1 - TAPP
Kubernetes现有应用类型(如:Deployment、StatefulSet等)无法满足很多非微服务应用的需求,比如:操作(升级、停止等)应用中的指定pod、应用支持多版本的pod。如果要将这些应用改造为适合于这些workload的应用,需要花费很大精力,这将使大多数用户望而却步。
为解决上述复杂应用管理场景,基于Kubernetes CRD开发了一种新的应用类型TAPP,它是一种通用类型的workload,同时支持service和batch类型作业,满足绝大部分应用场景,它能让用户更好的将应用迁移到Kubernetes集群。

TAPP 特点
| 功能点 | Deployment | StatefulSet | TAPP |
|---|---|---|---|
| Pod唯一性 | 无 | 每个Pod有唯一标识 | 每个Pod有唯一标识 |
| Pod存储独占 | 仅支持单容器 | 支持 | 支持 |
| 存储随Pod迁移 | 不支持 | 支持 | 支持 |
| 自动扩缩容 | 支持 | 不支持 | 支持 |
| 批量升级 | 支持 | 不支持 | 支持 |
| 严格顺序更新 | 不支持 | 支持 | 不支持 |
| 自动迁移问题节点 | 支持 | 不支持 | 支持 |
| 多版本管理 | 同时只有1个版本 | 可保持2个版本 | 可保持多个版本 |
| Pod原地升级 | 不支持 | 不支持 | 支持 |
如果用Kubernetes的应用类型类比,TAPP ≈ Deployment + StatefulSet + Job ,它包含了Deployment、StatefulSet、Job的绝大部分功能,同时也有自己的特性,并且和原生Kubernetes相同的使用方式完全一致。
实例具有可以标识的id
实例有了id,业务就可以将很多状态或者配置逻辑和该id做关联,当容器迁移时,通过TAPP的容器实例标识,可以识别该容器原来对应的数据,实现带云硬盘或者数据目录迁移
每个实例可以绑定自己的存储
通过TAPP的容器实例标识,能很好地支持有状态的作业。在实例发生跨机迁移时,云硬盘能跟随实例一起迁移
实现真正的灰度升级/回退
Kubernetes中的灰度升级概念应为滚动升级,kubernetes将pod”逐个”的更新,但现实中多业务需要的是稳定的灰度,即同一个app,需要有多个版本同时稳定长时间的存在,TAPP解决了此类问题
可以指定实例id做删除、停止、重启等操作
对于微服务app来说,由于没有固定id,因此无法对某个实例做操作,而是全部交给了系统去维持足够的实例数
对每个实例都有生命周期的跟踪
对于一个实例,由于机器故障发生了迁移、重启等操作,很难跟踪和监控其生命周期。通过TAPP的容器实例标识,获得了实例真正的生命周期的跟踪,对于判断业务和系统是否正常服务具有特别重要的意义。TAPP还可以记录事件,以及各个实例的运行时间,状态,高可用设置等。
TAPP 资源结构
TApp定义了一种用户自定义资源(CRD),TAPP controller是TAPP对应的controller/operator,它通过kube-apiserver监听TApp、Pod相关的事件,根据TApp spec和status进行相应的操作:创建、删除pod等。
// TApp represents a set of pods with consistent identities.
type TApp struct {
metav1.TypeMeta `json:",inline"`
metav1.ObjectMeta `json:"metadata,omitempty"`
// Spec defines the desired identities of pods in this tapp.
Spec TAppSpec `json:"spec,omitempty"`
// Status is the current status of pods in this TApp. This data
// may be out of date by some window of time.
