1 - 产品部署架构
总体架构
TKEStack 产品架构如下图所示:
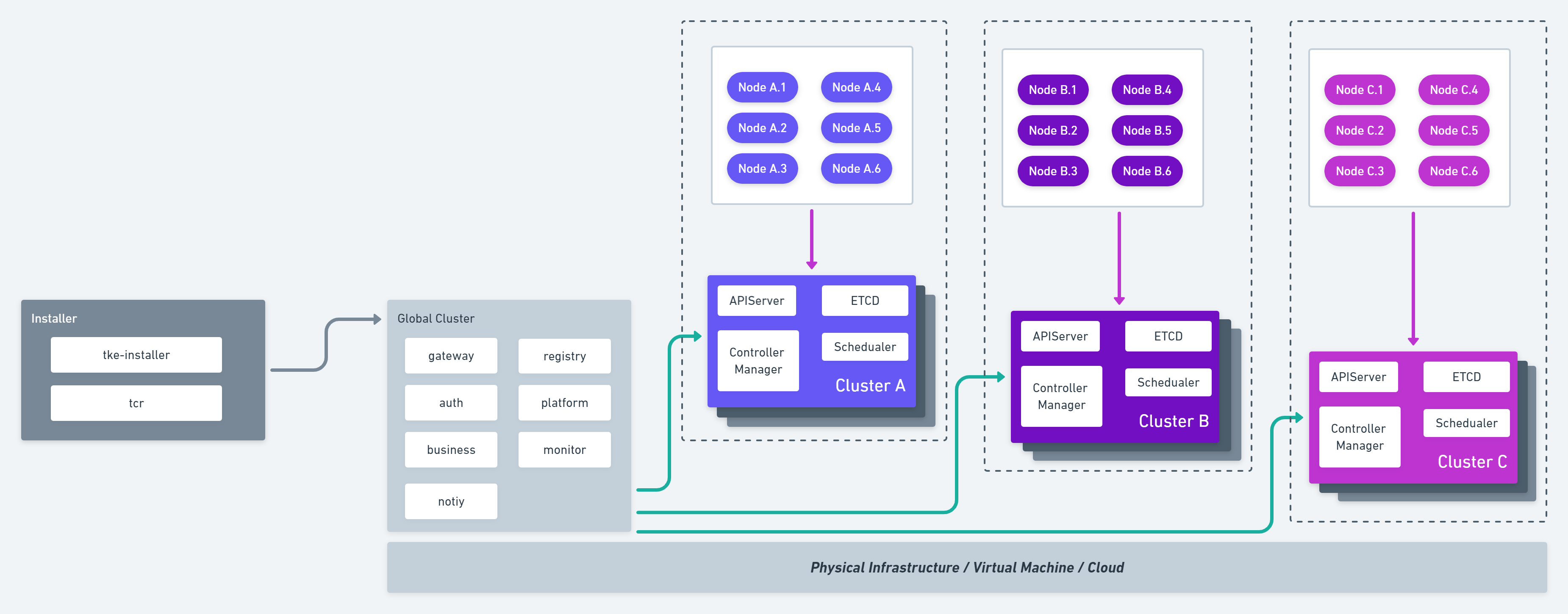
架构说明
TKEStack 采用了 Kubernetes on Kubernetes 的设计理念。即节点仅运行 Kubelet 进程,其他组件均采用容器化部署,由 Kubernetes 进行管理。
架构上分为 Global 集群和业务集群。Global 集群运行整个容器服务开源版平台自身所需要的组件,业务集群运行用户业务。在实际的部署过程中,可根据实际情况进行调整。
模块说明
- Installer: 运行 tke-installer 安装器的节点,用于提供 Web UI 指导用户在 Global 集群部署TKEStacl控制台;
- Global Cluster: 运行的 TKEStack 控制台的 Kubernetes 集群;
- Cluster: 运行业务的 Kubernetes 集群,可以通过 TKEStack 控制台创建或导入;
- Auth: 权限认证组件,提供用户鉴权、权限对接相关功能;
- Gateway: 网关组件,实现集群后台统一入口、统一鉴权相关的功能,并运行控制台的 Web 界面服务;
- Platform: 集群管理组件,提供 Global 集群管理多个业务集群相关功能;
- Business: 业务管理组件,提供平台业务管理相关功能的后台服务;
- Network Controller:网络服务组件,支撑 Galaxy 网络功能;
- Monitor: 监控服务组件,提供监控采集、上报、告警相关服务;
- Notify: 通知功能组件,提供消息通知相关的功能;
- Registry: 镜像服务组件,提供平台镜像仓库服务;
2 - 部署环境要求
硬件要求
特别注意:
安装的时候,至少需要一个 Installer 节点和一个作为 Global 集群的 master 节点共两个节点。 > > v1.3.0 之后的版本可直接使用 All-In-One 的安装模式,此时 Installer 节点也可以作为 Global 集群的节点。但注意:此时 Installer 的节点配置要以 Global 集群的节点配置为准,否则 Installer 节点配置太低很容易安装失败。另外该功能还不是很成熟,为避免安装失败,尽量将 Installer 节点和 Global 节点分开始用
Installer 节点:是单独的用作安装的节点,不能作为 Global 集群的节点使用。因为在安装 Global 集群时,需要多次重启 docker,此时如果 Global 集群里面有 Installer 节点,重启 docker 会中断 Global 集群的安装。该节点需要一台系统盘 100G 的机器,系统盘要保证剩余 50GB 可用的空间。 > > v1.3.0 之后 Installer 节点支持作为 Global 集群的节点使用,但注意此时 Installer 节点配置以 Global 集群的节点为准
Global 集群:至少需要一台 8核16G内存,100G系统盘的机器。
业务集群:业务集群是在部署完 Global 集群之后再添加的。
- 最小化部署硬件配置:
| 安装/业务集群 | 节点/集群 | CPU 核数 | 内存 | 系统盘 | 数量 |
|---|---|---|---|---|---|
| 安装 | Installer 节点 | 1 | 2G | 100G | 1 |
| TKEStack 控制台 | Global 集群 | 8 | 16G | 100G | 1 |
| 业务集群 | Master & ETCD | 4 | 8G | 100G | 1 |
| 业务集群 | Node | 8 | 16G | 100G | 3 |
- 推荐硬件配置:
| 安装/业务集群 | 节点/集群 | CPU 核数 | 内存 | 系统盘 | 数量 |
|---|---|---|---|---|---|
