FAQ
- 1: 部署类
- 2: 平台类
- 3: 授权类
- 3.1: 如何接入LDAP&OIDC
- 3.2: 业务管理、平台管理的区别
- 3.3: 如何设置自定义策略
- 3.4: Docker login 权限错误
- 4: 事件类
- 4.1: 常见错误事件
- 5:
- 6:
- 7:
- 8:
1 - 部署类
1.1 - 常见报错解决方法
当前 TKEStack 使用 tke-Installer 一键安装,安装过程中的错误主要集中在硬件和软件配置上,安装前请仔细阅读环境要求文档:
如何重新部署集群
重试安装
若安装报错后,请先排障,再登录到 Installer 节点执行如下命令后,重新打开 http://[tke-installer-IP]:8080/index.html 安装控制台。
docker restart tke-installer
重新安装
安装报错后,请先排障,再登录到 Installer 节点执行如下命令后,重新打开 http://[tke-installer-IP]:8080/index.html 安装控制台。
rm -rf /opt/tke-installer && docker restart tke-installer
注:重新安装前,请先清理节点上的残留:清除残留
清除残留
在添加新的节点或者重装环境之前,需要彻底清理节点,请对 Installer 或所有加入的节点执行下方脚本清理残留配置和文件。
curl -s https://tke-release-1251707795.cos.ap-guangzhou.myqcloud.com/tools/clean.sh | sh
或者使用如下脚本:
#!/bin/bash
rm -rf /etc/kubernetes
systemctl stop kubelet 2>/dev/null
docker rm -f $(docker ps -aq) 2>/dev/null
systemctl stop docker 2>/dev/null
ip link del cni0 2>/etc/null
for port in 80 2379 6443 8086 {10249..10259} ; do
fuser -k -9 ${port}/tcp
done
rm -rfv /etc/kubernetes
rm -rfv /etc/docker
rm -fv /root/.kube/config
rm -rfv /var/lib/kubelet
rm -rfv /var/lib/cni
rm -rfv /etc/cni
rm -rfv /var/lib/etcd
rm -rfv /var/lib/postgresql /etc/core/token /var/lib/redis /storage /chart_storage
systemctl start docker 2>/dev/null
注:如有混合部署其他业务,请基于实际情况评估目录内数据是否可删除。
安装密码报错
错误情况:使用密码安装 Global 集群报 ssh:unable to authenticate 错误
解决方案:将 Global 集群节点/etc/ssh/sshd_config配置文件中的PasswordAuthentication设为yes,重启sshd服务。
1.2 - 如何规划部署资源
TKEStack支持使用物理机或虚拟机部署,采用kubernetes on kubernetes架构部署,在主机上只拥有一个物理机进程kubelet,其他kubernetes组件均为容器。架构上分为global集群和业务集群。global集群,运行整个TKEStack平台自身所需要的组件,业务集群运行用户业务。在实际的部署过程中,可根据实际情况进行调整。
安装TKEStack,需要提供两种角色的 Server:
Installer server 1台,用以部署集群安装器,安装完成后可以回收。
Global server,若干台,用以部署 Globa 集群,常见的部署模式分为三种:
- All in one 模式,1台server部署 Global集群,global集群同时也充当业务集群的角色,即运行平台基础组件,又运行业务容器。global集群会默认设置taint不可调度,使用此模式时,需要手工在golbal集群【节点管理】-【更多】-【编辑Taint】中去除不可调度设置。(关于taint,了解更多)。由于此种模式不具有高可用能力,不建议在生产环境中使用。