Status TAppStatus `json:"status,omitempty"`
}
// A TAppSpec is the specification of a TApp.
type TAppSpec struct {
// Replicas 指定Template的副本数,尽管共享同一个Template定义,但是每个副本仍有唯一的标识
Replicas int32 `json:"replicas,omitempty"`
// 同Deployment的定义,标签选择器,默认为Pod Template上的标签
Selector *metav1.LabelSelector `json:"selector,omitempty"`
// Template 默认模板,描述将要被初始创建/默认缩放的pod的对象,在TApp中可以被添加到TemplatePool中
Template corev1.PodTemplateSpec `json:"template"`
// TemplatePool 描述不同版本的pod template, template name --> pod Template
TemplatePool map[string]corev1.PodTemplateSpec `json:"templatePool,omitempty"`
// Statuses 用来指定对应pod实例的目标状态,instanceID --> desiredStatus ["Running","Killed"]
Statuses map[string]InstanceStatus `json:"statuses,omitempty"`
// Templates 用来指定运行pod实例所使用的Template,instanceID --> template name
Templates map[string]string `json:"templates,omitempty"`
// UpdateStrategy 定义滚动更新策略
UpdateStrategy TAppUpdateStrategy `json:"updateStrategy,omitempty"`
// ForceDeletePod 定义是否强制删除pod,默认为false
ForceDeletePod bool `json:"forceDeletePod,omitempty"`
// 同Statefulset的定义
VolumeClaimTemplates []corev1.PersistentVolumeClaim `json:"volumeClaimTemplates,omitempty"`
}
// 滚动更新策略
type TAppUpdateStrategy struct {
// 滚动更新的template name
Template string `json:"template,omitempty"`
// 滚动更新时的最大不可用数, 如果不指定此配置,滚动更新时不限制最大不可用数
MaxUnavailable *int32 `json:"maxUnavailable,omitempty"`
}
// 定义TApp的状态
type TAppStatus struct {
// most recent generation observed by controller.
ObservedGeneration int64 `json:"observedGeneration,omitempty"`
// Replicas 描述副本数
Replicas int32 `json:"replicas"`
// ReadyReplicas 描述Ready副本数
ReadyReplicas int32 `json:"readyReplicas"`
// ScaleSelector 是用于对pod进行查询的标签,它与HPA使用的副本计数匹配
ScaleLabelSelector string `json:"scaleLabelSelector,omitempty"`
// AppStatus 描述当前Tapp运行状态, 包含"Pending","Running","Failed","Succ","Killed"
AppStatus AppStatus `json:"appStatus,omitempty"`
// Statues 描述实例的运行状态 instanceID --> InstanceStatus ["NotCreated","Pending","Running","Updating","PodFailed","PodSucc","Killing","Killed","Failed","Succ","Unknown"]
Statuses map[string]InstanceStatus `json:"statuses,omitempty"`
}
使用示例
本节以一个TApp应用部署,配置,升级,扩容以及杀死删除的操作步骤来说明TApp的使用。
创建TApp应用
创建TApp应用,副本数为3,TApp-controller将根据默认模板创建出的pod
$ cat tapp.yaml
apiVersion: apps.tkestack.io/v1
kind: TApp
metadata:
name: example-tapp
spec:
replicas: 3
template:
metadata:
labels:
app: example-tapp
spec:
containers:
- name: nginx
image: nginx:1.7.9
$ kubect apply -f tapp.yaml
查看TApp应用
$ kubectl get tapp XXX
NAME AGE
example-tapp 20m
$ kubectl descirbe tapp example-tapp
Name: example-tapp
Namespace: default
Labels: app=example-tapp
Annotations: <none>
API Version: apps.tkestack.io/v1
Kind: TApp
...
Spec:
...