| 安装 | Installer 节点 | 1 | 2G | 100G | 1 |
| TKEStack 控制台 | Global 节点 | 8 | 16G | 100G SSD | 3 |
| 业务集群 | Master & ETCD | 16 | 32G | 300G SSD | 3 |
| 业务集群 | Node | 16 | 32G | 系统盘:100G 数据盘:300G (/var/lib/docker) | >3 |
注意:上表中的数据盘(/var/lib/docker)表示的是 docker 相关信息在主机中存储的位置,即容器数据盘,包括 docker 的镜像、容器、日志(如果容器的日志文件所在路径没有挂载 volume,日志文件会被写入容器可写层,落盘到容器数据盘里)等文件。建议给此路径挂盘,避免与系统盘混用,避免因容器、镜像、日志等 docker 相关信息导致磁盘压力过大。
软件要求
注意,以下要求针对集群中的所有节点
| 需求项 | 具体要求 | 命令参考 (以 CentOS 7.6为例) |
|---|---|---|
| 操作系统 | Ubuntu 16.04/18.04 LTS (64-bit) CentOS Linux 7.6 (64-bit) Tencent Linux 2.2 | cat /etc/redhat-release |
| kernel 版本 | >= Kernel 3.10.0-957.10.1.el7.x86_64 | uname -sr |
| ssh sudo yum CLI | 确保 Installer 节点及其容器、 Global 集群节点及其容器、 业务集群节点及其容器…之间能够 ssh 互联; 确保每个节点都有基础工具 | 1. 确保在添加所有节点时,IP 和密码输入正确。 2. 确保每个节点都有 sudo 或 root 权限 3. 如果是 CentOS,确保拥有 yum;其他操作系统类似,确保拥有包管理器 4. 确保拥有命令行工具 |
| Swap | 关闭。 如果不满足,系统会有一定几率出现 io 飙升,造成 docker 卡死。kubelet 会启动失败 (可以设置 kubelet 启动参数 –fail-swap-on 为 false 关闭 swap 检查) | sudo swapoff -asudo sed -i '/ swap / s/^\(.*\)$/#\1/g' /etc/fstab# 注意:如果 /etc/fstab有挂载 swap,必须要注释掉,不然重新开机时又会重新挂载 swap |
| 防火墙 | 关闭。 或者至少要放通22、80、8080、443、6443、2379、2380、10250-10255、31138 端口 | 可通过以下关闭防火墙systemctl stop firewalld && systemctl disable firewalld或者通过以下命令放通指定端口,例如只放通80端口 firewall-cmd --zone=public --add-port=80/tcp --permanent |
| SELinux | 关闭。 Kubernetes 官方要求,否则 kubelet 挂载目录时可能报错 Permission denied | setenforce 0sed -i "s/SELINUX=enforcing/SELINUX=disabled/g" /etc/selinux/config |
| 时区 | 所有服务器时区必须统一,建议设置为 Asia/Shanghai | timedatectl set-timezone Asia/Shanghai |
| 时间同步 | ETCD 集群各机器需要时间同步,可以利用 chrony 用于系统时间同步; 所有服务器要求时间必须同步,误差不得超过 2 秒 | yum install -y chronydsystemctl enable chronyd && systemctl start chronyd |