- Global 与业务集群混部的高可用模式,3台Server部署global集群,global集群同时也充当业务集群的角色,即运行平台基础组件,又运行业务容器。global集群会默认设置taint不可调度,使用此模式时,需要手工在golbal集群【节点管理】-【更多】-【编辑Taint】中去除不可调度设置。(关于taint,了解更多)。由于此种模式有可能因为业务集群资源占用过高而影响global集群,不建议在生产环境中使用。
- Global 与业务集群分别部署的高可用模式,3台Server部署global集群,仅运行平台自身组件,业务集群单独在TKEStack控制台上创建(建议3台以上),此种模式下,业务资源占有与平台隔离,建议在生产环境中使用此种模式。
集群节点主机配置,请参考资源需求。
1.3 -
如何使用存储
TKEStack 没有提供存储服务,Global集群中的镜像仓库、ETCD、InfluxDB等数据组件,均使用本地磁盘存储数据。如果您需要使用存储服务,建议使用ROOK或者chubaoFS,部署一套容器化的分布式存储服务。
2 - 平台类
2.1 - 监控告警指标列表
监控 & 告警指标列表
目前 TKEStack 提供了以下维度的监控指标,所有指标均为统计周期内的平均值。
监控
集群监控指标
| 指标 | 单位 | 说明 |
|---|---|---|
| CPU 利用率 | % | 集群整体的 CPU 利用率 |
| 内存利用率 | % | 集群整体的内存利用率 |
节点监控指标
| 指标 | 单位 | 说明 |
|---|---|---|
| Pod 重启次数 | 次 | 节点内所有 Pod 的重启次数之和 |
| 异常状态 | - | 节点的状态,正常或异常 |
| CPU 利用率 | % | 节点内所有 Pod 的 CPU 使用量占节点总量之比 |
| 内存利用率 | % | 节点内所有 Pod 的内存使用量占节点总量之比 |
| 内网入带宽 | bps | 节点内所有 Pod 的内网入方向带宽之和 |
| 内网出带宽 | bps | 节点内所有 Pod 的内网出方向带宽之和 |
| 外网入带宽 | bps | 节点内所有 Pod 的外网入方向带宽之和 |
| 外网出带宽 | bps | 节点内所有 Pod 的外网出方向带宽之和 |
| TCP 连接数 | 个 | 节点保持的 TCP 连接数 |
工作负载监控指标
| 指标 | 单位 | 说明 |
|---|---|---|
| Pod 重启次数 | 次 | 工作负载内所有 Pod 的重启次数之和 |
| CPU 使用量 | 核 | 工作负载内所有 Pod 的 CPU 使用量 |
| CPU 利用率(占集群) | % | 工作负载内所有 Pod 的 CPU 使用量占集群总量之比 |
| 内存使用量 | B | 工作负载内所有 Pod 的内存使用量 |
| 内存利用率(占集群) | % | 工作负载内所有 Pod 的内存使用量占集群总量之比 |
| 网络入带宽 | bps | 工作负载内所有 Pod 的入方向带宽之和 |
| 网络出带宽 | bps | 工作负载内所有 Pod 的出方向带宽之和 |
| 网络入流量 | B | 工作负载内所有 Pod 的入方向流量之和 |
| 网络出流量 | B | 工作负载内所有 Pod 的出方向流量之和 |
| 网络入包量 | 个/s | 工作负载内所有 Pod 的入方向包数之和 |
| 网络出包量 | 个/s | 工作负载内所有 Pod 的出方向包数之和 |
Pod 监控指标
| 指标 | 单位 | 说明 |
|---|---|---|
| 异常状态 | - | Pod 的状态,正常或异常 |
| CPU 使用量 | 核 | Pod 的 CPU 使用量 |
| CPU 利用率(占节点) | % | Pod 的 CPU 使用量占节点总量之比 |
| CPU 利用率(占 Request) | % | Pod 的 CPU 使用量和设置的 Request 值之比 |
| CPU 利用率(占 Limit) | % | Pod 的 CPU 使用量和设置的 Limit 值之比 |
| 内存使用量 | B | Pod 的内存使用量,含缓存 |
| 内存使用量(不包含 Cache) | B | Pod 内所有 Container 的真实内存使用量(不含缓存) |
| 内存利用率(占节点) | % | Pod 的内存使用量占节点总量之比 |
| 内存利用率(占节点,不包含 Cache) | % | Pod 内所有 Container 的真实内存使用量(不含缓存)占节点总量之比 |
| 内存利用率(占 Request) | % | Pod 的内存使用量和设置的 Request 值之比 |
