置镜像拉取策略,当镜像版本为空或
latest时,使用 Always 策略,否则使用 IfNotPresent 策略- Always:总是从远程拉取该镜像
- IfNotPresent:默认使用本地镜像,若本地无该镜像则远程拉取该镜像
- Never:只使用本地镜像,若本地没有该镜像将报异常
- imagePullSecrets:镜像拉取密钥,用于拉取用户的私有镜像
- 节点调度策略:根据配置的调度规则,将Pod调度到预期的节点。支持指定节点调度和条件选择调度
- 注释(Annotations):给Pod添加相应Annotation,如用户信息等
- 网络模式:选择Pod网络模式
- OverLay(虚拟网络):基于 IPIP 和 Host Gateway 的 Overlay 网络方案
- FloatingIP(浮动 IP):支持容器、物理机和虚拟机在同一个扁平面中直接通过IP进行通信的 Underlay 网络方案。提供了 IP 漂移能力,支持 Pod 重启或迁移时 IP 不变
- NAT(端口映射):Kubernetes 原生 NAT 网络方案
- Host(主机网络):Kubernetes 原生 Host 网络方案
单击【创建Workload】,完成创建。
查看 CronJob 状态
- 登录TKEStack,切换到【业务管理】控制台,选择左侧导航栏中的【应用管理】。
- 选择需要创建CronJob的【业务】下相应的【命名空间】,展开【工作负载】下拉项,进入【CronJob】管理页面。
- 单击需要查看状态的 CronJob 名称,即可查看 CronJob 详情。
Kubectl 操作 CronJob 指引
YAML 示例
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: hello
spec:
schedule: "*/1 * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox
args:
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
restartPolicy: OnFailure
- kind:标识 CronJob 资源类型。
- metadata:CronJob 的名称、Label等基本信息。
- metadata.annotations:对 CronJob 的额外说明,可通过该参数设置腾讯云 TKE 的额外增强能力。
- spec.schedule:CronJob 执行的 Cron 的策略。
- spec.jobTemplate:Cron 执行的 Job 模板。
创建 CronJob
方法一
参考 YAML 示例,准备 CronJob YAML 文件。
安装 Kubectl,并连接集群。操作详情请参考 通过 Kubectl 连接集群。
执行以下命令,创建 CronJob YAML 文件。
kubectl create -f CronJob YAML 文件名称例如,创建一个文件名为 cronjob.yaml 的 CronJob YAML 文件,则执行以下命令:
kubectl create -f cronjob.yaml
方法二
通过执行
kubectl run命令,快速创建一个 CronJob。例如,快速创建一个不需要写完整配置信息的 CronJob,则执行以下命令:
kubectl run hello --schedule="*/1 * * * *" --restart=OnFailure --image=busybox -- /bin/sh -c "date; echo Hello"执行以下命令,验证创建是否成功。
kubectl get cronjob [NAME]返回类似以下信息,即表示创建成功。
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE cronjob * * * * * False 0 <none> 15s
删除 CronJob
!
- 执行此删除命令前,请确认是否存在正在创建的 Job,否则执行该命令将终止正在创建的 Job。
- 执行此删除命令时,已创建的 Job 和已完成的 Job 均不会被终止或删除。
- 如需删除 CronJob 创建的 Job,请手动删除。
执行以下命令,删除 CronJob。
kubectl delete cronjob [NAME]
4.3.1.2.6 - TApp
TApp
Kubernetes现有应用类型(如:Deployment、StatefulSet等)无法满足很多非微服务应用的需求,比如:操作(升级、停止等)应用中的指定pod、应用支持多版本的pod。如果要将这些应用改造为适合于这些workload的应用,需要花费很大精力,这将使大多数用户望而却步。
为解决上述复杂应用管理场景,TKEStack基于Kubernetes CRD开发了一种新的应用类型TAPP,它是一种通用类型的workload,同时支持service和batch类型作业,满足绝大部分应用场景,它能让用户更好的将应用迁移到Kubernetes集群。
查询TApp可查看更多相关信息
TApp控制台操作指引
创建 TApp
注意:使用前提,在【扩展组件】安装TApp
- 登录TKEStack,切换到【业务管理】控制台,选择左侧导航栏中的【应用管理】。
- 选择需要创建TApp的【业务】下相应的【命名空间】,展开【工作负载】下拉项,进入【TApp】管理页面。如下图所示:

单击【新建】,进入 “新建Workload” 页面。根据实际需求,设置 TApp 参数。关键参数信息如下,其中必填项为工作负载名、实例内容器的名称和镜像:
- 工作负载名:输入自定义名称。
- 标签:给工作负载添加标签
- 命名空间:根据实际需求进行选择。
- 类型:选择【TApp】。
- 节点异常策略
- 迁移,调度策略与Deployment一致,Pod会迁移到新的节点
- 不迁移,调度策略与StatefulSel一致,异常pod不会被迁移
- 数据卷:根据需求,为负载添加数据卷为容器提供存,目前支持临时路径、主机路径、云硬盘数据卷、文件存储NFS、配置文件、PVC,还需挂载到容器的指定路径中
- 临时目录:主机上的一个临时目录,生命周期和Pod一致
- 主机路径:主机上的真实路径,可以重复使用,不会随Pod一起销毁
- NFS盘:挂载外部NFS到Pod,用户需要指定相应NFS地址,格式:127.0.0.1:/data
- ConfigMap:用户在业务Namespace下创建的ConfigMap
- Secret:用户在业务namespace下创建的Secret
- PVC:用户在业务namespace下创建的PVC
- 实例内容器:根据实际需求,为 TApp 的一个 Pod 设置一个或多个不同的容器。
- 名称:自定义
- 镜像:根据实际需求进行选择
镜像版本(Tag):根据实际需求进行填写,不填默认为
latestCPU/内存限制:可根据 Kubernetes 资源限制 进行设置 CPU 和内存的限制范围,提高业务的健壮性(建议使用默认值)
GPU限制:如容器内需要使用GPU,此处填GPU需求
环境变量:用于设置容器内的变量,变量名只能包含大小写字母、数字及下划线,并且不能以数字开头
新增变量:自己设定变量键值对
引用ConfigMap/Secret:引用已有键值对
高级设置:可设置 “工作目录”、“运行命令”、“运行参数”、“镜像更新策略”、“容器健康检查”和“特权级”等参数。这里介绍一下镜像更新策略。
镜像更新策略:提供以下3种策略,请按需选择
若不设置镜像拉取策略,当镜像版本为空或
latest时,使用 Always 策略,否则使用 IfNotPresent 策略- Always:总是从远程拉取该镜像
- IfNotPresent:默认使用本地镜像,若本地无该镜像则远程拉取该镜像
- Never:只使用本地镜像,若本地没有该镜像将报异常
- 实例数量:根据实际需求选择调节方式,设置实例数量。
- 手动调节:直接设定实例个数
- 自动调节:根据设定的触发条件自动调节实例个数,目前支持根据CPU、内存利用率和利用量出入带宽等调节实例个数
- 定时调节:根据Crontab 语法周期性设置实例个数
- imagePullSecrets:镜像拉取密钥,用于拉取用户的私有镜像
- 节点调度策略:根据配置的调度规则,将Pod调度到预期的节点。支持指定节点调度和条件选择调度
- 注释(Annotations):给TApp添加相应Annotation,如用户信息等
- 网络模式:选择Pod网络模式
- OverLay(虚拟网络):基于 IPIP 和 Host Gateway 的 Overlay 网络方案
- FloatingIP(浮动 IP):支持容器、物理机和虚拟机在同一个扁平面中直接通过IP进行通信的 Underlay 网络方案。提供了 IP 漂移能力,支持 Pod 重启或迁移时 IP 不变
- NAT(端口映射):Kubernetes 原生 NAT 网络方案
- Host(主机网络):Kubernetes 原生 Host 网络方案
- Service:勾选【启用】按钮,配置负载端口访问
注意:如果不勾选【启用】则不会创建Service
服务访问方式:选择是【仅在集群内部访问】该负载还是集群外部通过【主机端口访问】该负载
- 仅在集群内访问:使用 Service 的 ClusterIP 模式,自动分配 Service 网段中的 IP,用于集群内访问。数据库类等服务如 MySQL 可以选择集群内访问,以保证服务网络隔离
- 主机端口访问:提供一个主机端口映射到容器的访问方式,支持 TCP、UDP、Ingress。可用于业务定制上层 LB 转发到 Node
- Headless Service:不创建用于集群内访问的ClusterIP,访问Service名称时返回后端Pods IP地址,用于适配自有的服务发现机制。解析域名时返回相应 Pod IP 而不是 Cluster IP
端口映射:输入负载要暴露的端口并指定通信协议类型(容器和服务端口建议都使用80)
Session Affinity: 点击【显示高级设置】出现,会话保持,设置会话保持后,会根据请求IP把请求转发给这个IP之前访问过的Pod。默认None,按需使用
单击【创建Workload】,完成创建。如下图所示:
当“运行/期望Pod数量”相等时,即表示 TApp 下的所有 Pod 已创建完成。

更新 TApp
更新 YAML
- 登录TKEStack,切换到【业务管理】控制台,选择左侧导航栏中的【应用管理】。
- 选择需要更新的【业务】下相应的【命名空间】,展开【工作负载】列表,进入【TApp】管理页面。在需要更新 YAML 的 TApp 行中,单击【更多】>【编辑YAML】,进入“更新 TApp” 页面。如下图所示:

- 在 “更新TApp” 页面,编辑 YAML,单击【完成】,即可更新 YAML。如下图所示:

调整 Pod 数量
- 登录 TKEStack,切换到【业务管理】控制台,选择左侧导航栏中的【应用管理】。
- 选择要变更的业务下相应的命名空间,展开工作负载列表,进入 TApp 管理页面。
- 点击 TApp 列表操作栏的【更新实例数量】按钮。如下图所示:

- 根据实际需求调整 Pod 数量,如3,单击页面下方的【更新实例数目】即可完成调整。
TApp特色功能-指定pod灰度升级
- 登录 TKEStack,切换到【业务管理】控制台,选择左侧导航栏中的【应用管理】。
- 选择要变更的业务下相应的【命名空间】,展开【工作负载】列表,进入【 TApp】 管理页面,点击进入要灰度升级的 TApp名称。如下图所示:

- 如下图标签1所示,可选指定需要灰度升级的pod,然后点击下图中标签2 的【灰度升级】即可升级指定pod。

在弹出的 “回滚资源” 提示框中,单击【确定】即可完成回滚。
注意:此页面同时可完成指定Pod监控和删除
查询TApp可查看更多相关信息
4.3.1.2.7 - 工作负载的请求与限制
工作负载的请求与限制
Request:容器使用的最小资源需求,作为容器调度时资源分配的判断依赖。只有当节点上可分配资源量 >= 容器资源请求数时才允许将容器调度到该节点。但 Request 参数不限制容器的最大可使用资源值。 Limit: 容器能使用的资源最大值。
! 更多 Limit 和 Request 参数介绍,单击 查看详情。
CPU 限制说明
CPU 资源允许设置 CPU 请求和 CPU 限制的资源量,以核(U)为单位,允许为小数。
!
- CPU Request 作为调度时的依据,在创建时为该容器在节点上分配 CPU 使用资源,称为 “已分配 CPU” 资源。
- CPU Limit 限制容器 CPU 资源的上限,不设置表示不做限制(CPU Limit >= CPU Request)。
内存限制说明
内存资源只允许限制容器最大可使用内存量。以 MiB 为单位,允许为小数。
!
- 内存 Request 作为调度时的依据,在创建时为该容器在节点上分配内存,称为 “已分配内存” 资源。
- 内存资源为不可伸缩资源。当节点上所有容器使用内存均超量时,存在 OOM 的风险。因此不设置 Limit 时,默认 Limit = Request,保证容器的正常运作。
CPU 使用量和 CPU 使用率
- CPU 使用量为绝对值,表示实际使用的 CPU 的物理核数,CPU 资源请求和 CPU 资源限制的判断依据都是 CPU 使用量。
- CPU 使用率为相对值,表示 CPU 的使用量与 CPU 单核的比值(或者与节点上总 CPU 核数的比值)。
使用示例
一个简单的示例说明 Request 和 Limit 的作用,测试集群包括1个 4U4G 的节点、已经部署的两个 Pod ( Pod1,Pod2 ),每个 Pod 的资源设置为(CPU Requst,CPU Limit,Memory Requst,Memory Limit)=(1U,2U,1G,1G)。(1.0G = 1000MiB) 节点上 CPU 和内存的资源使用情况如下图所示: 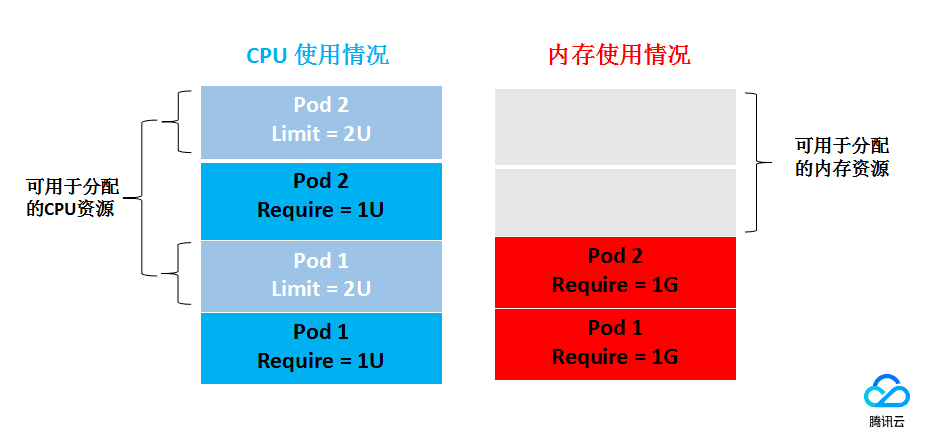 已经分配的 CPU 资源为:1U(分配 Pod1) + 1U(分配 Pod2) = 2U,剩余可以分配的 CPU 资源为2U。 已经分配的内存资源为:1G(分配 Pod1) + 1G(分配 Pod2) = 2G,剩余可以分配的内存资源为2G。 所以该节点可以再部署一个 ( CPU Requst, Memory Requst ) =( 2U,2G )的 Pod 部署,或者部署2个(CPU Requst,Memory Requst) = (1U,1G) 的 Pod 部署。
已经分配的 CPU 资源为:1U(分配 Pod1) + 1U(分配 Pod2) = 2U,剩余可以分配的 CPU 资源为2U。 已经分配的内存资源为:1G(分配 Pod1) + 1G(分配 Pod2) = 2G,剩余可以分配的内存资源为2G。 所以该节点可以再部署一个 ( CPU Requst, Memory Requst ) =( 2U,2G )的 Pod 部署,或者部署2个(CPU Requst,Memory Requst) = (1U,1G) 的 Pod 部署。
在资源限制方面,每个 Pod1 和 Pod2 使用资源的上限为 ( 2U,1G ),即在资源空闲的情况下,Pod 使用 CPU 的量最大能达到2U。
服务资源限制推荐
CCS 会根据您当前容器镜像的历史负载来推荐 Request 与 Limit 值,使用推荐值会保证您的容器更加平稳的运行,大大减小出现异常的概率。
推荐算法: 我们首先会取出过去7天当前容器镜像分钟级别负载,并辅以百分位统计第95%的值来最终确定推荐的 Request,Limit 为 Request 的2倍。
Request = Percentile(实际负载[7d],0.95)
Limit = Request * 2
如果当前的样本数量(实际负载)不满足推荐计算的数量要求,我们会相应的扩大样本取值范围,尝试重新计算。例如,去掉镜像 tag,namespace,serviceName 等筛选条件。若经过多次计算后同样未能得到有效值,则推荐值为空。
推荐值为空: 在使用过程中,您会发现有部分值暂无推荐的情况,可能由于以下几点造成: 1. 当前数据并不满足计算的需求,我们需要待计算的样本数量(实际负载)大于1440个,即有一天的数据。 2. 推荐值小于您当前容器已经配置的 Request 或者 Limit。
! 1. 由于推荐值是根据历史负载来计算的,原则上,容器镜像运行真实业务的时间越长,推荐的值越准确。 2. 使用推荐值创建服务,可能会因为集群资源不足造成容器无法调度成功。在保存时,须确认当前集群的剩余资源。 3. 推荐值是建议值,您可以根据自己业务的实际情况做相应的调整。
4.3.1.3 - 服务
服务
4.3.1.3.1 - Service
Service 定义访问后端 Pod 的访问方式,并提供固定的虚拟访问 IP。您可以在 Service 中通过设置来访问后端的 Pod,不同访问方式的服务可提供不同网络能力。 腾讯云容器服务(TKE)提供以下四种服务访问方式:
| 访问方式 | 说明 |
|---|---|
| 仅在集群内访问 |
|
| 主机端口访问 |
|
集群内进行 Service 访问时,建议不要通过负载均衡 IP 进行访问,以避免出现访问不通的情况。
一般情况下,4层负载均衡(LB)会绑定多台 Node 作为 real server(rs) ,使用时需要限制 client 和 rs 不能存在于同一台云服务器上,否则会有一定概率导致报文回环出不去。 当 Pod 去访问 LB 时,Pod 就是源 IP,当其传输到内网时 LB 也不会做 snat 处理将源 IP 转化成 Node IP,那么 LB 收到报文也就不能判断是从哪个 Node 发送的,LB 的避免回环策略也就不会生效,所有的 rs 都可能被转发。当转发到 client 所在的 Node 上时,LB 就无法收到回包,从而导致访问不通。
集群内访问时,支持Headless Service,解析服务名时直接返回对应Pod IP而不是Cluster IP,可以适配自有的服务发现机制。 两种访问方式均支持Session Affinity,设置会话保持后,会根据请求IP把请求转发给这个IP之前访问过的Pod.
Service 控制台操作指引
创建 Service
- 登录TKEStack,切换到【业务管理】控制台,选择左侧导航栏中的【应用管理】。
- 选择需要创建 Service 的【业务】下相应的【命名空间】,展开【服务】列表,进入【Service】管理页面。
- 单击【新建】,进入 “新建 Service” 页面。如下图所示:

- 根据实际需求,设置 Service 参数。关键参数信息如下:
- 服务名称:自定义。
- 命名空间:根据实际需求进行选择。
- 访问设置:请参考 简介 并根据实际需求进行设置。
- 单击【创建服务】,完成创建。
更新 Service
更新 YAML
- 登录TKEStack,切换到业务管理控制台,选择左侧导航栏中的【应用管理】。
- 选择需要创建Service的业务下相应的命名空间,展开服务列表,进入Service管理页面。
- 在需要更新 YAML 的 Service 行中,单击【编辑YAML】,进入更新 Service 页面。
- 在 “更新Service” 页面,编辑 YAML,单击【完成】,即可更新 YAML。
Kubectl 操作 Service 指引
YAML 示例
kind: Service
apiVersion: v1
metadata:
name: my-service
spec:
selector:
app: MyApp
ports:
- protocol: TCP
port: 80
targetPort: 9376
type: LoadBalancer
- kind:标识 Service 资源类型。
- metadata:Service 的名称、Label等基本信息。
- spec.type:标识 Service 的被访问形式
- ClusterIP:在集群内部公开服务,可用于集群内部访问。
- NodePort:使用节点的端口映射到后端 Service,集群外可以通过节点 IP:NodePort 访问。
- LoadBalancer:使用腾讯云提供的负载均衡器公开服务,默认创建公网 CLB, 指定 annotations 可创建内网 CLB。
- ExternalName:将服务映射到 DNS,仅适用于 kube-dns1.7及更高版本。
创建 Service
参考 YAML 示例,准备 StatefulSet YAML 文件。
安装 Kubectl,并连接集群。操作详情请参考 通过 Kubectl 连接集群。
执行以下命令,创建 Service YAML 文件。
kubectl create -f Service YAML 文件名称例如,创建一个文件名为 my-service.yaml 的 Service YAML 文件,则执行以下命令:
kubectl create -f my-service.yaml执行以下命令,验证创建是否成功。
kubectl get services返回类似以下信息,即表示创建成功。
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 172.16.255.1 <none> 443/TCP 38d
更新 Service
方法一
执行以下命令,更新 Service。
kubectl edit service/[name]
方法二
手动删除旧的 Service。
执行以下命令,重新创建 Service。
kubectl create/apply
删除 Service
执行以下命令,删除 Service。
kubectl delete service [NAME]
.params{margin-bottom:0px !important;}
4.3.1.3.2 - Ingress
Ingress 是允许访问到集群内 Service 的规则的集合,您可以通过配置转发规则,实现不同 URL 可以访问到集群内不同的 Service。
4.3.1.4 - 配置管理
配置管理
4.3.1.4.1 - ConfigMap
通过 ConfigMap 您可以将配置和运行的镜像进行解耦,使得应用程序有更强的移植性。ConfigMap 是有 key-value 类型的键值对,您可以通过控制台的 Kubectl 工具创建对应的 ConfigMap 对象,可以通过挂载数据卷、环境变量或在容器的运行命令中使用 ConfigMap。 ConfigMap 有两种使用方式,创建负载时做为数据卷挂载到容器和作为环境变量映射到容器。
ConfigMap 控制台操作指引
创建 ConfigMap
- 登录TKEStack,切换到【业务管理】控制台,选择左侧导航栏中的【应用管理】。
- 选择需要创建ConfigMap的【业务】下相应的【命名空间】,展开【配置管理】列表,进入ConfigMap管理页面。
- 单击【新建】,进入 “新建ConfigMap” 页面。如下图所示:

- 根据实际需求,设置 ConfigMap 参数。关键参数信息如下:
- 名称:自定义。
- 命名空间:根据实际需求进行选择命名空间类型
- 定义变量名和变量值。
- 单击【创建ConfigMap】,完成创建。
更新 ConfigMap
登录TKEStack,切换到业务管理控制台,选择左侧导航栏中的【应用管理】。
选择需要创建ConfigMap的业务下相应的命名空间,展开配置管理列表,进入ConfigMap管理页面。
在需要更新 YAML 的 ConfigMap 行中,单击【编辑YAML】,进入更新 ConfigMap 页面。
在 “更新ConfigMap” 页面,编辑 YAML,单击【完成】,即可更新 YAML。
如需修改 key-values,编辑 YAML 中 data 的参数值,单击【完成】,即可完成更新。
Kubectl 操作 ConfigMap 指引
YAML 示例
apiVersion: v1
data:
key1: value1
key2: value2
key3: value3
kind: ConfigMap
metadata:
name: test-config
namespace: default
- data:ConfigMap 的数据,以 key-value 形式呈现。
- kind:标识 ConfigMap 资源类型。
- metadata:ConfigMap 的名称、Label等基本信息。
- metadata.annotations:ConfigMap 的额外说明,可通过该参数设置腾讯云 TKE 的额外增强能力。
创建 ConfigMap
方式一:通过 YAML 示例文件方式创建
参考 YAML 示例,准备 ConfigMap YAML 文件。
安装 Kubectl,并连接集群。操作详情请参考 通过 Kubectl 连接集群。
执行以下命令,创建 ConfigMap YAML 文件。
kubectl create -f ConfigMap YAML 文件名称例如,创建一个文件名为 web.yaml 的 ConfigMap YAML 文件,则执行以下命令:
kubectl create -f web.yaml执行以下命令,验证创建是否成功。
kubectl get configmap返回类似以下信息,即表示创建成功。
NAME DATA AGE test 2 39d test-config 3 18d
方式二:通过执行命令方式创建
执行以下命令,在目录中创建 ConfigMap。
kubectl create configmap <map-name> <data-source>
- <map-name>:表示 ConfigMap 的名字。
- <data-source>:表示目录、文件或者字面值。
更多参数详情可参见 Kubernetes configMap 官方文档。
使用 ConfigMap
方式一:数据卷使用 ConfigMap 类型
YAML 示例如下:
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx:latest
volumeMounts:
name: config-volume
mountPath: /etc/config
volumes:
name: config-volume
configMap:
name: test-config ## 设置 ConfigMap 来源
## items: ## 设置指定 ConfigMap 的 Key 挂载
## key: key1 ## 选择指定 Key
## path: keys ## 挂载到指定的子路径
restartPolicy: Never
方式二:环境变量中使用 ConfigMap 类型
YAML 示例如下:
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx:latest
env:
- name: key1
valueFrom:
configMapKeyRef:
name: test-config ## 设置来源 ConfigMap 文件名
key: test-config.key1 ## 设置该环境变量的 Value 来源项
restartPolicy: Never
4.3.1.4.2 - Sercet
Sercet
Secret 可用于存储密码、令牌、密钥等敏感信息,降低直接对外暴露的风险。Secret 是 key-value 类型的键值对,您可以通过控制台的 Kubectl 工具创建对应的 Secret 对象,也可以通过挂载数据卷、环境变量或在容器的运行命令中使用 Secret。
Secret 控制台操作指引
创建 Secret
- 登录 TKEStack,切换到【业务管理】控制台,选择左侧导航栏中的【应用管理】。
- 选择需要创建 Secret 的【业务】下相应的【命名空间】,展开【配置管理】列表,进入 Secret 管理页面。
- 单击【新建】,进入“新建 Secret ”页面。
- 在“新建 Secret ”页面,根据实际需求,进行如下参数设置。如下图所示:

- 名称:请输入自定义名称。
- Secret类型:提供【Opaque】和【Dockercfg】两种类型,请根据实际需求进行选择。
- Opaque:适用于保存秘钥证书和配置文件,Value 将以 base64 格式编码。
- Dockercfg:适用于保存私有 Docker Registry 的认证信息。
- 生效范围:提供以下两种范围,请根据实际需求进行选择。
- 存量所有命名空间:不包括 kube-system、kube-public 和后续增量命名空间。
- 指定命名空间:支持选择当前集群下一个或多个可用命名空间。
- 内容:根据不同的 Secret 类型,进行配置。
- 当 Secret 类型为【Opaque】时:根据实际需求,设置变量名和变量值。
- 当 Secret 类型为【Dockercfg】时:
仓库域名:请根据实际需求输入域名或 IP。
用户名:请根据实际需求输入第三方仓库的用户名。
密码:请根据实际需求设置第三方仓库的登录密码。
如果本次为首次登录系统,则会新建用户,相关信息写入
~/.dockercrg文件中。
- 单击【创建 Secret】,即可完成创建。
使用 Secret
Secret 在 Workload中有三种使用场景: 1. 数据卷使用 Secret 类型 2. 环境变量中使用 Secret 类型 3. 使用第三方镜像仓库时引用
更新 Secret
登录 TKEStack,切换到业务管理控制台,选择左侧导航栏中的【应用管理】。
选择需要创建 Secret 的业务下相应的命名空间,展开配置管理列表,进入 Secret 管理页面。
在需要更新 YAML 的 Secret 行中,单击【编辑YAML】,进入更新 Secret 页面。
在“更新Secret”页面,编辑 YAML,并单击【完成】即可更新 YAML。
如需修改 key-values,则编辑 YAML 中 data 的参数值,并单击【完成】即可完成更新。
Kubectl 操作 Secret 指引
创建 Secret
方式一:通过指定文件创建 Secret
依次执行以下命令,获取 Pod 的用户名和密码。
$ echo -n 'username' > ./username.txt $ echo -n 'password' > ./password.txt执行 Kubectl 命令,创建 Secret。
$ kubectl create secret generic test-secret --from-file=./username.txt --from-file=./password.txt secret "testSecret" created执行以下命令,查看 Secret 详情。
kubectl describe secrets/ test-secret
方式二:YAML 文件手动创建
? 通过 YAML 手动创建 Secret,需提前将 Secret 的 data 进行 Base64 编码。
apiVersion: v1
kind: Secret
metadata:
name: test-secret
type: Opaque
data:
username: dXNlcm5hbWU= ## 由echo -n 'username' | base64生成
password: cGFzc3dvcmQ= ## 由echo -n 'password' | base64生成
使用 Secret
方式一: 数据卷使用 Secret 类型
YAML 示例如下:
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx:latest
volumeMounts:
name: secret-volume
mountPath: /etc/config
volumes:
name: secret-volume
secret:
name: test-secret ## 设置 secret 来源
## items: ## 设置指定 secret的 Key 挂载
## key: username ## 选择指定 Key
## path: group/user ## 挂载到指定的子路径
## mode: 256 ## 设置文件权限
restartPolicy: Never
方式二: 环境变量中使用 Secret 类型
YAML 示例如下:
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx:latest
env:
- name: SECRET_USERNAME
valueFrom:
secretKeyRef:
name: test-secret ## 设置来源 Secret 文件名
key: username ## 设置该环境变量的 Value 来源项
restartPolicy: Never
方法三:使用第三方镜像仓库时引用
YAML 示例如下:
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx:latest
imagePullSecrets:
- name: test-secret ## 设置来源 Secret 文件名
restartPolicy: Never
4.3.1.5 - 存储
存储
4.3.1.5.1 - PV和PVC
PersistentVolume(PV):集群内的存储资源。例如,节点是集群的资源。PV 独立于 Pod 的生命周期,根据不同的 StorageClass 类型创建不同类型的 PV。 PersistentVolumeClaim(PVC):集群内的存储请求。例如,PV 是 Pod 使用节点资源,PVC 则声明使用 PV 资源。当 PV 资源不足时,PVC 也可以动态创建 PV。
4.3.1.5.2 - StorageClass
StorageClass 描述存储的类型,集群管理员可以为集群定义不同的存储类别。可通过 StorageClass 配合 PersistentVolumeClaim 可以动态创建需要的存储资源。
4.3.1.6 - 事件
日志针对的是容器。包括了 Kuberntes 集群的运行容器的日志情况和各类资源的调度情况,对维护人员日常观察资源的变更以及定位问题均有帮助。
日志控制台操作指引
- 登录 TKEStack,切换到【业务管理】控制台,点击【应用管理】,选择【日志】。
- 进入“日志”页面。
- 可以按照不用的命名空间和资源类型进行筛选。