| 路由检查 | 有些设备可能会默认配置一些路由,这些路由可能与 TKEStack 冲突,建议删除这些路由并做相关配置 | ip link delete docker0ip link add name docker0 type bridgeip addr add dev docker0 172.17.0.1/16 |
| docker 检查 | 有些设备可能会默认安装 docker,该 docker 版本可能与 TKEStack 不一致, 建议在安装 TKEStack 之前删除docker | yum remove docker-ce containerd docker-ce-cli -y |
3 - 安装使用 GPU
安装使用步骤
安装使用步骤
限制条件
- 用户在安装使用GPU时,要求集群内必须包含GPU机型节点
- 该组件基于 Kubernetes DevicePlugin 实现,只能运行在支持 DevicePlugin 的 kubernetes版本(Kubernetes 1.10 之上的版本)
- GPU-Manager 将每张 GPU 卡视为一个有100个单位的资源:当前仅支持 0-1 的小数张卡,如 20、35、50;以及正整数张卡,如200、500等;不支持类似150、250的资源请求;显存资源是以 256MiB 为最小的一个单位的分配显存
TKEStack 支持的 GPU 类型
TKEStack目前支持两种GPU类型:
- vGPU:虚拟GPU类型(Virtual GPU),当选择安装此类型的GPU时,平台会自动安装组件GPUManager,对应在集群中部署的kubernetes资源对象如下:
| kubernetes 对象名称 | 类型 | 建议预留资源 | 所属 Namespaces |
|---|---|---|---|
| gpu-manager-daemonset | DaemonSet | 每节点1核 CPU, 1Gi内存 | kube-system |
| gpu-quota-admission | Deployment | 1核 CPU, 1Gi内存 | kube-system |
- pGPU: 物理GPU类型(Physical GPU),当选择安装此类型的GPU时,平台会自动安装组件Nvidia-k8s-device-plugin,对应的在集群中部署的kubernetes资源对象如下:
| kubernetes 对象名称 | 类型 | 建议预留资源 | 所属 Namespaces |
|---|---|---|---|
| nvidia-device-plugin-daemonset | DaemonSet | 每节点1核 CPU, 1Gi内存 | kube-system |
安装步骤
安装使用 vGPU
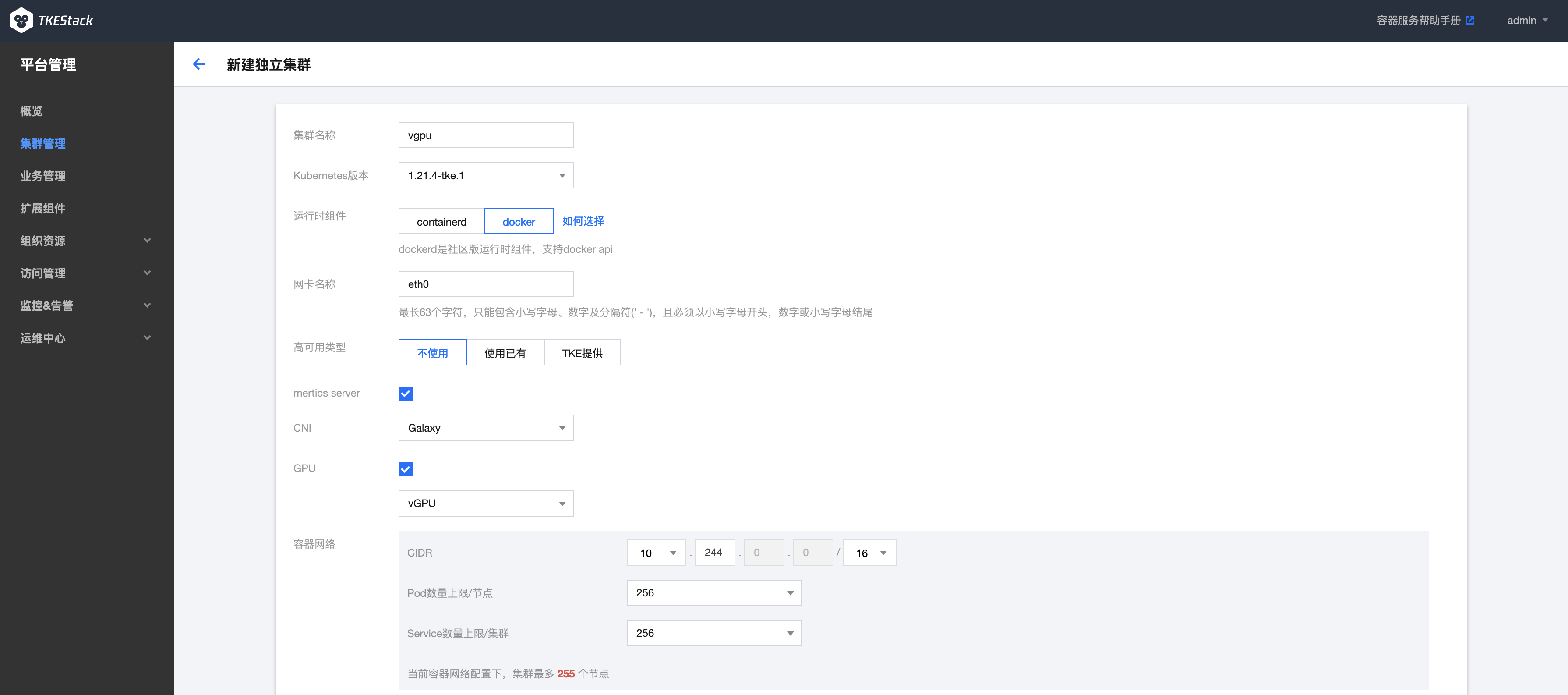
用户在新建独立集群时,勾选GPU选项,在下拉选项中选择 vGPU,如下图所示:
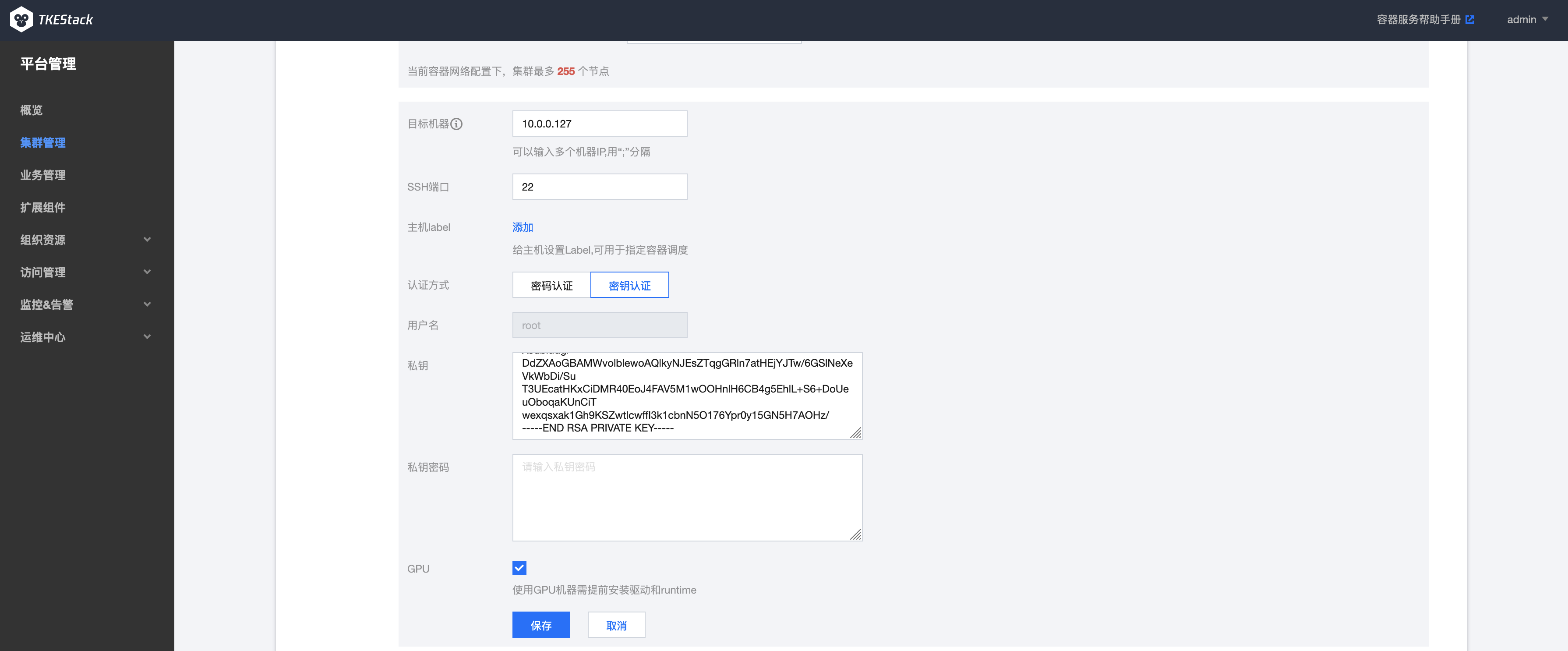
目标机器部分,勾选GPU选项,平台会自动为节点安装GPU驱动,如下图所示:
等待新建独立集群处于running状态后,可以通过登陆到集群节点通过kubectl查看在集群kube-system命名空间中部署了gpu-manager和gpu-quota-admission两个pod:
# kubectl get pods -n kube-system | grep gpu
gpu-manager-daemonset-2vvbm 1/1 Running 0 2m13s
gpu-quota-admission-76cfff49b6-vdh42 1/1 Running 0 3m2s
创建使用 vGPU 的工作负载
TKEStack创建使用GPU的工作负载支持两种方式:第一种是通过TKEStack前端页面创建,第二种是通过后台命令行的方式创建。