Status:
App Status: Running
Observed Generation: 2
Ready Replicas: 3
Replicas: 3
Scale Label Selector: app=example-tapp
Statuses:
0: Running
1: Running
2: Running
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulCreate 12m tapp-controller Instance: example-tapp-1
Normal SuccessfulCreate 12m tapp-controller Instance: example-tapp-0
Normal SuccessfulCreate 12m tapp-controller Instance: example-tapp-2
升级TApp应用
当前3个pod实例运行的镜像版本为nginx:1.7.9,现在要升级其中的一个pod实例的镜像版本为nginx:latest,在spec.templatPools中创建模板,然后在spec.templates中指定模板pod, 指定“1”:“test”表示使用模板test创建pod 1。
如果只更新镜像,Tapp controller将对pod进行原地升级,即仅更新重启对应的容器,否则将按k8s原生方式删除pod并重新创建它们。
apiVersion: apps.tkestack.io/v1
kind: TApp
metadata:
name: example-tapp
spec:
replicas: 3
template:
metadata:
labels:
app: example-tapp
spec:
containers:
- name: nginx
image: nginx:1.7.9
templatePool:
"test":
metadata:
labels:
app: example-tapp
spec:
containers:
- name: nginx
image: nginx:latest
templates:
"1": "test"
操作成功后,查看instanceID为'1’的pod已升级,镜像版本为nginx:latest
# kubectl describe tapp example-tapp
Name: example-tapp
Namespace: default
Labels: app=example-tapp
Annotations: kubectl.kubernetes.io/last-applied-configuration:
{"apiVersion":"apps.tkestack.io/v1","kind":"TApp","metadata":{"annotations":{},"name":"example-tapp","namespace":"default"},"spec":{"repli...
API Version: apps.tkestack.io/v1
Kind: TApp
...
Spec:
...
Templates:
1: test
Update Strategy:
Status:
App Status: Running
Observed Generation: 4
Ready Replicas: 3
Replicas: 3
Scale Label Selector: app=example-tapp
Statuses:
0: Running
1: Running
2: Running
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulCreate 25m tapp-controller Instance: example-tapp-1
Normal SuccessfulCreate 25m tapp-controller Instance: example-tapp-0
Normal SuccessfulCreate 25m tapp-controller Instance: example-tapp-2
Normal SuccessfulUpdate 10m tapp-controller Instance: example-tapp-1
# kubectl get pod | grep example-tapp
example-tapp-0 1/1 Running 0 27m