注意:Kubernetes 默认只将最近一个小时的事件存储在 ETCD 中,若想实现事件的持久化存储和查询操作
您可以参考 事件持久化 将事件导入外部存储,实现事件的持久化存储
4.3.1.7 - 日志
时间针对的是负载。Kubernetes Events 包括了 Kuberntes 集群的运行和各类资源的调度情况,对维护人员日常观察资源的变更以及定位问题均有帮助。
Event 控制台操作指引
- 登录 TKEStack,切换到【业务管理】控制台,点击【应用管理】中的【事件】,进入“事件”页面。
- 可以按照不用的命名空间和资源类型进行筛选。

您可以参考 日志采集 将日志导入外部存储,实现日志的高级管理。
4.3.2 - 业务管理
这里用户可以管理业务。
更改业务成员
登录 TKEStack。
切换至 【业务管理】控制台,点击【业务管理】。
在“业务管理”页面中,可以看到已创建的业务列表。鼠标移动到要修改的业务上(无需点击),成员列会出现修改图标按钮。如下图所示:

注意:修改业务成员仅限状态为Active的业务,这里可以新建和删除成员。
查看业务监控
登录 TKEStack。
切换至 【业务管理】控制台,点击【业务管理】。
在“业务管理”页面中,可以看到已创建的业务列表。点击监控按钮,如下图所示:

在右侧弹出窗口里查看业务监控情况,如下图所示:

删除业务
登录 TKEStack。
切换至 【业务管理】控制台,点击【业务管理】。
在“业务管理”页面中,可以看到已创建的业务列表。点击删除按钮,如下图所示:

注意:删除业务成员仅限状态为Active的业务
对业务的操作
- 登录 TKEStack。
- 在【业务管理】控制台的【业务管理】中,单击【业务id】。如下图所示:

a. 业务信息: 在这里可以对业务名称、关联的集群、关联集群的资源进行限制等操作。
b. 成员列表: 在这里可以对业务名称、关联的集群、关联集群的资源进行限制等操作。
c. 子业务: 在这里可以新建本业务的子业务或通过导入子业务将已有业务变成本业务的子业务
d. 业务下Namespace列表: 这里可以管理业务下的Namespace
单击【新建Namespace】。在“新建Namespace”页面中,填写相关信息。如下图所示:
名称:不能超过63个字符,这里以new-ns为例
集群:my-business业务中的集群,这里以global集群为例
资源限制*:这里可以限制当前命名空间下各种资源的使用量,可以不设置。
4.3.3 - 组织资源
组织资源
4.3.3.1 - 镜像仓库管理
这里用户可以管理镜像仓库。
注意:TKEStack的【业务管理】控制台不支持命名空间的创建,可以在【平台管理】下的【组织资源】下的【镜像仓库管理】新建命名空间。
删除命名空间
- 登录 TKEStack。
- 切换至 【业务管理】控制台,选择 【组织资源】->【仓库管理】。点击列表最右侧【删除】按钮。如下图所示:
- 点击【确认】

镜像上传
- 登录 TKEStack。
- 切换至 【业务管理】控制台,选择 【组织资源】->【仓库管理】,查看“命名空间”列表。点击列表中命名空间【名称】。如下图所示:

此时进入了“镜像列表”页面,点击【镜像上传指引】按钮。如下图所示:
注意:此页面可以通过上传的镜像最右边的【删除】按钮来删除上传的镜像

- 根据指引内容,在物理节点上执行相应命令。如下图所示:

4.3.3.2 - Helm模板
应用功能是 TKEStack 集成的 Helm 3.0 相关功能,为您提供创建 helm chart、容器镜像、软件服务等各种产品和服务的能力。已创建的应用将在您指定的集群中运行,为您带来相应的能力。
模板
登录 TKEStack
切换至 【平台管理】控制台,选择 【组织资源】->【 Helm模板】,点击【模板】 1. 所有模板:包含下列所有模板 2. 用户模板:权限范围为“指定用户”的仓库下的所有模板 3. 业务模板:权限范围为“指定业务”的仓库下的所有模板 4. 公共模板:权限范围为“公共”的仓库下的所有模板
仓库
登录 TKEStack
切换至 【平台管理】控制台,选择 【组织资源】->【 Helm模板】,点击【仓库】
点击【新建】按钮,如下图所示:
在弹出的 “新建仓库” 页面,填写 仓库 信息,如下图所示:
仓库名称: 仓库名字,不超过60个字符
权限访问
- 指定用户:选择当前仓库可以被哪些平台的用户访问
- 指定业务:选择当前仓库可以被哪些平台的业务访问,业务下的成员对该仓库的访问权限在【业务管理】中完成
- 公共:平台所有用户都能访问该仓库
导入第三方仓库: 若已有仓库想导入 TKEStack 中使用,请勾选
- 第三方仓库地址:请输入第三方仓库地址
- 第三方仓库用户名:若第三方仓库开启了鉴权,需要输入第三方仓库的用户名
- 第三方仓库密码:若第三方仓库开启了鉴权,需要输入第三方仓库的密码
仓库描述: 请输入仓库描述,不超过255个字符
单击【确认】按钮
删除仓库
登录 TKEStack
切换至 【平台管理】控制台,选择 【组织资源】-> 【 Helm 模板】,点击【仓库】,查看 “helm模板仓库”列表
点击列表最右侧【删除】按钮,如下图所示:
Chart 上传指引
登录 TKEStack
切换至 【平台管理】控制台,选择 【组织资源】-> 【 Helm模板】,点击【仓库】,查看 “helm模板仓库”列表
点击列表最右侧【上传指引】按钮,如下图所示:
根据指引内容,在物理节点上执行相应命令,如下图所示:
同步导入仓库
登录 TKEStack
切换至 【平台管理】控制台,选择 【组织资源】->【 Helm模板】,点击【仓库】
点击导入仓库的【同步仓库】按钮,如下图所示:
4.3.3.3 - 访问凭证
这里用户可以管理自己的凭据。
新建访问凭证
- 登录 TKEStack。
- 切换至 【业务管理】控制台,选择【组织资源】->【访问凭证】,点击【新建】按钮。
- 在弹出“创建访问凭证”页面,填写凭证信息。如下图所示:
- 凭证描述:描述当前凭证信息
- 过期时间:填写过期时间,选择小时/分钟为单位
- 单击【确认】按钮


停用/启用/删除访问凭证
登录 TKEStack。
切换至 【业务管理】控制台,选择 【组织资源】-> 【访问凭证】,查看“访问凭证”列表。单击列表右侧【禁用】/【启用】/【删除】按钮。如下图所示:
注意:点击【禁用】之后,【禁用】按钮就变成了【启用】
单击【确认】按钮

4.3.4 - 监控与告警
监控与告警
4.3.4.1 - 设置告警
概念
这里用户配置平台告警。
前提条件
- 需要设置告警的命名空间所在的集群,应该先在【扩展组件】安装Prometheus组件
操作步骤
新建告警设置
- 登录 TKEStack。
- 切换至【业务管理】控制台,选择【监控&告警】-> 【告警设置】,查看“告警设置”列表。
- 选择相应【项目】和【namespace】,点击【新建】按钮。如下图所示:

- 在“新建策略”页面填写告警策略信息。如下图所示:

- 告警策略名称: 输入告警策略名称,最长60字符
- 策略类型: 选择告警策略应用类型
- 集群: 集群监控告警
- Pod: Pod 监控告警
- 告警对象: 选择Pod相关的告警对象,支持对namespace下不同对deployment、stateful和daemonset 进行监控报警
- 按工作负载选择: 选择namespace下的某个工作负载
- 全部选择: 不区分namespace,全部监控
- 告警对象: 选择Pod相关的告警对象,支持对namespace下不同对deployment、stateful和daemonset 进行监控报警
- 节点: 节点监控告警
- 统计周期: 选择数据采集周期,支持1、2、3、4、5分钟
- 指标: 选择告警指标,支持对监测值与指标值进行【大于/小于】比较,选择结果持续周期。如下图:

- 接收组: 选择接收组,当出现满足条件当报警信息时,向组内人员发送消息。接收组需要先在 通知设置 创建
- 通知方式: 选择通知渠道和消息模版。通知渠道 和 消息模版需要先在 通知设置 创建
- 添加通知方式 如需要添加多种通知方式,点击该按钮。
- 单击【提交】按钮。
- 添加通知方式 如需要添加多种通知方式,点击该按钮。
复制告警设置
- 登录 TKEStack。
- 切换至【业务管理】控制台,选择 【监控&告警】->【告警设置】,查看告警设置列表。
- 选择相应【项目】和【namespace】,点击“告警设置”列表最右侧的【复制】按钮。如下图所示:

在复制策略页面,编辑告警策略信息。
单击【提交】按钮。
编辑告警设置
登录 TKEStack。
切换至 【业务管理】控制台,选择 【监控&告警】->【告警设置】,查看告警设置列表。
选择相应【项目】和【namespace】,点击【告警名称】。如下图所示:

- 在“告警策略详情”页面,单击【基本信息】右侧的【编辑】按钮。如下图所示:

在更新策略页面,编辑策略信息。
单击【提交】按钮。
删除告警设置
登录 TKEStack。
切换至 【业务管理】控制台,选择 【监控&告警】->【告警设置】,查看“告警设置”列表。
选择相应【项目】和【namespace】,点击列表最右侧的【删除】按钮。如下图所示:

- 在弹出的删除告警窗口,单击【确定】按钮。
4.3.4.2 - 通知设置
概念
这里用户配置平台通知。
操作步骤
这部分和【平台管理】控制台下【监控&告警】下的【通知设置】完全一致。故这里使用【平台管理】控制台下的截图。
通知渠道
新建通知渠道
- 登录 TKEStack。
- 切换至【业务管理】控制台,选择 【监控&告警】->【通知设置】->【通知渠道】,查看“通知渠道”列表。
- 点击【新建】按钮。如下图所示:

- 在“新建通知渠道”页面填写渠道信息。如下图所示:

- 名称: 填写渠道名称
- 渠道: 选择渠道类型,输入渠道信息
- 邮件: 邮件类型
- email: 邮件发送放地址
- password: 邮件发送方密码
- smtpHost: smtp IP地址
- smtpPort: smtp端口
- tls: 是否tls加密
- 短信: 短信方式
- appKey: 短信发送方的appKey
- sdkAppID: sdkAppID
- extend: extend 信息
- 微信公众号: 微信公众号方式
- appID: 微信公众号appID
- appSecret: 微信公众号app密钥
- 单击【保存】按钮。
编辑通知渠道
- 登录 TKEStack。
- 切换至【业务管理】控制台,选择 【监控&告警】->【通知设置】->【通知渠道】,查看“通知渠道”列表。
- 单击渠道名称。如下图所示:

- 在“基本信息”页面,单击【基本信息】右侧的【编辑】按钮。如下图所示:

- 在“更新渠道通知”页面,编辑渠道信息。
- 单击【保存】按钮。
删除通知渠道
- 登录 TKEStack。
- 切换至【业务管理】控制台,选择 【监控&告警】->【通知设置】->【通知渠道】,查看“通知渠道”列表。
- 选择要删除的渠道,点击【删除】按钮。如下图所示:

- 单击删除窗口的【确定】按钮。
通知模板
新建通知模版
- 登录 TKEStack。
- 切换至【业务管理】控制台,选择 【监控&告警】->【通知设置】->【通知模板】,查看“通知模板”列表。
- 点击【新建】按钮。如下图所示:

- 在“新建通知模版”页面填写模版信息。如下图所示:

- 名称: 模版名称
- 渠道: 选择已创建的渠道
- body: 填写消息body体
- header: 填写消息标题
- 单击【保存】按钮。
编辑通知模版
- 登录 TKEStack。
- 切换至【业务管理】控制台,选择 【监控&告警】->【通知设置】->【通知模板】,查看“通知模板”列表。
- 单击模版名称。如下图所示:

- 在基本信息页面,单击【基本信息】右侧的【编辑】按钮。如下图所示:

- 在“更新通知模版”页面,编辑模版信息。
- 单击【保存】按钮。
删除通知模版
- 登录 TKEStack。
- 切换至【业务管理】控制台,选择 【监控&告警】->【通知设置】->【通知模板】,查看"通知模板"列表。
- 选择要删除的模版,点击【删除】按钮。如下图所示:

- 单击删除窗口的【确定】按钮。
接收人
新建接收人
- 登录 TKEStack。
- 切换至【业务管理】控制台,选择 【监控&告警】->【通知设置】->【接收人】,查看"接收人"列表。
- 点击【新建】按钮。如下图所示:

- 在“新建接收人”页面填写模版信息。如下图所示:

- 显示名称: 接收人显示名称
- 用户名: 接收人用户名
- 移动电话: 手机号
- 电子邮件: 接收人邮箱
- 微信OpenID: 接收人微信ID
- 单击【保存】按钮。
编辑接收人信息
- 登录 TKEStack。
- 切换至【业务管理】控制台,选择 【监控&告警】->【通知设置】->【接收人】,查看“接收人”列表。
- 单击接收人名称。如下图所示:

- 在“基本信息”页面,单击【基本信息】右侧的【编辑】按钮。如下图所示:

- 在“更新接收人”页面,编辑接收人信息。
- 单击【保存】按钮。
删除接收人
- 登录 TKEStack。
- 切换至【业务管理】控制台,选择 【监控&告警】->【通知设置】->【接收人】,查看“接收人”列表。
- 选择要删除的接收人,点击【删除】按钮。如下图所示:

- 单击删除窗口的【确定】按钮。
接收组
新建接收组
- 登录 TKEStack。
- 切换至【业务管理】控制台,选择 【监控&告警】->【通知设置】->【接收组】,查看“接收组”列表。
- 点击【新建】按钮。如下图所示:

- 在“新建接收组”页面填写模版信息。如下图所示:

- 名称: 接收组显示名称
- 接收组: 从列表里选择接收人。如没有想要的接收人,请在接收人里创建。
- 单击【保存】按钮。
编辑接收组信息
- 登录 TKEStack。
- 切换至【业务管理】控制台,选择 【监控&告警】->【通知设置】->【接收组】,查看“接收组”列表。
- 单击接收组名称。如下图所示:

- 在“基本信息”页面,单击【基本信息】右侧的【编辑】按钮。如下图所示:

- 在“更新接收组”页面,编辑接收组信息。
- 单击【保存】按钮。
删除接收组
- 登录 TKEStack。
- 切换至【业务管理】控制台,选择 【监控&告警】->【通知设置】->【接收组】,查看“接收组”列表。
- 选择要删除的接收组,点击【删除】按钮。如下图所示:

- 单击删除窗口的【确定】按钮。
4.3.5 - 运维中心
运维中心
4.3.5.1 - Helm应用
应用功能是 TKEStack 集成的 Helm 3.0 相关功能,为您提供创建 helm chart、容器镜像、软件服务等各种产品和服务的能力。已创建的应用将在您指定的集群中运行,为您带来相应的能力。
新建 Helm 应用
- 登录 TKEStack
- 切换至【平台管理】控制台,选择【运维中心】->【 Helm 应用】
- 选择相应【集群】,单击【新建】按钮,如下图所示:
- 在“新建 Helm 应用”页面填写Helm应用信息,如下图所示:
- 应用名称: 输入应用名,1~63字符,只能包含小写字母、数字及分隔符("-"),且必须以小写字母开头,数字或小写字母结尾
- 运行集群: 选择应用所在集群
- 命名空间: 选择应用所在集群的命名空间
- 类型: 当前仅支持 HelmV3
- Chart: 选择需要部署的 chart
- Chart版本: 选择 chart 的版本
- 参数: 更新时如果选择不同版本的 Helm Chart,参数设置将被覆盖
- 拟运行: 会返回模板渲染清单,即最终将部署到集群的 YAML 资源,不会真正执行安装
- 单击【完成】按钮
删除 Helm 应用
- 登录 TKEStack
- 切换至【平台管理】控制台,选择【运维中心】->【 Helm 应用】
- 点击【删除】
查看 Helm 应用资源列表
- 登录 TKEStack
- 切换至【平台管理】控制台,选择【运维中心】->【 Helm 应用】
- 点击【应用名】后,点击【资源列表】,可查看该应用所有 Kubernetes 资源对象
查看 Helm 应用详情
- 登录 TKEStack
- 切换至【平台管理】控制台,选择【运维中心】->【 Helm 应用】
- 点击【应用名】后,点击【应用详情】
查看 Helm 应用版本历史
- 登录 TKEStack
- 切换至【平台管理】控制台,选择【运维中心】->【 Helm 应用】
- 点击【应用名】后,点击【版本历史】,可查看该应用所部署的历史版本。可以通过选择不同的版本进行参数对比查看其版本区别
4.3.5.2 - 日志采集
TKESTack 提供的集群内日志采集功能,支持将集群内服务或集群节点特定路径文件的日志发送至 Kafka、Elasticsearch 等消费端,支持采集容器标准输出日志,容器内文件日志以及主机内文件日志。更提供事件持久化、审计等功能,实时记录集群事件及操作日志记录,帮助运维人员存储和分析集群内部资源生命周期、资源调度、异常告警等情况

日志收集功能需要为每个集群手动开启。日志收集功能开启后,日志收集组件 logagent 会在集群内以 Daemonset 的形式运行。用户可以通过日志收集规则配置日志的采集源和消费端,日志收集 Agent 会从用户配置的采集源进行日志收集,并将日志内容发送至用户指定的消费端。需要注意的是,使用日志收集功能需要您确认 Kubernetes 集群内节点能够访问日志消费端。
- 采集容器标准输出日志 :采集集群内指定容器的 Stderr 和 Stdout 日志。,采集到的日志信息将会以 JSON 格式输出到用户指定的消费端,并会自动附加相关的 Kubernetes metadata, 包括容器所属 Pod 的 label 和 annotation 等信息。
- 采集容器内文件日志 :采集集群内指定容器内文件路径的日志,用户可以根据自己的需求,灵活的配置所需的容器和路径,采集到的日志信息将会以 JSON 格式输出到用户指定的消费端, 并会附加相关的 Kubernetes metadata,包括容器所属 pod 的 label 和 annotation 等信息。
- 采集主机内文件日志 :采集集群内所有节点的指定主机文件路径的日志,logagent 会采集集群内所有节点上满足指定路径规则的文件日志,以 JSON 格式输出到用户指定的输出端, 并会附加用户指定的 metadata,包括日志来源文件的路径和用户自定义的 metadata。
注意:日志采集对接外部 Kafka 或 Elasticsearch,该功能需要额外开启,位置在集群 基本信息 下面,点击开启“日志采集”服务

使用日志采集服务
业务管理侧
- 登录 TKEStack
- 切换至【业务管理】控制台,选择 【运维中心】->【日志采集】
- 选择相应【业务】和【命名空间】,单击【新建】按钮,如下图所示:

- 在“新建日志采集”页面填写日志采集信息,如下图所示:

- 收集规则名称: 输入规则名,1~63字符,只能包含小写字母、数字及分隔符("-"),且必须以小写字母开头,数字或小写字母结尾
- 业务: 选择所属业务(业务管理侧才会出现)
- 集群: 选择所属集群(平台管理侧才会出现)
- 类型: 选择采集类型
- 容器标准输出: 容器 Stderr 和 Stdout 日志信息采集
- 日志源: 可以选择所有容器或者某个 Namespace 下的所有容器/工作负载
- 所有容器: 所有容器
- 指定容器: 某个 Namespace 下的所有容器或者工作负载
- 日志源: 可以选择所有容器或者某个 Namespace 下的所有容器/工作负载
- 容器文件路径: 容器内文件内容采集
日志源: 可以采集具体容器内的某个文件路径下的文件内容
- 工作负载选项: 选择某个 Namespace 下的某种工作负载类型下的某个工作负载
- 配置采集路径: 选择某个容器下的某个文件路径
- 文件路径若输入
stdout,则转为容器标准输出模式 - 可配置多个路径。路径必须以
/开头和结尾,文件名支持通配符(*)。文件路径和文件名最长支持63个字符 - 请保证容器的日志文件保存在数据卷,否则收集规则无法生效,详见指定容器运行后的日志目录
- 节点文件路径: 收集节点上某个路径下的文件内容
- 日志源: 可以采集具体节点内的某个文件路径下的文件内容
- 收集路径: 节点上日志收集路径。路径必须以
/开头和结尾,文件名支持通配符(*)。文件路径和文件名最长支持63个字符
- 收集路径: 节点上日志收集路径。路径必须以
- metadata: key:value 格式,收集的日志会带上 metadata 信息上报给消费端
- 日志源: 可以采集具体节点内的某个文件路径下的文件内容
- 容器标准输出: 容器 Stderr 和 Stdout 日志信息采集
- 消费端: 选择日志消费端
- Kafka:
- 访问地址: Kafka IP 和端口
- 主题(Topic): Kafka Topic 名
- Elasticsearch:
Elasticsearch 地址: ES 地址,如:http://190.0.0.1:200
注意:当前只支持未开启用户登录认证的 ES 集群
索引: ES索引,最长60个字符,只能包含小写字母、数字及分隔符("-"、"_"、"+"),且必须以小写字母开头
- Kafka:
- 单击【完成】按钮
平台管理侧
在平台管理侧也支持日志采集规则的创建,创建方式和业务管理处相同。详情可点击平台侧的日志采集。
指定容器运行后的日志目录
LogAgent 除了支持日志规则的创建,也支持指定容器运行后的日志目录,可实现日志文件展示和下载。
前提:需要在创建负载时挂载数据卷,并指定日志目

创建负载以后,在容器内的/data/logdir目录下的所有文件可以展示并下载,例如我们在容器的/data/logdir下新建一个名为a.log的文件,如果有内容的话,也可以在这里展示与下载

4.3.6 -
Helm应用
概念
这里业务端用户可以管理通过 helm 创建的应用。
操作步骤
新建Helm应用
- 登录 TKEStack。
- 切换至 【业务管理】控制台,选择【 Helm应用】。
- 选择相应【业务】和【namespace】,单击【新建】按钮。如下图所示:
- 在“新建Helm应用”页面填写Helm应用信息。如下图所示:
- 应用名: 输入应用名,1~63字符,只能包含小写字母、数字及分隔符("-"),且必须以小写字母开头,数字或小写字母结尾
- 命名空间: 选择该应用运行的命名空间
- Chart_Url: 输入Chart 文件地址
- 类型: 选择应用类型
- 公有: 公有类型
- 私有: 私有类型
- 用户名: 私有用户名
- 密码: 私有密码
- Key-Value: 通过Key-Value替换Chart包中默认配置。
- 单击【完成】按钮。

5 - 特色功能
5.1 - TAPP
Kubernetes现有应用类型(如:Deployment、StatefulSet等)无法满足很多非微服务应用的需求,比如:操作(升级、停止等)应用中的指定pod、应用支持多版本的pod。如果要将这些应用改造为适合于这些workload的应用,需要花费很大精力,这将使大多数用户望而却步。
为解决上述复杂应用管理场景,基于Kubernetes CRD开发了一种新的应用类型TAPP,它是一种通用类型的workload,同时支持service和batch类型作业,满足绝大部分应用场景,它能让用户更好的将应用迁移到Kubernetes集群。