1、 通过前端控制台创建
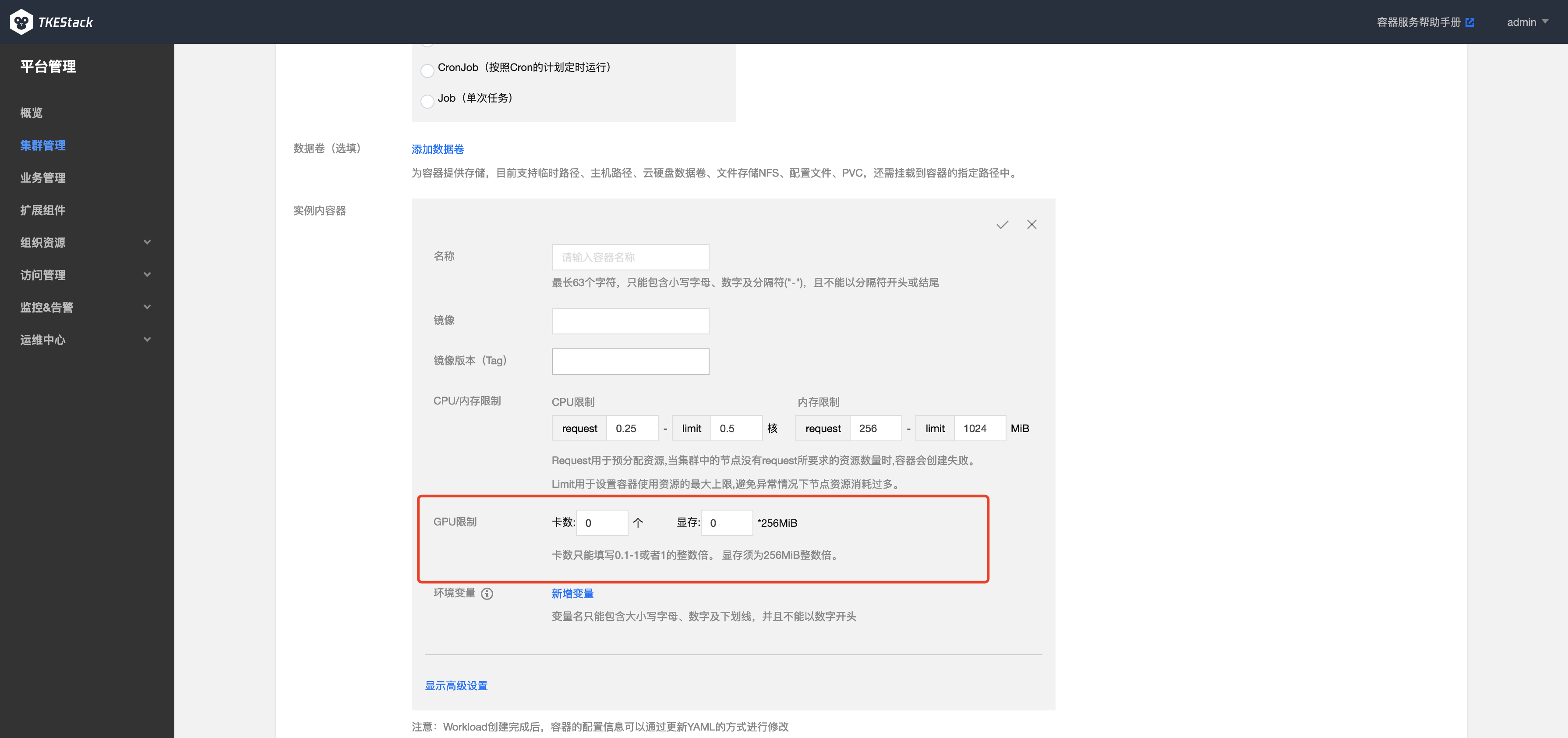
在安装了 GPU-Manager 的集群中,创建工作负载时可以设置GPU限制,如下图所示:
注意:
- 卡数只能填写 0.1 到 1 之间的两位小数或者是所有自然数,例如:0、0.3、0.56、0.7、0.9、1、6、34,不支持 1.5、2.7、3.54
- 显存只能填写自然数 n,负载使用的显存为 n*256MiB
2、 通过后台命令行创建
使用 YAML 创建使用 GPU 的工作负载,需要在 YAML 文件中为容器设置 GPU 的使用资源。
- CPU 资源需要在 resource 上填写
tencent.com/vcuda-core - 显存资源需要在 resource 上填写
tencent.com/vcuda-memory
如下所示:创建一个使用 0.3 张卡、5GiB 显存的nginx应用(5GiB = 20*256MB)
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
resources:
limits:
tencent.com/vcuda-core: 30
tencent.com/vcuda-memory: 20
requests:
tencent.com/vcuda-core: 30
tencent.com/vcuda-memory: 20
# kubectl create -f nginx.yaml
pod/nginx created
注意:
- 如果pod在创建过程中出现CrashLoopBackOff 的状态,且error log如下所示:
failed to create containerd task: OCI runtime create failed: container_linux.go:380: starting container process caused: process_linux.go:545: container init caused: Running hook #0:: error running hook: exit status 1, stdout: , stderr: nvidia-container-cli: mount error: open failed: /sys/fs/cgroup/devices/system.slice/containerd.service/kubepods-besteffort-podfd3b355a_665c_4c95_8e7f_61fd2111689f.slice/devices.allow: no such file or directory: unknown需要在GPU主机上手动安装libnvidia-container-tools这个组件,首先需要添加repo源:添加repo源, 添加repo源后执行如下命令:
# yum install libnvidia-container-tools
- 如果pod在创建过程中出现如下error log:
failed to generate spec: lstat /dev/nvidia-uvm: no such file or directory需要在pod所在的主机上手动mount这个设备文件:
# nvidia-modprobe -u -c=0
查看创建的应用状态:
# kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx 1/1 Running 0 3s
查看GPU监控数据(需要提前安装socat):
# yum install socat
# kubectl port-forward svc/gpu-manager-metric -n kube-system 5678:5678
# curl http://127.0.0.1:5678/metric
结果如下