example-tapp-1 1/1 Running 1 27m
example-tapp-2 1/1 Running 0 27m
# kubectl get pod example-tapp-1 -o template --template='{{range .spec.containers}}{{.image}}{{end}}'
nginx:latest
上述升级过程可根据实际需求灵活操作,可以指定多个pod的版本,帮助用户实现灵活的应用升级策略 同时可以指定updateStrategy升级策略,保证升级是最大不可用数为1,即保证滚动升级时每次仅更新和重启一个容器或pod
# cat tapp.yaml
apiVersion: apps.tkestack.io/v1
kind: TApp
metadata:
name: example-tapp
spec:
replicas: 3
template:
metadata:
labels:
app: example-tapp
spec:
containers:
- name: nginx
image: nginx:1.7.9
templatePool:
"test":
metadata:
labels:
app: example-tapp
spec:
containers:
- name: nginx
image: nginx:latest
templates:
"1": "test"
"2": "test"
"0": "test"
updateStrategy:
template: test
maxUnavailable: 1
# kubectl apply -f tapp.yaml
杀死指定pod
在spec.statuses中指定pod的状态,tapp-controller根据用户指定的状态控制pod实例,例如,如果spec.statuses为“1”:“killed”,tapp控制器会杀死pod 1。
# cat tapp.yaml
kind: TApp
metadata:
name: example-tapp
spec:
replicas: 3
template:
metadata:
labels:
app: example-tapp
spec:
containers:
- name: nginx
image: nginx:1.7.9
templatePool:
"test":
metadata:
labels:
app: example-tapp
spec:
containers:
- name: nginx
image: nginx:latest
templates:
"1": "test"
"2": "test"
"0": "test"
updateStrategy:
template: test
maxUnavailable: 1
statuses:
"1": "Killed"
# kubectl apply -f tapp.yaml
查看pod状态变为Terminating
# kubectl get pod
NAME READY STATUS RESTARTS AGE
example-tapp-0 1/1 Running 1 59m
example-tapp-1 0/1 Terminating 1 59m
example-tapp-2 1/1 Running 1 59m
扩容TApp应用
如果你想要扩展TApp使用默认的spec.template模板,只需增加spec.replicas的值,否则你需要在spec.templates中指定使用哪个模板。kubectl scale也适用于TApp。
kubectl scale --replicas=3 tapp/example-tapp
删除TApp应用
kubectl delete tapp example-tapp
其它
Tapp还支持其他功能,如HPA、volume templates,它们与k8s中的其它工作负载类型类似。
2 - Galaxy
Kubernetes没有提供默认可用的容器网络,但kubernetes网络的设计文档要求容器网络的实现能做到下面的三点:
- all containers can communicate with all other containers without NAT
- all nodes can communicate with all containers (and vice-versa) without NAT