| 内存利用率(占 Request,不包含Cache) | % | Pod 内所有 Container 的真实内存使用量(不含缓存)和设置的 Request 值之比 |
| 内存利用率(占 Limit) | % | Pod 的内存使用量和设置的 Limit 值之比 |
| 内存利用率(占 Limit,不包含 Cache) | % | Pod 内所有 Container 的真实内存使用量(不含缓存)和设置的 Limit 值之比 |
| 网络入带宽 | bps | Pod 的入方向带宽之和 |
| 网络出带宽 | bps | Pod 的出方向带宽之和 |
| 网络入流量 | B | Pod 的入方向流量之和 |
| 网络出流量 | B | Pod 的出方向流量之和 |
| 网络入包量 | 个/s | Pod 的入方向包数之和 |
| 网络出包量 | 个/s | Pod 的出方向包数之和 |
Container 监控指标
| 指标 | 单位 | 说明 |
|---|---|---|
| CPU 使用量 | 核 | Container 的 CPU 使用量 |
| CPU 利用率(占节点) | % | Container 的 CPU 使用量占节点总量之比 |
| CPU 利用率(占 Request) | % | Container 的 CPU 使用量和设置的 Request 值之比 |
| CPU 利用率(占 Limit) | % | Container 的 CPU 使用量和设置的 Limit 值之比 |
| 内存使用量 | B | Container 的内存使用量,含缓存 |
| 内存使用量(不包含 Cache) | B | Container 的真实内存使用量(不含缓存) |
| 内存利用率(占节点) | % | Container 的内存使用量占节点总量之比 |
| 内存利用率(占节点,不包含 Cache) | % | Container 的真实内存使用量(不含缓存)占节点总量之比 |
| 内存利用率(占 Request) | % | Container 的内存使用量和设置的 Request 值之比 |
| 内存利用率(占 Request,不包含 Cache) | % | Container 的真实内存使用量(不含缓存)和设置的 Request 值之比 |
| 内存利用率(占 Limit) | % | Container 的内存使用量和设置的 Limit 值之比 |
| 内存利用率(占 Limit,不包含 Cache) | % | Container 的真实内存使用量(不含缓存)和设置的 Limit 值之比 |
| 块设备读带宽 | B/s | Container 从硬盘读取数据的吞吐量 |
| 块设备写带宽 | B/s | Container 把数据写入硬盘的吞吐量 |
| 块设备读 IOPS | 次/s | Container 从硬盘读取数据的 IO 次数 |
| 块设备写 IOPS | 次/s | Container 把数据写入硬盘的 IO 次数 |
告警
目前容器服务提供了以下维度的告警指标,所有指标均为统计周期内的平均值。
集群告警指标
| 指标 | 单位 | 说明 |
|---|---|---|
| CPU 利用率 | % | 集群整体的 CPU 利用率 |
| 内存利用率 | % | 集群整体的内存利用率 |
| CPU 分配率 | % | 集群所有容器设置的 CPU Request 之和与集群总可分配 CPU 之比 |
| 内存分配率 | % | 集群所有容器设置的内存 Request 之和与集群总可分配内存之比 |
| Apiserver 正常 | - | Apiserver 状态,默认 False 时告警,仅独立集群支持该指标 |
| ETCD 正常 | - | ETCD 状态,默认 False 时告警,仅独立集群支持该指标 |
| Scheduler 正常 | - | Scheduler 状态,默认 False 时告警,仅独立集群支持该指标 |
| Controll Manager 正常 | - | Controll Manager 状态,默认 False 时告警,仅独立集群支持该指标 |
节点告警指标
| 指标 | 单位 | 说明 |
|---|---|---|
| CPU 利用率 | % | 节点内所有 Pod 的 CPU 使用量占节点总量之比 |
| 内存利用率 | % | 节点内所有 Pod 的内存使用量占节点总量之比 |
| 节点上 Pod 重启次数 | 次 | 节点内所有 Pod 重启次数之和 |
| Node Ready | - | 节点状态,默认 False 时告警 |
Pod 告警指标
| 指标 | 单位 | 说明 |