Handling connection for 5678
# HELP container_gpu_memory_total gpu memory usage in MiB
# TYPE container_gpu_memory_total gauge
container_gpu_memory_total{container_name="nginx",gpu_memory="gpu0",namespace="default",node="10.0.0.127",pod_name="nginx"} 0
container_gpu_memory_total{container_name="nginx",gpu_memory="total",namespace="default",node="10.0.0.127",pod_name="nginx"} 0
# HELP container_gpu_utilization gpu utilization
# TYPE container_gpu_utilization gauge
container_gpu_utilization{container_name="nginx",gpu="gpu0",namespace="default",node="10.0.0.127",pod_name="nginx"} 0
container_gpu_utilization{container_name="nginx",gpu="total",namespace="default",node="10.0.0.127",pod_name="nginx"} 0
# HELP container_request_gpu_memory request of gpu memory in MiB
# TYPE container_request_gpu_memory gauge
container_request_gpu_memory{container_name="nginx",namespace="default",node="10.0.0.127",pod_name="nginx",req_of_gpu_memory="total"} 5120
# HELP container_request_gpu_utilization request of gpu utilization
# TYPE container_request_gpu_utilization gauge
container_request_gpu_utilization{container_name="nginx",namespace="default",node="10.0.0.127",pod_name="nginx",req_of_gpu="total"} 0.30000001192092896
安装使用 pGPU
用户在新建独立集群时,勾选GPU选项,在下拉选项中选择pGPU,如下图所示:
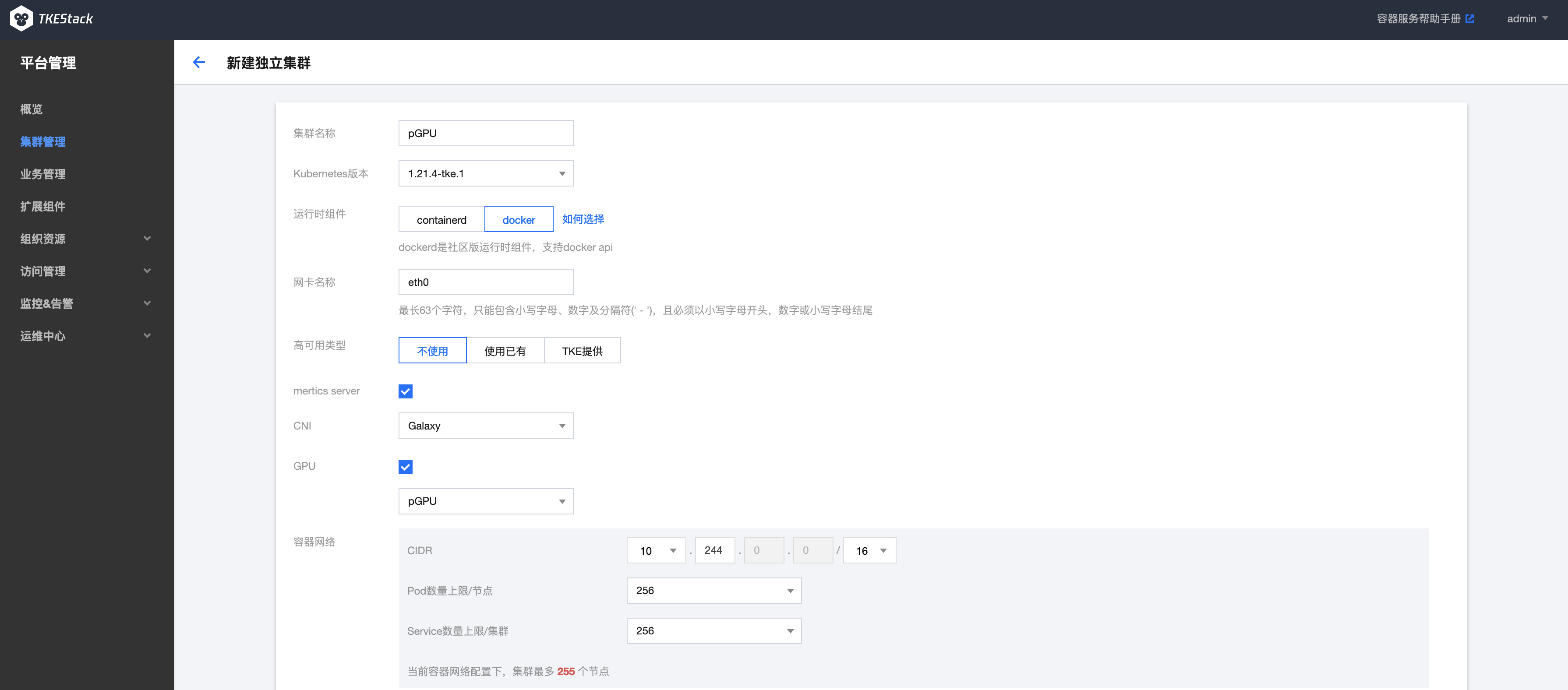
目标机器部分,勾选GPU选项,平台会自动为节点安装GPU驱动,如下图所示:
等待新建独立集群处于running状态后,可以通过登陆到集群节点通过kubectl查看到,在集群kube-system命名空间中部署了nvidia-device-pluginpod:
# kubectl get pods -n kube-system | grep nvidia
nvidia-device-plugin-daemonset-frdh2 1/1 Running 0 64s
通过查看节点信息可以看到GPU资源和使用情况:
# kubectl describe nodes <nodeIP>
显示信息如下:
Capacity:
cpu: 8
ephemeral-storage: 154685884Ki
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 32779608Ki