- the IP that a container sees itself as is the same IP that others see it as
即集群包含的每一个容器都拥有一个与其他集群中的容器和节点可直接路由的独立IP地址。但是Kubernetes并没有具体实现这样一个网络模型,而是实现了一个开放的容器网络标准CNI,可以自由选择使用开源的网络方案或者实现一套遵循CNI标准的网络,为用户提供两种网络类型:
- Overlay Network,即通用的虚拟化网络模型,不依赖于宿主机底层网络架构,可以适应任何的应用场景,方便快速体验。但是性能较差,因为在原有网络的基础上叠加了一层Overlay网络,封包解包或者NAT对网络性能都是有一定损耗的。
- Underlay Network,即基于宿主机物理网络环境的模型,容器与现有网络可以直接互通,不需要经过封包解包或是NAT,其性能最好。但是其普适性较差,且受宿主机网络架构的制约,比如MAC地址可能不够用。
为满足复杂应用容器化的特殊需求,大幅拓展了容器应用的场景,TKEStack利用Galaxy网络组件提供多种解决方案,支持overlay和underlay网络类型,支持高转发性能和高隔离性等场景应用。
Galaxy是一个Kubernetes网络项目,旨在为POD提供通用Overlay和高性能的Underlay网络。
TKEStack使用Galaxy网络组件,支持四种网络模式,并且可以为工作负载单独配置指定的网络模式,拓展了容器应用场景,满足复杂应用容器化的特殊需求。
Overlay网络
TKEStack的默认网络模式,基于IPIP和host gateway的flannel方案,同节点容器通信不走网桥,报文直接利用主机路由转发;跨节点容器通信利用IPIP协议封装, etcd记录节点间路由。该方案控制层简单稳定,网络转发性能优异,并且可以通过network policy实现多种网络策略。
Floating IP
容器IP由宿主机网络提供,打通了容器网络与underlay网络,容器与物理机可以直接路由,性能更好。容器与宿主机的二层连通, 支持了Linux bridge/MacVlan/IPVlan和SRIOV, 根据业务场景和硬件环境,具体选择使用哪种网桥
NAT
基于k8s中的hostPort配置,并且如果用户没有指定Port地址,galaxy会给实例配置容器到主机的随机端口映射
Host
利用k8s中的hostNetwork配置,直接使用宿主机的网络环境,最大的好处是其性能优势,但是需要处理端口冲突问题,并且也有安全隐患。
Galaxy架构
Galaxy在架构上由三部分组成:
- Galaxy: 以DaemonSet方式运行在每个节点上,通过调用各种CNI插件来配置k8s容器网络
- CNI plugins: 符合CNI标准的二进制文件,用于网络资源的配置和管理, 支持CNI插件Supported CNI plugins
- Galaxy IPAM: 通过tkestack中的IPAM扩展组件安装,K8S调度插件,kube-scheduler通过HTTP调用Galaxy-ipam的filter/priority/bind方法实现Float IP的配置和管理
Galaxy Overlay 网络

tke-installer安装tkestack并自动配置galaxy为overlay网络模式,在该模式下:
Flannel在每个Kubelet上分配一个子网,并将其保存在etcd和本地磁盘上(/run/ Flannel /subnet.env)
Kubelet根据CNI配置启动SDN CNI进程
1.SDN CNI进程通过unix socket调用Galaxy,所有的args都来自Kubelet
Galaxy调用FlannelCNI来解析来自/run/flannel/subnet.env的子网信息
Flannel CNI调用Bridge CNI或Veth CNI来为POD配置网络
Galaxy Underlay 网络
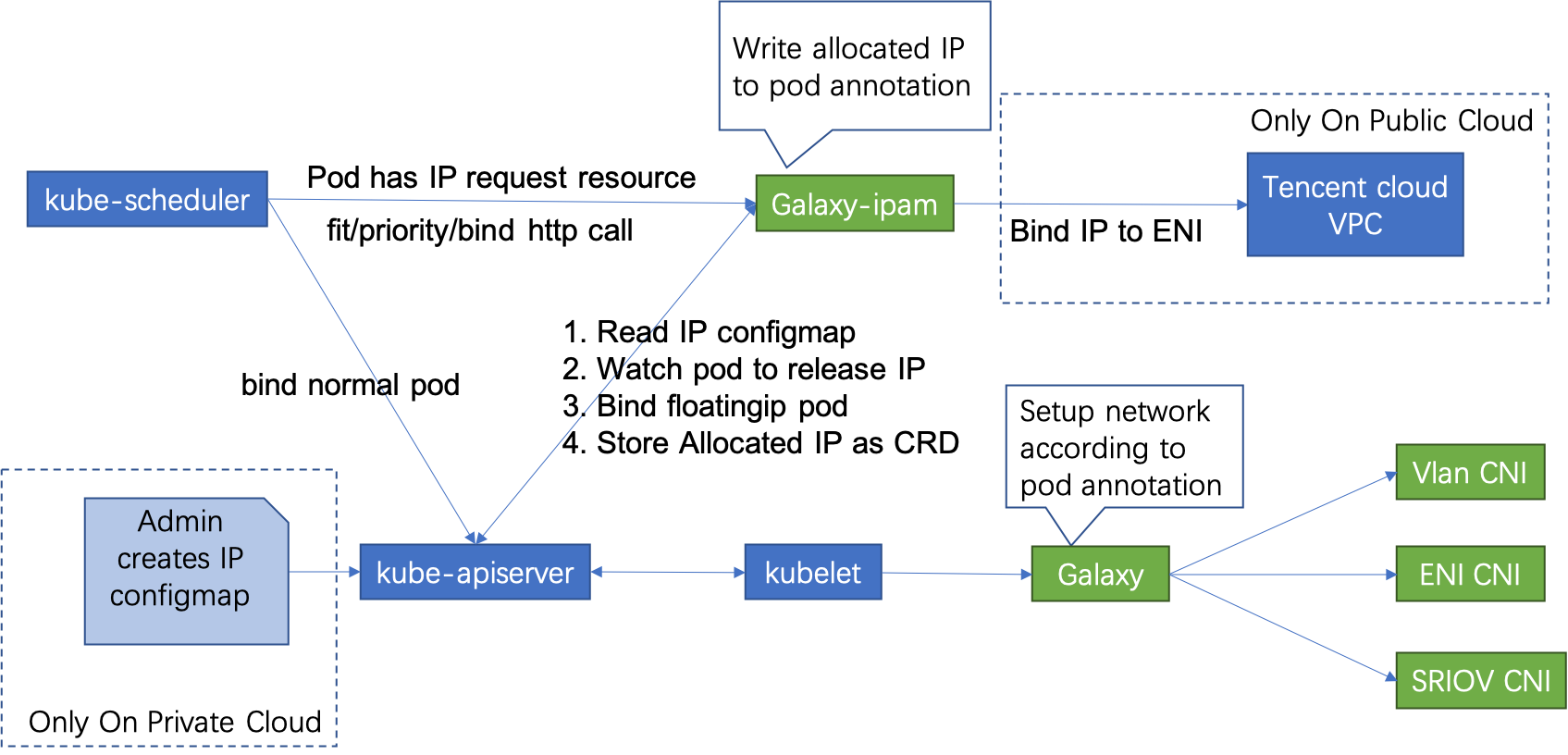
如需配置underlay网络,需要启用Galaxy-ipam组件,Galaxy-ipam根据配置为POD分配或释放IP:
- 规划容器网络使用的Underlay IP,配置floatingip-config ConfigMap
- Kubernetes调度器在filter/priority/bind方法上调用Galaxy-ipam