TAPP 特点
| 功能点 | Deployment | StatefulSet | TAPP |
|---|---|---|---|
| Pod唯一性 | 无 | 每个Pod有唯一标识 | 每个Pod有唯一标识 |
| Pod存储独占 | 仅支持单容器 | 支持 | 支持 |
| 存储随Pod迁移 | 不支持 | 支持 | 支持 |
| 自动扩缩容 | 支持 | 不支持 | 支持 |
| 批量升级 | 支持 | 不支持 | 支持 |
| 严格顺序更新 | 不支持 | 支持 | 不支持 |
| 自动迁移问题节点 | 支持 | 不支持 | 支持 |
| 多版本管理 | 同时只有1个版本 | 可保持2个版本 | 可保持多个版本 |
| Pod原地升级 | 不支持 | 不支持 | 支持 |
如果用Kubernetes的应用类型类比,TAPP ≈ Deployment + StatefulSet + Job ,它包含了Deployment、StatefulSet、Job的绝大部分功能,同时也有自己的特性,并且和原生Kubernetes相同的使用方式完全一致。
实例具有可以标识的id
实例有了id,业务就可以将很多状态或者配置逻辑和该id做关联,当容器迁移时,通过TAPP的容器实例标识,可以识别该容器原来对应的数据,实现带云硬盘或者数据目录迁移
每个实例可以绑定自己的存储
通过TAPP的容器实例标识,能很好地支持有状态的作业。在实例发生跨机迁移时,云硬盘能跟随实例一起迁移
实现真正的灰度升级/回退
Kubernetes中的灰度升级概念应为滚动升级,kubernetes将pod”逐个”的更新,但现实中多业务需要的是稳定的灰度,即同一个app,需要有多个版本同时稳定长时间的存在,TAPP解决了此类问题
可以指定实例id做删除、停止、重启等操作
对于微服务app来说,由于没有固定id,因此无法对某个实例做操作,而是全部交给了系统去维持足够的实例数
对每个实例都有生命周期的跟踪
对于一个实例,由于机器故障发生了迁移、重启等操作,很难跟踪和监控其生命周期。通过TAPP的容器实例标识,获得了实例真正的生命周期的跟踪,对于判断业务和系统是否正常服务具有特别重要的意义。TAPP还可以记录事件,以及各个实例的运行时间,状态,高可用设置等。
TAPP 资源结构
TApp定义了一种用户自定义资源(CRD),TAPP controller是TAPP对应的controller/operator,它通过kube-apiserver监听TApp、Pod相关的事件,根据TApp spec和status进行相应的操作:创建、删除pod等。
// TApp represents a set of pods with consistent identities.
type TApp struct {
metav1.TypeMeta `json:",inline"`
metav1.ObjectMeta `json:"metadata,omitempty"`
// Spec defines the desired identities of pods in this tapp.
Spec TAppSpec `json:"spec,omitempty"`
// Status is the current status of pods in this TApp. This data
// may be out of date by some window of time.
Status TAppStatus `json:"status,omitempty"`
}
// A TAppSpec is the specification of a TApp.
type TAppSpec struct {
// Replicas 指定Template的副本数,尽管共享同一个Template定义,但是每个副本仍有唯一的标识
Replicas int32 `json:"replicas,omitempty"`
// 同Deployment的定义,标签选择器,默认为Pod Template上的标签
Selector *metav1.LabelSelector `json:"selector,omitempty"`
// Template 默认模板,描述将要被初始创建/默认缩放的pod的对象,在TApp中可以被添加到TemplatePool中
Template corev1.PodTemplateSpec `json:"template"`
// TemplatePool 描述不同版本的pod template, template name --> pod Template
TemplatePool map[string]corev1.PodTemplateSpec `json:"templatePool,omitempty"`
// Statuses 用来指定对应pod实例的目标状态,instanceID --> desiredStatus ["Running","Killed"]
Statuses map[string]InstanceStatus `json:"statuses,omitempty"`
// Templates 用来指定运行pod实例所使用的Template,instanceID --> template name
Templates map[string]string `json:"templates,omitempty"`
// UpdateStrategy 定义滚动更新策略
UpdateStrategy TAppUpdateStrategy `json:"updateStrategy,omitempty"`
// ForceDeletePod 定义是否强制删除pod,默认为false
ForceDeletePod bool `json:"forceDeletePod,omitempty"`
// 同Statefulset的定义
VolumeClaimTemplates []corev1.PersistentVolumeClaim `json:"volumeClaimTemplates,omitempty"`
}
// 滚动更新策略
type TAppUpdateStrategy struct {
// 滚动更新的template name
Template string `json:"template,omitempty"`
// 滚动更新时的最大不可用数, 如果不指定此配置,滚动更新时不限制最大不可用数
MaxUnavailable *int32 `json:"maxUnavailable,omitempty"`
}
// 定义TApp的状态
type TAppStatus struct {
// most recent generation observed by controller.
ObservedGeneration int64 `json:"observedGeneration,omitempty"`
// Replicas 描述副本数
Replicas int32 `json:"replicas"`
// ReadyReplicas 描述Ready副本数
ReadyReplicas int32 `json:"readyReplicas"`
// ScaleSelector 是用于对pod进行查询的标签,它与HPA使用的副本计数匹配
ScaleLabelSelector string `json:"scaleLabelSelector,omitempty"`
// AppStatus 描述当前Tapp运行状态, 包含"Pending","Running","Failed","Succ","Killed"
AppStatus AppStatus `json:"appStatus,omitempty"`
// Statues 描述实例的运行状态 instanceID --> InstanceStatus ["NotCreated","Pending","Running","Updating","PodFailed","PodSucc","Killing","Killed","Failed","Succ","Unknown"]
Statuses map[string]InstanceStatus `json:"statuses,omitempty"`
}
使用示例
本节以一个TApp应用部署,配置,升级,扩容以及杀死删除的操作步骤来说明TApp的使用。
创建TApp应用
创建TApp应用,副本数为3,TApp-controller将根据默认模板创建出的pod
$ cat tapp.yaml
apiVersion: apps.tkestack.io/v1
kind: TApp
metadata:
name: example-tapp
spec:
replicas: 3
template:
metadata:
labels:
app: example-tapp
spec:
containers:
- name: nginx
image: nginx:1.7.9
$ kubect apply -f tapp.yaml
查看TApp应用
$ kubectl get tapp XXX
NAME AGE
example-tapp 20m
$ kubectl descirbe tapp example-tapp
Name: example-tapp
Namespace: default
Labels: app=example-tapp
Annotations: <none>
API Version: apps.tkestack.io/v1
Kind: TApp
...
Spec:
...
Status:
App Status: Running
Observed Generation: 2
Ready Replicas: 3
Replicas: 3
Scale Label Selector: app=example-tapp
Statuses:
0: Running
1: Running
2: Running
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulCreate 12m tapp-controller Instance: example-tapp-1
Normal SuccessfulCreate 12m tapp-controller Instance: example-tapp-0
Normal SuccessfulCreate 12m tapp-controller Instance: example-tapp-2
升级TApp应用
当前3个pod实例运行的镜像版本为nginx:1.7.9,现在要升级其中的一个pod实例的镜像版本为nginx:latest,在spec.templatPools中创建模板,然后在spec.templates中指定模板pod, 指定“1”:“test”表示使用模板test创建pod 1。
如果只更新镜像,Tapp controller将对pod进行原地升级,即仅更新重启对应的容器,否则将按k8s原生方式删除pod并重新创建它们。
apiVersion: apps.tkestack.io/v1
kind: TApp
metadata:
name: example-tapp
spec:
replicas: 3
template:
metadata:
labels:
app: example-tapp
spec:
containers:
- name: nginx
image: nginx:1.7.9
templatePool:
"test":
metadata:
labels:
app: example-tapp
spec:
containers:
- name: nginx
image: nginx:latest
templates:
"1": "test"
操作成功后,查看instanceID为'1’的pod已升级,镜像版本为nginx:latest
# kubectl describe tapp example-tapp
Name: example-tapp
Namespace: default
Labels: app=example-tapp
Annotations: kubectl.kubernetes.io/last-applied-configuration:
{"apiVersion":"apps.tkestack.io/v1","kind":"TApp","metadata":{"annotations":{},"name":"example-tapp","namespace":"default"},"spec":{"repli...
API Version: apps.tkestack.io/v1
Kind: TApp
...
Spec:
...
Templates:
1: test
Update Strategy:
Status:
App Status: Running
Observed Generation: 4
Ready Replicas: 3
Replicas: 3
Scale Label Selector: app=example-tapp
Statuses:
0: Running
1: Running
2: Running
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulCreate 25m tapp-controller Instance: example-tapp-1
Normal SuccessfulCreate 25m tapp-controller Instance: example-tapp-0
Normal SuccessfulCreate 25m tapp-controller Instance: example-tapp-2
Normal SuccessfulUpdate 10m tapp-controller Instance: example-tapp-1
# kubectl get pod | grep example-tapp
example-tapp-0 1/1 Running 0 27m
example-tapp-1 1/1 Running 1 27m
example-tapp-2 1/1 Running 0 27m
# kubectl get pod example-tapp-1 -o template --template='{{range .spec.containers}}{{.image}}{{end}}'
nginx:latest
上述升级过程可根据实际需求灵活操作,可以指定多个pod的版本,帮助用户实现灵活的应用升级策略 同时可以指定updateStrategy升级策略,保证升级是最大不可用数为1,即保证滚动升级时每次仅更新和重启一个容器或pod
# cat tapp.yaml
apiVersion: apps.tkestack.io/v1
kind: TApp
metadata:
name: example-tapp
spec:
replicas: 3
template:
metadata:
labels:
app: example-tapp
spec:
containers:
- name: nginx
image: nginx:1.7.9
templatePool:
"test":
metadata:
labels:
app: example-tapp
spec:
containers:
- name: nginx
image: nginx:latest
templates:
"1": "test"
"2": "test"
"0": "test"
updateStrategy:
template: test
maxUnavailable: 1
# kubectl apply -f tapp.yaml
杀死指定pod
在spec.statuses中指定pod的状态,tapp-controller根据用户指定的状态控制pod实例,例如,如果spec.statuses为“1”:“killed”,tapp控制器会杀死pod 1。
# cat tapp.yaml
kind: TApp
metadata:
name: example-tapp
spec:
replicas: 3
template:
metadata:
labels:
app: example-tapp
spec:
containers:
- name: nginx
image: nginx:1.7.9
templatePool:
"test":
metadata:
labels:
app: example-tapp
spec:
containers:
- name: nginx
image: nginx:latest
templates:
"1": "test"
"2": "test"
"0": "test"
updateStrategy:
template: test
maxUnavailable: 1
statuses:
"1": "Killed"
# kubectl apply -f tapp.yaml
查看pod状态变为Terminating
# kubectl get pod
NAME READY STATUS RESTARTS AGE
example-tapp-0 1/1 Running 1 59m
example-tapp-1 0/1 Terminating 1 59m
example-tapp-2 1/1 Running 1 59m
扩容TApp应用
如果你想要扩展TApp使用默认的spec.template模板,只需增加spec.replicas的值,否则你需要在spec.templates中指定使用哪个模板。kubectl scale也适用于TApp。
kubectl scale --replicas=3 tapp/example-tapp
删除TApp应用
kubectl delete tapp example-tapp
其它
Tapp还支持其他功能,如HPA、volume templates,它们与k8s中的其它工作负载类型类似。
5.2 - Galaxy
Kubernetes没有提供默认可用的容器网络,但kubernetes网络的设计文档要求容器网络的实现能做到下面的三点:
- all containers can communicate with all other containers without NAT
- all nodes can communicate with all containers (and vice-versa) without NAT
- the IP that a container sees itself as is the same IP that others see it as
即集群包含的每一个容器都拥有一个与其他集群中的容器和节点可直接路由的独立IP地址。但是Kubernetes并没有具体实现这样一个网络模型,而是实现了一个开放的容器网络标准CNI,可以自由选择使用开源的网络方案或者实现一套遵循CNI标准的网络,为用户提供两种网络类型:
- Overlay Network,即通用的虚拟化网络模型,不依赖于宿主机底层网络架构,可以适应任何的应用场景,方便快速体验。但是性能较差,因为在原有网络的基础上叠加了一层Overlay网络,封包解包或者NAT对网络性能都是有一定损耗的。
- Underlay Network,即基于宿主机物理网络环境的模型,容器与现有网络可以直接互通,不需要经过封包解包或是NAT,其性能最好。但是其普适性较差,且受宿主机网络架构的制约,比如MAC地址可能不够用。
为满足复杂应用容器化的特殊需求,大幅拓展了容器应用的场景,TKEStack利用Galaxy网络组件提供多种解决方案,支持overlay和underlay网络类型,支持高转发性能和高隔离性等场景应用。
Galaxy是一个Kubernetes网络项目,旨在为POD提供通用Overlay和高性能的Underlay网络。
TKEStack使用Galaxy网络组件,支持四种网络模式,并且可以为工作负载单独配置指定的网络模式,拓展了容器应用场景,满足复杂应用容器化的特殊需求。
Overlay网络
TKEStack的默认网络模式,基于IPIP和host gateway的flannel方案,同节点容器通信不走网桥,报文直接利用主机路由转发;跨节点容器通信利用IPIP协议封装, etcd记录节点间路由。该方案控制层简单稳定,网络转发性能优异,并且可以通过network policy实现多种网络策略。
Floating IP
容器IP由宿主机网络提供,打通了容器网络与underlay网络,容器与物理机可以直接路由,性能更好。容器与宿主机的二层连通, 支持了Linux bridge/MacVlan/IPVlan和SRIOV, 根据业务场景和硬件环境,具体选择使用哪种网桥
NAT
基于k8s中的hostPort配置,并且如果用户没有指定Port地址,galaxy会给实例配置容器到主机的随机端口映射
Host
利用k8s中的hostNetwork配置,直接使用宿主机的网络环境,最大的好处是其性能优势,但是需要处理端口冲突问题,并且也有安全隐患。
Galaxy架构
Galaxy在架构上由三部分组成:
- Galaxy: 以DaemonSet方式运行在每个节点上,通过调用各种CNI插件来配置k8s容器网络
- CNI plugins: 符合CNI标准的二进制文件,用于网络资源的配置和管理, 支持CNI插件Supported CNI plugins
- Galaxy IPAM: 通过tkestack中的IPAM扩展组件安装,K8S调度插件,kube-scheduler通过HTTP调用Galaxy-ipam的filter/priority/bind方法实现Float IP的配置和管理
Galaxy Overlay 网络

tke-installer安装tkestack并自动配置galaxy为overlay网络模式,在该模式下:
Flannel在每个Kubelet上分配一个子网,并将其保存在etcd和本地磁盘上(/run/ Flannel /subnet.env)
Kubelet根据CNI配置启动SDN CNI进程
1.SDN CNI进程通过unix socket调用Galaxy,所有的args都来自Kubelet
Galaxy调用FlannelCNI来解析来自/run/flannel/subnet.env的子网信息
Flannel CNI调用Bridge CNI或Veth CNI来为POD配置网络
Galaxy Underlay 网络