nvidia.com/gpu: 1
pods: 256
Allocatable:
cpu: 7800m
ephemeral-storage: 142558510459
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 31653208Ki
nvidia.com/gpu: 1
pods: 256
创建使用vGPU的工作负载
通过控制台创建方式参考vGPU的创建步骤
通过命令行创建
通过如下YAML创建使用1个GPU的工作负载:
apiVersion: v1
kind: Pod
metadata:
name: gpu-operator-test
spec:
restartPolicy: OnFailure
containers:
- name: cuda-vector-add
image: "tkestack/cuda-vector-add:v0.1"
resources:
limits:
nvidia.com/gpu: 1
# kubectl create -f pod.yaml
pod/gpu-operator-test created
查看pod的状态和log:
# kubectl get pods
NAME READY STATUS RESTARTS AGE
gpu-operator-test 0/1 Completed 0 4m51s
# kubectl logs gpu-operator-test
[Vector addition of 50000 elements]
Copy input data from the host memory to the CUDA device
CUDA kernel launch with 196 blocks of 256 threads
Copy output data from the CUDA device to the host memory
Test PASSED
Done
通过再次查看节点信息可以看到GPU已经被分配使用:
kubectl describe nodes <nodeIP>
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 1137m (14%) 282m (3%)
memory 644Mi (2%) 1000Mi (3%)
ephemeral-storage 0 (0%) 0 (0%)
hugepages-1Gi 0 (0%) 0 (0%)
hugepages-2Mi 0 (0%) 0 (0%)
nvidia.com/gpu 1 1
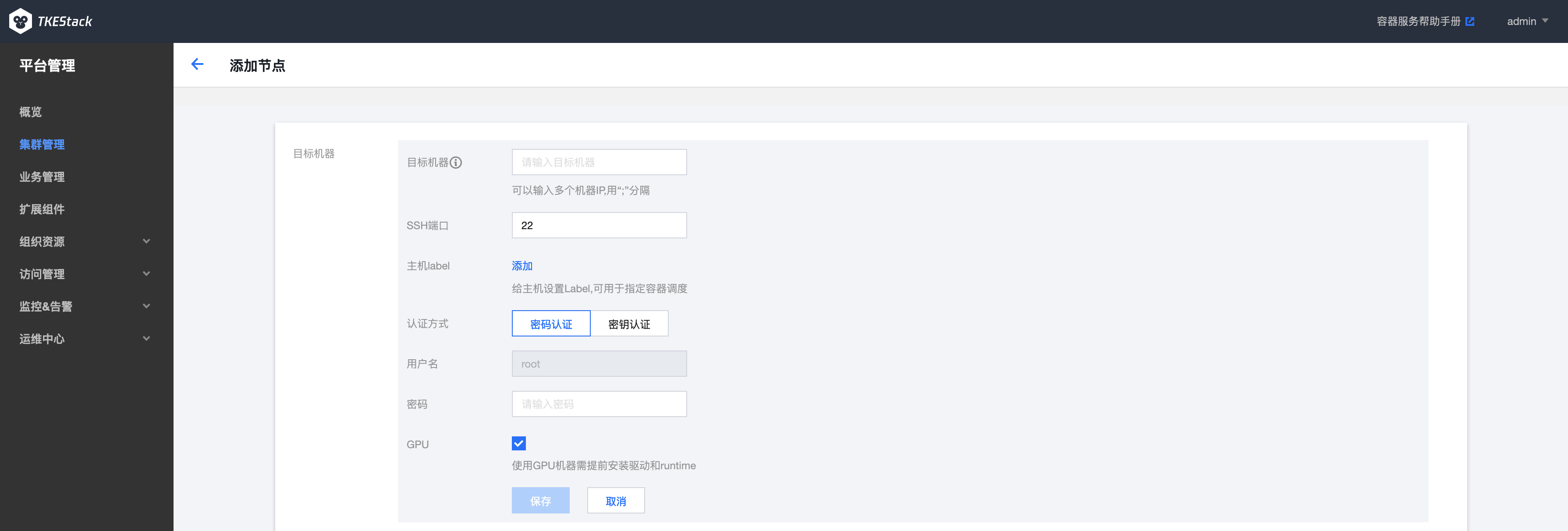
添加节点使用GPU
在添加节点上使用GPU资源,需要在创建添加节点时勾选GPU选项,如下图所示:
5 - 安装步骤
安装步骤
安装步骤
1. 需求检查
仔细检查每个节点的硬件和软件需求:installation requirements
2. Installer安装
为了简化平台安装过程,容器服务开源版基于 tke-installer 安装器提供了一个向导式的图形化安装指引界面。
在您 Installer 节点的终端,执行如下脚本:
# amd64
arch=amd64 version=v1.3.1 && wget https://tke-release-1251707795.cos.ap-guangzhou.myqcloud.com/tke-installer-linux-$arch-$version.run{,.sha256} && sha256sum --check --status tke-installer-linux-$arch-$version.run.sha256 && chmod +x tke-installer-linux-$arch-$version.run && ./tke-installer-linux-$arch-$version.run