- Galaxy-ipam检查POD是否配置了reserved IP,如果是,则Galaxy-ipam仅将此IP所在的可用子网的节点标记为有效节点,否则所有都将被标记为有效节点。在POD绑定IP期间,Galaxy-ipam分配一个IP并将其写入到POD annotations中
- Galaxy从POD annotations获得IP,并将其作为参数传递给CNI,通过CNI配置POD IP
Galaxy配置
常见问题
为pod配置float ip网络模式失败 1. 检查ipam扩展组件是否已正确安装 1. 检查kube-scheduler是否正确配置scheduler-policy 1. 检查floatingip-config ConfigMap是否配置正确 1. 检查创建的Deployment工作负载: 1. 容器限额中配置 tke.cloud.tencent.com/eni-ip:1 1. 容器annotation中配置 k8s.v1.cni.cncf.io/networks=galaxy-k8s-vlan
如果上述配置都正确,pod会被成功创建并运行,galaxy-ipam会自动为pod分配指定的Float IP
为pod配置float ip网络模式后,如何与其他pod和主机通信
Galaxy为pod配置float ip网络模式,pod的nic和ip由宿主机网络提供,此pod的就加入了underlay的网络,因此pod间的通信以及pod与主机的通信就需要网络管理员在相应的交换机和路由器上配置对应的路由。
参考配置
本节展示了在一个正确配置了float-ip的deployment工作负载。
查看kube-scheduler的policy配置文件是否配置正确
# cat /etc/kubernetes/scheduler-policy-config.json
{
"apiVersion" : "v1",
"extenders" : [
{
"apiVersion" : "v1beta1",
"enableHttps" : false,
"filterVerb" : "predicates",
"managedResources" : [
{
"ignoredByScheduler" : false,
"name" : "tencent.com/vcuda-core"
}
],
"nodeCacheCapable" : false,
"urlPrefix" : "http://gpu-quota-admission:3456/scheduler"
},
{
"urlPrefix": "http://127.0.0.1:32760/v1",
"httpTimeout": 10000000000,
"filterVerb": "filter",
"prioritizeVerb": "prioritize",
"BindVerb": "bind",
"weight": 1,
"enableHttps": false,
"managedResources": [
{
"name": "tke.cloud.tencent.com/eni-ip",
"ignoredByScheduler": true
}
]
}
],
"kind" : "Policy"
}
查看floatingip-config配置
# kubectl get cm -n kube-system floatingip-config -o yaml
apiVersion: v1
data:
floatingips: '[{"routableSubnet":"172.21.64.0/20","ips":["192.168.64.200~192.168.64.251"],"subnet":"192.168.64.0/24","gateway":"192.168.64.1"}]'
kind: ConfigMap
metadata:
creationTimestamp: "2020-03-04T07:09:14Z"
name: floatingip-config
namespace: kube-system
resourceVersion: "2711974"
selfLink: /api/v1/namespaces/kube-system/configmaps/floatingip-config
uid: 62524e92-f37b-4db2-8ec0-b01d7a90d1a1
查看deployment配置float-ip
# kubectl get deploy nnn -o yaml
apiVersion: apps/v1
kind: Deployment
...
spec:
...