如需配置underlay网络,需要启用Galaxy-ipam组件,Galaxy-ipam根据配置为POD分配或释放IP:
- 规划容器网络使用的Underlay IP,配置floatingip-config ConfigMap
- Kubernetes调度器在filter/priority/bind方法上调用Galaxy-ipam
- Galaxy-ipam检查POD是否配置了reserved IP,如果是,则Galaxy-ipam仅将此IP所在的可用子网的节点标记为有效节点,否则所有都将被标记为有效节点。在POD绑定IP期间,Galaxy-ipam分配一个IP并将其写入到POD annotations中
- Galaxy从POD annotations获得IP,并将其作为参数传递给CNI,通过CNI配置POD IP
Galaxy配置
常见问题
为pod配置float ip网络模式失败 1. 检查ipam扩展组件是否已正确安装 1. 检查kube-scheduler是否正确配置scheduler-policy 1. 检查floatingip-config ConfigMap是否配置正确 1. 检查创建的Deployment工作负载: 1. 容器限额中配置 tke.cloud.tencent.com/eni-ip:1 1. 容器annotation中配置 k8s.v1.cni.cncf.io/networks=galaxy-k8s-vlan
如果上述配置都正确,pod会被成功创建并运行,galaxy-ipam会自动为pod分配指定的Float IP
为pod配置float ip网络模式后,如何与其他pod和主机通信
Galaxy为pod配置float ip网络模式,pod的nic和ip由宿主机网络提供,此pod的就加入了underlay的网络,因此pod间的通信以及pod与主机的通信就需要网络管理员在相应的交换机和路由器上配置对应的路由。
参考配置
本节展示了在一个正确配置了float-ip的deployment工作负载。
查看kube-scheduler的policy配置文件是否配置正确
# cat /etc/kubernetes/scheduler-policy-config.json
{
"apiVersion" : "v1",
"extenders" : [
{
"apiVersion" : "v1beta1",
"enableHttps" : false,
"filterVerb" : "predicates",
"managedResources" : [
{
"ignoredByScheduler" : false,
"name" : "tencent.com/vcuda-core"
}
],
"nodeCacheCapable" : false,
"urlPrefix" : "http://gpu-quota-admission:3456/scheduler"
},
{
"urlPrefix": "http://127.0.0.1:32760/v1",
"httpTimeout": 10000000000,
"filterVerb": "filter",
"prioritizeVerb": "prioritize",
"BindVerb": "bind",
"weight": 1,
"enableHttps": false,
"managedResources": [
{
"name": "tke.cloud.tencent.com/eni-ip",
"ignoredByScheduler": true
}
]
}
],
"kind" : "Policy"
}
查看floatingip-config配置
# kubectl get cm -n kube-system floatingip-config -o yaml
apiVersion: v1
data:
floatingips: '[{"routableSubnet":"172.21.64.0/20","ips":["192.168.64.200~192.168.64.251"],"subnet":"192.168.64.0/24","gateway":"192.168.64.1"}]'
kind: ConfigMap
metadata:
creationTimestamp: "2020-03-04T07:09:14Z"
name: floatingip-config
namespace: kube-system
resourceVersion: "2711974"
selfLink: /api/v1/namespaces/kube-system/configmaps/floatingip-config
uid: 62524e92-f37b-4db2-8ec0-b01d7a90d1a1
查看deployment配置float-ip
# kubectl get deploy nnn -o yaml
apiVersion: apps/v1
kind: Deployment
...
spec:
...
template:
metadata:
annotations:
k8s.v1.cni.cncf.io/networks: galaxy-k8s-vlan
k8s.v1.cni.galaxy.io/release-policy: immutable
creationTimestamp: null
labels:
k8s-app: nnn
qcloud-app: nnn
spec:
containers:
- image: nginx
imagePullPolicy: Always
name: nnn
resources:
limits:
cpu: 500m
memory: 1Gi
tke.cloud.tencent.com/eni-ip: "1"
requests:
cpu: 250m
memory: 256Mi
tke.cloud.tencent.com/eni-ip: "1"
查看生成的pod带有float-ip的annotations
# kubectl get pod nnn-7df5984746-58hjm -o yaml
apiVersion: v1
kind: Pod
metadata:
annotations:
k8s.v1.cni.cncf.io/networks: galaxy-k8s-vlan
k8s.v1.cni.galaxy.io/args: '{"common":{"ipinfos":[{"ip":"192.168.64.202/24","vlan":0,"gateway":"192.168.64.1","routable_subnet":"172.21.64.0/20"}]}}'
k8s.v1.cni.galaxy.io/release-policy: immutable
...
spec:
...
status:
...
hostIP: 172.21.64.15
phase: Running
podIP: 192.168.64.202
podIPs:
- ip: 192.168.64.202
查看crd中保存的floatingips绑定信息
# kubectl get floatingips.galaxy.k8s.io 192.168.64.202 -o yaml
apiVersion: galaxy.k8s.io/v1alpha1
kind: FloatingIP
metadata:
creationTimestamp: "2020-03-04T08:28:15Z"
generation: 1
labels:
ipType: internalIP
name: 192.168.64.202
resourceVersion: "2744910"
selfLink: /apis/galaxy.k8s.io/v1alpha1/floatingips/192.168.64.202
uid: b5d55f27-4548-44c7-b8ad-570814b55026
spec:
attribute: '{"NodeName":"172.21.64.15"}'
key: dp_default_nnn_nnn-7df5984746-58hjm
policy: 1
subnet: 172.21.64.0/20
updateTime: "2020-03-04T08:28:15Z"
查看所在主机上生成了对应的nic和ip
# ip route
default via 172.21.64.1 dev eth0
169.254.0.0/16 dev eth0 scope link metric 1002
172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1
172.21.64.0/20 dev eth0 proto kernel scope link src 172.21.64.15
...
192.168.64.202 dev v-hb21e7165d
5.3 - CronHPA
Cron Horizontal Pod Autoscaler(CronHPA)使我们能够使用crontab模式定期自动扩容工作负载(那些支持扩展子资源的负载,例如deployment、statefulset)。
CronHPA使用Cron格式进行编写,周期性地在给定的调度时间对工作负载进行扩缩容。
CronHPA 资源结构
CronHPA定义了一个新的CRD,cron-hpa-controller是该CRD对应的controller/operator,它解析CRD中的配置,根据系统时间信息对相应的工作负载进行扩缩容操作。
// CronHPA represents a set of crontabs to set target's replicas.
type CronHPA struct {
metav1.TypeMeta `json:",inline"`
metav1.ObjectMeta `json:"metadata,omitempty"`
// Spec defines the desired identities of pods in this cronhpa.
Spec CronHPASpec `json:"spec,omitempty"`
// Status is the current status of pods in this CronHPA. This data
// may be out of date by some window of time.
Status CronHPAStatus `json:"status,omitempty"`
}
// A CronHPASpec is the specification of a CronHPA.
type CronHPASpec struct {
// scaleTargetRef points to the target resource to scale
ScaleTargetRef autoscalingv2.CrossVersionObjectReference `json:"scaleTargetRef" protobuf:"bytes,1,opt,name=scaleTargetRef"`
Crons []Cron `json:"crons" protobuf:"bytes,2,opt,name=crons"`
}
type Cron struct {
// The schedule in Cron format, see https://en.wikipedia.org/wiki/Cron.
Schedule string `json:"schedule" protobuf:"bytes,1,opt,name=schedule"`
TargetReplicas int32 `json:"targetReplicas" protobuf:"varint,2,opt,name=targetReplicas"`
}
// CronHPAStatus represents the current state of a CronHPA.
type CronHPAStatus struct {
// Information when was the last time the schedule was successfully scheduled.
// +optional
LastScheduleTime *metav1.Time `json:"lastScheduleTime,omitempty" protobuf:"bytes,2,opt,name=lastScheduleTime"`
}
// +k8s:deepcopy-gen:interfaces=k8s.io/apimachinery/pkg/runtime.Object
// CronHPAList is a collection of CronHPA.
type CronHPAList struct {
metav1.TypeMeta `json:",inline"`
metav1.ListMeta `json:"metadata,omitempty"`
Items []CronHPA `json:"items"`
}
使用示例
指定deployment每周五20点扩容到60个实例,周日23点缩容到30个实例
apiVersion: extensions.tkestack.io/v1
kind: CronHPA
metadata:
name: example-cron-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: demo-deployment
crons:
- schedule: "0 20 * * 5"
targetReplicas: 60
- schedule: "0 23 * * 7"
targetReplicas: 30
指定deployment每天8点到9点,19点到21点扩容到60,其他时间点恢复到10
apiVersion: extensions.tkestack.io/v1
kind: CronHPA
metadata:
name: web-servers-cronhpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: web-servers
crons:
- schedule: "0 8 * * *"
targetReplicas: 60
- schedule: "0 9 * * *"
targetReplicas: 10
- schedule: "0 19 * * *"
targetReplicas: 60
- schedule: "0 21 * * *"
targetReplicas: 10
查看cronhpa
# kubectl get cronhpa
NAME AGE
example-cron-hpa 104s
# kubectl get cronhpa example-cron-hpa -o yaml
apiVersion: extensions.tkestack.io/v1
kind: CronHPA
...
spec:
crons:
- schedule: 0 20 * * 5
targetReplicas: 60
- schedule: 0 23 * * 7
targetReplicas: 30
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: demo-deployment
删除cronhpa
kubectl delete cronhpa example-cron-hpa
5.4 - GPU-Manager说明
组件介绍
GPU Manager提供一个All-in-One的GPU管理器, 基于Kubernets Device Plugin插件系统实现, 该管理器提供了分配并共享GPU, GPU指标查询, 容器运行前的GPU相关设备准备等功能, 支持用户在Kubernetes集群中使用GPU设备。
管理器包含如下功能:
- 拓扑分配:提供基于GPU拓扑分配功能, 当用户分配超过1张GPU卡的的应用, 可以选择拓扑连接最快的方式分配GPU设备
- GPU共享:允许用户提交小于1张卡资源的的任务, 并提供QoS保证
- 应用GPU指标的查询:用户可以访问主机的端口(默认为5678)的/metrics路径,可以为Prometheus提供GPU指标的收集功能, /usage路径可以提供可读性的容器状况查询
部署在集群内kubernetes对象
在集群内部署GPU-Manager Add-on , 将在集群内部署以下kubernetes对象
| kubernetes对象名称 | 类型 | 建议预留资源 | 所属Namespaces |
|---|---|---|---|
| gpu-manager-daemonset | DaemonSet | 每节点1核CPU, 1Gi内存 | kube-system |
| gpu-quota-admission | Deployment | 1核CPU, 1Gi内存 | kube-system |
GPU-Manager使用场景
在Kubernetes集群中运行GPU应用时, 可以解决AI训练等场景中申请独立卡造成资源浪费的情况,让计算资源得到充分利用。
GPU-Manager限制条件
- 该组件基于Kubernetes DevicePlugin实现, 只能运行在支持DevicePlugin的TKE的1.10kubernetes版本之上。
- 每张GPU卡一共有100个单位的资源, 仅支持0-1的小数卡,以及1的倍数的整数卡设置. 显存资源是以256MiB为最小的一个单位的分配显存。
- 使用GPU-Manager 要求集群内包含GPU机型节点。
GPU-Manager使用方法
- 安装GPU-Manager扩展组件
- 在安装了GPU-Manager扩展组件的集群中,创建工作负载。
- 创建工作负载设置GPU限制,如图:
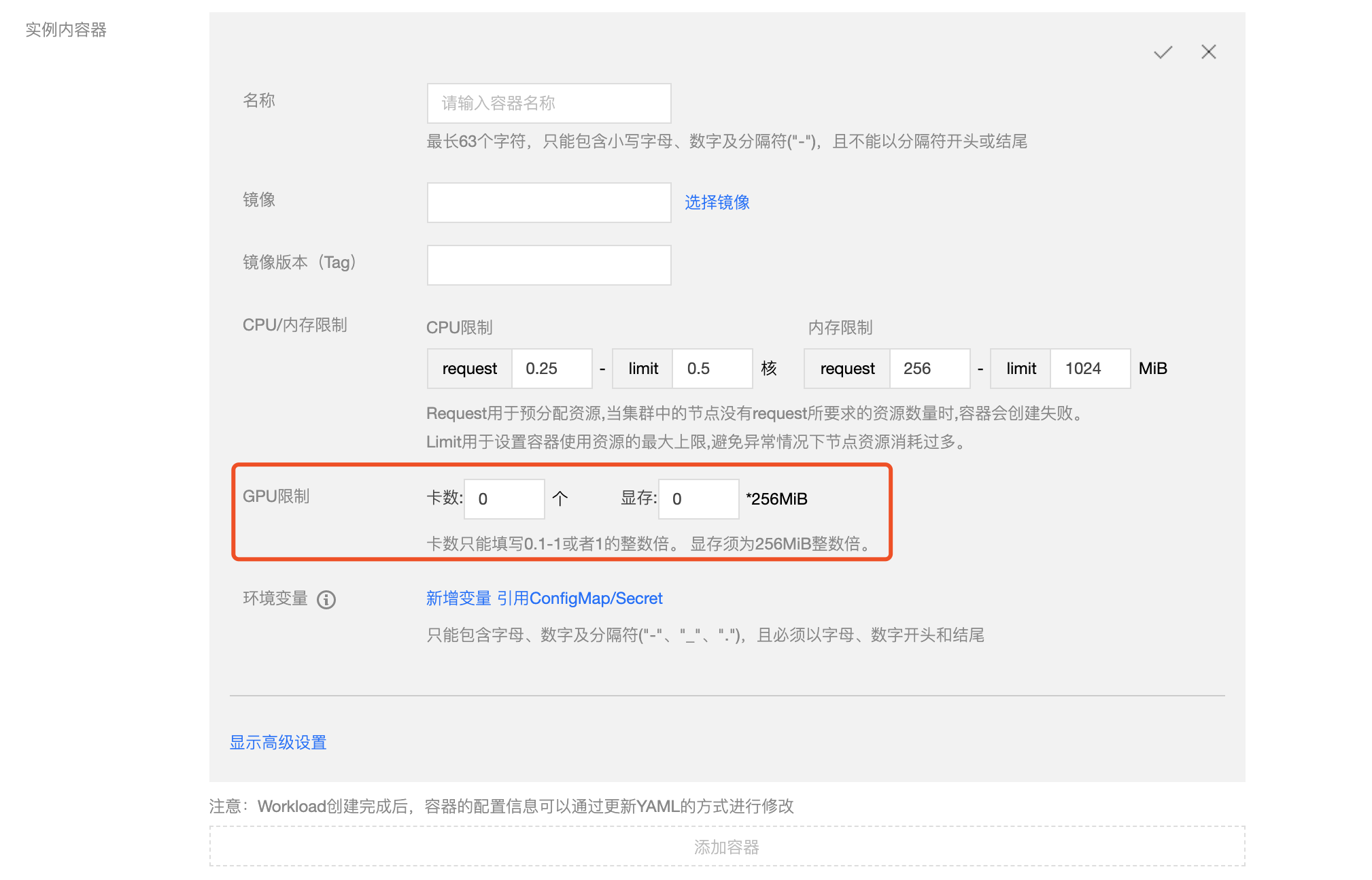
yaml创建
如果使用yaml创建工作负载,提交的时候需要在yaml为容器设置GPU的的使用资源, 核资源需要在resource上填写tencent.com/vcuda-core, 显存资源需要在resource上填写tencent.com/vcuda-memory,
- 使用1张卡
apiVersion: v1
kind: Pod
...
spec:
containers:
- name: gpu
resources:
tencent.com/vcuda-core: 100
- 使用0.3张卡, 5GiB显存的应用(20*256MB)
apiVersion: v1
kind: Pod
...
spec:
containers:
- name: gpu
resources:
tencent.com/vcuda-core: 30
tencent.com/vcuda-memory: 20
5.5 - LBCF说明
组件介绍 : Load Balancer Controlling Framework (LBCF)
LBCF是一款部署在Kubernetes内的通用负载均衡控制面框架,旨在降低容器对接负载均衡的实现难度,并提供强大的扩展能力以满足业务方在使用负载均衡时的个性化需求。
部署在集群内kubernetes对象
在集群内部署LBCF Add-on , 将在集群内部署以下kubernetes对象
| kubernetes对象名称 | 类型 | 默认占用资源 | 所属Namespaces |
|---|---|---|---|
| lbcf-controller | Deployment | / | kube-system |
| lbcf-controller | ServiceAccount | / | kube-system |
| lbcf-controller | ClusterRole | / | / |
| lbcf-controller | ClusterRoleBinding | / | / |
| lbcf-controller | Secret | / | kube-system |
| lbcf-controller | Service | / | kube-system |
| backendrecords.lbcf.tkestack.io | CustomResourceDefinition | / | / |
| backendgroups.lbcf.tkestack.io | CustomResourceDefinition | / | / |
| loadbalancers.lbcf.tkestack.io | CustomResourceDefinition | / | / |
| loadbalancerdrivers.lbcf.tkestack.io | CustomResourceDefinition | / | / |
| lbcf-mutate | MutatingWebhookConfiguration | / | / |
| lbcf-validate | ValidatingWebhookConfiguration | / | / |
LBCF使用场景
LBCF对K8S内部晦涩的运行机制进行了封装并以Webhook的形式对外暴露,在容器的全生命周期中提供了多达8种Webhook。通过实现这些Webhook,开发人员可以轻松实现下述功能:
- 对接任意负载均衡/名字服务,并自定义对接过程
- 实现自定义灰度升级策略
- 容器环境与其他环境共享同一个负载均衡
- 解耦负载均衡数据面与控制面
LBCF使用方法
- 通过扩展组件安装LBCF
- 开发或选择安装LBCF Webhook规范的要求实现Webhook服务器
- 以下按腾讯云CLB开发的webhook服务器为例
详细的使用方法和帮助文档,请参考lb-controlling-framework文档
使用示例
使用已有四层CLB
本例中使用了id为lb-7wf394rv的负载均衡实例,监听器为四层监听器,端口号为20000,协议类型TCP。
注: 程序会以端口号20000,协议类型TCP为条件查询监听器,若不存在,会自动创建新的
apiVersion: lbcf.tkestack.io/v1beta1
kind: LoadBalancer
metadata:
name: example-of-existing-lb
namespace: kube-system
spec:
lbDriver: lbcf-clb-driver
lbSpec:
loadBalancerID: "lb-7wf394rv"
listenerPort: "20000"
listenerProtocol: "TCP"
ensurePolicy:
policy: Always
创建新的七层CLB
本例在vpc vpc-b5hcoxj4中创建了公网(OPEN)负载均衡实例,并为之创建了端口号为9999的HTTP监听器,最后会在监听器中创建mytest.com/index.html的转发规则
apiVersion: lbcf.tkestack.io/v1beta1
kind: LoadBalancer
metadata:
name: example-of-create-new-lb
namespace: kube-system
spec:
lbDriver: lbcf-clb-driver
lbSpec:
vpcID: vpc-b5hcoxj4
loadBalancerType: "OPEN"
listenerPort: "9999"
listenerProtocol: "HTTP"
domain: "mytest.com"
url: "/index.html"
ensurePolicy:
policy: Always
设定backend权重
本例展示了Service NodePort的绑定。被绑定Service的名称为svc-test,service port为80(TCP),绑定到CLB的每个Node:NodePort的权重都是66
apiVersion: lbcf.tkestack.io/v1beta1
kind: BackendGroup
metadata:
name: web-svc-backend-group
namespace: kube-system
spec:
lbName: test-clb-load-balancer
service:
name: svc-test
port:
portNumber: 80
parameters:
weight: "66"
附录
腾讯云CLB LBCF driver
ConfigMap:
apiVersion: v1
kind: ConfigMap
metadata:
name: trusted-tencentcloudapi
namespace: kube-system
data:
tencentcloudapi.pem: |
-----BEGIN CERTIFICATE-----
.............
-----END CERTIFICATE-----
Deployment
apiVersion: lbcf.tkestack.io/v1beta1
kind: LoadBalancerDriver
metadata:
name: lbcf-clb-driver
namespace: kube-system
spec:
driverType: Webhook
url: "http://lbcf-clb-driver.kube-system.svc"
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: lbcf-clb-driver
namespace: kube-system
spec:
replicas: 1
selector:
matchLabels:
lbcf.tkestack.io/component: lbcf-clb-driver
template:
metadata:
labels:
lbcf.tkestack.io/component: lbcf-clb-driver
spec:
priorityClassName: "system-node-critical"
containers:
- name: driver
image: ${image-name}
args:
- "--region=${your-region}"
- "--vpc-id=${your-vpc-id}"
- "--secret-id=${your-account-secret-id}"
- "--secret-key=${your-account-secret-key}"
ports:
- containerPort: 80
name: insecure
imagePullPolicy: Always
volumeMounts:
- name: trusted-ca
mountPath: /etc/ssl/certs
readOnly: true
volumes:
- name: trusted-ca
configMap:
name: trusted-tencentcloudapi
Service:
apiVersion: v1
kind: Service
metadata:
labels:
name: lbcf-clb-driver
namespace: kube-system
spec:
ports:
- name: insecure
port: 80
targetPort: 80
selector:
lbcf.tkestack.io/component: lbcf-clb-driver
sessionAffinity: None
type: ClusterIP
6 - 最佳实践
6.1 - K8S 版本升级说明
TKEStack提供升级 Kubernetes 版本的功能,您可通过此功能对运行中的 Kubernetes 集群进行升级。在升级 kubernetes 版本之前,建议您查阅 CHANGELOG 确认Kubernetes 版本差异。
Concept
主版本:k8s版本号的格式vx.y.z中的x为主版本,例如v1.18.3主版本是1
次要版本:k8s版本号的格式vx.y.z中的y为次要版本,例如v1.18.3的次要版本是18
补丁版本:k8s版本号的格式vx.y.z中的z为补丁版本
升级须知
1.升级属于不可逆操作、请谨慎进行。
2.请在升级集群前,查看集群下业务状态是否均为健康状态。
3.升级期间不建议对集群进行任何操作。
4.仅支持次要版本和补丁版本升级,不支持降级,不支持跨多个版本升级(例如1.16跳过1.17直接升级至1.18),且仅当集群内 Master 版本和 Node 版本一致时才可继续升级下一个版本。
升级技术原理
升级的过程为:升级包准备、升级 Master 和升级 Node。
1.升级包准备
当前运行集群所需要的镜像二进制等都保存在tke-installer中,已经安装好的TKEStack已包含至少三个连续的 K8S 版本,如TKEStack v1.5.0 中包含K8S v1.16.9, v1.17.13 和 v1.18.3,同时也包含了对应的kubeadm,kubelet和kubectl版本。
2.升级Master
Master升级采用滚动升级的方式,同一时间只会对一个节点进行升级,只有当前节点升级成功才会进行下个节点的升级。
Master升级调用kubeadm 处理集群的升级操作,Kubeadm 工作原理参考:how it works
3.升级Node
节点原地升级,采用滚动升级的方式,即同一时间只会对一个节点进行升级,只有当前节点升级成功后才会进行下个节点的升级。每个节点升级时执行以下操作:
- 替换和重启节点上的 kubelet组件。
- 从集群取回 kubeadm ClusterConfiguration。
- 为本节点升级 kubelet 配置
操作步骤
1.登录 平台管理 控制台,选择左侧导航栏中的【集群管理】。
2.在“集群管理”页面,选择需要升级的集群,点击右侧的【升级Master】按钮,进入集群升级页面。
3.在集群升级页面配置升级所需参数,如下图所示:
4.在点击提交按钮,等待升级完成。同时可以点击【状态】按钮查看升级状态。
5.如果上述配置没有选择【自动升级worker】,在Master节点升级完成后,点击【升级worker】,进入node升级页面。
6.在node升级页面配置node节点升级所需参数,如下图所示:
7.在点击提交按钮,等待升级完成。同时可以点击【状态】按钮查看当前升级状态。
###其他技术细节
1.升级中任何步骤出现错误,系统都将自动进行重试,用户可在升级进度界面中得到错误信息。
风险点与规避措施
Master节点升级存在一定风险,用户在升级前,应检查集群状态是否足够健康,从而判断是否开始master节点升级,本节列举一些较为典型的风险及规避方法供用户参考。
重启kubelet的风险点
1.Not Ready Pod 数目超过设置值导致升级卡死
选择了【驱逐节点】选项,同时节点过少,而设置【最大不可用pod数】比例过低,没有足够多的节点承载pod的迁移会导致升级卡死。
规避措施:
- 尽如果业务对pod可用比例较高,请考虑选择升级前不驱逐节点。
2.kubelet进程无法启动
当该master节点资源十分紧张的时候,启动kubelet有可能失败,从而导致节点升级无法正常完成。
规避措施:
- 尽量不要将业务Pod运行于master节点
- 确保节点资源不能处于高度紧张状态
3.容器重启
某些版本kubelet与旧版本对于container的管理有一定差异,有可能导致节点上所有container重启
规避措施:
- 加强container的重启容忍度,例如确保deployment的副本数不为1
FQA
1.何时使用K8S升级功能:
答:当集群版本不满足业务需求,K8S漏洞修复,或当前集群版本低于TKEStack所能支持的最小版本。
2.升级的目标版本能否选择:
答:目前只支持升级到下一个次要版本,例如1.16.x的集群只能升到1.17.x;或者升级到补丁版本,例如1.16.x升级到 1.16.z
3.为什么我看不到升级worker按钮:
答:只有当前集群所有worker节点版本与master节点版本相同时,才允许进行master版本升级。
4.是否支持回滚:
答:不支持回滚操作。
5.自行修改的参数怎么办
答:master升级将会把用户自行修改的参数重置成与新建集群时的一致,若用户有特殊参数修改,建议升级完成后手动添加。
6.升级时出现异常情况如何处理?
答:升级过程中有可能出现意想不到的问题而导致升级失败或升级过程被卡住。针对失败发生的时间点不同,管理员处理策略有所不同。
- 失败发生在k8s集群版本号变化之前:
此时k8集群版本号未发生变化,首节点尚未升级,可回滚。可以将Cluster.Spec.Version的版本号修改为与当前k8s版本一致,集群便可恢复正常运行状态。
- 失败发生在k8s集群版本号变化之后:
此时集群的首节点已经升级成功,原则上不允许回滚到低版本。需要管理员排查其他节点没有按照预期进行升级到原因,解决问题后升级流程会自动向前推进。
7.Not Ready Pod数目超过设置值导致升级卡死
答:升级时遇到Not Ready Pod数目超过设置值导致升级卡死的情况,检查是否是由于驱逐导致的Not Ready状态,可尝试修改cluster.spec.features.upgrade.strategy. drainNodeBeforeUpgrade,设置false不驱逐节点, 或调大 maxUnready 值,以允许容忍更多的Not Ready Pod。
案例分析
升级时间点选择不当
- 案例详情:集群 A 的运维人员在工作日业务高峰期进行节点升级操作,由于没有配置合理的扩缩容机制,业务 Pod 一直处于高负载状态,某个节点升级失败导致该节点 Pod 重启,剩余 Pod 无法满足高峰期时段的业务负载导致出现大量访问异常,业务受到较为严重的影响。
- 最佳实践:选择业务低峰期进行节点升级将大大降低业务受影响的概率。
成功案例
- 案例详情:集群 D 计划进行节点升级。运维人员决定先升级测试集群,成功后再升级生产集群,并将升级时间选在业务负载较低的周五凌晨2点。升级前,他通过监控面板观察到各目标节点的负载情况都较低,再通过节点详情页观察每个节点上 Pod 分布较为合理。第一个节点开始升级后,运维人员点击了暂停升级任务,随后第一个节点升级完成后任务到达暂停点自动转为暂停状态。运维人员再次检查被升级节点,确认无异常后点击继续任务,升级动作继续进行。在随后升级过程中,运维人员时刻观察集群和业务情况,直到升级全部完成。成功升级测试集群后,运维人员继续以同样的步骤成功升级生产集群。
- 最佳实践:1.先升级测试集群或者开发集群,成功后再升级生产集群;2. 时间选择合理;3. 升级前检查集群状态;4.先升级少量节点观察并解决问题;5.升级过程中继续保持观察。
6.2 - 自定义k8s版本升级
用户可以通过向TKEStack平台提供自定义版本的k8s,以允许集群升级到非内置的版本。本文将以v1.16.15版本的k8s作为例子演示用户如何将集群升级到自定义版本。本文中只以amd64环境作为示例,如果用户希望自己的物料镜像可以支持multi-CPU architecture,请在制作镜像和推送镜像阶段参考Leverage multi-CPU architecture support和构建多CPU架构支持的Docker镜像。
制作provider-res镜像
provider镜像用于存储kubeadm、kubelet和kubectl的二进制文件。
执行下面命令为环境设置好版本号,并从官方下载好二进制文件并压缩,若遇到网络问题请通过其他途径下载对应二进制文件:
export RELEASE=v1.16.15 && \
curl -L --remote-name-all https://storage.googleapis.com/kubernetes-release/release/$RELEASE/bin/linux/amd64/{kubeadm,kubelet,kubectl} && \
chmod +x kubeadm kubectl kubelet && \
mkdir -p kubernetes/node/bin/ && \
cp kubelet kubectl kubernetes/node/bin/ && \
tar -czvf kubeadm-linux-amd64-$RELEASE.tar.gz kubeadm && \
tar -czvf kubernetes-node-linux-amd64-$RELEASE.tar.gz kubernete
执行下面命令生成dockerfiel:
cat << EOF >Dockerfile
FROM tkestack/provider-res:v1.18.3-2
WORKDIR /data
COPY kubernetes-*.tar.gz res/linux-amd64/
COPY kubeadm-*.tar.gz res/linux-amd64/
ENTRYPOINT ["sh"]
EOF
制作provider-res镜像:
docker build -t registry.tke.com/library/provider-res:myversion .
此处使用了默认的registry.tke.com作为registry的domian,如未使用默认的domain请修改为自定义的domain,下文中如遇到registry.tke.com也做相同处理。
为平台准备必要镜像
从官方下载k8s组件镜像,如遇到网络问题请通过其他途径下载:
docker pull k8s.gcr.io/kube-scheduler:$RELEASE && \
docker pull k8s.gcr.io/kube-controller-manager:$RELEASE && \
docker pull k8s.gcr.io/kube-apiserver:$RELEASE && \
docker pull k8s.gcr.io/kube-proxy:$RELEAS
重新为镜像为镜像打标签:
docker tag k8s.gcr.io/kube-proxy:$RELEASE registry.tke.com/library/kube-proxy:$RELEASE && \
docker tag k8s.gcr.io/kube-apiserver:$RELEASE registry.tke.com/library/kube-apiserver:$RELEASE && \
docker tag k8s.gcr.io/kube-controller-manager:$RELEASE registry.tke.com/library/kube-controller-manager:$RELEASE && \
docker tag k8s.gcr.io/kube-scheduler:$RELEASE registry.tke.com/library/kube-scheduler:$RELEASE
导出镜像:
docker save -o kube-proxy.tar registry.tke.com/library/kube-proxy:$RELEASE && \
docker save -o kube-apiserver.tar registry.tke.com/library/kube-apiserver:$RELEASE && \
docker save -o kube-controller-manager.tar registry.tke.com/library/kube-controller-manager:$RELEASE && \
docker save -o kube-scheduler.tar registry.tke.com/library/kube-scheduler:$RELEASE && \
docker save -o provider-res.tar registry.tke.com/library/provider-res:myversion
发送到global集群节点上:
scp kube*.tar provider-res.tar root@your_global_node:/root/
在global集群上导入物料
注意在此之后执行到命令都是发生在global集群节点上,为了方便首先在环境中设置版本号:
加载镜像:
docker load -i kube-apiserver.tar && \
docker load -i kube-controller-manager.tar && \
docker load -i kube-proxy.tar && \
docker load -i kube-scheduler.tar && \
docker load -i provider-res.tar
登陆registry:
docker login registry.tke.co
此处会提示输入用户名密码,如果默认使用了内置registry,用户名密码为admin的用户名密码,如果配置了第三方镜像仓库,请使用第三方镜像仓库的用户名密码。
登陆成功后推送镜像到registry:
docker push registry.tke.com/library/kube-apiserver:$RELEASE && \
docker push registry.tke.com/library/kube-controller-manager:$RELEASE && \
docker push registry.tke.com/library/kube-proxy:$RELEASE && \
docker push registry.tke.com/library/kube-scheduler:$RELEASE && \
docker push registry.tke.com/library/provider-res:myversion
为使得导入物料可以被平台使用,首先需要修改tke-platform-controller的deployment:
kubectl edit -n tke deployments tke-platform-controller
修改spec.template.spec.initContainers[0].image中的内容为刚刚制作的provider-res镜像registry.tke.com/library/provider-res:myversion。
其次需要修改cluster-info:
kubectl edit -n kube-public configmaps cluster-info
在data.k8sValidVersions内容中添加"1.16.15"。
升级集群到自定义版本
触发集群升级需要在global集群上修改cluster资源对象内容:
kubectl edit cluster cls-yourcluster
修改spec.version中的内容为1.16.15。
更详细的升级相关文档请参考:K8S 版本升级说明。
目前Web UI不允许补丁版本升级,会导致可以在UI升级选项中可以看到
1.16.15版本,但是提示无法升级到该版本,后续版本中将会修复。当前请使用kubectl�修改cluster资源对象内容升级自定义版本。
6.3 - wx 私有化部署最佳实践
[TOC]
wx tkestack 私有化部署最佳实践
背景
随着私有化项目越来越多,简单快捷部署交付需求日益强烈。在开源协同大行其道,私有化一键部署如何合理利用开源协同力量做到用好80%,做好20% 值得思而深行而简。本文将揭秘私有化一键部署结合tkestack 实现私有化一键部署最佳实践面纱。
方案选型
虽然开源协同大行其道,但合适才是最好基本原则仍然需要贯彻执行 – 量体裁衣;结合开发难度,开发效率,后期代码维护,组件维护,实施人员使用难度,实施人员现场修改难度等多维度进行考量。方案如下:
- kubeadm+ansible: **优点:**对kubernetes版本,网络插件,docker 版本自主可控; **缺点:**维护成本高,特别kubernetes升级,,无法专注于业务层面的一键部署;
- tkestack+ansible: **优点:**对于kubernetes的集成,维护无需关心,只需要用好tkestack也就掌握tkestack的基本原理做好应急;专注于业务层面的一键部署集成即可。通过ansible进行机器批量初始化,部署方便快捷对于实施人员要求低,可以随时现场修改; 缺点: kubernetes 版本,网络插件,docker 版本不自主可控;
- tkestack+operator: **优点:**私有化一键部署产品化,平台化; **缺点:**operator开发成本高,客户环境多变复杂,出现问题没法现场修改;
综合上述方案考虑维护kubernetes成本有点高,另外tkestack+ansible通过hooks方式进行扩展,能实现快速集成,可以专注于业务组件集成即可;ansible 入手容易,降低实施人员学习成本,并且可以随时根据现场环境随时修改适配;综合考量选择tkestack+ansible 模式。
需求
功能性需求:
| 功能 | 说明 |
|---|---|
| 主机初始化 | 安装前进行主机初始化,比如添加域名hosts,安装压测工具,离线yum源等 |
| 主机检查 | 检查当前主机的性能是否符合需求,磁盘大小是否符合需求,操作系统版本,内核版本,性能压测等 |
| tkestack部署 | 部署kuberntes和tkestack |
| 业务依赖组件部署 | 部署业务依赖组件,比如redis,mysql,部署运维组件elk,prometheus等 |
| 业务部署 | 部署业务服务 |
非功能性需求:
| 功能 | 说明 |
|---|---|
| 解耦 | 针对一些已有kubernetes/tke 平台,此时需要只部署业务依赖组件及业务,所以需要和tkestack解耦 |
| 扩展性 | 业务依赖组件不同项目需要采用不同的依赖组件,需要快捷集成新的组件 |
| 幂等 | 部署及卸载时可以重复执行 |
实现
1. 走进tkesack
从tkestack git 获取到的架构图可以看出tkestack分为installer, Global,cluster这三种角色;其中installer 负责tkestack Global集群的安装,当前提供命令行安装模式和图形化安装模式;cluster 角色是作为业务集群,通Global集群纳管。当前我们只需要部署一个Global集群作为业务集群即可满足需求,cluster集群只是为了提供给客户使用tkestack多集群管理使用。
tkestack 在installer 以hooks 方式实现用户自定义扩展, 有如下hook脚本:
- pre-installer: 主要集群部署前的一些自定义初始化操作
- post-cluster-ready: 种子集群ready后针对tkestack 部署前的初始化操作
- post-install: tkestack 部署完毕,部署自定义扩展
默认tkestack部署流程如下:
由于installer 节点在tkestack 设计上计划安装完毕直接废弃,所以tkestack 会在global集群重新部署一个镜像仓库作为后续业务使用,当然也会将tkestack 平台的镜像重新repush到集群内的镜像仓库。所以容器化的自定义扩展主件的部署需要放到post-install 脚本进行触发。
2. 魔改部署配置
- tkestack git 使用手册给出了两种部署模式一种是web页面配置模式,一种是命令行模式;经过使用发现tkestack有个亮点特性就是配置文件记录了一个step 安装步骤,可以在安装失败后解决问失败原因直接重启tke-installer 即可根据当前step 步骤继续进行安装部署;我们利用这特性实现web页面配置模式也可以命令行模式部署。具体操作是先通过页面配置得到配置文件,把配置文件做成模板; 部署时候通过ansible templet 模块进行渲染。 当前抽取出来配置模板有:
- tke-ha-lb.json.j2 对应web页面的使用已有,也就是采用负载均衡ip地址作为tkestack集群高可用
- tke-ha-keepalived.json.j2 对应web页面的TKE提供,采用vip通过keepalived 浮动漂移实现高可用
- tke-sigle.json.j2 对应web页面的不设置场景, 也就是单master版场景 以下以tke-ha-lb.json.j2 为例:
{
"config": {
"ServerName": "tke-installer",
"ListenAddr": ":8080",
"NoUI": false,
"Config": "conf/tke.json",
"Force": false,
"SyncProjectsWithNamespaces": false,
"Replicas": {{ tke_replicas }}
},
"para": {
"cluster": {
"kind": "Cluster",
"apiVersion": "platform.tkestack.io/v1",
"metadata": {
"name": "global"
},
"spec": {
"finalizers": [
"cluster"
],
"tenantID": "default",
"displayName": "TKE",
"type": "Baremetal",
"version": "{{ k8s_version }}",
"networkDevice": "{{ net_interface }}",
"clusterCIDR": "{{ cluster_cidr }}",
"dnsDomain": "cluster.local",
"features": {
"ipvs": {{ ipvs }},
"enableMasterSchedule": true,
"ha": {
"thirdParty": {
"vip": "{{ tke_vip }}",
"vport": {{ tke_vport}}
}
}
},
"properties": {
"maxClusterServiceNum": {{ max_cluster_service_num }},
"maxNodePodNum": {{ max_node_pod_num }}
},
"machines": [
{
"ip": "{{ groups['masters'][0] }}",
"port": {{ ansible_port }},
"username": "{{ ansible_ssh_user }}",
"password": "{{ ansible_ssh_pass_base64 }}"
},
{
"ip": "{{ groups['masters'][1] }}",
"port": {{ ansible_port }},
"username": "{{ ansible_ssh_user }}",
"password": "{{ ansible_ssh_pass_base64 }}"
},
{
"ip": "{{ groups['masters'][2] }}",
"port": {{ ansible_port }},
"username": "{{ ansible_ssh_user }}",
"password": "{{ ansible_ssh_pass_base64 }}"
}
],
"dockerExtraArgs": {
"data-root": "{{ docker_data_root }}"
},
"kubeletExtraArgs": {
"root-dir": "{{ kubelet_root_dir }}"
},
"apiServerExtraArgs": {
"runtime-config": "apps/v1beta1=true,apps/v1beta2=true,extensions/v1beta1/daemonsets=true,extensions/v1beta1/deployments=true,extensions/v1beta1/replicasets=true,extensions/v1beta1/networkpolicies=true,extensions/v1beta1/podsecuritypolicies=true"
}
}
},
"Config": {
"basic": {
"username": "{{ tke_admin_user }}",
"password": "{{ tke_pwd_base64 }}"
},
"auth": {
"tke": {
"tenantID": "default",
"username": "{{ tke_admin_user }}",
"password": "{{ tke_pwd_base64 }}"
}
},
"registry": {
"tke": {
"domain": "{{ tke_registry_domain }}",
"namespace": "library",
"username": "{{ tke_admin_user }}",
"password": "{{ tke_pwd_base64 }}"
}
},
"business": {},
"monitor": {
"influxDB": {
"local": {}
}
},
"ha": {
"thirdParty": {
"vip": "{{ tke_vip }}",
"vport": {{ tke_vport}}
}
},
"gateway": {
"domain": "{{ tke_console_domain }}",
"cert": {
"selfSigned": {}
}
}
}
},
"cluster": {
"kind": "Cluster",
"apiVersion": "platform.tkestack.io/v1",
"metadata": {
"name": "global"
},
"spec": {
"finalizers": [
"cluster"
],
"tenantID": "default",
"displayName": "TKE",
"type": "Baremetal",
"version": "{{ k8s_version }}",
"networkDevice": "{{ net_interface }}",
"clusterCIDR": "{{ cluster_cidr }}",
"dnsDomain": "cluster.local",
"features": {
"ipvs": {{ ipvs }},
"enableMasterSchedule": true,
"ha": {
"thirdParty": {
"vip": "{{ tke_vip }}",
"vport": {{ tke_vport}}
}
}
},
"properties": {
"maxClusterServiceNum": {{ max_cluster_service_num }},
"maxNodePodNum": {{ max_node_pod_num }}
},
"machines": [
{
"ip": "{{ groups['masters'][0] }}",
"port": {{ ansible_port }},
"username": "{{ ansible_ssh_user }}",
"password": "{{ ansible_ssh_pass_base64 }}"
},
{
"ip": "{{ groups['masters'][1] }}",
"port": {{ ansible_port }},
"username": "{{ ansible_ssh_user }}",
"password": "{{ ansible_ssh_pass_base64 }}"
},
{
"ip": "{{ groups['masters'][2] }}",
"port": {{ ansible_port }},
"username": "{{ ansible_ssh_user }}",
"password": "{{ ansible_ssh_pass_base64 }}"
}
],
"dockerExtraArgs": {
"data-root": "{{ docker_data_root }}"
},
"kubeletExtraArgs": {
"root-dir": "{{ kubelet_root_dir }}"
},
"apiServerExtraArgs": {
"runtime-config": "apps/v1beta1=true,apps/v1beta2=true,extensions/v1beta1/daemonsets=true,extensions/v1beta1/deployments=true,extensions/v1beta1/replicasets=true,extensions/v1beta1/networkpolicies=true,extensions/v1beta1/podsecuritypolicies=true"
}
}
},
"step": 0 # 重启tke-installer 后会按此步骤执行继续的安装,当前设置为0意味着从零开始
}
为了实现此方式安装,我们的安装脚本如下:
#!/bin/bash
# Author: yhchen
set -e
BASE_DIR=$(cd `dirname $0` && pwd)
cd $BASE_DIR
# get offline-pot parent dir
OFFLINE_POT_PDIR=`echo ${BASE_DIR} | awk -Foffline-pot '{print $1}'`
INSTALL_DIR=/opt/tke-installer
DATA_DIR=${INSTALL_DIR}/data
HOOKS=${OFFLINE_POT_PDIR}offline-pot
IMAGES_DIR="${OFFLINE_POT_PDIR}offline-pot-images"
TGZ_DIR="${OFFLINE_POT_PDIR}offline-pot-tgz"
REPORTS_DIR="${OFFLINE_POT_PDIR}perfor-reports"
version=v1.2.4
init_tke_installer(){
if [ `docker images | grep tke-installer | grep ${version} | wc -l` -eq 0 ]; then
if [ `docker ps -a | grep tke-installer | wc -l` -gt 0 ]; then
docker rm -f tke-installer
fi
if [ `docker images | grep tke-installer | wc -l` -gt 0 ]; then
docker rmi -f `docker images | grep tke-installer | awk '{print $3}'`
fi
cd ${OFFLINE_POT_PDIR}tkestack
if [ -d "${OFFLINE_POT_PDIR}tkestack/tke-installer-x86_64-${version}.run.tmp" ]; then
rm -rf ${OFFLINE_POT_PDIR}tkestack/tke-installer-x86_64-${version}.run.tmp
fi
sha256sum --check --status tke-installer-x86_64-$version.run.sha256 && \
chmod +x tke-installer-x86_64-$version.run && ./tke-installer-x86_64-$version.run
fi
}
reinstall_tke_installer(){
if [ -d "${REPORTS_DIR}" ]; then
mkdir -p ${REPORTS_DIR}
fi