# arm64
arch=arm64 version=v1.3.1 && wget https://tke-release-1251707795.cos.ap-guangzhou.myqcloud.com/tke-installer-linux-$arch-$version.run{,.sha256} && sha256sum --check --status tke-installer-linux-$arch-$version.run.sha256 && chmod +x tke-installer-linux-$arch-$version.run && ./tke-installer-linux-$arch-$version.run
您可以查看 TKEStack Release 按需选择版本进行安装,建议您安装最新版本。
tke-installer 约为 7GB,包含安装所需的所有资源。
以上脚本执行完之后,终端会提示访问 http://[tke-installer-IP]:8080/index.html,使用本地主机的浏览器访问该地址,按照指引开始安装控制台,可参考下面的控制台安装。
注意:这里
tke-installer-IP地址默认为内网地址,如果本地主机不在集群内网,tke-installer-IP为内网地址所对应的外网地址。
3. 控制台安装
注意:控制台是运行在global集群之上,控制台安装就是在安装global集群。
- 填写 TKEStack 控制台基本配置信息
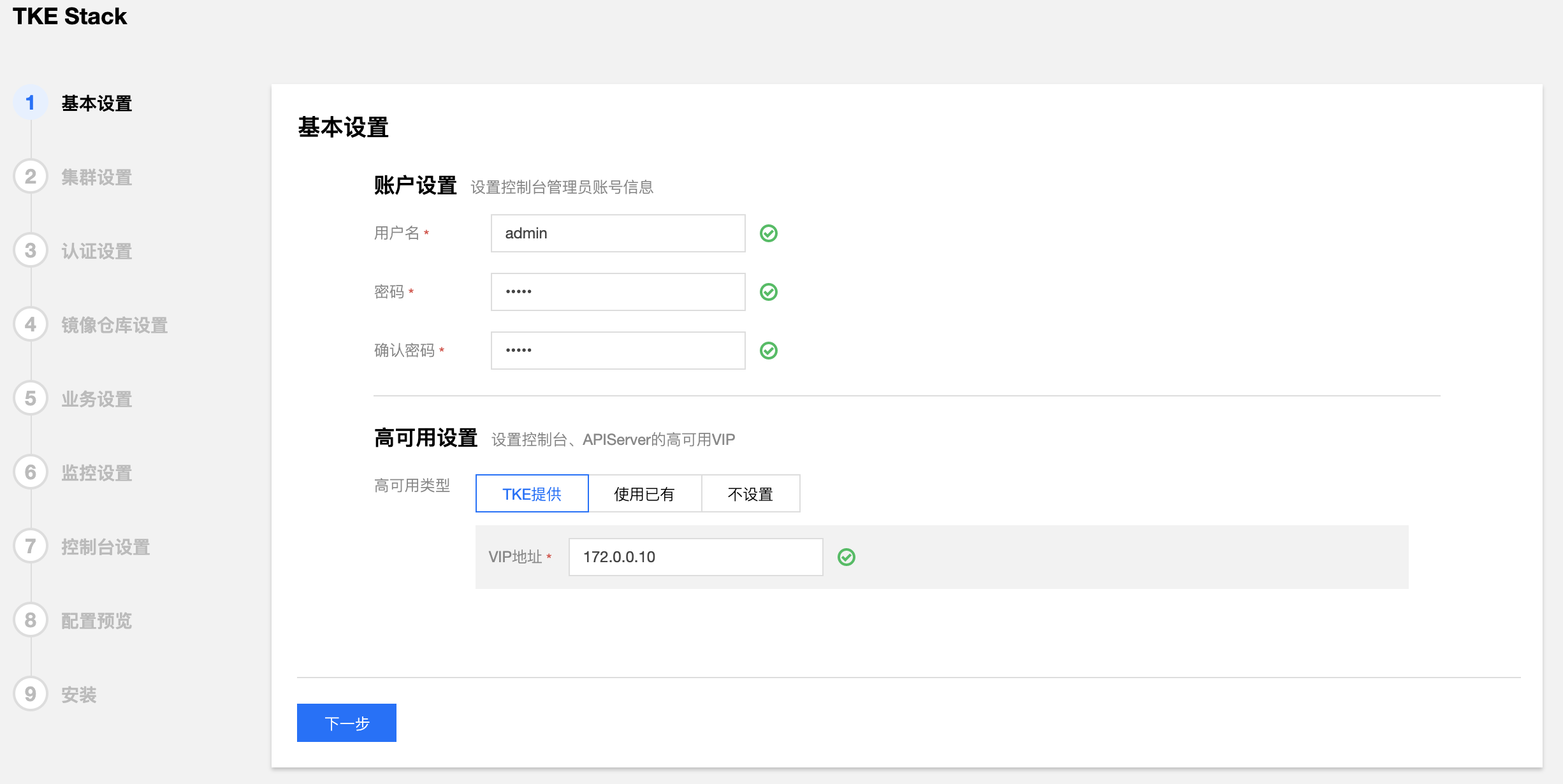
- 用户名:TKEStack 控制台管理员名称(例如:admin)
- 密码:TKEStack 控制台管理员密码
- 高可用设置(按需使用,可直接选择【不设置】)
- TKE提供:在所有 master 节点额外安装 Keepalived 完成 VIP 的配置与连接
- 使用已有:对接配置好的外部 LB 实例
- 不设置:访问第一台 master 节点 APIServer
- 填写 TKEStack 控制台集群设置信息
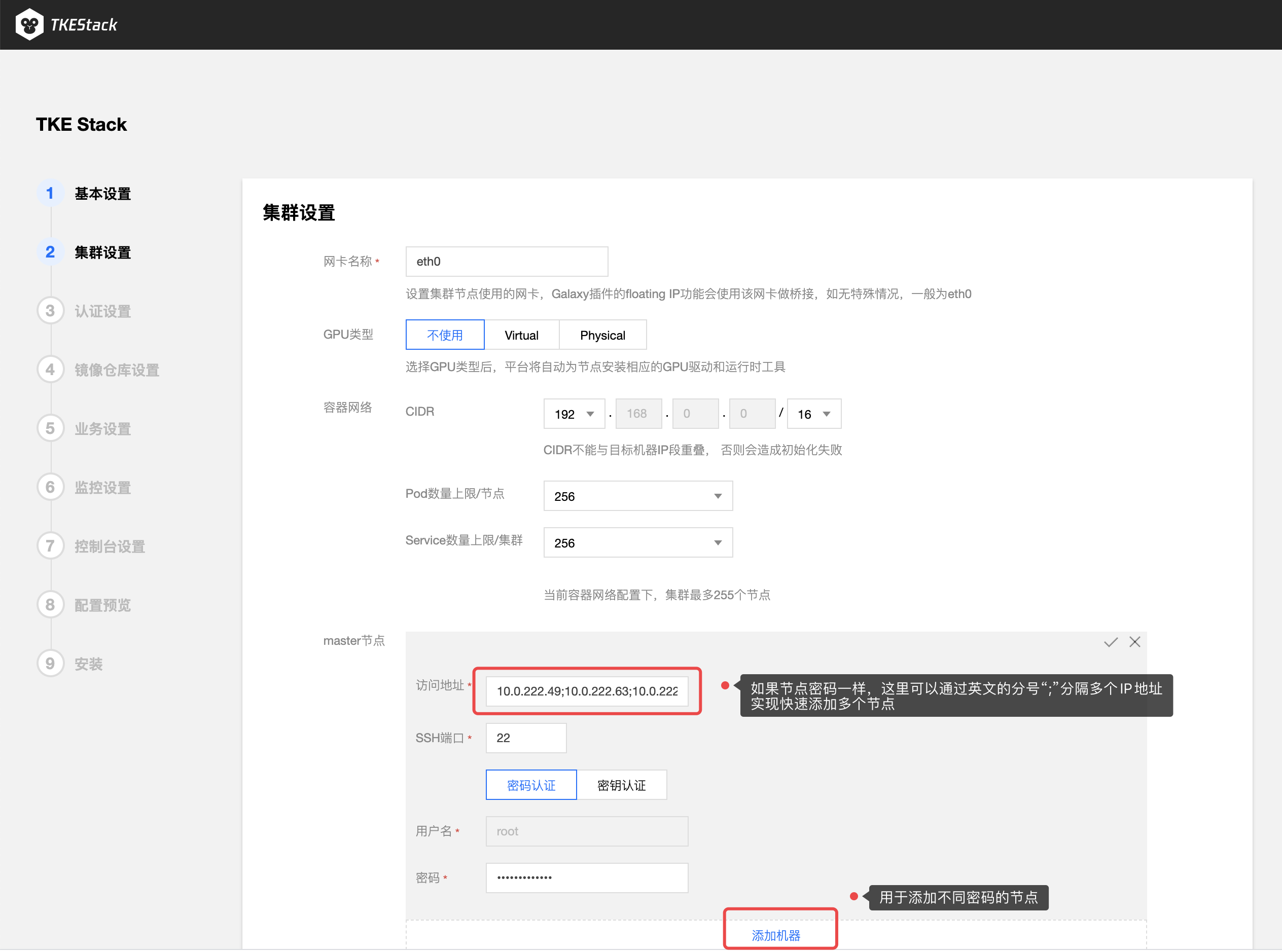
- 网卡名称:集群节点使用的网卡,根据实际环境填写正确的网卡名称,默认为eth0(建议使用默认值)
- GPU 类型:(按需使用,可直接选择【不设置】)
- 不使用:不安装 Nvidia GPU 相关驱动
- Virtual:平台会自动为集群安装 GPUManager 扩展组件
- Physical:平台会自动为集群安装 Nvidia-k8s-device-plugin
- 容器网络: 将为集群内容器分配在容器网络地址范围内的 IP 地址,您可以自定义三大私有网段作为容器网络, 根据您选择的集群内服务数量的上限,自动分配适当大小的 CIDR 段用于 Kubernetes service;根据您选择 Pod 数量上限/节点,自动为集群内每台服务器分配一个适当大小的网段用于该主机分配 Pod 的 IP 地址(建议使用默认值)
- CIDR: 集群内 Sevice、 Pod 等资源所在网段
- Pod数量上限/节点: 决定分配给每个 Node 的 CIDR 的大小
- Service数量上限/集群:决定分配给 Sevice 的 CIDR 大小
- master 节点: 输入目标机器信息后单击保存,若保存按钮是灰色,单击网页空白处即可变蓝
- 访问地址: Master 节点内网 IP,请配置至少 8 Cores & 16G内存 及以上的机型,否则会部署失败
- SSH 端口:请确保目标机器安全组开放 SSH 端口和 ICMP 协议,否则无法远程登录和 PING 服务器(建议使用22)
- 用户名和密码: 均为添加的节点的用户名和密码
- 可以通过节点下面的【添加机器】蓝色字体增加master节点(按需添加)