|---|---|---|
| CPU 利用率(占节点) | % | Pod 的 CPU 使用量占节点总量之比 |
| 内存利用率(占节点) | % | Pod 的内存使用量占节点总量之比 |
| 实际内存利用率(占节点,不包含 Cache) | % | Pod 内所有 Container 的真实内存使用量(不含缓存)占节点总量之比 |
| CPU 利用率(占 Limit) | % | Pod 的CPU使用量和设置的 Limit 值之比 |
| 内存利用率(占 Limit) | % | Pod 的内存使用量和设置的 Limit 值之比 |
| 实际内存利用率(占 Limit,不包含 Cache) | % | Pod 内所有 Container 的真实内存使用量(不含缓存)和设置的 Limit 值之比 |
| Pod 重启次数 | 次 | Pod 的重启次数 |
| Pod Ready | - | Pod 的状态,默认 False 时告警 |
| CPU 使用量 | 核 | Pod 的 CPU 使用量 |
| 内存使用量 | MB | Pod 的内存使用量,含缓存 |
| 实际内存使用量 | MB | Pod 内所有 Container 的真实内存使用量之和,不含缓存 |
2.2 - 平台使用常见问题
此处为平台使用常见问题,在使用 TKEStack 过程中,欢迎在 issue 上提出自己的问题,最好配上相关的信息和截图,以便我们更好定位问题所在,每个 issue 我们都会认真对待。
APIServer 的 Real 和 Advertise

Real:表示 Master 节点 APIServer
Advertise:表示高可用 VIP 的 APIServer、或者是各大云厂商托管集群的 APIServer 地址
global 集群没出现
参考:清除浏览器缓存
field is immuable

参考:表示已有同名对象,例如已有同名 Service,需要手动删除 Service,或者换个名字
控制台无法编辑节点 Taint
在部署负载时,有时会出现下图中的事件,表示节点被 Taint

原因:通过 TKEStack 部署的集群里 Master 节点默认带污点(taint),是为了防止业务 Pod 运行在 Master 节点上,此时如果平台有问题的话,业务也会挂掉。但在测试环境中,节点有限的情况下,可以适当删除节点的 taint,但在控制台上没办法删掉,只能在命令行删除

node(s) had tiant
解决方法和上图一样,删除或注释节点中的 taint
镜像仓库镜像上传问题
WARNING! Using --password via the CLI is insecure. Use --password-stdin.
Error response from daemon: Get https://defult.registry.tke.com/v2/: dial tcp: lookup defult.registry.tke.com on 183.60.83.19:53: no such host
很可能是因为 Registry container 没有启动
kubectl get pod -n tke | grep tke-registry
事件持久化插件无法点击完成来添加
原因:在页面下方要添加用于持久化的 ES 地址和索引
注意:当前只支持未开启 用户登录认证 的 ES 集群
业务管理界面没有找到想要的业务
因为当前用户不是该业务的成员,需要为该业务添加成员用户

业务的 NS 只能选择一个集群
业务下的每个命名空间只能选取一个集群,因为是在这个集群下面新建的这个命名空间

数据卷 以主机路径为例
主机路径为节点上的一个地址
注意:主机路径指的是 Pod 所在主机的路径

下图2和3中的 testv 相当于一个标签,用于指定不同的挂载类型,本例为主机路径
4中的目录为容器中的目录,会在容器的根目录中创建一个 hahaha 的文件夹
最后一个框为路径/hahaha下面的路径,可不填

使用数据卷的效果:主机上的主机路径和容器上的hahaha文件夹中的内容完全一致
kube-state-metrics 和 metric-server 的区别
metric-server
TKEStack 的 Global 集群和新建的独立集群会默认安装名为 metric-server 的负载,是一个容器资源监控和性能分析工具。只是显示数据,并不提供数据存储服务,类似 cAdvisor(默认集成在 kubelet 中)、heapster(已被 metric-server 替代),可以利用 metric-server 提供的数据实现 HPA