if [ `docker ps -a | grep tke-installer | wc -l` -eq 1 ]; then
docker rm -f tke-installer
rm -rf /opt/tke-installer/data
fi
docker run --restart=always --name tke-installer -d --privileged --net=host -v/etc/hosts:/app/hosts \
-v/etc/docker:/etc/docker -v/var/run/docker.sock:/var/run/docker.sock -v$DATA_DIR:/app/data \
-v$INSTALL_DIR/conf:/app/conf -v$HOOKS:/app/hooks -v$IMAGES_DIR:${IMAGES_DIR} -v${TGZ_DIR}:${TGZ_DIR} \
-v${REPORTS_DIR}:${REPORTS_DIR} tkestack/tke-installer:$version
if [ -f "hosts" ]; then
# set hosts file's dpl_dir variable
sed -i 's#^dpl_dir=.*#dpl_dir=\"'"${HOOKS}"'\"#g' hosts
installer_ip=`cat hosts | grep -A 1 '\[installer\]' | grep -v installer`
echo "please exec install-offline-pot.sh or access http://${installer_ip}:8080 to install offline-pot"
fi
}
main(){
init_tke_installer # 此函数是为了实现当前节点尚未安装过tke-installer, 进行第一次安装实现初始化
reinstall_tke_installer # 此函数是实现自定义安装tke-installer, 主要是为了将扩展的hooks脚本挂载到tke-installer,以及hooks脚本调用到的整个一键部署脚本。
}
main
最终实现开始部署tkestack脚本如下:
#!/bin/bash
# Author: yhchen
set -e
BASE_DIR=$(cd `dirname $0` && pwd)
cd $BASE_DIR
CALL_FUN="defaut"
help(){
echo "show usage:"
echo "init_and_check: will be init hosts, inistall tke-installer and hosts check"
echo "dpl_offline_pot: init tke config and deploy offline-pot"
echo "init_keepalived: just tmp use, when tkestack fix keepalived issue will be remove"
echo "only_install_tkestack: if you want only install tkestack, please -f parameter pass only_install_tkestack"
echo "defualt: will be exec dpl_offline_pot and init_keepalived"
echo "all_func: execute init_and_check, dpl_offline_pot, init_keepalived"
exit 0
}
while getopts ":f:h:" opt
do
case $opt in
f)
CALL_FUN="${OPTARG}"
;;
h)
hosts="${OPTARG}"
;;
?)
echo "unkown args! just suport -f[call function] and -h[ansible hosts group] arg!!!"
exit 0;;
esac
done
INSTALL_DATA_DIR=/opt/tke-installer/data/
init_and_check(){
sh ./init-and-check.sh
}
# init tke config and deploy offline-pot
dpl_offline_pot(){
echo "###### deploy offline-pot start ######"
if [ `docker ps | grep tke-installer | wc -l` -eq 1 ]; then
# deploy tkestack , base commons and business
sh ./offline-pot-cmd.sh -s init-tke-config.sh -f init
docker restart tke-installer
if [ -f "hosts" ]; then
installer_ip=`cat hosts | grep -A 1 '\[installer\]' | grep -v installer`
echo "please exec tail -f ${INSTALL_DATA_DIR}/tke.log or access http://${installer_ip}:8080 check install progress..."
fi
elif [ ! -d "../tkestack" ]; then
# deploy base commons and business on other kubernetes plat
sh ./post-install
else
echo "if first install,please exec init-and-check.sh script, else exec reinstall-offline-pot.sh script" && exit 0
fi
echo "###### deploy offline-pot end ######"
}
# just tmp use, when tkestack fix keepalived issue will be remove
init_keepalived(){
echo "###### init keepalived start ######"
if [ -f "${INSTALL_DATA_DIR}/tke.json" ]; then
if [ `cat ${INSTALL_DATA_DIR}/tke.json | grep -i '"ha"' | wc -l` -gt 0 ]; then
nohup sh ./init_keepalived.sh 2>&1 > ${INSTALL_DATA_DIR}/dpl-keepalived.log &
fi
fi
echo "###### init keepalived end ######"
}
# only install tkestack
only_install_tkestack(){
echo "###### install tkestack start ######"
# change tke components's replicas number
if [ -f "hosts" ]; then
sed -i 's/tke_replicas="1"/tke_replicas="2"/g' hosts
fi
# hosts init
if [ `docker ps | grep tke-installer | wc -l` -eq 1 ]; then
sh ./offline-pot-cmd.sh -s host-init.sh -f sshd_init
sh ./offline-pot-cmd.sh -s host-init.sh -f selinux_init
sh ./offline-pot-cmd.sh -s host-init.sh -f remove_devnet_proxy
sh ./offline-pot-cmd.sh -s host-init.sh -f add_domains
sh ./offline-pot-cmd.sh -s host-init.sh -f data_disk_init
sh ./offline-pot-cmd.sh -s host-init.sh -f check_iptables
else
echo "please exec install-tke-installer.sh to start tke-installer" && exit 0
fi
# start install tkestack
dpl_offline_pot
init_keepalived
echo "###### install tkestack end ######"
}
defaut(){
# change tke components's replicas number
if [ -f "hosts" ]; then
sed -i 's/tke_replicas="2"/tke_replicas="1"/g' hosts
fi
# only deploy tkestack
if [ -d '../tkestack' ] && [ ! -d "../offline-pot-images" ] && [ ! -d "../offline-pot-tgz" ]; then
only_install_tkestack
fi
dpl_offline_pot
# when deploy tkestack will be init keepalived config
if [ -d '../tkestack' ]; then
init_keepalived
fi
}
all_func(){
# change tke components's replicas number
if [ -f "hosts" ]; then
sed -i 's/tke_replicas="2"/tke_replicas="1"/g' hosts
fi
init_and_check
defaut
}
main(){
$CALL_FUN || help
}
main
此脚本主要是判断当前部署是否需要部署tkestack或者是否单独部署tkestack,若是部署tkestack则生成tkestack 所需的配置文件,然后通过docker restart tke-installer 即可出发tkestack部署以及业务依赖组件,业务部署。
添加worker节点
增加自定义参数使集群更稳,更强。主要增加自定义参数如下:
1. dockerExtraArgs data-root 制定docker 目录到数据盘,避免系统盘太小导致节点磁盘使用率很快到达节点压力阈值以至于节点处于not ready状态 2. kubeletExtraArgs kubelete自定义参数 root-dir 和docker data-root 参数作用一致 3. kubeletExtraArgs kube-apiserver runtime-config apps/v1beta1=true,apps/v1beta2=true,extensions/v1beta1/daemonsets=true,extensions/v1beta1/deployments=true,extensions/v1beta1/replicasets=true,extensions/v1beta1/networkpolicies=true,extensions/v1beta1/podsecuritypolicies=true 增加工作负载deployment
,statefulset的api version兼容性
当前通过ansible set facts 方式,ansible when 条件执行,以及shell 命令增加判断方式实现幂等;通过设置开关+hooks+ansible tag方式实现扩展性和解耦。
最终私有化一键部署流程如下:
#### 3. 业务应用
业务通过helmfile release(release名称必须以${中心名}-${客户名简称})来组织不同客户部署不同的业务组件,不同release对应到不同的业务组件的helm chart value,当打包业务helm时会根据release ${中心名}-${客户名简称}.yaml文件定义的业务组件进行过滤打包,完成业务按需部署。
私有化一键部署时会通过helmfile 工具进行部署,如上图所示。
更新过程私有化一键部署当前不纳入管控,只负责将 agent 部署到master1 节点作为cicd执行更新agent,具体流程如上图所示。
合理利用tkestack特性(用好80%),结合自身业务场景做出满足需求私有化一键部署\(做好20%\)。
### 不足
* 当前所有镜像都是打成tar附件模式打包安装包,使得安装包有点大;同时部署集群镜像仓库时还需要从installer节点的镜像仓库重新将镜像推送至集群镜像仓库,这个耗时很大;建议将出包时将镜像推送到离线镜像仓库,然后将离线镜像仓库持久化目录打包这样合理利用镜像特性缩减安装包大小;部署时拷贝镜像仓库持久化数据到对应目录并挂载,加速部署。
6.4 - 使用存储的实践
本文以介绍如何在不同场景下选用合适的存储类型,并以实际的例子演示如何通过 TKEStack 部署和管理一个分布式存储服务,并以云原生的方式为容器化的应用提供高可用、高性能的存储服务。
简介
TKEStack 是腾讯开源的一款集易用性和扩展性于一身的企业级容器服务平台,帮助用户在私有云环境中敏捷、高效地构建和发布应用服务。TKEStack 本身不提供存储功能,但是可以通过集成云原生的存储应用,或者通过存储扩展组件的方式,对接用户的存储设施,扩展 TKEStack 平台的存储能力。
在本文中,通过 TKEStack 集成不同类型存储的介绍,帮助用户掌握云原生环境下存储的使用与管理,助力用户构建面向不同业务场景的容器云解决方案。
本文所介绍的实践方案基于社区开源的存储方案,以及部分云提供商的存储服务方案,TKEStack 不提供对存储服务的质量保证。用户请根据自身实际情况,选择合适的存储方案,或者联系 TKEStack 官方社区、论坛寻求帮助。
TKEStack 支持通过 CSI 存储插件的方式对接外部存储系统,详情请参考 TKEStack CSI Operator。
存储类型的选择
存储类型大致有三种:块存储、文件存储及对象存储
- 块存储:是以块为单位,块存储实际上是管理到数据块一级,相当于直接管理硬盘的数据块。高性能、低时延,满足随机读写,使用时需要格式化为指定的文件系统后才能访问。
- 文件存储:文件系统存储,文件系统是操作系统概念的一部份,支持 POSIX 的文件访问接口。优势是易管理、易共享,但由于采用上层协议, 因此开销大, 延时比块存储高。
- 对象存储:提供 Key-Value(简称 K/V)方式的 RESTful 数据读写接口,并且常以网络服务的形式提供数据的访问。优点是高可用性、全托管、易扩展。
上述几种存储类型各具特色,分别对应不同场景下的需求,例如:
- 块存储具备高性能的读写,提供原始块设备操作能力,非常适合作为一些数据库系统的底层存储。
- 文件系统有着与操作系统一致的 POSIX 文件访问接口,能够方便的在特定范围内共享文件空间,典型的场景是 AI 学习、模型训练场景下对训练数据,模型和结果的存储。
- 对象存储是近年来兴起的一种新的存储方式,适用于分布式云计算场景下的应用业务的海量,高并发的互联网产品场景。
更多存储系统的信息,请参考:wiki
块存储参考实践
本节将介绍如何通过 TKEStack 部署一套块存储系统,并演示如何在集群中使用该存储,在集群中部署 ElasticSearch 对外提供服务。
块存储系统有着较长的历史,基于传统 SAN 存储系统的方案已经非常成熟,但是 SAN 系统的价格较高,且可扩展性较差,难以满足大规模云计算系统下的使用需求。
但块存储本身具有的高带宽、低延迟,高吞吐率等优势,使它在云计算领域仍具有一席之地,典型的产品有 Ceph RBD,AWS EBS,腾讯云 CBS 等。
本节将以 Ceph RBD 为例,通过 Rook 在 TKEStack 容器平台中部署 Ceph RBD 块存储集群,对业务提供块存储服务。
Rook 是一个自管理的分布式存储编排系统,可以为 Kubernetes 提供便利的存储解决方案。
Rook 支持在 K8S 中部署,主要由 Operator 和 Cluster 两部分组成:
- Operator:Rook 的核心组件,自动启动存储集群,并监控存储守护进程,来确保存储集群的健康。
- Cluster:负责创建 CRD 对象,指定相关参数,包括 Ceph 镜像、元数据持久化位置、磁盘位置、dashboard 等等。
部署块存储系统
Rook 支持通过 helm 或 yaml 文件的方式进行部署,本文直接使用官方的 yaml 文件部署 Rook Ceph 存储集群。
登录 TKEStack 管理页面,进入集群管理页下,新建一个至少包括三台节点的集群
登录至该集群的任意节点下,下载 Rook 项目,通过官方例子部署 Rook 集群
git clone --single-branch --branch release-1.3 https://github.com/rook/rook.git cd rook/cluster/examples/kubernetes/ceph kubectl create -f common.yaml kubectl create -f operator.yaml kubectl create -f cluster.yaml
文件中有几个地方要注意:
- dataDirHostPath: 这个路径是会在宿主机上生成的,默认为 /var/lib/rook,保存的是 ceph 的相关的配置文件,再重新生成集群的时候要确保这个目录为空,否则 Ceph 监视器守护进程 MON 会无法启动
- useAllDevices: 使用节点上所有的设备,默认为 true,使用宿主机所有可用的磁盘
- useAllNodes:使用所有的 node 节点,默认为 true,使用用 k8s 集群内的所有 node 来搭建 Ceph
- network.hostNetwork: 使用宿主机的网络进行通讯,默认为 false,如果需要集群外挂载的场景可以开启这个选项
部署完毕后,检查 Rook 组件工作状态:
# kubectl get pod -n rook-ceph
NAME READY STATUS RESTARTS AGE
csi-rbdplugin-b52jx 3/3 Running 3 9d
csi-rbdplugin-jpmgv 3/3 Running 1 2d9h
csi-rbdplugin-provisioner-54cc7d5848-5fn8c 5/5 Running 0 2d8h
csi-rbdplugin-provisioner-54cc7d5848-w8dvk 5/5 Running 3 4d22h
csi-rbdplugin-z8dlc 3/3 Running 1 2d9h
rook-ceph-mgr-a-6775645c-7qg5t 1/1 Running 1 4d7h
rook-ceph-mon-a-98664df75-jm72n 1/1 Running 0 2d9h
rook-ceph-operator-676bcb686f-2kwmz 1/1 Running 0 9d
rook-ceph-osd-0-6949755785-gjpxw 1/1 Running 0 2d9h
rook-ceph-osd-1-647fdc4d84-6lvw2 1/1 Running 0 11d
rook-ceph-osd-2-c6c6db577-gtcpz 1/1 Running 0 2d8h
rook-ceph-osd-prepare-172.21.64.15-xngl7 0/1 Completed 0 2d8h
rook-ceph-osd-prepare-172.21.64.36-gv2kw 0/1 Completed 0 28d
rook-ceph-osd-prepare-172.21.64.8-bhffr 0/1 Completed 0 2d8h
rook-ceph-tools-864695994d-b7nb8 1/1 Running 0 2d7h
rook-discover-28fqr 1/1 Running 0 2d9h
rook-discover-m529m 1/1 Running 0 9d
rook-discover-t2jzc 1/1 Running 0 2d9h
至此一个完整的 Ceph RBD 集群就建立完毕,每台节点上都部署有 Ceph 对象存储守护进程 OSD,默认使用节点下的 /var/lib/rook 目录存储数据。
使用块存储部署 ElasticSearch
创建 Ceph pool,创建 StorageClass
# cat storageclass.yaml --- apiVersion: ceph.rook.io/v1 kind: CephBlockPool metadata: name: replicapool namespace: rook-ceph spec: failureDomain: host replicated: size: 1 # 池中数据的副本数 --- apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: global-storageclass provisioner: rook-ceph.rbd.csi.ceph.com parameters: # clusterID is the namespace where the rook cluster is running # If you change this namespace, also change the namespace below where the secret namespaces are defined clusterID: rook-ceph # Ceph pool into which the RBD image shall be created pool: replicapool # RBD image format. Defaults to "2". imageFormat: \"2\" # RBD image features. Available for imageFormat: "2". CSI RBD currently supports only layering feature. imageFeatures: layering # The secrets contain Ceph admin credentials. These are generated automatically by the operator # in the same namespace as the cluster. csi.storage.k8s.io/provisioner-secret-name: rook-csi-rbd-provisioner csi.storage.k8s.io/provisioner-secret-namespace: rook-ceph csi.storage.k8s.io/node-stage-secret-name: rook-csi-rbd-node csi.storage.k8s.io/node-stage-secret-namespace: rook-ceph # Specify the filesystem type of the volume. If not specified, csi-provisioner # will set default as ext4. csi.storage.k8s.io/fstype: ext4 # uncomment the following to use rbd-nbd as mounter on supported nodes #mounter: rbd-nbd reclaimPolicy: Delete通过 StorageClass 动态创建 PVC,检查 PVC 能够正确的创建并绑定
# cat pvc.yaml apiVersion: v1 kind: PersistentVolumeClaim metadata: name: rbd-pvc spec: accessModes: - ReadWriteOnce resources: requests: storage: 1Gi storageClassName: global-storageclass # kubectl get pvc NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE rbd-pvc Bound pvc-f9703e0d-9887-4bf2-8e31-1c3103a6ce2f 1Gi RWO global-storageclass 2s创建 ElasticSearch 应用,通过 StorageClass 动态申请块存储,使用 Ceph RBD 集群作为 ElasticSearch 的后端存储设备
# cat es.yaml apiVersion: v1 kind: Namespace metadata: name: efk --- apiVersion: apps/v1 kind: StatefulSet metadata: name: elasticsearch-master namespace: efk labels: app: elasticsearch-master spec: podManagementPolicy: Parallel serviceName: elasticsearch-master replicas: 3 selector: matchLabels: app: elasticsearch-master template: metadata: labels: app: elasticsearch-master spec: affinity: podAntiAffinity: preferredDuringSchedulingIgnoredDuringExecution: - weight: 1 podAffinityTerm: topologyKey: kubernetes.io/hostname labelSelector: matchLabels: app: "elasticsearch-master" initContainers: # see https://www.elastic.co/guide/en/elasticsearch/reference/current/vm-max-map-count.html # and https://www.elastic.co/guide/en/elasticsearch/reference/current/setup-configuration-memory.html#mlockall - name: "sysctl" image: "busybox" imagePullPolicy: "Always" command: ["sysctl", "-w", "vm.max_map_count=262144"] securityContext: allowPrivilegeEscalation: true privileged: true containers: - name: elasticsearch env: - name: cluster.name value: elasticsearch-cluster - name: discovery.zen.ping.unicast.hosts value: elasticsearch-master - name: discovery.zen.minimum_master_nodes value: "2" - name: KUBERNETES_NAMESPACE valueFrom: fieldRef: fieldPath: metadata.namespace # node roles, default to all true # - name: NODE_MASTER # value: "true" # - name: NODE_DATA # value: "true" # - name: NODE_INGEST # value: "true" - name: PROCESSORS valueFrom: resourceFieldRef: resource: limits.cpu - name: ES_JAVA_OPTS value: "-Djava.net.preferIPv4Stack=true -Xmx1g -Xms1g" resources: readinessProbe: httpGet: path: /_cluster/health?local=true port: 9200 initialDelaySeconds: 5 image: docker.elastic.co/elasticsearch/elasticsearch-oss:6.2.4 imagePullPolicy: IfNotPresent ports: - containerPort: 9300 name: transport - containerPort: 9200 name: http volumeMounts: - mountPath: /usr/share/elasticsearch/data name: elasticsearch-master volumes: terminationGracePeriodSeconds: 120 volumeClaimTemplates: - metadata: name: elasticsearch-master spec: accessModes: - ReadWriteOnce resources: requests: storage: 20Gi storageClassName: global-storageclass volumeMode: Filesystem --- apiVersion: v1 kind: Service metadata: name: elasticsearch-master namespace: efk labels: app: elasticsearch-master spec: type: ClusterIP ports: - name: http port: 9200 protocol: TCP targetPort: 9200 - name: transport port: 9300 protocol: TCP targetPort: 9300 selector: app: elasticsearch-master等待 ElasticSearch 实例建立完成,磁盘被正确的挂载
# kubectl get pod -n efk NAME READY STATUS RESTARTS AGE elasticsearch-master-0 1/1 Running 0 2d19h elasticsearch-master-1 1/1 Running 0 2d19h elasticsearch-master-2 1/1 Running 0 2d19h # kubectl get pvc -n efk NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE elasticsearch-master-elasticsearch-master-0 Bound pvc-405fc7b2-82eb-4eda-a6b7-e54d1713cbeb 20Gi RWO global-storageclass 41d elasticsearch-master-elasticsearch-master-1 Bound pvc-6e89f8d5-4702-4b2f-81c2-f9f89a249b0a 20Gi RWO global-storageclass 41d elasticsearch-master-elasticsearch-master-2 Bound pvc-16c9c1ab-4c77-463f-b5f0-fc643ced2fce 20Gi RWO global-storageclass 41d
块存储小结
按照本节指引,用户可以在 TKEStack 平台下创建出一个 Ceph RBD 块存储集群,并通过 StorageClass 方式动态的申请和使用块存储资源,并能够搭建出 ElasticSearch 应用对外提供服务。
由于块存储的特性,在 K8S 场景下仅支持 ReadWriteOnce 和 ReadOnlyMany 访问方式,并且这里的访问方式是节点级别的,例如 ReadOnlyMany, 只能被同一节点的多个 Pod 挂载,如果从多个节点挂载,系统会报 Multi-Attach 错误。
因此在 K8S 使用块存储场景上,基本上一个 Pod 挂载一个 PVC,典型的应用场景是 Redis,ElasticSearch,Mysql数据库等。
如果用户已存在块存储设备,TKEStack 支持通过 CSI 插件对接已有的存储设备,详情请参考 TKEStack CSI Operator。
文件存储参考实践
本节将介绍如何在 TKEStack 中部署一套文件存储系统,并演示如何在平台中使用该存储。
本节以 ChubaoFS (储宝文件系统)为例,通过在集群中部署和集成 ChubaoFS,向用户展示如何在 TKEStack 中使能文件存储功能。
ChubaoFS (储宝文件系统)是为大规模容器平台设计的分布式文件系统,详情请参考ChubaoFS 官方文档。
ChubaoFS 支持在 k8s 集群中部署,通过 Helm 的方式在集群中安装元数据子系统,数据子系统和资源管理节点等,对外提供文件存储服务。
部署文件存储系统
登录 TKEStack 管理页面,进入集群管理页下,新建一个至少包括五台节点的集群,并为该集群使能"Helm 应用管理"扩展组件
设置节点标签,ChubaoFS 将根据标签分配不同的组件到节点上运行
kubectl label node <nodename> chuabaofs-master=enabled kubectl label node <nodename> chuabaofs-metanode=enabled kubectl label node <nodename> chuabaofs-datanode=enabled登录到该集群下的一台节点上,下载 ChubaoFS 应用的 chart 包,根据环境修改 values.yaml 文件中的参数(本文使用默认值)
# ls chubaofs Chart.yaml config README.md templates values.yaml本地安装 Helm 客户端, 更多可查看 安装 Helm,使用 Helm 客户端安装 ChubaoFS ,等待安装完成
# helm install --name chubao ./chubaofs # ./helm status chubao安装完成后,检查所有组件工作正常
# kubectl get pod -n chubaofs NAME READY STATUS RESTARTS AGE client-c5c5b99f6-qqf7h 1/1 Running 0 17h consul-6d67d5c55-jgw9z 1/1 Running 0 18h datanode-9vqvm 1/1 Running 0 18h datanode-bgffs 1/1 Running 0 18h datanode-dtckp 1/1 Running 0 18h datanode-jtrzj 1/1 Running 0 18h datanode-p5nmc 1/1 Running 0 18h grafana-7cc9db7489-st27v 1/1 Running 0 18h master-0 1/1 Running 0 18h master-1 1/1 Running 0 18h master-2 1/1 Running 0 17h metanode-ghrpm 1/1 Running 0 18h metanode-gn5kl 1/1 Running 0 18h metanode-wqzwp 1/1 Running 0 18h prometheus-77d5d6cb7f-xs748 1/1 Running 0 18h kubectl get svc -n chubaofs NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE consul-service NodePort 192.168.255.116 <none> 8500:30831/TCP 20h grafana-service ClusterIP 192.168.255.16 <none> 3000/TCP 20h master-service NodePort 192.168.255.104 <none> 8080:32102/TCP 20h prometheus-service ClusterIP 192.168.255.4 <none> 9090/TCP 20h
使用文件存储系统
参考 ChubaoFS CSI 文档,在想要使用文件存储的集群上部署 ChubaoFS CSI Driver 插件
# git clone https://github.com/chubaofs/chubaofs-csi.git # cd chubaofs-csi # kubectl apply -f deploy/csi-controller-deployment.yaml # kubectl apply -f deploy/csi-node-daemonset.yaml创建 StorageClass,指定 master 和 consul 的访问地址
kind: StorageClass apiVersion: storage.k8s.io/v1 metadata: name: chubaofs-sc provisioner: csi.chubaofs.com reclaimPolicy: Delete parameters: masterAddr: "172.21.64.14:32102" # Master地址 owner: "csiuser" # cannot set profPort and exporterPort value, reason: a node may be run many cfs-client # profPort: "10094" # exporterPort: "9513" consulAddr: "172.21.64.14:30831" # 监控系统的地址 logLevel: "debug"通过 StorageClass 创建 PVC,创建使用 PVC 的应用
# cat pvc.yaml apiVersion: v1 kind: PersistentVolumeClaim metadata: name: chubaofs-pvc spec: accessModes: - ReadWriteOnce resources: requests: storage: 1Gi storageClassName: chubaofs-sc # cat deployment.yaml apiVersion: apps/v1 kind: Deployment metadata: name: cfs-csi-demo namespace: default spec: replicas: 1 selector: matchLabels: app: cfs-csi-demo-pod template: metadata: labels: app: cfs-csi-demo-pod spec: containers: - name: chubaofs-csi-demo image: nginx:1.17.9 imagePullPolicy: "IfNotPresent" ports: - containerPort: 80 name: "http-server" volumeMounts: - mountPath: "/usr/share/nginx/html" name: mypvc volumes: - name: mypvc persistentVolumeClaim: claimName: chubaofs-pvc
文件存储小结
通过上面的例子,用户可以创建一个 ChubaoFS 的文件系统集群,并通过 ChubaoFS CSI Driver 插件,将文件存储映射为 K8S 的资源(PVC,StorageClass)。
由于文件存储的支持多读多写的特性,使得用户在有共享存储需求的场景下,如 AI 计算、模型训练等,通过 TKEStack + ChubaoFS 的方案,快速构建出容器产品和解决方案。
如果用户已存在文件存储设备,TKEStack支持通过 CSI 插件对接已有的存储设备,详情请参考 TKEStack CSI Operator。
对象存储参考实践
本节介绍最后一个存储类型——对象存储, 对象存储的访问接口基本都是 RESTful API,用户可通过网络存储和查看数据,具备高扩展性、低成本、可靠和安全特性。
常见的对象存储有 Ceph 的 RADOS、OpenStack 的 Swift、AWS S3 等,并且各大主流的云提供商的都有提供对象存储服务,方便互联网用户快速地接入,实现了海量数据访问和管理。
本节将在一个公有云的环境下,申请云提供商提供的对象存储,通过标准的 S3 接口对接 TKEStack 的镜像仓库的服务,这样就可以将 TKEStack 平台下的镜像存储在对象存储中,方便扩展和管理。
申请对象存储
以腾讯云为例,登录控制台后进入对象存储产品中心,在存储桶列表页面下创建一个新的存储桶,创建成功后记录下访问域名,所属地域,访问 ID 和密钥等。
注:访问 ID 和密钥信息请参考腾讯云对象存储文档,更多关于对象存储的信息访问官网。
配置镜像仓库
TKEStack 提供镜像仓库功能,为用户提供容器镜像的上传,下载和管理功能,并且镜像仓库中保存平台所需的所有镜像,满足各种离线环境的需求。
如果按照默认方式安装配置,TKEStack 的镜像仓库默认使用 Global 集群下 Master 主机上的存储资源,该种方式占用了有限的主机资源,且不方便进行扩展和迁移,有必要对镜像仓库模块重新配置,使其对接对象存储,方便扩展。
登录 TKEStack 管理界面,进入 Global 集群配置管理,找到 tke 命名空间下的 tke-registry-api 配置(configmap),修改
storage字段如下tke-registry-config.yaml: | apiVersion: registry.config.tkestack.io/v1 kind: RegistryConfiguration storage: # fileSystem: # rootDirectory: /storage s3: bucket: xxxxxxxxxxxxx region: ap-beijing accessKey: xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx secretKey: xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx secure: false regionEndpoint: https://xxxxxxxxxxxxxx.cos.ap-beijing.myqcloud.com修改完成后,重启 tke 命名空间下的 tke-registry-api 的 pod,使配置生效,等待重启后 pod 恢复
此时镜像仓库已使用基于 S3 接口的对象存储,用户可以向该仓库推送或下载镜像,验证功能
注意:
- 由于更换了底层存储,重启后的镜像仓库中没有镜像,需要用户提前将原仓库中的所有镜像备份后,重新恢复至新的镜像仓库中
- 也可以在安装 TKEStack 平台时,为镜像仓库,以及监控存储配置对象存储服务,免去后期转移镜像和存储的操作,关于如何在安装时指定存储服务,详见高可用部署相关文章
对象存储小结
本节展示如果通过云提供商提供的对象存储服务,增强 TKEStack 的镜像仓库服务。在实际场景中,用户根据自身情况,选择合适的公有云上服务。
本文前面介绍的 Rook Ceph,ChubaoFS 等都支持对象存储服务,用户也可自行搭建本地的对象存储集群,详细指引参考对应产品的官网。
总结
综上所述,TKEStack 平台能够通过各种云原生及扩展组件的方式,对接和集成不同种类的存储服务,满足各类应用场景的需求。后续 TKEStack 还会继续增强在存储方面的功能,不断完善操作体验,使得容器平台存储功能具备易于上手,种类丰富,灵活扩展的能力。
参考链接
6.5 - 基于 Jenkins 的 CI/CD
持续构建与发布是日常工作中必不可少的一个步骤,目前大多公司都采用 Jenkins 集群来搭建符合需求的 CI/CD 流程,然而传统的 Jenkins Slave 一主多从方式会存在一些痛点,比如:
- 主 Master 发生单点故障时,整个流程都不可用了
- 每个 Slave 的配置环境不一样,来完成不同语言的编译打包等操作,但是这些差异化的配置导致管理起来非常不方便,维护起来也是比较费劲
- 资源分配不均衡,有的 Slave 要运行的 job 出现排队等待,而有的 Slave 处于空闲状态
- 资源有浪费,每台 Slave 可能是物理机或者虚拟机,当 Slave 处于空闲状态时,也不会完全释放掉资源。
正因为上面的这些种种痛点,渴望一种更高效更可靠的方式来完成这个 CI/CD 流程,而 Docker 虚拟化容器技术能很好的解决这个痛点,又特别是在 Kubernetes 集群环境下面能够更好来解决上面的问题,下图是基于 Kubernetes 搭建 Jenkins 集群的简单示意图:
从图上可以看到 Jenkins Master 和 Jenkins Slave 以 Pod 形式运行在 Kubernetes 集群的 Node 上,Master 运行在其中一个节点,并且将其配置数据存储到一个 Volume 上去,Slave 运行在各个节点上,并且它不是一直处于运行状态,它会按照需求动态的创建并自动删除。
这种方式的工作流程大致为:当 Jenkins Master 接受到 Build 请求时,会根据配置的 Label 动态创建一个运行在 Pod 中的 Jenkins Slave 并注册到 Master 上,当运行完 Job 后,这个 Slave 会被注销并且这个 Pod 也会自动删除,恢复到最初状态。
使用这种方式带来的好处:
- 服务高可用:当 Jenkins Master 出现故障时,Kubernetes 会自动创建一个新的 Jenkins Master 容器,并且将 Volume 分配给新创建的容器,保证数据不丢失,从而达到集群服务高可用。
- 动态伸缩:合理使用资源,每次运行 Job 时,会自动创建一个 Jenkins Slave,Job 完成后,Slave 自动注销并删除容器,资源自动释放,而且 Kubernetes 会根据每个资源的使用情况,动态分配 Slave 到空闲的节点上创建,降低出现因某节点资源利用率高,还排队等待在该节点的情况。
- 扩展性好:当 Kubernetes 集群的资源严重不足而导致 Job 排队等待时,可以很容易的添加一个 Kubernetes Node 到集群中,从而实现扩展。
安装 Jenkins Master
既然要基于Kubernetes来做CI/CD,这里需要将 Jenkins 安装到 Kubernetes 集群当中,新建一个 Deployment:(jenkins2.yaml)
前提:集群中可以使用 PVC
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: jenkins2
namespace: kube-ops
spec:
selector:
matchLabels:
app: jenkins2
template:
metadata:
labels:
app: jenkins2
spec:
terminationGracePeriodSeconds: 10
serviceAccount: jenkins2
containers:
- name: jenkins
image: jenkins/jenkins:lts
imagePullPolicy: IfNotPresent
ports:
- containerPort: 8080
name: web
protocol: TCP
- containerPort: 50000
name: agent
protocol: TCP
resources:
limits:
cpu: 1000m
memory: 1Gi
requests:
cpu: 500m
memory: 512Mi
livenessProbe:
httpGet:
path: /login
port: 8080
initialDelaySeconds: 60
timeoutSeconds: 5
failureThreshold: 12
readinessProbe:
httpGet:
path: /login
port: 8080
initialDelaySeconds: 60
timeoutSeconds: 5
failureThreshold: 12
volumeMounts:
- name: jenkinshome
subPath: jenkins2
mountPath: /var/jenkins_home
securityContext:
fsGroup: 1000
volumes:
- name: jenkinshome
persistentVolumeClaim:
claimName: opspvc
---
apiVersion: v1
kind: Service
metadata:
name: jenkins2
namespace: kube-ops
labels:
app: jenkins2
spec:
selector:
app: jenkins2
type: NodePort
ports:
- name: web
port: 8080
targetPort: web
nodePort: 30002
- name: agent
port: 50000
targetPort: agent
这里将所有的对象资源都放置在一个名为 kube-ops 的 namespace 下面:
$ kubectl create namespace kube-ops
这里使用一个名为 jenkins/jenkins:lts 的镜像,这是 jenkins 官方的 Docker 镜像,然后也有一些环境变量,当然也可以根据自己的需求来定制一个镜像,比如可以将一些插件打包在自定义的镜像当中,可以参考文档:https://github.com/jenkinsci/docker,我们这里使用默认的官方镜像就行,另外一个还需要注意的是将容器的 /var/jenkins_home 目录挂载到了一个名为 opspvc 的 PVC 对象上面,所以同样还得提前创建一个对应的 PVC 对象,当然也可以使用 StorageClass 对象来自动创建:(pvc.yaml)
apiVersion: v1
kind: PersistentVolume
metadata:
name: opspv
spec:
capacity:
storage: 20Gi
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Delete
nfs:
server: 42.194.158.74
path: /data/k8s
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: opspvc
namespace: kube-ops
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 20Gi
创建需要用到的 PVC 对象:
$ kubectl create -f pvc.yaml
另外这里还需要使用到一个拥有相关权限的 serviceAccount:jenkins2,我们这里只是给 jenkins 赋予了一些必要的权限,当然如果你对 serviceAccount 的权限不是很熟悉的话,给这个 SA 绑定一个 cluster-admin 的集群角色权限也是可以的,当然这样具有一定的安全风险:(rbac.yaml)
apiVersion: v1
kind: ServiceAccount
metadata:
name: jenkins2
namespace: kube-ops
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
name: jenkins2
rules:
- apiGroups: ["extensions", "apps"]
resources: ["deployments"]
verbs: ["create", "delete", "get", "list", "watch", "patch", "update"]
- apiGroups: [""]
resources: ["services"]
verbs: ["create", "delete", "get", "list", "watch", "patch", "update"]
- apiGroups: [""]
resources: ["pods"]
verbs: ["create","delete","get","list","patch","update","watch"]
- apiGroups: [""]
resources: ["pods/exec"]
verbs: ["create","delete","get","list","patch","update","watch"]
- apiGroups: [""]
resources: ["pods/log"]
verbs: ["get","list","watch"]
- apiGroups: [""]
resources: ["secrets"]
verbs: ["get"]
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: jenkins2
namespace: kube-ops
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: jenkins2
subjects:
- kind: ServiceAccount
name: jenkins2
namespace: kube-ops
创建 RBAC 相关的资源对象:
$ kubectl create -f rbac.yaml
serviceaccount "jenkins2" created
role.rbac.authorization.k8s.io "jenkins2" created
rolebinding.rbac.authorization.k8s.io "jenkins2" created
最后为了方便测试,这里通过 NodePort 的形式来暴露 Jenkins 的 web 服务,固定为 30002 端口,另外还需要暴露一个 agent 的端口,这个端口主要是用于 Jenkins 的 master 和 slave 之间通信使用的。
一切准备的资源准备好过后,直接创建 Jenkins 服务:
$ kubectl create -f jenkins2.yaml
deployment.extensions "jenkins2" created
service "jenkins2" created
创建完成后,要去拉取镜像可能需要等待一会儿,然后我们查看下 Pod 的状态:
$ kubectl get pods -n kube-ops
NAME READY STATUS RESTARTS AGE
jenkins2-7f5494cd44-pqpzs 0/1 Running 0 2m
可以看到该 Pod 处于 Running 状态,但是 READY 值确为 0,然后用 describe 命令去查看下该 Pod 的详细信息:
$ kubectl describe pod jenkins2-7f5494cd44-pqpzs -n kube-ops
...
Normal Created 3m kubelet, node01 Created container
Normal Started 3m kubelet, node01 Started container
Warning Unhealthy 1m (x10 over 2m) kubelet, node01 Liveness probe failed: Get http://10.244.1.165:8080/login: dial tcp 10.244.1.165:8080: getsockopt: connection refused
Warning Unhealthy 1m (x10 over 2m) kubelet, node01 Readiness probe failed: Get http://10.244.1.165:8080/login: dial tcp 10.244.1.165:8080: getsockopt: connection refused
可以看到上面的 Warning 信息,健康检查没有通过,可以通过查看日志进一步了解:
$ kubectl logs -f jenkins2-7f5494cd44-pqpzs -n kube-ops
touch: cannot touch '/var/jenkins_home/copy_reference_file.log': Permission denied
Can not write to /var/jenkins_home/copy_reference_file.log. Wrong volume permissions?
很明显可以看到上面的错误信息,意思就是:当前用户没有权限在 jenkins 的 home 目录下面创建文件,这是因为默认的镜像使用的是 jenkins 这个用户,而通过 PVC 挂载到 NFS 服务器的共享数据目录下面却是 root 用户的,所以没有权限访问该目录,要解决该问题,也很简单,只需要在 NFS 共享数据目录下面把目录权限重新分配下即可:
$ chown -R 1000 /data/k8s/jenkins2
当然还有另外一种方法是:自定义一个镜像,在镜像中指定使用 root 用户也可以
然后再重新创建:
$ kubectl delete -f jenkins.yaml
deployment.extensions "jenkins2" deleted
service "jenkins2" deleted
$ kubectl create -f jenkins.yaml
deployment.extensions "jenkins2" created
service "jenkins2" created
现在我们再去查看新生成的 Pod 已经没有错误信息了:
$ kubectl get pods -n kube-ops
NAME READY STATUS RESTARTS AGE
jenkins2-7f5494cd44-smn2r 1/1 Running 0 25s
等到服务启动成功后,我们就可以根据任意节点的 IP:30002 端口就可以访问 jenkins 服务了,可以根据提示信息进行安装配置即可: 初始化的密码可以在 jenkins 的容器的日志中进行查看,也可以直接在 NFS 的共享数据目录中查看:
$ cat /data/k8s/jenkins2/secrets/initialAdminPassword
然后选择安装推荐的插件即可:
安装完成后添加管理员帐号即可进入到 jenkins 主界面:
配置 Jenkins Slave
接下来就需要来配置 Jenkins,让他能够动态的生成 Slave 的 Pod。
第1步:需要安装 kubernetes plugin, 点击 Manage Jenkins -> Manage Plugins -> Available -> Kubernetes plugin 勾选安装即可。
第2步: 安装完毕后,点击 Manage Jenkins —> Configure System —> (拖到最下方的 Cloud,点击 a separate configuration page) —> Add a new cloud —> 选择 Kubernetes,然后填写 Kubernetes 和 Jenkins 配置信息。
Kubernetes 名称:kubernetes
Kubernetes 地址:https://kubernetes.default.svc.cluster.local
Kubernetes 命名空间: kube-ops
然后点击 连接测试,如果出现
Connected to Kubernetes 1.18的提示信息证明 Jenkins 已经可以和 Kubernetes 系统正常通信了。如果失败的话,很有可能是权限问题,这里就需要把创建的 jenkins 的 serviceAccount 对应的 secret 添加到这里的 Credentials 里面。Jenkins URL 地址:http://jenkins2.kube-ops.svc.cluster.local:8080
这里的格式为:服务名.namespace.svc.cluster.local:8080
第3步:配置 Pod Template,其实就是配置 Jenkins Slave 运行的 Pod 模板
- 名称:jnlp
- 命名空间:kube-ops
- Labels :haimaxy-jnlp,这里也非常重要,对于后面执行 Job 的时候需要用到该值
- 容器:使用 cnych/jenkins:jnlp 镜像,这个镜像是在官方的 jnlp 镜像基础上定制的,加入了 kubectl 等一些实用的工具
注意:由于新版本的 Kubernetes 插件变化较多,如果你使用的 Jenkins 版本在 2.176.x 版本以上,注意将上面的镜像替换成
cnych/jenkins:jnlp6,否则使用会报错,配置如下图所示:
另外需要注意挂载两个主机目录,一个是/var/run/docker.sock,该文件是用于 Pod 中的容器能够共享宿主机的 Docker,这就是大家说的 docker in docker 的方式,Docker 二进制文件我们已经打包到上面的镜像中了,另外一个目录下/root/.kube目录,将这个目录挂载到容器的/root/.kube目录下面这是为了能够在 Pod 的容器中能够使用 kubectl 工具来访问的 Kubernetes 集群,方便后面在 Slave Pod 部署 Kubernetes 应用。
另外还有几个参数需要注意,如下图中的Time in minutes to retain slave when idle,这个参数表示的意思是当处于空闲状态的时候保留 Slave Pod 多长时间,这个参数最好保存默认就行了,如果你设置过大的话,Job 任务执行完成后,对应的 Slave Pod 就不会立即被销毁删除。
另外一些用户在配置了后运行 Slave Pod 的时候出现了权限问题,因为 Jenkins Slave Pod 中没有配置权限,所以需要配置上 ServiceAccount,在 Slave Pod 配置的地方点击下面的高级,添加上对应的 ServiceAccount 即可:
还有一些用户在配置完成后发现启动 Jenkins Slave Pod 的时候,出现 Slave Pod 连接不上,然后尝试100次连接之后销毁 Pod,然后会再创建一个 Slave Pod 继续尝试连接,无限循环,类似于下面的信息:
如果出现这种情况的话就需要将 Slave Pod 中的运行命令和参数两个值给清空掉
到这里我们的 Kubernetes Plugin 插件就算配置完成了。
测试
Kubernetes 插件的配置工作完成了,接下来添加一个 Job 任务,看是否能够在 Slave Pod 中执行,任务执行完成后看 Pod 是否会被销毁。
在 Jenkins 首页点击 新建item,创建一个测试的任务,输入任务名称,然后选择 Freestyle project 类型的任务:
注意在下面的 Label Expression 这里要填入haimaxy-jnlp,就是前面配置的 Slave Pod 中的 Label,这两个地方必须保持一致
然后往下拉,在 Build 区域选择Execute shell
然后输入测试命令
echo "测试 Kubernetes 动态生成 jenkins slave"
echo "==============docker in docker==========="
docker info
echo "=============kubectl============="
kubectl get pods
最后点击保存:
现在直接在页面点击做成的 Build now 触发构建即可,然后观察 Kubernetes 集群中 Pod 的变化:
$ kubectl get pods -n kube-ops
NAME READY STATUS RESTARTS AGE
jenkins2-7c85b6f4bd-rfqgv 1/1 Running 3 1d
jnlp-9gjhr 0/1 ContainerCreating 0 7s
可以看到在点击“立刻构建”的时候可以看到一个新的 Pod:jnlp-9gjhr 被创建了,这就是 Jenkins Slave。任务执行完成后可以看到任务信息,如下图所示:比如这里是花费了 2.3s 时间在 jnlp-hfmvd 这个 Slave上面:
如果没有看见新的 Pod:jnlp-9gjhr,可能原因是已经构建完成,Pod 被自动删除了。
同样也可以查看到对应的控制台信息:
到这里证明任务已经构建完成,然后这个时候再去集群查看我们的 Pod 列表,发现 kube-ops 这个 namespace 下面已经没有之前的 Slave 这个 Pod 了。
$ kubectl get pods -n kube-ops
NAME READY STATUS RESTARTS AGE
jenkins2-7c85b6f4bd-rfqgv 1/1 Running 3 1d
Jenkins Pipeline
要实现在 Jenkins 中的构建工作,可以有多种方式,比如 Pipeline。简单来说,就是一套运行在 Jenkins 上的工作流框架,将原来独立运行于单个或者多个节点的任务连接起来,实现单个任务难以完成的复杂流程编排和可视化的工作。
Jenkins Pipeline 核心概念:
- Node:节点,一个 Node 就是一个 Jenkins 节点,Master 或者 Agent,是执行 Step 的具体运行环境,比如[上面](#配置 Jenkins Slave)动态运行的 Jenkins Slave 就是一个 Node 节点
- Stage:阶段,一个 Pipeline 可以划分为若干个 Stage,每个 Stage 代表一组操作,比如:Build、Test、Deploy,Stage 是一个逻辑分组的概念,可以跨多个 Node
- Step:步骤,Step 是最基本的操作单元,可以是打印一句话,也可以是构建一个 Docker 镜像,由各类 Jenkins 插件提供,比如命令:sh ‘make’,就相当于平时 shell 终端中执行 make 命令一样。
创建 Jenkins Pipline:
- Pipeline 脚本是由 Groovy 语言实现的
- Pipeline 支持两种语法:Declarative(声明式)和 Scripted Pipeline(脚本式)语法
- Pipeline 也有两种创建方法:可以直接在 Jenkins 的 Web UI 界面中输入脚本;也可以通过创建一个 Jenkinsfile 脚本文件放入项目源码库中
- 一般推荐在 Jenkins 中直接从源代码控制(SCMD)中直接载入 Jenkinsfile Pipeline 这种方法
创建一个简单的 Pipeline
这里快速创建一个简单的 Pipeline,直接在 Jenkins 的 Web UI 界面中输入脚本运行。
新建 Job:在 Web UI 中点击 “新建任务” -> 输入名称:pipeline-demo -> 选择下面的 “流水线” -> 点击 OK
配置:在最下方的 Pipeline 区域输入如下 Script 脚本,然后点击保存。
node { stage('Clone') { echo "1.Clone Stage" } stage('Test') { echo "2.Test Stage" } stage('Build') { echo "3.Build Stage" } stage('Deploy') { echo "4. Deploy Stage" } }构建:点击左侧区域的 “立即构建”,可以看到 Job 开始构建了
隔一会儿,构建完成,可以点击左侧区域的 Console Output,就可以看到如下输出信息:
可以看到上面 Pipeline 脚本中的4条输出语句都打印出来了,证明是符合预期的。
如果对 Pipeline 语法不是特别熟悉的,可以点击脚本的下面的“流水线语法”进行查看,这里有很多关于 Pipeline 语法的介绍,也可以自动帮我们生成一些脚本。
在 Slave 中构建任务
上面创建了一个简单的 Pipeline 任务,但是可以看到这个任务并没有在 Jenkins 的 Slave 中运行,那么如何让我们的任务跑在 Slave 中呢?之前在添加 Slave Pod 的时候,有为其添加的 label,因此在创建任务的时候,可以通过 label 的形式将任务运行在指定 Slave 中。重新编辑上面创建的 Pipeline 脚本,给 node 添加一个 label 属性,如下:
node('haimaxy-jnlp') {
stage('Clone') {
echo "1.Clone Stage"
}
stage('Test') {
echo "2.Test Stage"
}
stage('Build') {
echo "3.Build Stage"
}
stage('Deploy') {
echo "4. Deploy Stage"
}
}
这里只是给 node 添加了一个 haimaxy-jnlp 这样的一个 label,然后保存,构建之前查看下 kubernetes 集群中的 Pod:
$ kubectl get pods -n kube-ops
NAME READY STATUS RESTARTS AGE
jenkins-7c85b6f4bd-rfqgv 1/1 Running 4 6d
然后重新触发“立刻构建”:
$ kubectl get pods -n kube-ops
NAME READY STATUS RESTARTS AGE
jenkins-7c85b6f4bd-rfqgv 1/1 Running 4 6d
jnlp-ntn1s 1/1 Running 0 23s
发现多了一个名叫jnlp-ntn1s的 Pod 正在运行,隔一会儿这个 Pod 就不再了:
$ kubectl get pods -n kube-ops
NAME READY STATUS RESTARTS AGE
jenkins-7c85b6f4bd-rfqgv 1/1 Running 4 6d
这也证明 Job 构建完成了,同样回到 Jenkins 的 Web UI 界面中查看 Console Output,可以看到如下的信息:
由此证明当前的任务在跑在上面动态生成的这个 Pod 中。回到任务的主界面,也可以看到“阶段视图”界面:
部署 Kubernetes 应用
要部署 Kubernetes 应用,熟悉一下 Kubernetes 应用的部署流程:
- 编写代码
- 测试
- 编写 Dockerfile
- 构建打包 Docker 镜像
- 推送 Docker 镜像到仓库
- 编写 Kubernetes YAML 文件
- 更改 YAML 文件中 Docker 镜像 TAG
- 利用 kubectl 工具部署应用
需要把上面这些流程放入 Jenkins 中来自动完成(编码除外),从测试到更新 YAML 文件属于 CI 流程,后面部署属于 CD 的流程。如果按照上面的示例,现在要来编写一个 Pipeline 的脚本:
node('haimaxy-jnlp') {
stage('Clone') {
echo "1.Clone Stage"
}
stage('Test') {
echo "2.Test Stage"
}
stage('Build') {
echo "3.Build Docker Image Stage"
}
stage('Push') {
echo "4.Push Docker Image Stage"
}
stage('YAML') {
echo "5. Change YAML File Stage"
}
stage('Deploy') {
echo "6. Deploy Stage"
}
}
这里将一个简单 golang 程序,部署到 kubernetes 环境中,代码链接:https://github.com/willemswang/jenkins-demo。如果按照之前的示例,Pipeline 脚本编写顺序如下:
- 第一步,clone 代码
- 第二步,进行测试,如果测试通过了才继续下面的任务
- 第三步,由于 Dockerfile 基本上都是放入源码中进行管理的,所以这里就是直接构建 Docker 镜像了
- 第四步,镜像打包完成,推送到镜像仓库
- 第五步,镜像推送完成,更改 YAML 文件中的镜像 TAG 为这次镜像的 TAG
- 第六步,使用 kubectl 命令行工具进行部署了
到这里整个 CI/CD 的流程就完成了。
接下来对每一步具体要做的事情进行详细描述:
第一步:Clone 代码
stage('Clone') {
echo "1.Clone Stage"
git url: "https://github.com/willemswang/jenkins-demo.git"
}
第二步:测试
由于示例代码比较简单,可以忽略该步骤
第三步:构建镜像
stage('Build') {
echo "3.Build Docker Image Stage"
sh "docker build -t default.registry.tke.com/library/jenkins-demo:${build_tag} ."
}
平时构建的时候一般是直接使用docker build命令进行构建就行了,但是 Slave Pod 的镜像里面采用的是 Docker In Docker 的方式,也就是说可以直接在 Slave 中使用 docker build 命令,所以这里可以直接使用 sh 直接执行 docker build 命令即可。但是镜像的 tag 呢?如果使用镜像 tag,则每次都是 latest 的 tag,这对于以后的排查或者回滚之类的工作会带来很大麻烦,这里可以采用和 git commit的记录为镜像的 tag,这里的好处就是镜像的 tag 可以和 git 提交记录对应起来,也方便日后对应查看。但是由于这个 tag 不只是这一个 stage 需要使用,下一个推送镜像是不是也需要,所以这里把 tag 编写成一个公共的参数,把它放在 Clone 这个 stage 中,这样一来前两个 stage 就变成了下面这个样子:
stage('Clone') {
echo "1.Clone Stage"
git url: "https://github.com/willemswang/jenkins-demo.git"
script {
build_tag = sh(returnStdout: true, script: 'git rev-parse --short HEAD').trim()
}
}
stage('Build') {
echo "3.Build Docker Image Stage"
sh "docker build -t default.registry.tke.com/library/jenkins-demo:${build_tag} ."
}
第四步:推送镜像
镜像构建完成了,现在就需要将此处构建的镜像推送到镜像仓库中去,可以是私有镜像仓库,也可以直接使用 docker hub 即可。
docker hub 是公共的镜像仓库,任何人都可以获取上面的镜像,但是要往上推送镜像就需要用到一个帐号了,所以需要提前注册一个 docker hub 的帐号,记住用户名和密码,这里需要使用。正常来说在本地推送 docker 镜像的时候,需要使用docker login命令,然后输入用户名和密码,认证通过后,就可以使用docker push命令来推送本地的镜像到 docker hub 上面去了。此外,由于 TKEStack 本身提供了镜像仓库的能力,因此,这里以使用 TKEStack的镜像仓库:
stage('Push') {
echo "4.Push Docker Image Stage"
sh "docker login -u tkestack -p 【访问凭证】 default.registry.tke.com"
sh "docker push default.registry.tke.com/library/jenkins-demo:${build_tag}"
}
如果只是在 Jenkins 的 Web UI 界面中来完成这个任务的话,这里的 Pipeline 是可以这样写的。但一般推荐使用 Jenkinsfile 的形式放入源码中进行版本管理,这样同时会引发另一个问题:直接把镜像仓库的用户名和密码暴露给别人了,很显然是非常不安全的,更何况这里使用的是 github 的公共代码仓库,所有人都可以直接看到源码,所以应该用一种方式来隐藏用户名和密码这种私密信息,幸运的是 Jenkins 提供了解决方法。
在首页点击 “系统管理” -> Manage Credentials -> 全局凭据 Global credentials (unrestricted) -> 左侧的添加凭据:添加一个 Username with password 类型的认证信息,如下:
输入 docker hub 的用户名和密码,ID 部分输入TKEStack,注意,这个值非常重要,在后面 Pipeline 的脚本中我们需要使用到这个 ID 值。
有了上面的镜像仓库的用户名和密码的认证信息,现在可以在 Pipeline 中使用这里的用户名和密码了:
stage('Push') {
echo "4.Push Docker Image Stage"
withCredentials([usernamePassword(credentialsId: 'TKEStack', passwordVariable: 'TKEStackPassword', usernameVariable: 'TKEStackUser')]) {
sh "docker login -u ${TKEStackUser} -p ${TKEStackPassword} default.registry.tke.com"
sh "docker push default.registry.tke.com/library/jenkins-demo:${build_tag}"
}
}
注意这里在 stage 中使用了一个新的函数 withCredentials,其中有一个 credentialsId 值就是刚刚创建的 ID 值,而对应的用户名变量就是 ID 值加上 User,密码变量就是 ID 值加上 Password,然后就可以在脚本中直接使用这里两个变量值来直接替换掉之前的登录镜像仓库的用户名和密码,现在就很安全了,只是传递进去了两个变量而已,别人并不知道真正用户名和密码,只有自己的 Jenkins 平台上添加的才知道。
第五步:更改 YAML
上面已经完成了镜像的打包、推送的工作,接下来应该更新 Kubernetes 系统中应用的镜像版本了,当然为了方便维护,都是用 YAML 文件的形式来编写应用部署规则,比如这里的 YAML 文件:(k8s.yaml)
apiVersion: app/v1
kind: Deployment
metadata:
name: jenkins-demo
namespace: kube-ops
spec:
selector:
matchLabels:
app: jenkins-demo
template:
metadata:
labels:
app: jenkins-demo
spec:
containers:
- image: default.registry.tke.com/library/jenkins-demo:
imagePullPolicy: IfNotPresent
name: jenkins-demo
env:
- name: branch
value:
这个 YAML 文件使用一个 Deployment 资源对象来管理 Pod,该 Pod 使用的就是上面推送的镜像,唯一不同的地方是 Docker 镜像的 tag 不是平常见的具体的 tag,而是一个标识,实际上如果将这个标识替换成上面的 Docker 镜像的 tag,就是最终本次构建需要使用到的镜像,可以使用一个sed命令就可以实现tag的替换:
stage('YAML') {
echo "5. Change YAML File Stage"
sh "sed -i 's//${build_tag}/' k8s.yaml"
sh "sed -i 's//${env.BRANCH_NAME}/' k8s.yaml"
}
上面的 sed 命令就是将 k8s.yaml 文件中的 标识给替换成变量 build_tag 的值。
第六步:部署
Kubernetes 应用的 YAML 文件已经更改完成了,之前手动的环境下,直接使用 kubectl apply 命令就可以直接更新应用,当然这里只是写入到了 Pipeline 里面,思路都是一样的:
stage('Deploy') {
echo "6. Deploy Stage"
sh "kubectl apply -f k8s.yaml"
}
这样到这里整个流程就算完成了。
人工确认
理论上来说上面的6个步骤其实已经完成了,但是一般在实际项目实践过程中,可能还需要一些人工干预的步骤。这是因为比如提交了一次代码,测试也通过了,镜像也打包上传了,但是这个版本并不一定就是要立刻上线到生产环境的,可能需要将该版本先发布到测试环境、QA 环境、或者预览环境之类的,总之直接就发布到线上环境去还是挺少见的,所以需要增加人工确认的环节,一般都是在 CD 的环节才需要人工干预,比如这里的最后两步,就可以在前面加上确认,比如:
stage('YAML') {
echo "5. Change YAML File Stage"
def userInput = input(
id: 'userInput',
message: 'Choose a deploy environment',
parameters: [
[
$class: 'ChoiceParameterDefinition',
choices: "Dev\nQA\nProd",
name: 'Env'
]
]
)
echo "This is a deploy step to ${userInput.Env}"
sh "sed -i 's//${build_tag}/' k8s.yaml"
sh "sed -i 's//${env.BRANCH_NAME}/' k8s.yaml"
}
这里使用了 input 关键字,里面使用一个 Choice 的列表来让用户进行选择,然后选择了部署环境后,当然也可以针对不同的环境再做一些操作,比如可以给不同环境的 YAML 文件部署到不同的 namespace 下面去,增加不同的标签等等操作:
stage('Deploy') {
echo "6. Deploy Stage"
if (userInput.Env == "Dev") {
// deploy dev stuff
} else if (userInput.Env == "QA"){
// deploy qa stuff
} else {
// deploy prod stuff
}
sh "kubectl apply -f k8s.yaml"
}
由于这一步也属于部署的范畴,所以可以将最后两步都合并成一步,我们最终的 Pipeline 脚本如下:
node('haimaxy-jnlp') {
stage('Clone') {
echo "1.Clone Stage"
git url: "https://github.com/willemswang/jenkins-demo.git"
script {
build_tag = sh(returnStdout: true, script: 'git rev-parse --short HEAD').trim()
}
}
stage('Test') {
echo "2.Test Stage"
}
stage('Build') {
echo "3.Build Docker Image Stage"
sh "docker build -t default.registry.tke.com/library/jenkins-demo:${build_tag} ."
}
stage('Push') {
echo "4.Push Docker Image Stage"
withCredentials([usernamePassword(credentialsId: 'TKEStack', passwordVariable: 'TKEStackPassword', usernameVariable: 'TKEStackUser')]) {
sh "docker login -u ${TKEStackUser} -p ${TKEStackPassword} default.registry.tke.com"
sh "docker push default.registry.tke.com/library/jenkins-demo:${build_tag}"
}
}
stage('Deploy') {
echo "5. Deploy Stage"
def userInput = input(
id: 'userInput',
message: 'Choose a deploy environment',
parameters: [
[
$class: 'ChoiceParameterDefinition',
choices: "Dev\nQA\nProd",
name: 'Env'
]
]
)
echo "This is a deploy step to ${userInput}"
sh "sed -i 's//${build_tag}/' k8s.yaml"
sh "sed -i 's//${env.BRANCH_NAME}/' k8s.yaml"
if (userInput == "Dev") {
// deploy dev stuff
} else if (userInput == "QA"){
// deploy qa stuff
} else {
// deploy prod stuff
}
sh "kubectl apply -f k8s.yaml"
}
}
现在可以在 Jenkins Web UI 中重新配置 pipeline-demo 这个任务,将上面的脚本粘贴到 Script 区域,重新保存,然后点击左侧的 Build Now,触发构建,然后过一会儿就可以看到 Stage View 界面出现了暂停的情况:
这就是上面 Deploy 阶段加入了人工确认的步骤,所以这个时候构建暂停了,需要人为的确认下,比如这里选择 “QA”,然后点击“继续”,就可以继续往下走了,然后构建就成功了,在 Stage View 的 Deploy 这个阶段可以看到如下的一些日志信息:
由上面白色一行可以看出当前打印出来了 QA,和选择是一致的,现在去 Kubernetes 集群中观察下部署的应用:
[root@VM-222-139-centos ~]# kubectl get deploy
NAME READY UP-TO-DATE AVAILABLE AGE
jenkins-demo 0/1 1 0 61s
jenkins2 1/1 1 1 26h
[root@VM-222-139-centos ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
jenkins-demo-b47c7684c-mvpkm 0/1 CrashLoopBackOff 3 62s
jenkins2-7f6cb7d69c-2hnzg 1/1 Running 0 10h
[root@VM-222-139-centos ~]# kubectl logs jenkins-demo-b47c7684c-mvpkm
Hello, Kubernetes!I'm from Jenkins CI!
BRANCH_NAME:
可以看到应用已经正确的部署到了 Kubernetes 的集群环境中了。
Jenkinsfile
这里完成了一次手动的添加任务的构建过程,在实际的工作实践中,更多的是将 Pipeline 脚本写入到 Jenkinsfile 文件中,然后和代码一起提交到代码仓库中进行版本管理。现在将上面的 Pipeline 脚本拷贝到一个 Jenkinsfile 中,将该文件放入上面的 git 仓库中,但是要注意的是,现在既然已经在 git 仓库中了,是不是就不需要 git clone 这一步骤了,所以需要将第一步 Clone 操作中的 git clone 这一步去掉,可以参考:https://github.com/willemswang/jenkins-demo/Jenkinsfile
更改上面的 jenkins-demo 这个任务,点击 Configure -> 最下方的 Pipeline 区域 -> 将之前的 Pipeline Script 更改成 Pipeline Script from SCM,然后根据实际情况填写上对应的仓库配置,要注意 Jenkinsfile 脚本路径:
7 - 开发指引
7.1 - API 使用指引
1. 调用方式
1.1. 创建访问凭证
访问【平台管理】控制台,在左侧找到【组织资源】,选择【访问凭证】,新建一个访问凭证。
1.2. 访问 API
TKEStack上各种资源的接口均以 Kubernetes 原生 API 的形式提供,所有接口使用统一的前缀: http://console.tke.com:8080/platform,请求中需要将上一步申请的访问凭证以"Authorization: Bearer ${访问凭证}"的形式放入 header。
以查询集群信息为例,使用的请求如下:
curl -H "Authorization: Bearer xxxxxxx" \
"http://console.tke.com:8080/platform/apis/platform.tkestack.io/v1/clusters"
1.3. 查看特定集群的 Namespace
查看集群所包含的 Namespace 需要传递 “X-TKE-ClusterName: cls-xxx” 的 header,cls-xxx 为特定集群 ID
curl -H "Authorization: Bearer xxxxxxx" \
-H "X-TKE-ClusterName: cls-xxx" \
"http://console.tke.com:8080/platform/api/v1/namespaces"
2. 通过 API 创建应用
2.1. 非 TApp 应用(deployment,statefulset,daemonset)
curl 'http://console.tke.com:8080/platform/apis/apps/v1/namespaces/命名空间/工作负载类型/工作负载名称'
-X PATCH
-H 'Content-Type:application/strategic-merge-patch+json'
-H 'X-TKE-ClusterName:所属集群'
-H 'Authorization: Bearer 访问凭证'
-d '{"spec":{"template":{"spec":{"containers":[{"name":"容器名称","image":"容器镜像"}]}}}}'
工作负载类型: 选择需要更新的工作负载类型(deployment,statefulset, daemonset) 所属集群:填写所要更新容器所属集群。 命名空间:填写所要更新容器所属的命名空间。 工作负载名称:填写所要更新容器的工作负载名称。 容器名称:填写所要更新容器的名称。 访问凭证:填写访问该容器资源的访问凭证,可以在“tkestack-组织资源-访问凭证“中获取该信息(访问凭证有过期时间,如过期需要重新创建)。 容器镜像:填写所要更新的Docker镜像
2.2. TApp
TApp 是自研的应用类型,更新镜像需要两步,首先获取当前的容器 spec,调整镜像名后在调用更新接口
2.2.1. 获取tapp spec
curl 'http://console.tke.com:8080/platform/apis/platform.tkestack.io/v1/clusters/所属集群/tapps?namespace=命名空间&name=工作负载名称'
-X GET
-H 'Authorization: Bearer 访问凭证'
返回值示例:
{"apiVersion":"apps.tkestack.io/v1","kind":"TApp","metadata":{"creationTimestamp":"2020-06-10T13:35:54Z","generation":8,"labels":{"k8s-app":"kevintest","qcloud-app":"kevintest"},"name":"kevintest","namespace":"default","resourceVersion":"13925571","selfLink":"/apis/apps.tkestack.io/v1/namespaces/default/tapps/kevintest","uid":"0269fb69-fa87-42f8-9c3a-e1f96cef40f1"},"spec":{"forceDeletePod":true,"replicas":1,"selector":{"matchLabels":{"k8s-app":"kevintest","qcloud-app":"kevintest"}},"template":{"metadata":{"creationTimestamp":null,"labels":{"k8s-app":"kevintest","qcloud-app":"kevintest","tapp_template_hash_key":"9636164821252331163","tapp_uniq_hash_key":"9518255606018677371"}},"spec":{"containers":[{"image":"mirrors.tencent.com/elsanli/devops-demo:62","imagePullPolicy":"Always","livenessProbe":{"failureThreshold":10,"periodSeconds":10,"successThreshold":1,"tcpSocket":{"port":8888},"timeoutSeconds":2},"name":"test","readinessProbe":{"failureThreshold":10,"periodSeconds":30,"successThreshold":1,"tcpSocket":{"port":8888},"timeoutSeconds":2},"resources":{"limits":{"cpu":"100m","memory":"48Mi"},"requests":{"cpu":"100m","memory":"25Mi"}}}],"restartPolicy":"Always"}},"updateStrategy":{}},"status":{"appStatus":"Running","observedGeneration":7,"readyReplicas":0,"replicas":1,"scaleLabelSelector":"k8s-app=kevintest,qcloud-app=kevintest","statuses":{"0":"Pending"}}}
2.3. 更新 TApp 镜像
从上一步返回值中获取想要更新的整个容器的 spec,替换其中的 image 字段,这样做是为了避免将其他字段覆盖为空
curl ''http://console.tke.com:8080/platform/apis/platform.tkestack.io/v1/clusters/所属集群/tapps?namespace=命名空间&name=工作负载名称'
-X PATCH
-H 'Content-Type:application/merge-patch+json'
-H 'X-TKE-ClusterName:所属集群'
-H 'Authorization: Bearer 访问凭证'
-d '{"spec":{"template":{"spec":{"containers":[{"name":"容器名称","image":"容器镜像","resources":{"limits":{"cpu":"100m","memory":"48Mi"},"requests":{"cpu":"100m","memory":"25Mi"}},"livenessProbe":{"tcpSocket":{"port":8888},"timeoutSeconds":2,"periodSeconds":10,"successThreshold":1,"failureThreshold":10},"readinessProbe":{"tcpSocket":{"port":8888},"timeoutSeconds":2,"periodSeconds":30,"successThreshold":1,"failureThreshold":10},"imagePullPolicy":"Always"}]}},"templates":null}}
所属集群:填写所要更新容器所属集群。 命名空间:填写所要更新容器所属的命名空间。 工作负载名称:填写所要更新容器的工作负载名称。 容器名称:填写所要更新容器的名称。 访问凭证:填写访问该容器资源的访问凭证,可以在“tkestack-组织资源-访问凭证“中获取该信息(访问凭证有过期时间,如过期需要重新创建)。 容器镜像:填写所要更新的Docker镜像
3. 通过 API 增删集群节点
只能对独立集群的节点进行增删操作,不可操作导入集群。
3.1. 增加节点
URL: http://console.tke.com:8080/platform/apis/platform.tkestack.io/v1/machines
Method: POST
Headers:
- Content-Type: application/json
- Authorization: Bearer xxx
按照以下命令的格式,将中文部分替换成实际值,发送请求。请求成功后,会返回被创建的Machine对象。
curl -X POST \
"http://console.tke.com:8080/platform/apis/platform.tkestack.io/v1/machines" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer 你的访问凭证" \
-d '
{
"kind": "Machine",
"apiVersion": "platform.tkestack.io/v1",
"metadata": {
"generateName": "mc-"
},
"spec": {
"finalizers": [
"machine"
],
"tenantID": "租户ID(联系平台管理员获取)",
"clusterName": "集群ID,可通过页面查看(不是集群名称)",
"type": "Baremetal",
"ip": "节点IP",
"port": 节点SSH端口(int),
"username": "root",
"password": "节点root密码(需经base64编码)"
}
}'
password base64编码:
echo -n $PASSWORD | base64 假设password原文为123456,则生成的base64编码为MTIzNDU2
PS: 使用 echo 命令时一定加上 -n 参数
3.2. 查看节点
URL: http://console.tke.com:8080/platform/apis/platform.tkestack.io/v1/machines/${machine.metadata.name}
Method: GET
Headers:
- Authorization: Bearer xxx
假设平台中有 name 为 mc-brd44nzd 的 Machine 对象:
{
"kind": "Machine",
"apiVersion": "platform.tkestack.io/v1",
"metadata": {
"name": "mc-brd44nzd",
"generateName": "mc-",
"selfLink": "/apis/platform.tkestack.io/v1/machines/mc-brd44nzd",
"uid": "9ef7c08f-c535-4e99-b11d-9f7d02be19f5",
"resourceVersion": "343953553",
"creationTimestamp": "2020-02-27T00:25:02Z"
},
"spec": {
"finalizers": [
"machine"
],
"tenantID": "default",
"clusterName": "xxxx",
"type": "Baremetal",
"ip": "xxxxxx",
"port": 36000,
"username": "root",
"password": "xxxxxx"
}
}
则查看该 Machine 部署进度的请求为:
curl "http://console.tke.com:8080/platform/apis/platform.tkestack.io/v1/machines/mc-brd44nzd" \
-H "Authorization: Bearer 你的访问凭证"
3.3. 删除节点
URL: http://console.tke.com:8080/platform/apis/platform.tkestack.io/v1/machines/${machine.metadata.name}
Method: DELETE
Headers:
- Authorization: Bearer xxx
假设平台中有 name 为 mc-brd44nzd 的 Machine 对象,则删除节点的请求为:
curl -X DELETE "http://console.tke.com:8080/platform/apis/platform.tkestack.io/v1/machines/mc-brd44nzd" \
-H "Authorization: Bearer 你的访问凭证"
4. 通过 API 获取业务信息
4.1. 查看自身所在业务
curl 'http://console.tke.com:8080/business/apis/business.tkestack.io/v1/portal' \
-X GET \
-H "Authorization: Bearer 访问凭证"
4.2. 查看特定业务包含的 Namespace 信息
curl 'http://console.tke.com:8080/business/apis/business.tkestack.io/v1/namespaces/prj-xxx/namespaces' \
-X GET \
-H "Authorization: Bearer 访问凭证"
prj-xxx 为业务 id
4.3. 查看特定业务信息
curl 'http://console.tke.com:8080/business/apis/business.tkestack.io/v1/projects/prj-xxx' \
-X GET \
-H 'Authorization: Bearer 访问凭证'
prj-xxx为业务id
8 - FAQ
8.1 - 部署类
8.1.1 - 常见报错解决方法
当前 TKEStack 使用 tke-Installer 一键安装,安装过程中的错误主要集中在硬件和软件配置上,安装前请仔细阅读环境要求文档:
如何重新部署集群
重试安装
若安装报错后,请先排障,再登录到 Installer 节点执行如下命令后,重新打开 http://[tke-installer-IP]:8080/index.html 安装控制台。
docker restart tke-installer
重新安装
安装报错后,请先排障,再登录到 Installer 节点执行如下命令后,重新打开 http://[tke-installer-IP]:8080/index.html 安装控制台。
rm -rf /opt/tke-installer && docker restart tke-installer
注:重新安装前,请先清理节点上的残留:清除残留
清除残留
在添加新的节点或者重装环境之前,需要彻底清理节点,请对 Installer 或所有加入的节点执行下方脚本清理残留配置和文件。
curl -s https://tke-release-1251707795.cos.ap-guangzhou.myqcloud.com/tools/clean.sh | sh
或者使用如下脚本:
#!/bin/bash
rm -rf /etc/kubernetes
systemctl stop kubelet 2>/dev/null
docker rm -f $(docker ps -aq) 2>/dev/null
systemctl stop docker 2>/dev/null
ip link del cni0 2>/etc/null
for port in 80 2379 6443 8086 {10249..10259} ; do
fuser -k -9 ${port}/tcp
done
rm -rfv /etc/kubernetes
rm -rfv /etc/docker
rm -fv /root/.kube/config
rm -rfv /var/lib/kubelet
rm -rfv /var/lib/cni
rm -rfv /etc/cni
rm -rfv /var/lib/etcd
rm -rfv /var/lib/postgresql /etc/core/token /var/lib/redis /storage /chart_storage
systemctl start docker 2>/dev/null
注:如有混合部署其他业务,请基于实际情况评估目录内数据是否可删除。
安装密码报错
错误情况:使用密码安装 Global 集群报 ssh:unable to authenticate 错误
解决方案:将 Global 集群节点/etc/ssh/sshd_config配置文件中的PasswordAuthentication设为yes,重启sshd服务。
8.1.2 - 如何规划部署资源
TKEStack支持使用物理机或虚拟机部署,采用kubernetes on kubernetes架构部署,在主机上只拥有一个物理机进程kubelet,其他kubernetes组件均为容器。架构上分为global集群和业务集群。global集群,运行整个TKEStack平台自身所需要的组件,业务集群运行用户业务。在实际的部署过程中,可根据实际情况进行调整。
安装TKEStack,需要提供两种角色的 Server:
Installer server 1台,用以部署集群安装器,安装完成后可以回收。
Global server,若干台,用以部署 Globa 集群,常见的部署模式分为三种:
- All in one 模式,1台server部署 Global集群,global集群同时也充当业务集群的角色,即运行平台基础组件,又运行业务容器。global集群会默认设置taint不可调度,使用此模式时,需要手工在golbal集群【节点管理】-【更多】-【编辑Taint】中去除不可调度设置。(关于taint,了解更多)。由于此种模式不具有高可用能力,不建议在生产环境中使用。
- Global 与业务集群混部的高可用模式,3台Server部署global集群,global集群同时也充当业务集群的角色,即运行平台基础组件,又运行业务容器。global集群会默认设置taint不可调度,使用此模式时,需要手工在golbal集群【节点管理】-【更多】-【编辑Taint】中去除不可调度设置。(关于taint,了解更多)。由于此种模式有可能因为业务集群资源占用过高而影响global集群,不建议在生产环境中使用。
- Global 与业务集群分别部署的高可用模式,3台Server部署global集群,仅运行平台自身组件,业务集群单独在TKEStack控制台上创建(建议3台以上),此种模式下,业务资源占有与平台隔离,建议在生产环境中使用此种模式。
集群节点主机配置,请参考资源需求。
8.1.3 -
如何使用存储
TKEStack 没有提供存储服务,Global集群中的镜像仓库、ETCD、InfluxDB等数据组件,均使用本地磁盘存储数据。如果您需要使用存储服务,建议使用ROOK或者chubaoFS,部署一套容器化的分布式存储服务。
8.2 - 平台类
8.2.1 - 监控告警指标列表
监控 & 告警指标列表
目前 TKEStack 提供了以下维度的监控指标,所有指标均为统计周期内的平均值。
监控
集群监控指标
| 指标 | 单位 | 说明 |
|---|---|---|
| CPU 利用率 | % | 集群整体的 CPU 利用率 |
| 内存利用率 | % | 集群整体的内存利用率 |
节点监控指标
| 指标 | 单位 | 说明 |
|---|---|---|
| Pod 重启次数 | 次 | 节点内所有 Pod 的重启次数之和 |
| 异常状态 | - | 节点的状态,正常或异常 |
| CPU 利用率 | % | 节点内所有 Pod 的 CPU 使用量占节点总量之比 |
| 内存利用率 | % | 节点内所有 Pod 的内存使用量占节点总量之比 |
| 内网入带宽 | bps | 节点内所有 Pod 的内网入方向带宽之和 |
| 内网出带宽 | bps | 节点内所有 Pod 的内网出方向带宽之和 |
| 外网入带宽 | bps | 节点内所有 Pod 的外网入方向带宽之和 |
| 外网出带宽 | bps | 节点内所有 Pod 的外网出方向带宽之和 |
| TCP 连接数 | 个 | 节点保持的 TCP 连接数 |
工作负载监控指标
| 指标 | 单位 | 说明 |
|---|---|---|
| Pod 重启次数 | 次 | 工作负载内所有 Pod 的重启次数之和 |
| CPU 使用量 | 核 | 工作负载内所有 Pod 的 CPU 使用量 |
| CPU 利用率(占集群) | % | 工作负载内所有 Pod 的 CPU 使用量占集群总量之比 |
| 内存使用量 | B | 工作负载内所有 Pod 的内存使用量 |
| 内存利用率(占集群) | % | 工作负载内所有 Pod 的内存使用量占集群总量之比 |
| 网络入带宽 | bps | 工作负载内所有 Pod 的入方向带宽之和 |
| 网络出带宽 | bps | 工作负载内所有 Pod 的出方向带宽之和 |
| 网络入流量 | B | 工作负载内所有 Pod 的入方向流量之和 |
| 网络出流量 | B | 工作负载内所有 Pod 的出方向流量之和 |
| 网络入包量 | 个/s | 工作负载内所有 Pod 的入方向包数之和 |
| 网络出包量 | 个/s | 工作负载内所有 Pod 的出方向包数之和 |
Pod 监控指标
| 指标 | 单位 | 说明 |
|---|---|---|
| 异常状态 | - | Pod 的状态,正常或异常 |
| CPU 使用量 | 核 | Pod 的 CPU 使用量 |
| CPU 利用率(占节点) | % | Pod 的 CPU 使用量占节点总量之比 |
| CPU 利用率(占 Request) | % | Pod 的 CPU 使用量和设置的 Request 值之比 |
| CPU 利用率(占 Limit) | % | Pod 的 CPU 使用量和设置的 Limit 值之比 |
| 内存使用量 | B | Pod 的内存使用量,含缓存 |
| 内存使用量(不包含 Cache) | B | Pod 内所有 Container 的真实内存使用量(不含缓存) |
| 内存利用率(占节点) | % | Pod 的内存使用量占节点总量之比 |
| 内存利用率(占节点,不包含 Cache) | % | Pod 内所有 Container 的真实内存使用量(不含缓存)占节点总量之比 |
| 内存利用率(占 Request) | % | Pod 的内存使用量和设置的 Request 值之比 |
| 内存利用率(占 Request,不包含Cache) | % | Pod 内所有 Container 的真实内存使用量(不含缓存)和设置的 Request 值之比 |
| 内存利用率(占 Limit) | % | Pod 的内存使用量和设置的 Limit 值之比 |
| 内存利用率(占 Limit,不包含 Cache) | % | Pod 内所有 Container 的真实内存使用量(不含缓存)和设置的 Limit 值之比 |
| 网络入带宽 | bps | Pod 的入方向带宽之和 |
| 网络出带宽 | bps | Pod 的出方向带宽之和 |
| 网络入流量 | B | Pod 的入方向流量之和 |
| 网络出流量 | B | Pod 的出方向流量之和 |
| 网络入包量 | 个/s | Pod 的入方向包数之和 |
| 网络出包量 | 个/s | Pod 的出方向包数之和 |
Container 监控指标
| 指标 | 单位 | 说明 |
|---|---|---|
| CPU 使用量 | 核 | Container 的 CPU 使用量 |
| CPU 利用率(占节点) | % | Container 的 CPU 使用量占节点总量之比 |
| CPU 利用率(占 Request) | % | Container 的 CPU 使用量和设置的 Request 值之比 |
| CPU 利用率(占 Limit) | % | Container 的 CPU 使用量和设置的 Limit 值之比 |
| 内存使用量 | B | Container 的内存使用量,含缓存 |
| 内存使用量(不包含 Cache) | B | Container 的真实内存使用量(不含缓存) |
| 内存利用率(占节点) | % | Container 的内存使用量占节点总量之比 |
| 内存利用率(占节点,不包含 Cache) | % | Container 的真实内存使用量(不含缓存)占节点总量之比 |
| 内存利用率(占 Request) | % | Container 的内存使用量和设置的 Request 值之比 |
| 内存利用率(占 Request,不包含 Cache) | % | Container 的真实内存使用量(不含缓存)和设置的 Request 值之比 |
| 内存利用率(占 Limit) | % | Container 的内存使用量和设置的 Limit 值之比 |
| 内存利用率(占 Limit,不包含 Cache) | % | Container 的真实内存使用量(不含缓存)和设置的 Limit 值之比 |
| 块设备读带宽 | B/s | Container 从硬盘读取数据的吞吐量 |
| 块设备写带宽 | B/s | Container 把数据写入硬盘的吞吐量 |
| 块设备读 IOPS | 次/s | Container 从硬盘读取数据的 IO 次数 |
| 块设备写 IOPS | 次/s | Container 把数据写入硬盘的 IO 次数 |
告警
目前容器服务提供了以下维度的告警指标,所有指标均为统计周期内的平均值。
集群告警指标
| 指标 | 单位 | 说明 |
|---|---|---|
| CPU 利用率 | % | 集群整体的 CPU 利用率 |
| 内存利用率 | % | 集群整体的内存利用率 |
| CPU 分配率 | % | 集群所有容器设置的 CPU Request 之和与集群总可分配 CPU 之比 |
| 内存分配率 | % | 集群所有容器设置的内存 Request 之和与集群总可分配内存之比 |
| Apiserver 正常 | - | Apiserver 状态,默认 False 时告警,仅独立集群支持该指标 |
| ETCD 正常 | - | ETCD 状态,默认 False 时告警,仅独立集群支持该指标 |
| Scheduler 正常 | - | Scheduler 状态,默认 False 时告警,仅独立集群支持该指标 |
| Controll Manager 正常 | - | Controll Manager 状态,默认 False 时告警,仅独立集群支持该指标 |
节点告警指标
| 指标 | 单位 | 说明 |
|---|---|---|
| CPU 利用率 | % | 节点内所有 Pod 的 CPU 使用量占节点总量之比 |
| 内存利用率 | % | 节点内所有 Pod 的内存使用量占节点总量之比 |
| 节点上 Pod 重启次数 | 次 | 节点内所有 Pod 重启次数之和 |
| Node Ready | - | 节点状态,默认 False 时告警 |
Pod 告警指标
| 指标 | 单位 | 说明 |
|---|---|---|
| CPU 利用率(占节点) | % | Pod 的 CPU 使用量占节点总量之比 |
| 内存利用率(占节点) | % | Pod 的内存使用量占节点总量之比 |
| 实际内存利用率(占节点,不包含 Cache) | % | Pod 内所有 Container 的真实内存使用量(不含缓存)占节点总量之比 |
| CPU 利用率(占 Limit) | % | Pod 的CPU使用量和设置的 Limit 值之比 |
| 内存利用率(占 Limit) | % | Pod 的内存使用量和设置的 Limit 值之比 |
| 实际内存利用率(占 Limit,不包含 Cache) | % | Pod 内所有 Container 的真实内存使用量(不含缓存)和设置的 Limit 值之比 |
| Pod 重启次数 | 次 | Pod 的重启次数 |
| Pod Ready | - | Pod 的状态,默认 False 时告警 |
| CPU 使用量 | 核 | Pod 的 CPU 使用量 |
| 内存使用量 | MB | Pod 的内存使用量,含缓存 |
| 实际内存使用量 | MB | Pod 内所有 Container 的真实内存使用量之和,不含缓存 |
8.2.2 - 平台使用常见问题
此处为平台使用常见问题,在使用 TKEStack 过程中,欢迎在 issue 上提出自己的问题,最好配上相关的信息和截图,以便我们更好定位问题所在,每个 issue 我们都会认真对待。
APIServer 的 Real 和 Advertise