template:
metadata:
annotations:
k8s.v1.cni.cncf.io/networks: galaxy-k8s-vlan
k8s.v1.cni.galaxy.io/release-policy: immutable
creationTimestamp: null
labels:
k8s-app: nnn
qcloud-app: nnn
spec:
containers:
- image: nginx
imagePullPolicy: Always
name: nnn
resources:
limits:
cpu: 500m
memory: 1Gi
tke.cloud.tencent.com/eni-ip: "1"
requests:
cpu: 250m
memory: 256Mi
tke.cloud.tencent.com/eni-ip: "1"
查看生成的pod带有float-ip的annotations
# kubectl get pod nnn-7df5984746-58hjm -o yaml
apiVersion: v1
kind: Pod
metadata:
annotations:
k8s.v1.cni.cncf.io/networks: galaxy-k8s-vlan
k8s.v1.cni.galaxy.io/args: '{"common":{"ipinfos":[{"ip":"192.168.64.202/24","vlan":0,"gateway":"192.168.64.1","routable_subnet":"172.21.64.0/20"}]}}'
k8s.v1.cni.galaxy.io/release-policy: immutable
...
spec:
...
status:
...
hostIP: 172.21.64.15
phase: Running
podIP: 192.168.64.202
podIPs:
- ip: 192.168.64.202
查看crd中保存的floatingips绑定信息
# kubectl get floatingips.galaxy.k8s.io 192.168.64.202 -o yaml
apiVersion: galaxy.k8s.io/v1alpha1
kind: FloatingIP
metadata:
creationTimestamp: "2020-03-04T08:28:15Z"
generation: 1
labels:
ipType: internalIP
name: 192.168.64.202
resourceVersion: "2744910"
selfLink: /apis/galaxy.k8s.io/v1alpha1/floatingips/192.168.64.202
uid: b5d55f27-4548-44c7-b8ad-570814b55026
spec:
attribute: '{"NodeName":"172.21.64.15"}'
key: dp_default_nnn_nnn-7df5984746-58hjm
policy: 1
subnet: 172.21.64.0/20
updateTime: "2020-03-04T08:28:15Z"
查看所在主机上生成了对应的nic和ip
# ip route
default via 172.21.64.1 dev eth0
169.254.0.0/16 dev eth0 scope link metric 1002
172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1
172.21.64.0/20 dev eth0 proto kernel scope link src 172.21.64.15
...
192.168.64.202 dev v-hb21e7165d
3 - CronHPA
Cron Horizontal Pod Autoscaler(CronHPA)使我们能够使用crontab模式定期自动扩容工作负载(那些支持扩展子资源的负载,例如deployment、statefulset)。
CronHPA使用Cron格式进行编写,周期性地在给定的调度时间对工作负载进行扩缩容。
CronHPA 资源结构
CronHPA定义了一个新的CRD,cron-hpa-controller是该CRD对应的controller/operator,它解析CRD中的配置,根据系统时间信息对相应的工作负载进行扩缩容操作。
// CronHPA represents a set of crontabs to set target's replicas.
type CronHPA struct {
metav1.TypeMeta `json:",inline"`
metav1.ObjectMeta `json:"metadata,omitempty"`
// Spec defines the desired identities of pods in this cronhpa.
Spec CronHPASpec `json:"spec,omitempty"`
// Status is the current status of pods in this CronHPA. This data
// may be out of date by some window of time.
Status CronHPAStatus `json:"status,omitempty"`
}
// A CronHPASpec is the specification of a CronHPA.
type CronHPASpec struct {
// scaleTargetRef points to the target resource to scale
ScaleTargetRef autoscalingv2.CrossVersionObjectReference `json:"scaleTargetRef" protobuf:"bytes,1,opt,name=scaleTargetRef"`
Crons []Cron `json:"crons" protobuf:"bytes,2,opt,name=crons"`
}
type Cron struct {
// The schedule in Cron format, see https://en.wikipedia.org/wiki/Cron.
Schedule string `json:"schedule" protobuf:"bytes,1,opt,name=schedule"`
TargetReplicas int32 `json:"targetReplicas" protobuf:"varint,2,opt,name=targetReplicas"`
}
// CronHPAStatus represents the current state of a CronHPA.
type CronHPAStatus struct {
// Information when was the last time the schedule was successfully scheduled.