kube-state-metrics
使用 TKEStack 为集群安装 Prometheus 监控组件时会安装名为 kube-state-metrics 的负载,用于为 Prometheus 提供监控数据。kube-state-metrics 基于 client-go 开发的服务,监听 Kubernetes APIServer,并将 Kubernetes 的结构化信息转换为 metrics,它不关注单个 Kubernetes 组件的运行状况,而是关注内部各种对象(例如 Deployment、Node、Pod)的运行状况。
kube-state-metrics 和 metric-server 一样,只是简单提供一个 metrics 数据,并不会存储这些指标数据,所以我们可以使用 Prometheus 来抓取这些数据然后存储
kube-state-metrics-service.yaml 中有 prometheus.io/scrape: ‘true’ 标识,因此会将 metrics 暴露给Prometheus,而 Prometheus 会在 kubernetes-service-endpoints 这个 job 下自动发现 kube-state-metrics,并开始拉取 metrics,无需其他配置。
使用 kube-state-metrics 后的常用场景有:
- 存在执行失败的 Job: kube_job_status_failed{job=“kubernetes-service-endpoints”,k8s_app=“kube-state-metrics”}==1
- 集群节点状态错误: kube_node_status_condition{condition=“Ready”,status!=“true”}==1
- 集群中存在启动失败的 Pod:kube_pod_status_phase{phase=~“Failed|Unknown”}==1
- 最近30分钟内有 Pod 容器重启: changes(kube_pod_container_status_restarts[30m])>0
- 配合报警可以更好地监控集群的运行
区别
- kube-state-metrics 主要关注的是业务相关的一些元数据,针对是是 k8s 集群内资源对象数据,比如 Deployment、Pod、副本状态等
- metrics-server 主要关注的是资源度量 API 的实现,比如 CPU、文件描述符、内存、请求延时等指标
- metric-server(或 heapster)是从 api-server 中获取 CPU、内存使用率这种监控指标,并把他们发送给存储后端,如 InfluxDB 或云厂商,他当前的核心作用是:为 HPA 等组件提供决策指标支持
- kube-state-metrics关注于获取 k8s 各种资源的最新状态,如 Deployment 或者 DaemonSet,之所以没有把 kube-state-metrics 纳入到 metric-server 的能力中,是因为他们的关注点本质上是不一样的。 metric-server 仅仅是获取、格式化现有数据,写入特定的存储,实质上是一个监控系统。而 kube-state-metrics 是将 k8s 的运行状况在内存中做了个快照,并且获取新的指标,但他没有能力导出这些指标
- 换个角度讲,kube-state-metrics 本身是 metric-server 的一种数据来源,虽然现在没有这么做
- 另外,像 Prometheus 这种监控系统,并不会去用 metric-server 中的数据,他都是自己做指标收集、集成的(Prometheus 包含了 metric-server的能力),但 Prometheus 可以监控 metric-server本 身组件的监控状态并适时报警,这里的监控就可以通过 kube-state-metrics 来实现,如 metric-server 的 Pod 的运行状态
2.3 -
平台使用常见问题
3 - 授权类
3.1 - 如何接入LDAP&OIDC
接入LDAP、OIDC有两种方式;
- 在集群安装时,配置OIDC认证信息,关于OIDC配置信息,请参考Configuring the API Server。

集群安装完成后,可以通过调用API的形式切换认证模式为OIDC或LDAP
a. 修改auth配置文件,configmap: tke-auth-api,指定默认idp类型为ldap:
"auth": { "init_tenant_type": "ldap", // 指定ldap类型的idp "init_tenant_id": "ldap-test", // tenant id "init_idp_administrators": ["jane"], //idp的管理员列表,需要存在客户ldap系统中,具有平台的超级管理员权限 "ldap_config_file":"_debug/auth-ldap.json", }b. 准备ldap配置文件,配置说明参见:dex-ldap
{ //ldap地址,host:port "host": "localhost:389", "insecureNoSSL": true, // 是否开始SSL,如果host没有指定端口,ture,端口为389和false, 端口为636 "bindDN": "cn=admin,dc=example,dc=org", //服务账户的DN和密码,用来查询ldap用户组和用户 "bindPW": "admin", //密码 "usernamePrompt": "User Name", // "userSearch": { "baseDN": "ou=People,dc=example,dc=org", //用户baseDN "filter": "(objectClass=person)", //查询过滤条件 "username": "cn", // username的属性key,cn=jane,ou=People,dc=example,dc=org "idAttr": "DN", // user id的属性key "emailAttr": "mail", // 邮件属性key "nameAttr": "cn" //displayname 的属性key }, "groupSearch": { "baseDN": "ou=Groups,dc=example,dc=org",//用户组baseDN "filter": "(objectClass=groupOfNames)", //查询过滤条件 "userAttr": "DN", //用户组成员id属性key "groupAttr": "member", //用户组成员key "nameAttr": "cn" //用户组名称key } }c. 调用API,新增ldap idp,
curl -XPOST https://{auth_address}/apis/auth.tkestack.io/v1/identityproviders -H 'Authorization: Bearer {admin_token}' -H 'Content-Type: application/json' Body:
{ "metadata": { "name": "ldap-test" //tennatID }, "spec": { "name": "ldap-test", "type": "ldap", "administrators": [ //超级管理员 "jane" ], "config": " {\"host\":\"localhost:389\",\"insecureNoSSL\":true,\"bindDN\":\"cn=admin,dc=example,dc=org\",\"bindPW\":\"admin\",\"usernamePrompt\":\"Email Address\",\"userSearch\":{\"baseDN\":\"ou=People,dc=example,dc=org\",\"filter\":\"(objectClass=person)\",\"username\":\"cn\",\"idAttr\":\"DN\",\"emailAttr\":\"mail\",\"nameAttr\":\"cn\"},\"groupSearch\":{\"baseDN\":\"ou=Groups,dc=example,dc=org\",\"filter\":\"(objectClass=groupOfNames)\",\"userAttr\":\"DN\",\"groupAttr\":\"member\",\"nameAttr\":\"cn\"}}" //ldap配置 } }
d. 删除IDP
curl -XDELETE https://{auth_address}/apis/auth.tkestack.io/v1/identityproviders/ldap-test -H 'Authorization: Bearer {admin_token}'
3.2 - 业务管理、平台管理的区别
TKEStack的权限体系分为业务使用者和平台管理员两种角色,平台管理员可以管理平台所有功能,业务使用者可以访问自己有权限的业务或者namespace下的资源。同时平台管理员可以通过自定义策略,定义不同的策略类型。