Real:表示 Master 节点 APIServer
Advertise:表示高可用 VIP 的 APIServer、或者是各大云厂商托管集群的 APIServer 地址
global 集群没出现
参考:清除浏览器缓存
field is immuable

参考:表示已有同名对象,例如已有同名 Service,需要手动删除 Service,或者换个名字
控制台无法编辑节点 Taint
在部署负载时,有时会出现下图中的事件,表示节点被 Taint

原因:通过 TKEStack 部署的集群里 Master 节点默认带污点(taint),是为了防止业务 Pod 运行在 Master 节点上,此时如果平台有问题的话,业务也会挂掉。但在测试环境中,节点有限的情况下,可以适当删除节点的 taint,但在控制台上没办法删掉,只能在命令行删除

node(s) had tiant
解决方法和上图一样,删除或注释节点中的 taint
镜像仓库镜像上传问题
WARNING! Using --password via the CLI is insecure. Use --password-stdin.
Error response from daemon: Get https://defult.registry.tke.com/v2/: dial tcp: lookup defult.registry.tke.com on 183.60.83.19:53: no such host
很可能是因为 Registry container 没有启动
kubectl get pod -n tke | grep tke-registry
事件持久化插件无法点击完成来添加
原因:在页面下方要添加用于持久化的 ES 地址和索引
注意:当前只支持未开启 用户登录认证 的 ES 集群
业务管理界面没有找到想要的业务
因为当前用户不是该业务的成员,需要为该业务添加成员用户

业务的 NS 只能选择一个集群
业务下的每个命名空间只能选取一个集群,因为是在这个集群下面新建的这个命名空间

数据卷 以主机路径为例
主机路径为节点上的一个地址
注意:主机路径指的是 Pod 所在主机的路径

下图2和3中的 testv 相当于一个标签,用于指定不同的挂载类型,本例为主机路径
4中的目录为容器中的目录,会在容器的根目录中创建一个 hahaha 的文件夹
最后一个框为路径/hahaha下面的路径,可不填

使用数据卷的效果:主机上的主机路径和容器上的hahaha文件夹中的内容完全一致
kube-state-metrics 和 metric-server 的区别
metric-server
TKEStack 的 Global 集群和新建的独立集群会默认安装名为 metric-server 的负载,是一个容器资源监控和性能分析工具。只是显示数据,并不提供数据存储服务,类似 cAdvisor(默认集成在 kubelet 中)、heapster(已被 metric-server 替代),可以利用 metric-server 提供的数据实现 HPA
kube-state-metrics
使用 TKEStack 为集群安装 Prometheus 监控组件时会安装名为 kube-state-metrics 的负载,用于为 Prometheus 提供监控数据。kube-state-metrics 基于 client-go 开发的服务,监听 Kubernetes APIServer,并将 Kubernetes 的结构化信息转换为 metrics,它不关注单个 Kubernetes 组件的运行状况,而是关注内部各种对象(例如 Deployment、Node、Pod)的运行状况。
kube-state-metrics 和 metric-server 一样,只是简单提供一个 metrics 数据,并不会存储这些指标数据,所以我们可以使用 Prometheus 来抓取这些数据然后存储
kube-state-metrics-service.yaml 中有 prometheus.io/scrape: ‘true’ 标识,因此会将 metrics 暴露给Prometheus,而 Prometheus 会在 kubernetes-service-endpoints 这个 job 下自动发现 kube-state-metrics,并开始拉取 metrics,无需其他配置。
使用 kube-state-metrics 后的常用场景有:
- 存在执行失败的 Job: kube_job_status_failed{job=“kubernetes-service-endpoints”,k8s_app=“kube-state-metrics”}==1
- 集群节点状态错误: kube_node_status_condition{condition=“Ready”,status!=“true”}==1
- 集群中存在启动失败的 Pod:kube_pod_status_phase{phase=~“Failed|Unknown”}==1
- 最近30分钟内有 Pod 容器重启: changes(kube_pod_container_status_restarts[30m])>0
- 配合报警可以更好地监控集群的运行
区别
- kube-state-metrics 主要关注的是业务相关的一些元数据,针对是是 k8s 集群内资源对象数据,比如 Deployment、Pod、副本状态等
- metrics-server 主要关注的是资源度量 API 的实现,比如 CPU、文件描述符、内存、请求延时等指标
- metric-server(或 heapster)是从 api-server 中获取 CPU、内存使用率这种监控指标,并把他们发送给存储后端,如 InfluxDB 或云厂商,他当前的核心作用是:为 HPA 等组件提供决策指标支持
- kube-state-metrics关注于获取 k8s 各种资源的最新状态,如 Deployment 或者 DaemonSet,之所以没有把 kube-state-metrics 纳入到 metric-server 的能力中,是因为他们的关注点本质上是不一样的。 metric-server 仅仅是获取、格式化现有数据,写入特定的存储,实质上是一个监控系统。而 kube-state-metrics 是将 k8s 的运行状况在内存中做了个快照,并且获取新的指标,但他没有能力导出这些指标
- 换个角度讲,kube-state-metrics 本身是 metric-server 的一种数据来源,虽然现在没有这么做
- 另外,像 Prometheus 这种监控系统,并不会去用 metric-server 中的数据,他都是自己做指标收集、集成的(Prometheus 包含了 metric-server的能力),但 Prometheus 可以监控 metric-server本 身组件的监控状态并适时报警,这里的监控就可以通过 kube-state-metrics 来实现,如 metric-server 的 Pod 的运行状态
8.2.3 -
平台使用常见问题
8.3 - 授权类
8.3.1 - 如何接入LDAP&OIDC
接入LDAP、OIDC有两种方式;
- 在集群安装时,配置OIDC认证信息,关于OIDC配置信息,请参考Configuring the API Server。