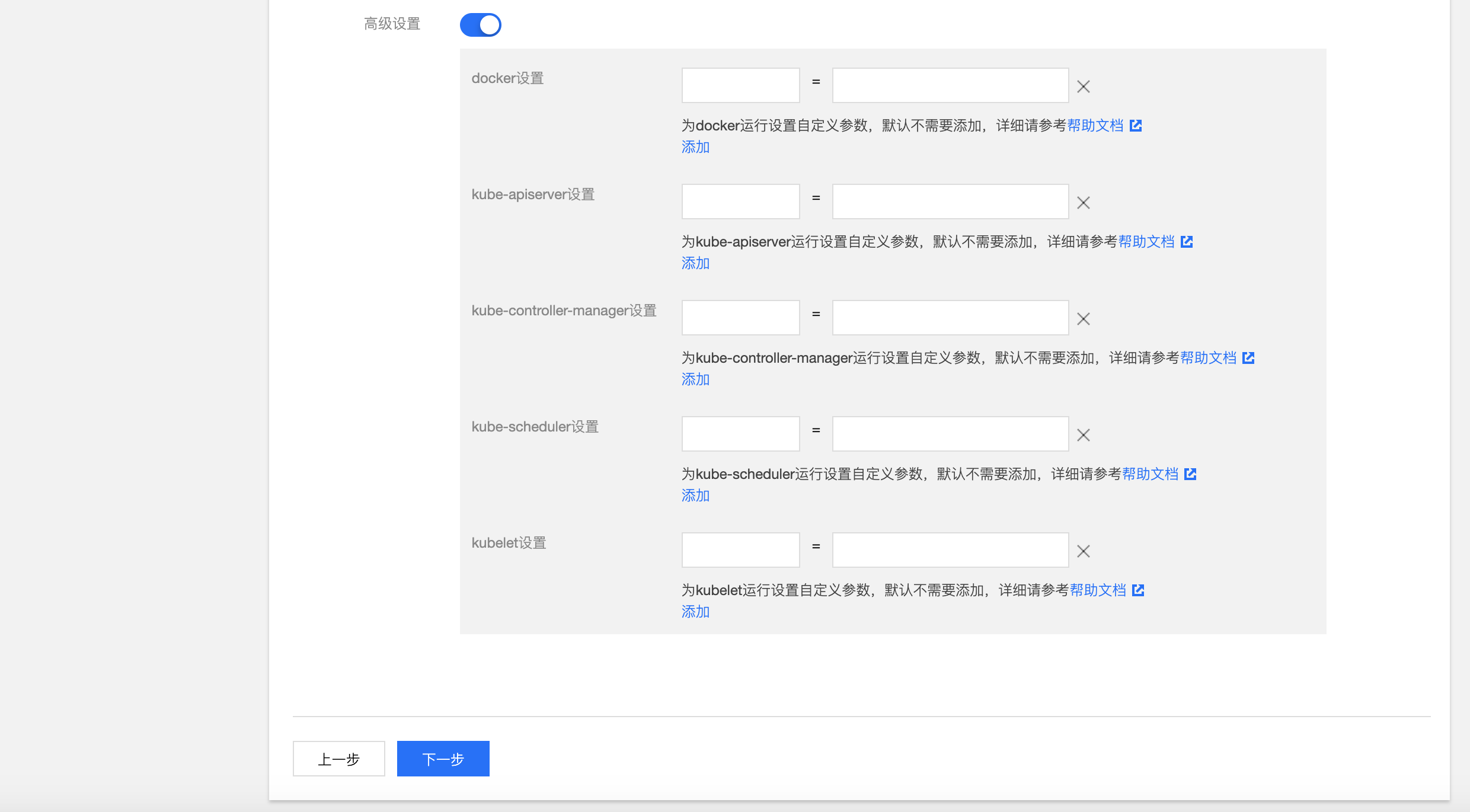
- 高级设置(非必须):可以自定义 Global 集群的 Docker、kube-apiserver、kube-controller-manager、kube-scheduler、kubelet 运行参数
- 填写 TKEStack 控制台认证信息。(建议使用TKE提供)
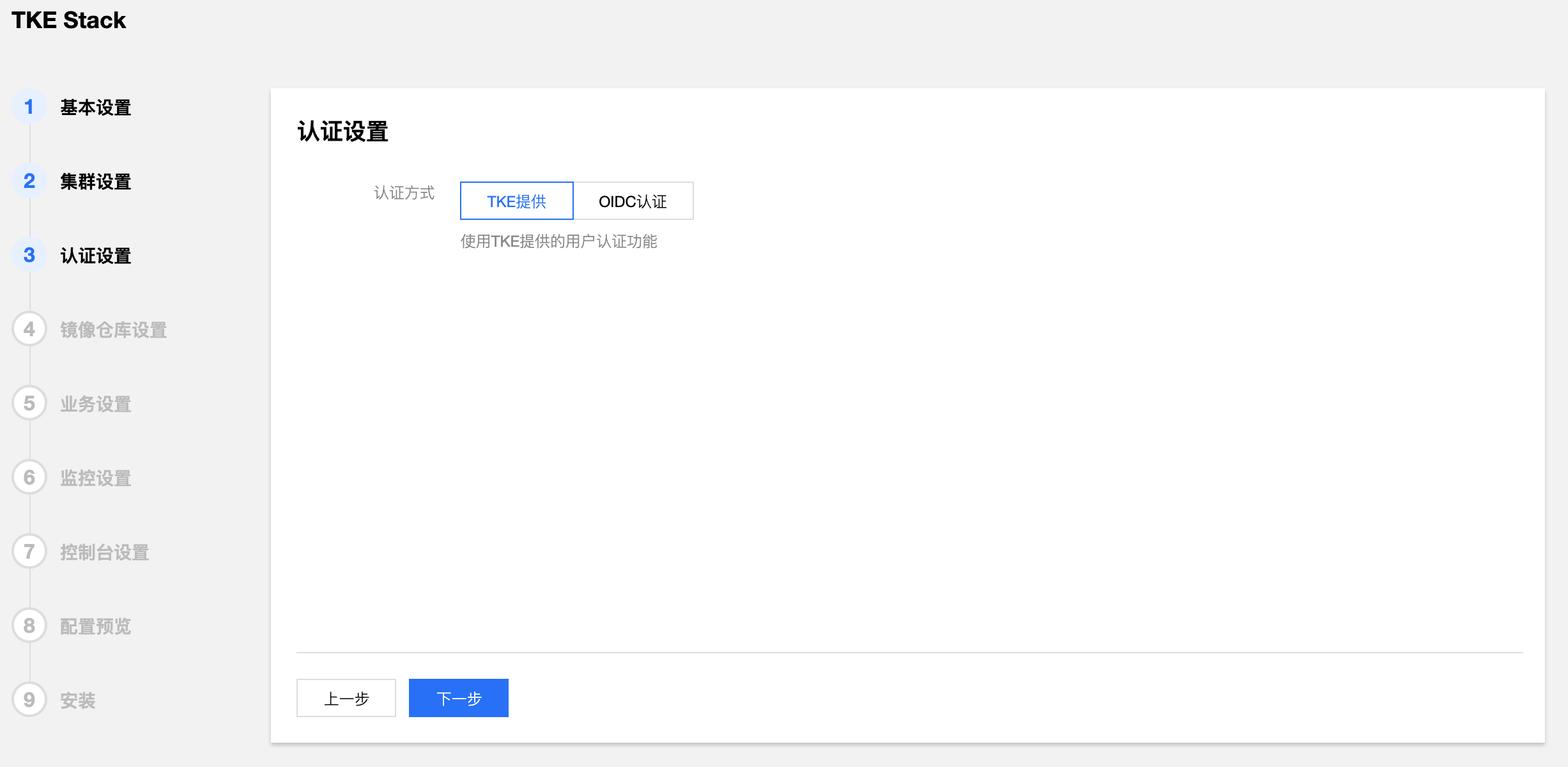
- 认证方式:
- TKE提供:使用 TKE 自带的认证方式
- OIDC:使用 OIDC 认证方式,详见 OIDC
- 填写 TKEStack 控制台镜像仓库信息。(建议使用TKE提供)
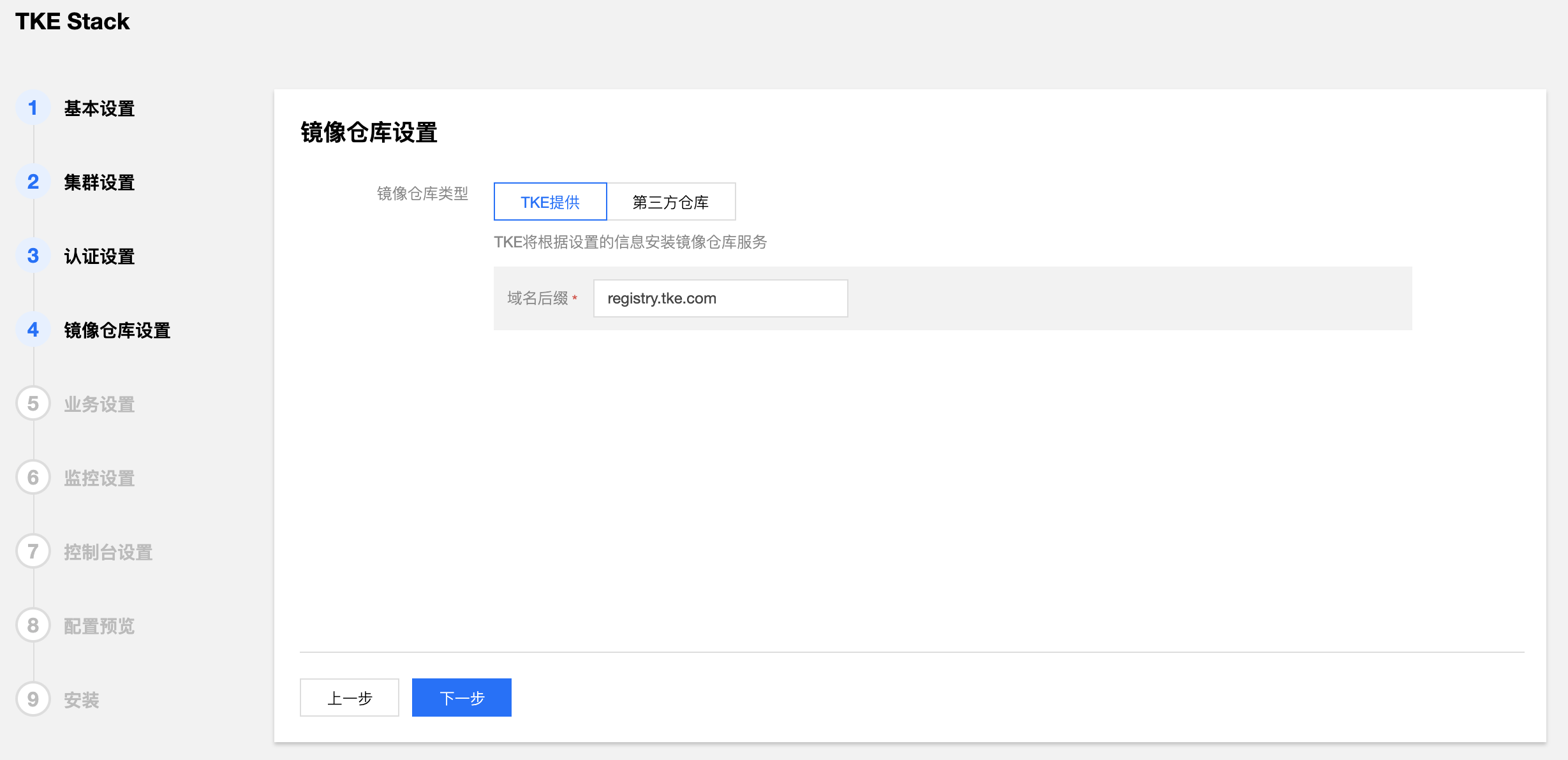
- 镜像仓库类型:
- TKE提供:使用 TKE 自带的镜像仓库
- 第三方仓库:对接配置好的外部镜像仓库,此时,TKEStack 将不会再安装镜像仓库,而是使用您提供的镜像仓库作为默认镜像仓库服务
- 业务设置
- 确认是否开启 TKEStack 控制台业务模块。(建议开启)
- 确实是否开启平台审计功能,审计模块为平台提供了操作记录,用户可以在平台管理进行查询,需用用户提供ES资源。(按需使用,可不开启)
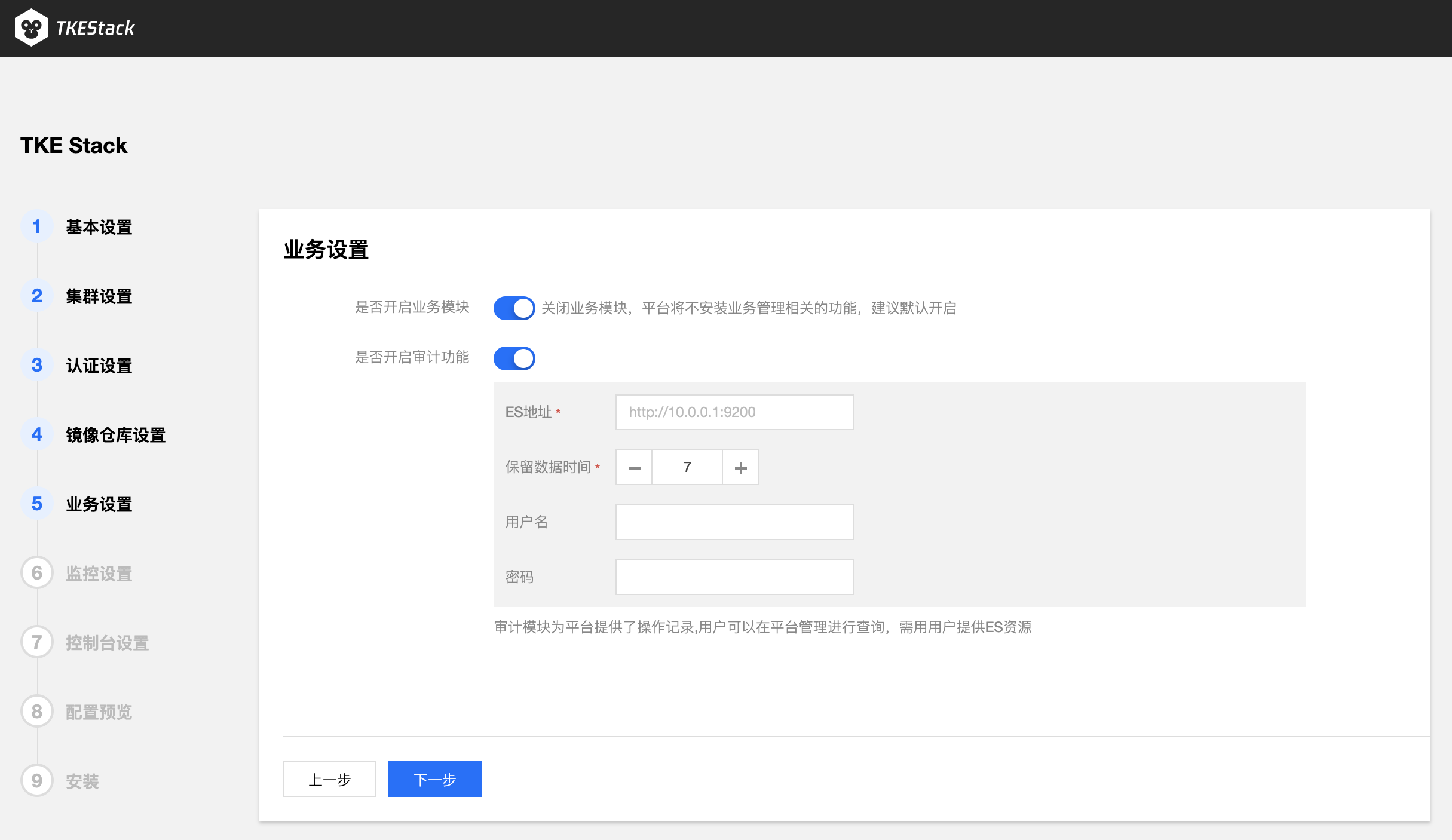
- 选择 TKEStack 控制台监控存储类型。(建议使用TKE提供)
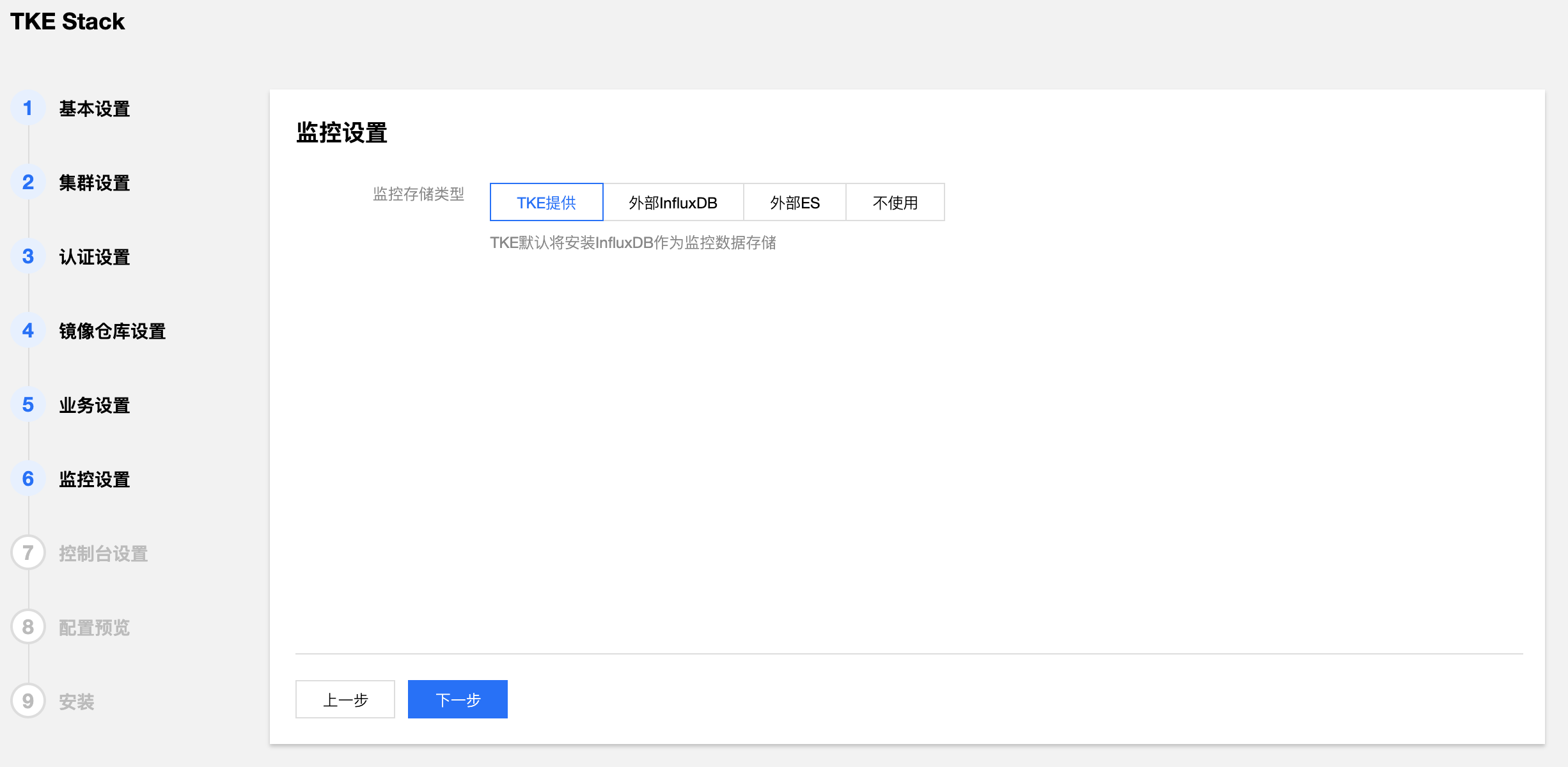
- 监控存储类型:
- TKE提供:使用 TKE 自带的 Influxdb 作为存储
- 外部 Influxdb:对接外部的 Influxdb 作为存储
- 外部 ES:对接外部的 Elasticsearch作为存储
- 不使用:不使用监控
- 确认是否开启 TKEStack 控制台,选择开启则需要填写控制台域名及证书。(建议使用默认值)
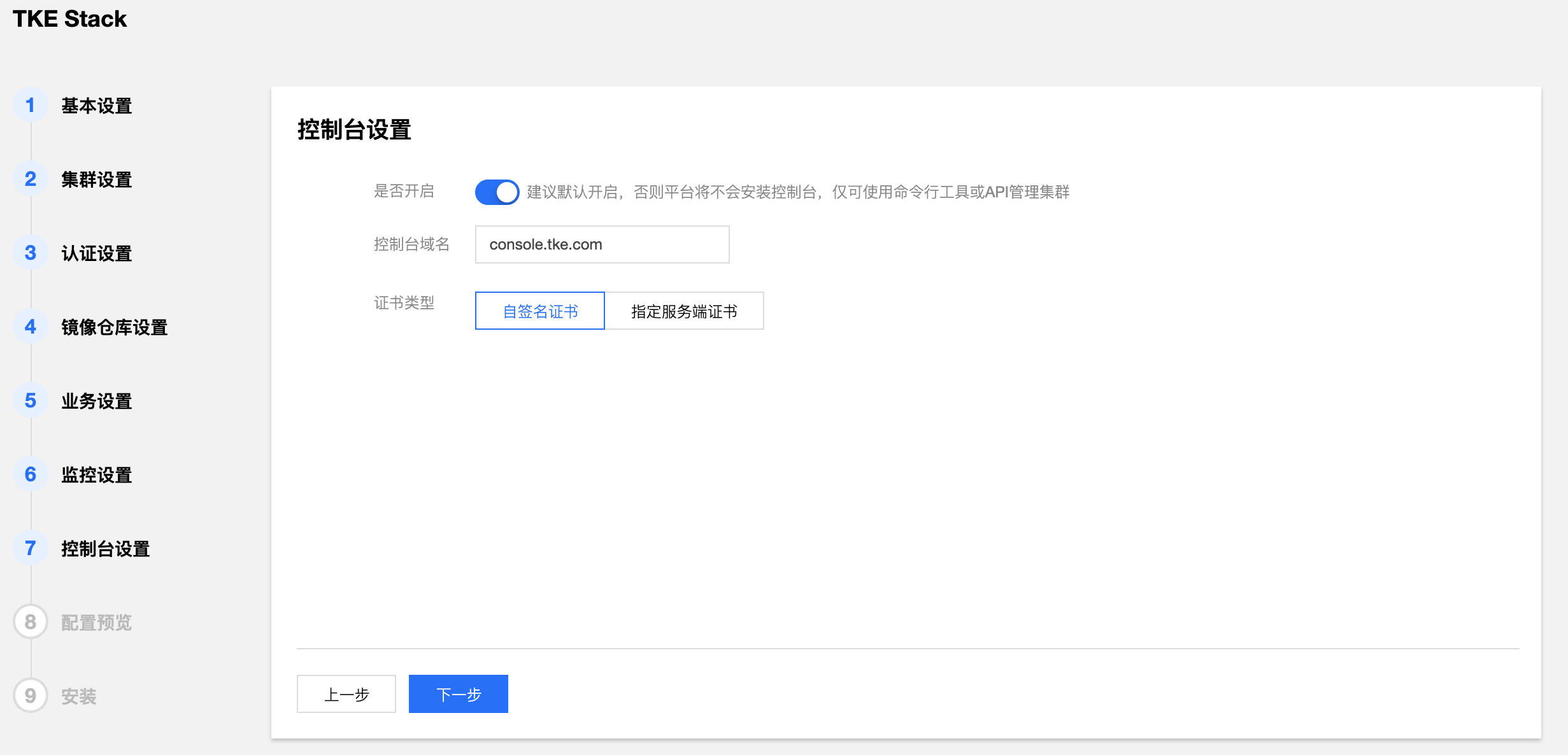
- 监控存储类型:
- 自签名证书:使用 TKE 带有的自签名证书
- 指定服务器证书:填写已备案域名的服务器证书
- 确认 TKEStack 控制台所有配置是否正确。
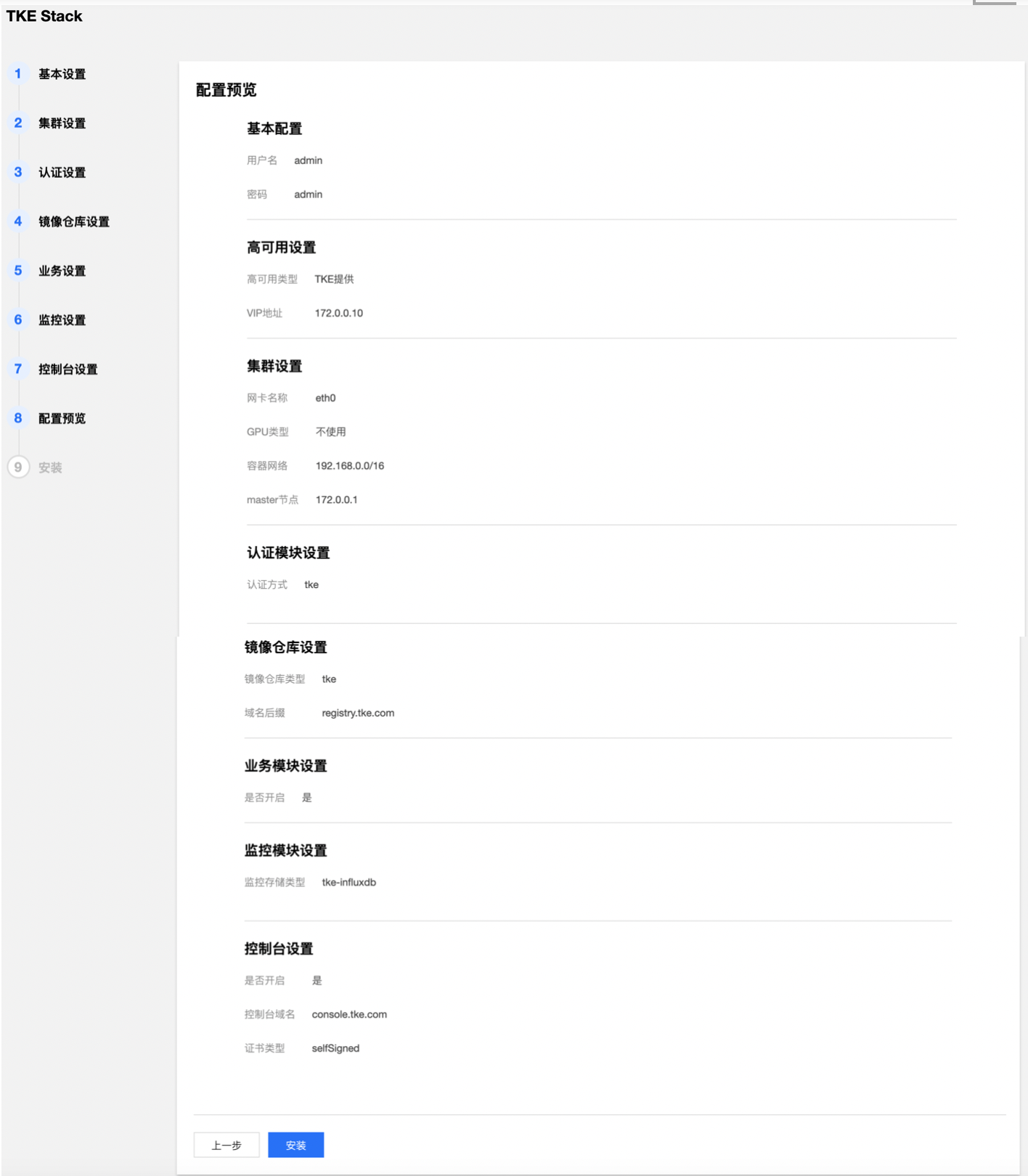
- 开始安装 TKEStack 控制台,安装成功后界面如下,最下面出现【查看指引】的按钮。
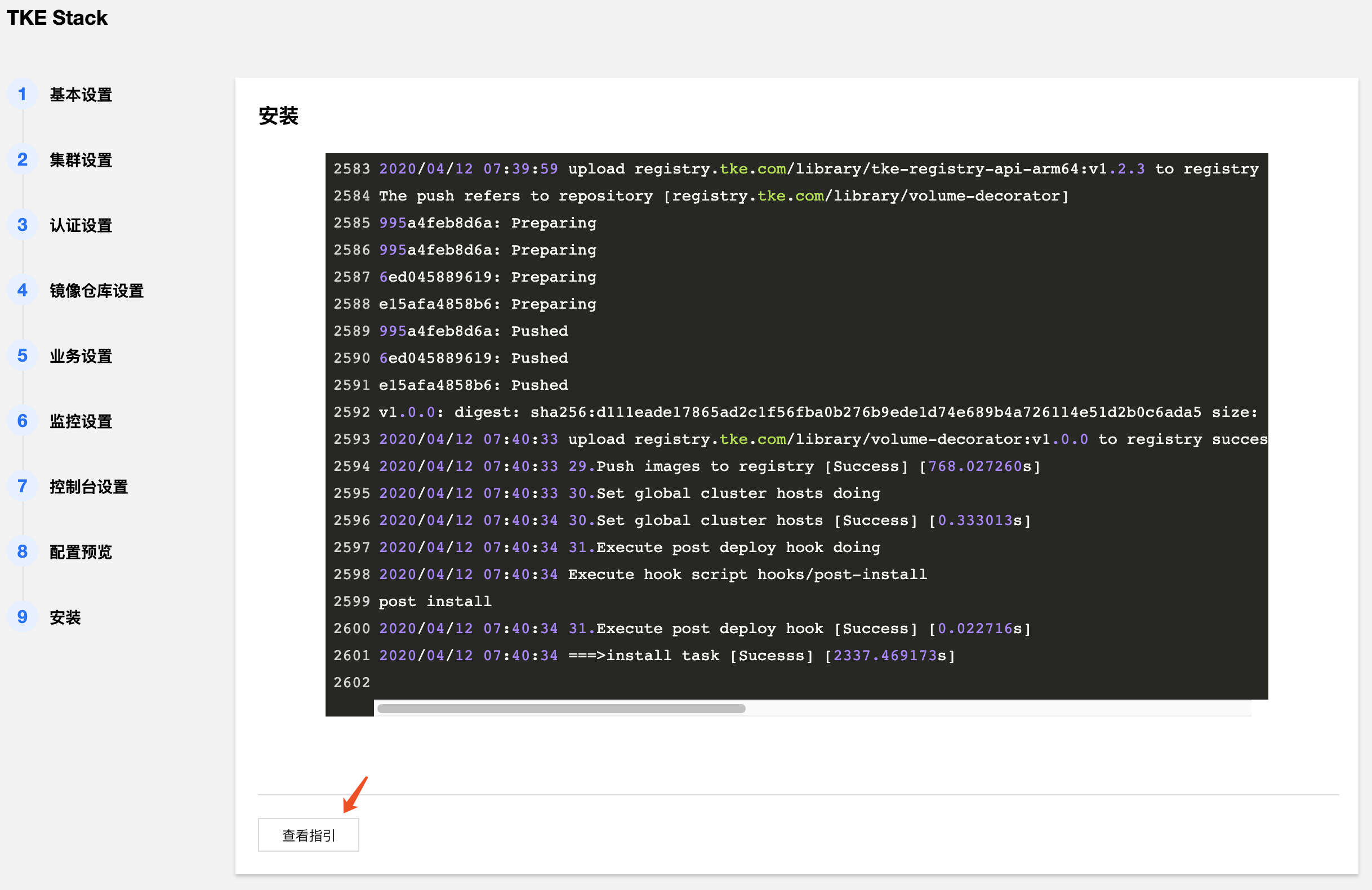
- 点击【查看指引】,按照指引,在本地主机上添加域名解析,以访问 TKEStack 控制台。
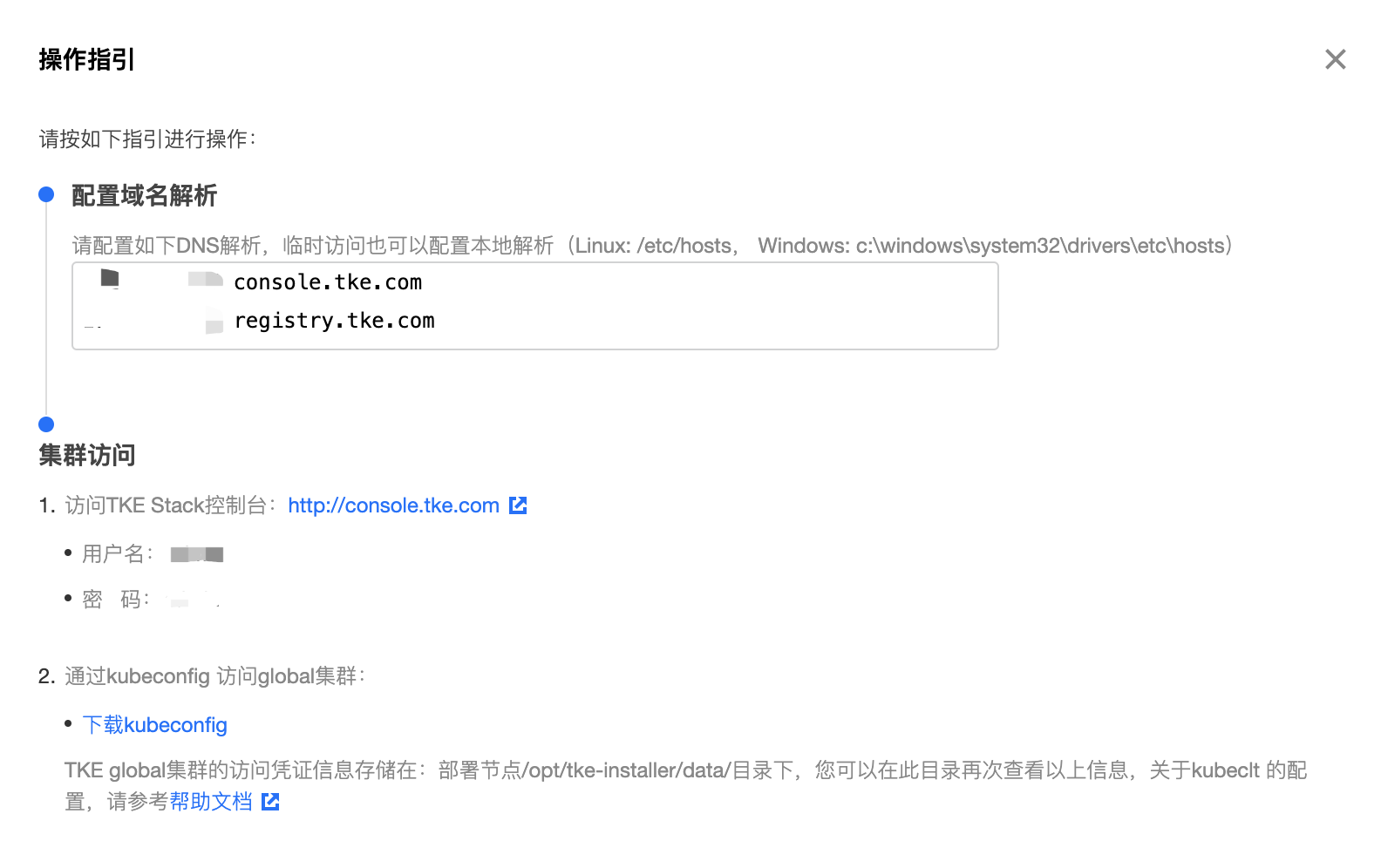
以Linux/MacOS为例: 在
/etc/hosts文件中加入以下两行域名解析- 【IP】 console.tke.com
- 【IP】 registry.tke.com
注意:这里域名的【IP】地址默认为内网地址,如果本地主机不在集群内网,域名的IP地址应该填该内网地址所对应的外网地址。
4. 访问控制台
在本地主机的浏览器地址输入http://console.tke.com,可访问Global集群的控制台界面,输入控制台安装创建的用户名和密码后即可使用TKEStack。
安装常见问题
安装失败请首先检查硬件和软件需求:installation requirements
可参考FAQ installation获得更多帮助。
6 -
readme
Because we can not find resources online with static folder,so use this folder to store image.
If we fix this issue in the future, then we use static folder rather than this folder.