3.3 - 如何设置自定义策略
TKEStack 策略(policy)用来描述授权的具体信息。核心元素包括操作(action)、资源(resource)以及效力(effect)。
操作(action)
描述允许或拒绝的操作。操作可以是 API(以 name 前缀描述)或者功能集(一组特定的 API,以 permid 前缀描述)。该元素是必填项。
资源(resource)
描述授权的具体数据。资源是用六段式描述。每款产品的资源定义详情会有所区别。有关如何指定资源的信息,请参阅您编写的资源声明所对应的产品文档。该元素是必填项。
效力(effect)
描述声明产生的结果是“允许”还是“显式拒绝”。包括 allow(允许)和 deny (显式拒绝)两种情况。该元素是必填项。
策略样例
该样例描述为:允许关联到此策略的用户,对cls-123集群下的工作负载deploy-123中的所有资源,有查看权限。
{
"actions": [
"get*",
"list*",
"watch*"
],
"resources": [
"cluster:cls-123/deployment:deploy-123/*"
],
"effect": "allow"
}
3.4 - Docker login 权限错误
Docker login 权限错误
在Tkestack选用用了自建证书,需要用户在客户端手动导入,docker login 权限报错:certificate signed by unknown authority。
方法一
在 Global 集群上执行 kubectl get cm certs -n tke -o yaml 将 ca.crt 内容保存到客户端节点的/etc/docker/certs.d/**/ca.crt ( 为镜像仓库地址) 重启docker即可
方法二:
在/etc/docker/daemon.json文件里添加insecure-registries,如下: { “insecure-registries”: [ “xxx”,“xxx” ] } (* 为镜像仓库地址)
重启docker即可
4 - 事件类
4.1 - 常见错误事件
常见错误事件
Back-off restarting failed docker container
说明:正在重启异常的 Docker 容器。 解决方法:检查镜像中执行的 Docker 进程是否异常退出,若镜像内并无一持续运行的进程,可在创建服务的页面中添加执行脚本。
fit failure on node: Insufficient cpu
说明:集群 CPU 不足。 解决方法:原因是节点无法提供足够的计算核心,请在服务页面修改 CPU 限制或者对集群进行扩容。
no nodes available to schedule pods
说明:集群资源不足。 解决方法:原因是没有足够的节点用于承载实例,请在服务页面修改服务的实例数量,修改实例数量或者 CPU 限制。
pod failed to fit in any node
说明:没有合适的节点可供实例使用。 解决方法:原因是服务配置了不合适的资源限制,导致没有合适的节点用于承载实例,请在服务页面修改服务的实例数量或者 CPU 限制。
Liveness probe failed
说明:容器健康检查失败 解决方法:检查镜像内容器进程是否正常,检查检测端口是否配置正确。
Error syncing pod, skipping
Error syncing pod, skipping failed to “StartContainer” for with CrashLoopBackOff: “Back-off 5m0s restarting failed container 说明:容器进程崩溃或退出。 解决方法:检查容器内是否有持续运行的前台进程,若有检查其是否有异常行为。详情请参考 如何构建Docker 镜像。
6 -
如何接入LDAP&OIDC
接入LDAP、OIDC有两种方式;
- 在集群安装时,配置OIDC认证信息,关于OIDC配置信息,请参考Configuring the API Server。
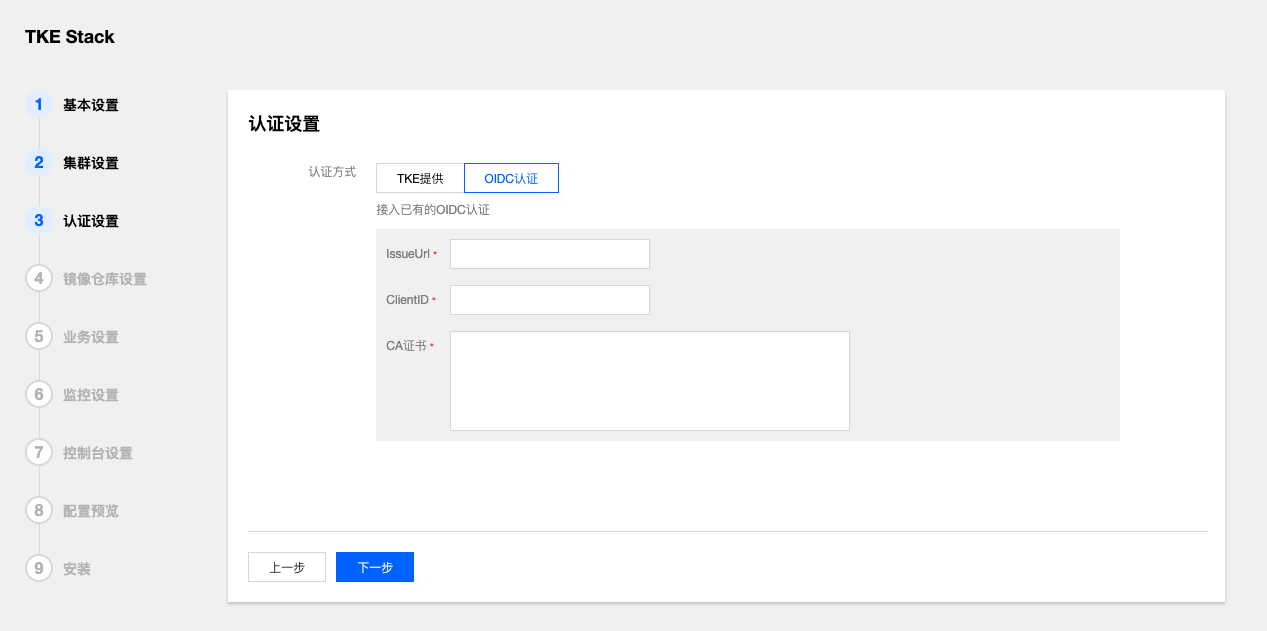
集群安装完成后,可以通过调用API的形式切换认证模式为OIDC或LDAP
a. 修改auth配置文件,configmap: tke-auth-api,指定默认idp类型为ldap:
"auth": { "init_tenant_type": "ldap", // 指定ldap类型的idp "init_tenant_id": "ldap-test", // tenant id "init_idp_administrators": ["jane"], //idp的管理员列表,需要存在客户ldap系统中,具有平台的超级管理员权限 "ldap_config_file":"_debug/auth-ldap.json", }b. 准备ldap配置文件,配置说明参见:dex-ldap
{ //ldap地址,host:port "host": "localhost:389", "insecureNoSSL": true, // 是否开始SSL,如果host没有指定端口,ture,端口为389和false, 端口为636 "bindDN": "cn=admin,dc=example,dc=org", //服务账户的DN和密码,用来查询ldap用户组和用户 "bindPW": "admin", //密码 "usernamePrompt": "User Name", // "userSearch": { "baseDN": "ou=People,dc=example,dc=org", //用户baseDN "filter": "(objectClass=person)", //查询过滤条件 "username": "cn", // username的属性key,cn=jane,ou=People,dc=example,dc=org "idAttr": "DN", // user id的属性key "emailAttr": "mail", // 邮件属性key "nameAttr": "cn" //displayname 的属性key }, "groupSearch": { "baseDN": "ou=Groups,dc=example,dc=org",//用户组baseDN "filter": "(objectClass=groupOfNames)", //查询过滤条件 "userAttr": "DN", //用户组成员id属性key "groupAttr": "member", //用户组成员key "nameAttr": "cn" //用户组名称key } }c. 调用API,新增ldap idp,
curl -XPOST https://{auth_address}/apis/auth.tkestack.io/v1/identityproviders -H 'Authorization: Bearer {admin_token}' -H 'Content-Type: application/json' Body:
{ "metadata": { "name": "ldap-test" //tennatID }, "spec": { "name": "ldap-test", "type": "ldap", "administrators": [ //超级管理员 "jane" ], "config": " {\"host\":\"localhost:389\",\"insecureNoSSL\":true,\"bindDN\":\"cn=admin,dc=example,dc=org\",\"bindPW\":\"admin\",\"usernamePrompt\":\"Email Address\",\"userSearch\":{\"baseDN\":\"ou=People,dc=example,dc=org\",\"filter\":\"(objectClass=person)\",\"username\":\"cn\",\"idAttr\":\"DN\",\"emailAttr\":\"mail\",\"nameAttr\":\"cn\"},\"groupSearch\":{\"baseDN\":\"ou=Groups,dc=example,dc=org\",\"filter\":\"(objectClass=groupOfNames)\",\"userAttr\":\"DN\",\"groupAttr\":\"member\",\"nameAttr\":\"cn\"}}" //ldap配置 } }
d. 删除IDP
curl -XDELETE https://{auth_address}/apis/auth.tkestack.io/v1/identityproviders/ldap-test -H 'Authorization: Bearer {admin_token}'
7 -
如何做日志分析
为集群开启日志采集功能后,在【运维中心】中配置【日志采集规则】,将日志输出。。。