集群安装完成后,可以通过调用API的形式切换认证模式为OIDC或LDAP
a. 修改auth配置文件,configmap: tke-auth-api,指定默认idp类型为ldap:
"auth": { "init_tenant_type": "ldap", // 指定ldap类型的idp "init_tenant_id": "ldap-test", // tenant id "init_idp_administrators": ["jane"], //idp的管理员列表,需要存在客户ldap系统中,具有平台的超级管理员权限 "ldap_config_file":"_debug/auth-ldap.json", }b. 准备ldap配置文件,配置说明参见:dex-ldap
{ //ldap地址,host:port "host": "localhost:389", "insecureNoSSL": true, // 是否开始SSL,如果host没有指定端口,ture,端口为389和false, 端口为636 "bindDN": "cn=admin,dc=example,dc=org", //服务账户的DN和密码,用来查询ldap用户组和用户 "bindPW": "admin", //密码 "usernamePrompt": "User Name", // "userSearch": { "baseDN": "ou=People,dc=example,dc=org", //用户baseDN "filter": "(objectClass=person)", //查询过滤条件 "username": "cn", // username的属性key,cn=jane,ou=People,dc=example,dc=org "idAttr": "DN", // user id的属性key "emailAttr": "mail", // 邮件属性key "nameAttr": "cn" //displayname 的属性key }, "groupSearch": { "baseDN": "ou=Groups,dc=example,dc=org",//用户组baseDN "filter": "(objectClass=groupOfNames)", //查询过滤条件 "userAttr": "DN", //用户组成员id属性key "groupAttr": "member", //用户组成员key "nameAttr": "cn" //用户组名称key } }c. 调用API,新增ldap idp,
curl -XPOST https://{auth_address}/apis/auth.tkestack.io/v1/identityproviders -H 'Authorization: Bearer {admin_token}' -H 'Content-Type: application/json' Body:
{ "metadata": { "name": "ldap-test" //tennatID }, "spec": { "name": "ldap-test", "type": "ldap", "administrators": [ //超级管理员 "jane" ], "config": " {\"host\":\"localhost:389\",\"insecureNoSSL\":true,\"bindDN\":\"cn=admin,dc=example,dc=org\",\"bindPW\":\"admin\",\"usernamePrompt\":\"Email Address\",\"userSearch\":{\"baseDN\":\"ou=People,dc=example,dc=org\",\"filter\":\"(objectClass=person)\",\"username\":\"cn\",\"idAttr\":\"DN\",\"emailAttr\":\"mail\",\"nameAttr\":\"cn\"},\"groupSearch\":{\"baseDN\":\"ou=Groups,dc=example,dc=org\",\"filter\":\"(objectClass=groupOfNames)\",\"userAttr\":\"DN\",\"groupAttr\":\"member\",\"nameAttr\":\"cn\"}}" //ldap配置 } }
d. 删除IDP
curl -XDELETE https://{auth_address}/apis/auth.tkestack.io/v1/identityproviders/ldap-test -H 'Authorization: Bearer {admin_token}'
8.3.2 - 业务管理、平台管理的区别
TKEStack的权限体系分为业务使用者和平台管理员两种角色,平台管理员可以管理平台所有功能,业务使用者可以访问自己有权限的业务或者namespace下的资源。同时平台管理员可以通过自定义策略,定义不同的策略类型。
8.3.3 - 如何设置自定义策略
TKEStack 策略(policy)用来描述授权的具体信息。核心元素包括操作(action)、资源(resource)以及效力(effect)。
操作(action)
描述允许或拒绝的操作。操作可以是 API(以 name 前缀描述)或者功能集(一组特定的 API,以 permid 前缀描述)。该元素是必填项。
资源(resource)
描述授权的具体数据。资源是用六段式描述。每款产品的资源定义详情会有所区别。有关如何指定资源的信息,请参阅您编写的资源声明所对应的产品文档。该元素是必填项。
效力(effect)
描述声明产生的结果是“允许”还是“显式拒绝”。包括 allow(允许)和 deny (显式拒绝)两种情况。该元素是必填项。
策略样例
该样例描述为:允许关联到此策略的用户,对cls-123集群下的工作负载deploy-123中的所有资源,有查看权限。
{
"actions": [
"get*",
"list*",
"watch*"
],
"resources": [
"cluster:cls-123/deployment:deploy-123/*"
],
"effect": "allow"
}
8.3.4 - Docker login 权限错误
Docker login 权限错误
在Tkestack选用用了自建证书,需要用户在客户端手动导入,docker login 权限报错:certificate signed by unknown authority。
方法一
在 Global 集群上执行 kubectl get cm certs -n tke -o yaml 将 ca.crt 内容保存到客户端节点的/etc/docker/certs.d/**/ca.crt ( 为镜像仓库地址) 重启docker即可
方法二:
在/etc/docker/daemon.json文件里添加insecure-registries,如下: { “insecure-registries”: [ “xxx”,“xxx” ] } (* 为镜像仓库地址)
重启docker即可
8.4 - 事件类
8.4.1 - 常见错误事件
常见错误事件
Back-off restarting failed docker container
说明:正在重启异常的 Docker 容器。 解决方法:检查镜像中执行的 Docker 进程是否异常退出,若镜像内并无一持续运行的进程,可在创建服务的页面中添加执行脚本。
fit failure on node: Insufficient cpu
说明:集群 CPU 不足。 解决方法:原因是节点无法提供足够的计算核心,请在服务页面修改 CPU 限制或者对集群进行扩容。
no nodes available to schedule pods
说明:集群资源不足。 解决方法:原因是没有足够的节点用于承载实例,请在服务页面修改服务的实例数量,修改实例数量或者 CPU 限制。
pod failed to fit in any node
说明:没有合适的节点可供实例使用。 解决方法:原因是服务配置了不合适的资源限制,导致没有合适的节点用于承载实例,请在服务页面修改服务的实例数量或者 CPU 限制。
Liveness probe failed
说明:容器健康检查失败 解决方法:检查镜像内容器进程是否正常,检查检测端口是否配置正确。
Error syncing pod, skipping
Error syncing pod, skipping failed to “StartContainer” for with CrashLoopBackOff: “Back-off 5m0s restarting failed container 说明:容器进程崩溃或退出。 解决方法:检查容器内是否有持续运行的前台进程,若有检查其是否有异常行为。详情请参考 如何构建Docker 镜像。
8.6 -
如何接入LDAP&OIDC
接入LDAP、OIDC有两种方式;
- 在集群安装时,配置OIDC认证信息,关于OIDC配置信息,请参考Configuring the API Server。
集群安装完成后,可以通过调用API的形式切换认证模式为OIDC或LDAP
a. 修改auth配置文件,configmap: tke-auth-api,指定默认idp类型为ldap:
"auth": { "init_tenant_type": "ldap", // 指定ldap类型的idp "init_tenant_id": "ldap-test", // tenant id "init_idp_administrators": ["jane"], //idp的管理员列表,需要存在客户ldap系统中,具有平台的超级管理员权限 "ldap_config_file":"_debug/auth-ldap.json", }b. 准备ldap配置文件,配置说明参见:dex-ldap
{ //ldap地址,host:port "host": "localhost:389", "insecureNoSSL": true, // 是否开始SSL,如果host没有指定端口,ture,端口为389和false, 端口为636 "bindDN": "cn=admin,dc=example,dc=org", //服务账户的DN和密码,用来查询ldap用户组和用户 "bindPW": "admin", //密码 "usernamePrompt": "User Name", // "userSearch": { "baseDN": "ou=People,dc=example,dc=org", //用户baseDN "filter": "(objectClass=person)", //查询过滤条件 "username": "cn", // username的属性key,cn=jane,ou=People,dc=example,dc=org "idAttr": "DN", // user id的属性key "emailAttr": "mail", // 邮件属性key "nameAttr": "cn" //displayname 的属性key }, "groupSearch": { "baseDN": "ou=Groups,dc=example,dc=org",//用户组baseDN "filter": "(objectClass=groupOfNames)", //查询过滤条件 "userAttr": "DN", //用户组成员id属性key "groupAttr": "member", //用户组成员key "nameAttr": "cn" //用户组名称key } }c. 调用API,新增ldap idp,
curl -XPOST https://{auth_address}/apis/auth.tkestack.io/v1/identityproviders -H 'Authorization: Bearer {admin_token}' -H 'Content-Type: application/json' Body:
{ "metadata": { "name": "ldap-test" //tennatID }, "spec": { "name": "ldap-test", "type": "ldap", "administrators": [ //超级管理员 "jane" ], "config": " {\"host\":\"localhost:389\",\"insecureNoSSL\":true,\"bindDN\":\"cn=admin,dc=example,dc=org\",\"bindPW\":\"admin\",\"usernamePrompt\":\"Email Address\",\"userSearch\":{\"baseDN\":\"ou=People,dc=example,dc=org\",\"filter\":\"(objectClass=person)\",\"username\":\"cn\",\"idAttr\":\"DN\",\"emailAttr\":\"mail\",\"nameAttr\":\"cn\"},\"groupSearch\":{\"baseDN\":\"ou=Groups,dc=example,dc=org\",\"filter\":\"(objectClass=groupOfNames)\",\"userAttr\":\"DN\",\"groupAttr\":\"member\",\"nameAttr\":\"cn\"}}" //ldap配置 } }
d. 删除IDP
curl -XDELETE https://{auth_address}/apis/auth.tkestack.io/v1/identityproviders/ldap-test -H 'Authorization: Bearer {admin_token}'
8.7 -
如何做日志分析
为集群开启日志采集功能后,在【运维中心】中配置【日志采集规则】,将日志输出。。。
8.8 -
功能类
9.1 - 1.5
TKEStack Release v1.5.0
TKEStack 1.5.0 版本,相较于上一版本(v1.4.x),增加了集群升级,master节点扩容,导入外部应用商店功能等,同时对监控组件,工作负载等页面也进行了优化,满足海量 pod 工作负载的分页和查询。
Installation
参考 QuickStart 指引快速安装部署TKEStack平台。
AMD64版本
arch=amd64 version=v1.5.0 && wget https://tke-release-1251707795.cos.ap-guangzhou.myqcloud.com/tke-installer-linux-$arch-$version.run{,.sha256} && sha256sum --check --status tke-installer-linux-$arch-$version.run.sha256 && chmod +x tke-installer-linux-$arch-$version.run && ./tke-installer-linux-$arch-$version.run
ARM64版本
arch=arm64 version=v1.5.0 && wget https://tke-release-1251707795.cos.ap-guangzhou.myqcloud.com/tke-installer-linux-$arch-$version.run{,.sha256} && sha256sum --check --status tke-installer-linux-$arch-$version.run.sha256 && chmod +x tke-installer-linux-$arch-$version.run && ./tke-installer-linux-$arch-$version.run
Changelog since v1.4.0
完整的修改日志请查阅 changelog
A complete changelog for the release notes please check at changelog
Major Feature and Enhancements
集群功能
- 提供了集群升级的功能,支持将独立集群或global集群的K8S 版本 vx.y.z 升级,支持次要版本升级(y+1),以及补丁版本升级(z)。 提供Auto 自动和Manual 手动升级两种模式,自动模式下TKEStack按顺序滚动升级所有master 节点和worker 节点;手动模式下可单独升级master 节点,单独选择部分或所有 worker 节点进行升级。所有升级过程可观察,并且支持配置节点驱逐和最大不可用pod数,保证升级过程的稳定。
- 支持master节点扩容和缩容能力,以满足对性能和高可用的需求。该功能需要集群apiserver地址为高可用 vip或 loadbalance地址,且待添加master节点与原节点在同一网段,操作系统与环境相同。
- 支持通过 kubeconfig 文件自动导入集群,优化导入集群操作体验。
应用商店和镜像仓库
- 支持导入外部应用商店,常用helm仓库地址都可快速导入和同步。
- 支持根据多用户或业务创建和分配模板仓库。
- 同时镜像仓库部分也进行了代码重构,支持对接distribution和harbor作为存储后端。
前端分页和搜索
- 优化workload下的pod管理页面的分页和搜索功能,支持按 pod 名称,IP,状态及自定义label字段查询。
- 页面支持修改节点 Taint。
- 支持为 TAPP 类型工作负载开启监控。
其他
- 新增了监控组件的配置页面,用户可根据集群运行环境配置合理的监控参数。
- 审计,日志和事件等功能支持对接至 ElasticSearch 7.5.1 版本,支持修改 ES 地址,index patern,用户名密码等。
Bugs Fixed
自 v1.4.0 以来修复的主要问题
- 参见 Bug Fixes
Versions
离线安装包地址
https://tke-release-1251707795.cos.ap-guangzhou.myqcloud.com/tke-installer-linux-amd64-v1.5.0.run
arm64版本
https://tke-release-1251707795.cos.ap-guangzhou.myqcloud.com/tke-installer-linux-arm64-v1.5.0.run
Kubernetes 版本
kube-apiserver-amd64:v1.16.9
kube-apiserver-amd64:v1.17.13
kube-apiserver-amd64:v1.18.3
kube-apiserver-arm64:v1.16.9
kube-apiserver-arm64:v1.17.13
kube-apiserver-arm64:v1.18.3
kube-controller-manager-amd64:v1.16.9
kube-controller-manager-amd64:v1.17.13
kube-controller-manager-amd64:v1.18.3
kube-controller-manager-arm64:v1.16.9
kube-controller-manager-arm64:v1.17.13
kube-controller-manager-arm64:v1.18.3
kube-proxy-amd64:v1.16.9
kube-proxy-amd64:v1.17.13
kube-proxy-amd64:v1.18.3
kube-proxy-arm64:v1.16.9
kube-proxy-arm64:v1.17.13
kube-proxy-arm64:v1.18.3
kube-scheduler-amd64:v1.16.9
kube-scheduler-amd64:v1.17.13
kube-scheduler-amd64:v1.18.3
kube-scheduler-arm64:v1.16.9
kube-scheduler-arm64:v1.17.13
kube-scheduler-arm64:v1.18.3
镜像版本
tke-application-api-amd64:v1.5.0
tke-application-api-arm64:v1.5.0
tke-application-controller-amd64:v1.5.0
tke-application-controller-arm64:v1.5.0
tke-audit-api-amd64:v1.5.0
tke-audit-api-arm64:v1.5.0
tke-auth-api-amd64:v1.5.0
tke-auth-api-arm64:v1.5.0
tke-auth-controller-amd64:v1.5.0
tke-auth-controller-arm64:v1.5.0
tke-business-api-amd64:v1.5.0
tke-business-api-arm64:v1.5.0
tke-business-controller-amd64:v1.5.0
tke-business-controller-arm64:v1.5.0
tke-gateway-amd64:v1.5.0
tke-gateway-arm64:v1.5.0
tke-logagent-api-amd64:v1.5.0
tke-logagent-api-arm64:v1.5.0
tke-logagent-controller-amd64:v1.5.0
tke-logagent-controller-arm64:v1.5.0
tke-monitor-api-amd64:v1.5.0
tke-monitor-api-arm64:v1.5.0
tke-monitor-controller-amd64:v1.5.0
tke-monitor-controller-arm64:v1.5.0
tke-notify-api-amd64:v1.5.0
tke-notify-api-arm64:v1.5.0
tke-notify-controller-amd64:v1.5.0
tke-notify-controller-arm64:v1.5.0
tke-platform-api-amd64:v1.5.0
tke-platform-api-arm64:v1.5.0
tke-platform-controller-amd64:v1.5.0
tke-platform-controller-arm64:v1.5.0
tke-registry-api-amd64:v1.5.0
tke-registry-api-arm64:v1.5.0
tke-registry-controller-amd64:v1.5.0
tke-registry-controller-arm64:v1.5.0
其他addon镜像版本
addon-resizer-amd64:1.8.11
addon-resizer-arm64:1.8.11
alertmanager:v0.18.0
busybox-amd64:1.31.0
busybox-amd64:1.31.1
busybox-arm64:1.31.0
busybox-arm64:1.31.1
configmap-reload:v0.1
coredns-amd64:1.6.7
coredns-arm64:1.6.7
cron-hpa-controller:v1.0.0
csi-operator:v1.0.2
etcd-amd64:v3.4.7
etcd-arm64:v3.4.7
flannel-amd64:v0.10.0
flannel-arm64:v0.10.0
galaxy-amd64:v1.0.6
galaxy-arm64:v1.0.6
galaxy-ipam-amd64:v1.0.6
galaxy-ipam-arm64:v1.0.6
gpu-manager:v1.0.4
gpu-quota-admission:v1.0.0
helm-api:v1.3
influxdb-amd64:1.7.9
influxdb-arm64:1.7.9
k8s-prometheus-adapter:4c67353
keepalived-amd64:2.0.16-r0
keepalived-arm64:2.0.16-r0
kube-state-metrics:v1.9.5
lbcf-controller:v1.0.0.rc.2
log-agent:v1.1.0
log-collector:v1.1.0
log-file:v1.1.0
metrics-server-amd64:v0.3.6
metrics-server-arm64:v0.3.6
node-exporter:v0.18.1
node-problem-detector:v0.8.2
nvidia-device-plugin:1.0.0-beta4
pause-amd64:3.1
pause-arm64:3.1
prometheus-config-reloader:v0.31.1
prometheus-operator:v0.31.1
prometheus:v2.16.0
prometheusbeat:6.4.1
provider-res-amd64:v1.18.3-2
provider-res-arm64:v1.18.3-2
registry-amd64:2.7.1
registry-arm64:2.7.1
swift:0.9.0
tapp-controller:v1.1.1
tiller:v2.10.0
tke-audit-collector:v1.10.0
tke-event-watcher:v0.1
volume-decorator:v1.0.1
Known Issues
Upgrades Notes
暂不支持自动升级,需要人工升级操作,升级过程保证configmap,workload 配置以及组件镜像的同时升级。
9.2 - 1.4
TKEStack Release v1.4.0
TKEStack v1.4.0 版本继续增强平台健壮性和易用性,修复社区和用户发现的问题Issue,升级Tapp应用和Galaxy网络扩展组件版本。 新增 Helm 模板和仓库功能,支持 Helm v3 应用的安装部署。 新增集群概览页面,集中展示多集群资源和负载情况,增加了更多的metrics监控指标,帮助用户更相信准确的评估健康状态。 独立出 HPA 和 CronHPA 自动伸缩页面,允许客户更灵活的自定义弹性伸缩规则。 增强了集群的管理和安全能力,支持为集群独立开启或关闭功能组件,支持使用主机 hostname 作为集群节点名称,加固TKEStack底层基础镜像。
Installation
参考 QuickStart 指引快速安装部署TKEStack平台。
AMD64版本
arch=amd64 version=v1.4.0 && wget https://tke-release-1251707795.cos.ap-guangzhou.myqcloud.com/tke-installer-linux-$arch-$version.run{,.sha256} && sha256sum --check --status tke-installer-linux-$arch-$version.run.sha256 && chmod +x tke-installer-linux-$arch-$version.run && ./tke-installer-linux-$arch-$version.run
ARM64版本
arch=arm64 version=v1.4.0 && wget https://tke-release-1251707795.cos.ap-guangzhou.myqcloud.com/tke-installer-linux-$arch-$version.run{,.sha256} && sha256sum --check --status tke-installer-linux-$arch-$version.run.sha256 && chmod +x tke-installer-linux-$arch-$version.run && ./tke-installer-linux-$arch-$version.run
Changelog since v1.3.1
完整的修改日志请查阅 changelog
A complete changelog for the release notes please check at changelog
Major Feature and Enhancements
Helm charts仓库和应用中心
- 新增 Helm 模板和仓库功能,支持 Helm v3 应用的安装部署。
集群概览
- 新增集群概览页面,集中展示多集群资源和负载情况,增加了更多的metrics监控指标,帮助用户更相信准确的评估健康状态
HPA 和 CronHPA
- 独立出 HPA 和 CronHPA 自动伸缩页面,允许客户更灵活的自定义弹性伸缩规则。
其他
- 增强了集群的管理和安全能力,支持为集群独立开启或关闭功能组件
- 支持使用主机 hostname 作为集群节点名称
- 加固TKEStack底层基础镜像。
Bugs Fixed
自 v1.3.1 以来修复的主要问题
- 参见 Bug Fixes
Versions
离线安装包地址
https://tke-release-1251707795.cos.ap-guangzhou.myqcloud.com/tke-installer-linux-amd64-v1.4.0.run
arm64版本
https://tke-release-1251707795.cos.ap-guangzhou.myqcloud.com/tke-installer-linux-arm64-v1.4.0.run
Kubernetes 版本
kube-apiserver-amd64:v1.16.9
kube-apiserver-amd64:v1.18.3
kube-apiserver-arm64:v1.16.9
kube-apiserver-arm64:v1.18.3
kube-controller-manager-amd64:v1.16.9
kube-controller-manager-amd64:v1.18.3
kube-controller-manager-arm64:v1.16.9
kube-controller-manager-arm64:v1.18.3
kube-proxy-amd64:v1.16.9
kube-proxy-amd64:v1.18.3
kube-proxy-arm64:v1.16.9
kube-proxy-arm64:v1.18.3
kube-scheduler-amd64:v1.16.9
kube-scheduler-amd64:v1.18.3
kube-scheduler-arm64:v1.16.9
kube-scheduler-arm64:v1.18.3
镜像版本
tkestack/tke-auth-api-amd64:v1.4.0
tkestack/tke-auth-api-arm64:v1.4.0
tkestack/tke-auth-controller-amd64:v1.4.0
tkestack/tke-auth-controller-arm64:v1.4.0
tkestack/tke-business-api-amd64:v1.4.0
tkestack/tke-business-api-arm64:v1.4.0
tkestack/tke-business-controller-amd64:v1.4.0
tkestack/tke-business-controller-arm64:v1.4.0
tkestack/tke-gateway-amd64:v1.4.0
tkestack/tke-gateway-arm64:v1.4.0
tkestack/tke-logagent-api-amd64:v1.4.0
tkestack/tke-logagent-api-arm64:v1.4.0
tkestack/tke-logagent-controller-amd64:v1.4.0
tkestack/tke-logagent-controller-arm64:v1.4.0
tkestack/tke-monitor-api-amd64:v1.4.0
tkestack/tke-monitor-api-arm64:v1.4.0
tkestack/tke-monitor-controller-amd64:v1.4.0
tkestack/tke-monitor-controller-arm64:v1.4.0
tkestack/tke-notify-api-amd64:v1.4.0
tkestack/tke-notify-api-arm64:v1.4.0
tkestack/tke-notify-controller-amd64:v1.4.0
tkestack/tke-notify-controller-arm64:v1.4.0
tkestack/tke-platform-api-amd64:v1.4.0
tkestack/tke-platform-api-arm64:v1.4.0
tkestack/tke-platform-controller-amd64:v1.4.0
tkestack/tke-platform-controller-arm64:v1.4.0
tkestack/tke-registry-api-amd64:v1.4.0
tkestack/tke-registry-api-arm64:v1.4.0
其他addon镜像版本
addon-resizer-amd64:1.8.11
addon-resizer-arm64:1.8.11
alertmanager:v0.18.0
busybox-amd64:1.31.0
busybox-amd64:1.31.1
busybox-arm64:1.31.0
busybox-arm64:1.31.1
configmap-reload:v0.1
coredns-amd64:1.6.7
coredns-arm64:1.6.7
cron-hpa-controller:v1.0.0
csi-operator:v1.0.2
etcd-amd64:v3.4.7
etcd-arm64:v3.4.7
flannel-amd64:v0.10.0
flannel-arm64:v0.10.0
galaxy-amd64:v1.0.6
galaxy-arm64:v1.0.6
galaxy-ipam-amd64:v1.0.6
galaxy-ipam-arm64:v1.0.6
gpu-manager:v1.0.4
gpu-quota-admission:v1.0.0
helm-api:v1.3
influxdb-amd64:1.7.9
influxdb-arm64:1.7.9
keepalived-amd64:2.0.16-r0
keepalived-arm64:2.0.16-r0
kube-state-metrics:v1.9.5
lbcf-controller:v1.0.0.rc.2
log-agent:v1.1.0
log-collector:v1.1.0
log-file:v1.1.0
metrics-server-amd64:v0.3.6
metrics-server-arm64:v0.3.6
node-exporter:v0.18.1
node-problem-detector:v0.8.2
nvidia-device-plugin:1.0.0-beta4
pause-amd64:3.1
pause-arm64:3.1
prometheus-config-reloader:v0.31.1
prometheus-operator:v0.31.1
prometheus:v2.16.0
prometheusbeat:6.4.1
provider-res-amd64:v1.18.3-1
provider-res-arm64:v1.18.3-1
registry-amd64:2.7.1
registry-arm64:2.7.1
swift:0.9.0
tapp-controller:v1.1.1
tiller:v2.10.0
tke-audit-collector:v0.3
tke-event-watcher:v0.1
volume-decorator:v1.0.1
Known Issues
Upgrades Notes
暂不支持自动升级,需要人工升级操作,升级过程保证configmap,workload 配置以及组件镜像的同时升级。
9.3 - 1.3
TKEStack Release v1.3.0
TKEStack v1.3.0 版本已于本周发布,相较上一版本(v1.2.x)增强了用户权限,业务能力,优化日志、审计及监控告警等功能,支持最新 K8S v1.18.3 及 v1.16.9 版本,同时修复大量影响业务功能和使用体验的bug。
TKEStack 是腾讯内部几大团队合力打造的开源版本,总结了多年来腾讯在云原生领域的经验和技术积累,吸收了 Gaia 平台、TKE 公有云以及腾讯内部众多容器产品的优点,全新打造的面向私有云业务场景的开源容器平台。
本次版本重点增强用户权限及业务管理能力,区分平台用户和业务用户,平台用户负责维护平台下集群,节点,业务及运维中心等资源,保障平台的正常运行和资源的可用; 业务用户专注自身业务应用的配置管理和部署发布,通过统一提供的配额、命名空间以及镜像仓库等管理能力,方便用户在多集群场景下编排业务应用。
本版本还在日志功能上有较大重构和增强,对原有 logcollector 扩展组件进行降级处理,增加了 logagent 日志组件设置页面,用以控制集群的日志采集功能。 支持在工作负载创建时配置日志目录,指定日志输出的数据卷和挂载点;在详情页的日志面板下,支持查看日志文件的内容并能够下载日志文件。 增加了业务管理视图下日志采集页面,支持对命名空间下的工作负载、容器等配置日志采集规则。完备的采集策略将支持用户全程监控记录业务应用运行数据,及时高效地发现和定位问题。
新增审计功能,记录并保存用户操作记录,并提供独立的页面方便管理员集中查看和搜索审计记录,满足相关机构对平台安全合规的要求。 同时优化大量监控告警等指标参数,并支持多种通知告警渠道帮助管理员第一时间发现平台问题。更多优化请参考 Major Feature and Enhancements
Installation
参考 QuickStart 指引快速安装部署TKEStack平台。
AMD64版本
arch=amd64 version=v1.3.0 && wget https://tke-release-1251707795.cos.ap-guangzhou.myqcloud.com/tke-installer-linux-$arch-$version.run{,.sha256} && sha256sum --check --status tke-installer-linux-$arch-$version.run.sha256 && chmod +x tke-installer-linux-$arch-$version.run && ./tke-installer-linux-$arch-$version.run
ARM64版本
arch=arm64 version=v1.3.0 && wget https://tke-release-1251707795.cos.ap-guangzhou.myqcloud.com/tke-installer-linux-$arch-$version.run{,.sha256} && sha256sum --check --status tke-installer-linux-$arch-$version.run.sha256 && chmod +x tke-installer-linux-$arch-$version.run && ./tke-installer-linux-$arch-$version.run
Changelog since v1.2.4
完整的修改日志请查阅 changelog
A complete changelog for the release notes please check at changelog
Major Feature and Enhancements
用户权限
- 增加预设平台策略:平台管理员、平台用户、平台租户,允许用户在新建或更新时绑定不同的平台策略权限,更支持为用户自定义独立的权限,方便管理平台视图下集群,业务,扩展组件及运维中心等功能。
- 增加预设业务策略:业务管理员、业务成员、只读成员,同时支持配置自定义业务权限,允许用户为不同业务绑定不同的业务权限,方便用户在业务视图下实现更细粒度的权限控制。
业务管理
- 增强业务管理功能,支持用户在业务管理视图下查看自身业务详情,包括资源配额、成员列表、子业务及命名空间,具有业务管理员权限的用户可以管理自身业务的成员、子业务和命名空间。
- 平台管理员负责管理各个业务的配额,支持根据不同集群设置不同配额。支持子业务的解除和导入,支持命名空间在不同业务下迁移。
- 支持生成业务下命名空间访问凭证,获得访问凭证(kubeconfig) 的用户有权限访问和操作(kubectl) 指定命名空间下的资源.
日志
- 新建工作负载时支持配置日志目录,指定日志输出的数据卷和挂载点。在pod详情页中的日志面板下,支持查看文件日志的内容。
- 平台管理视图下增加了日志组件设置页面,同时在集群基本信息页面也增加日志组件按钮,用以控制开启或关闭集群的日志采集功能。
- 业务管理视图下增加日志采集页面,支持命名空间下的工作负载、容器等配置日志采集规则。
- 对 logcollector 组件进行降级处理,已安装 log-collector 组件的可以删除,未安装 log-collector 组件的将无法新增安装,前台代码还对各处的 logAgent 和 logCollector 做了兼容处理
审计
- 新增审计功能,记录并保存用户操作记录,包括时间、操作人、操作类、集群、命名空间、资源类型、操作对象及操作结果,并有独立的页面方便管理员集中查看审计记录。
监控告警
- 升级后台 prometheus 至 v2.16.0,增加对 prometheus 的资源配额限制
- 优化业务指标页面数据,优化工作负载监控页面展示
- 创建告警支持选择某一个 ns 下所有 pod/ 某一个 ns 下某一类工作负载的 pod。新增对 tapp 类型的告警和监控支持。
- 新增历史告警记录功能,记录保存平台下所有触发的告警记录.
- 新增 webhook 告警渠道,增加通知模板说明指引,累计已支持邮件、短信、微信公众号及 webhook 通知渠道。
其他
- 新建工作负载页面支持配置 pod annotatoion,支持配置多行容器运行命令,支持 field 环境变量引用类型,支持权限集配置,支持滚动列表展示指定节点调度。
- 新增导入集群检查机制,对已导入的集群或版本不符合要求的集群禁止导入。
- 登录 pod 支持多种命令行。
- tke-installer 增加对 logagent,audit 等组件的安装配置管理。
- 优化 tke 组件的资源配额
- 支持对接外部 etcd
Bugs Fixed
自 v1.2.5 以来修复的主要问题
- 修复由k8s升级导致的 Deployment 无法在控制台里回滚
- 业务管理控制台 pod 销毁重建操作前台发起的api中namespace参数不对
- 业务管理控制台 helm 应用展示没有区分ns
- namespace detail page is always loading
- 私有镜像仓库设置 Secret,密码长度输入限制
- Chart 包地址和镜像路径显示不全,且没有复制的按钮
- 业务管理控制台无法新建通知模板
- 扩展组件新建异常或一直检查
- Namespace 状态无法自动恢复
- 安装 VolumeDecorator失败
- Master 支持通过keepalive + iptables 实现负载均衡
- Create ClusterCredential before create Cluster
- Delete Imported cluster hang in Terminating
- Docker startup err not detected
- 节点列表搜索一个 nodename,点开后的 yaml 显示的并不是该节点的 yaml
- 创建应用时环境变量支持小数点
- 告警策略创建时,pod ready 的默认值调整为 false,包括平台管理和业务管理
- Webshell 使用 vim 时卡住
- QR code into wechat group is not valid any more
Versions
离线安装包地址
https://tke-release-1251707795.cos.ap-guangzhou.myqcloud.com/tke-installer-linux-amd64-v1.3.0.run
arm64版本
https://tke-release-1251707795.cos.ap-guangzhou.myqcloud.com/tke-installer-linux-arm64-v1.3.0.run
Kubernetes 版本
kube-apiserver-amd64:v1.16.9
kube-apiserver-amd64:v1.18.3
kube-apiserver-arm64:v1.16.9
kube-apiserver-arm64:v1.18.3
kube-controller-manager-amd64:v1.16.9
kube-controller-manager-amd64:v1.18.3
kube-controller-manager-arm64:v1.16.9
kube-controller-manager-arm64:v1.18.3
kube-proxy-amd64:v1.16.9
kube-proxy-amd64:v1.18.3
kube-proxy-arm64:v1.16.9
kube-proxy-arm64:v1.18.3
kube-scheduler-amd64:v1.16.9
kube-scheduler-amd64:v1.18.3
kube-scheduler-arm64:v1.16.9
kube-scheduler-arm64:v1.18.3
镜像版本
tkestack/tke-auth-api-amd64:v1.3.0
tkestack/tke-auth-api-arm64:v1.3.0
tkestack/tke-auth-controller-amd64:v1.3.0
tkestack/tke-auth-controller-arm64:v1.3.0
tkestack/tke-business-api-amd64:v1.3.0
tkestack/tke-business-api-arm64:v1.3.0
tkestack/tke-business-controller-amd64:v1.3.0
tkestack/tke-business-controller-arm64:v1.3.0
tkestack/tke-gateway-amd64:v1.3.0
tkestack/tke-gateway-arm64:v1.3.0
tkestack/tke-logagent-api-amd64:v1.3.0
tkestack/tke-logagent-api-arm64:v1.3.0
tkestack/tke-logagent-controller-amd64:v1.3.0
tkestack/tke-logagent-controller-arm64:v1.3.0
tkestack/tke-monitor-api-amd64:v1.3.0
tkestack/tke-monitor-api-arm64:v1.3.0
tkestack/tke-monitor-controller-amd64:v1.3.0
tkestack/tke-monitor-controller-arm64:v1.3.0
tkestack/tke-notify-api-amd64:v1.3.0
tkestack/tke-notify-api-arm64:v1.3.0
tkestack/tke-notify-controller-amd64:v1.3.0
tkestack/tke-notify-controller-arm64:v1.3.0
tkestack/tke-platform-api-amd64:v1.3.0
tkestack/tke-platform-api-arm64:v1.3.0
tkestack/tke-platform-controller-amd64:v1.3.0
tkestack/tke-platform-controller-arm64:v1.3.0
tkestack/tke-registry-api-amd64:v1.3.0
tkestack/tke-registry-api-arm64:v1.3.0
其他addon镜像版本
alertmanager:v0.18.0
busybox-amd64:1.31.0
busybox-amd64:1.31.1
busybox-arm64:1.31.0
busybox-arm64:1.31.1
configmap-reload:v0.1
coredns-amd64:1.6.7
coredns-arm64:1.6.7
cron-hpa-controller:v1.0.0
csi-operator:v1.0.2
etcd-amd64:v3.4.7
etcd-arm64:v3.4.7
flannel-amd64:v0.10.0
flannel-arm64:v0.10.0
galaxy-amd64:v1.0.4
galaxy-arm64:v1.0.4
galaxy-ipam-amd64:v1.0.4
galaxy-ipam-arm64:v1.0.4
gpu-manager:v1.0.4
gpu-quota-admission:v1.0.0
helm-api:v1.3
influxdb-amd64:1.7.9
influxdb-arm64:1.7.9
keepalived-amd64:2.0.16-r0
keepalived-arm64:2.0.16-r0
kube-state-metrics:v1.9.5
lbcf-controller:v1.0.0.rc.2
log-agent:v1.1.0
log-collector:v1.1.0
log-file:v1.1.0
node-exporter:v0.18.1
nvidia-device-plugin:1.0.0-beta4
pause-amd64:3.1
pause-arm64:3.1
prometheus-config-reloader:v0.31.1
prometheus-operator:v0.31.1
prometheus:v2.16.0
prometheusbeat:6.4.1
provider-res-amd64:v1.18.3-1
provider-res-arm64:v1.18.3-1
registry-amd64:2.7.1
registry-arm64:2.7.1
swift:0.9.0
tapp-controller:v1.0.0
tiller:v2.10.0
volume-decorator:v1.0.1
Known Issues
Upgrades Notes
暂不支持自动升级,需要人工升级操作,升级过程保证configmap,workload 配置以及组件镜像的同时升级。