// +optional
LastScheduleTime *metav1.Time `json:"lastScheduleTime,omitempty" protobuf:"bytes,2,opt,name=lastScheduleTime"`
}
// +k8s:deepcopy-gen:interfaces=k8s.io/apimachinery/pkg/runtime.Object
// CronHPAList is a collection of CronHPA.
type CronHPAList struct {
metav1.TypeMeta `json:",inline"`
metav1.ListMeta `json:"metadata,omitempty"`
Items []CronHPA `json:"items"`
}
使用示例
指定deployment每周五20点扩容到60个实例,周日23点缩容到30个实例
apiVersion: extensions.tkestack.io/v1
kind: CronHPA
metadata:
name: example-cron-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: demo-deployment
crons:
- schedule: "0 20 * * 5"
targetReplicas: 60
- schedule: "0 23 * * 7"
targetReplicas: 30
指定deployment每天8点到9点,19点到21点扩容到60,其他时间点恢复到10
apiVersion: extensions.tkestack.io/v1
kind: CronHPA
metadata:
name: web-servers-cronhpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: web-servers
crons:
- schedule: "0 8 * * *"
targetReplicas: 60
- schedule: "0 9 * * *"
targetReplicas: 10
- schedule: "0 19 * * *"
targetReplicas: 60
- schedule: "0 21 * * *"
targetReplicas: 10
查看cronhpa
# kubectl get cronhpa
NAME AGE
example-cron-hpa 104s
# kubectl get cronhpa example-cron-hpa -o yaml
apiVersion: extensions.tkestack.io/v1
kind: CronHPA
...
spec:
crons:
- schedule: 0 20 * * 5
targetReplicas: 60
- schedule: 0 23 * * 7
targetReplicas: 30
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: demo-deployment
删除cronhpa
kubectl delete cronhpa example-cron-hpa
4 - GPU-Manager说明
组件介绍
GPU Manager提供一个All-in-One的GPU管理器, 基于Kubernets Device Plugin插件系统实现, 该管理器提供了分配并共享GPU, GPU指标查询, 容器运行前的GPU相关设备准备等功能, 支持用户在Kubernetes集群中使用GPU设备。
管理器包含如下功能:
- 拓扑分配:提供基于GPU拓扑分配功能, 当用户分配超过1张GPU卡的的应用, 可以选择拓扑连接最快的方式分配GPU设备
- GPU共享:允许用户提交小于1张卡资源的的任务, 并提供QoS保证
- 应用GPU指标的查询:用户可以访问主机的端口(默认为5678)的/metrics路径,可以为Prometheus提供GPU指标的收集功能, /usage路径可以提供可读性的容器状况查询
部署在集群内kubernetes对象
在集群内部署GPU-Manager Add-on , 将在集群内部署以下kubernetes对象
| kubernetes对象名称 | 类型 | 建议预留资源 | 所属Namespaces |
|---|---|---|---|
| gpu-manager-daemonset | DaemonSet | 每节点1核CPU, 1Gi内存 | kube-system |
| gpu-quota-admission | Deployment | 1核CPU, 1Gi内存 | kube-system |
GPU-Manager使用场景
在Kubernetes集群中运行GPU应用时, 可以解决AI训练等场景中申请独立卡造成资源浪费的情况,让计算资源得到充分利用。
GPU-Manager限制条件
- 该组件基于Kubernetes DevicePlugin实现, 只能运行在支持DevicePlugin的TKE的1.10kubernetes版本之上。
- 每张GPU卡一共有100个单位的资源, 仅支持0-1的小数卡,以及1的倍数的整数卡设置. 显存资源是以256MiB为最小的一个单位的分配显存。
- 使用GPU-Manager 要求集群内包含GPU机型节点。
GPU-Manager使用方法
- 安装GPU-Manager扩展组件
- 在安装了GPU-Manager扩展组件的集群中,创建工作负载。
- 创建工作负载设置GPU限制,如图:
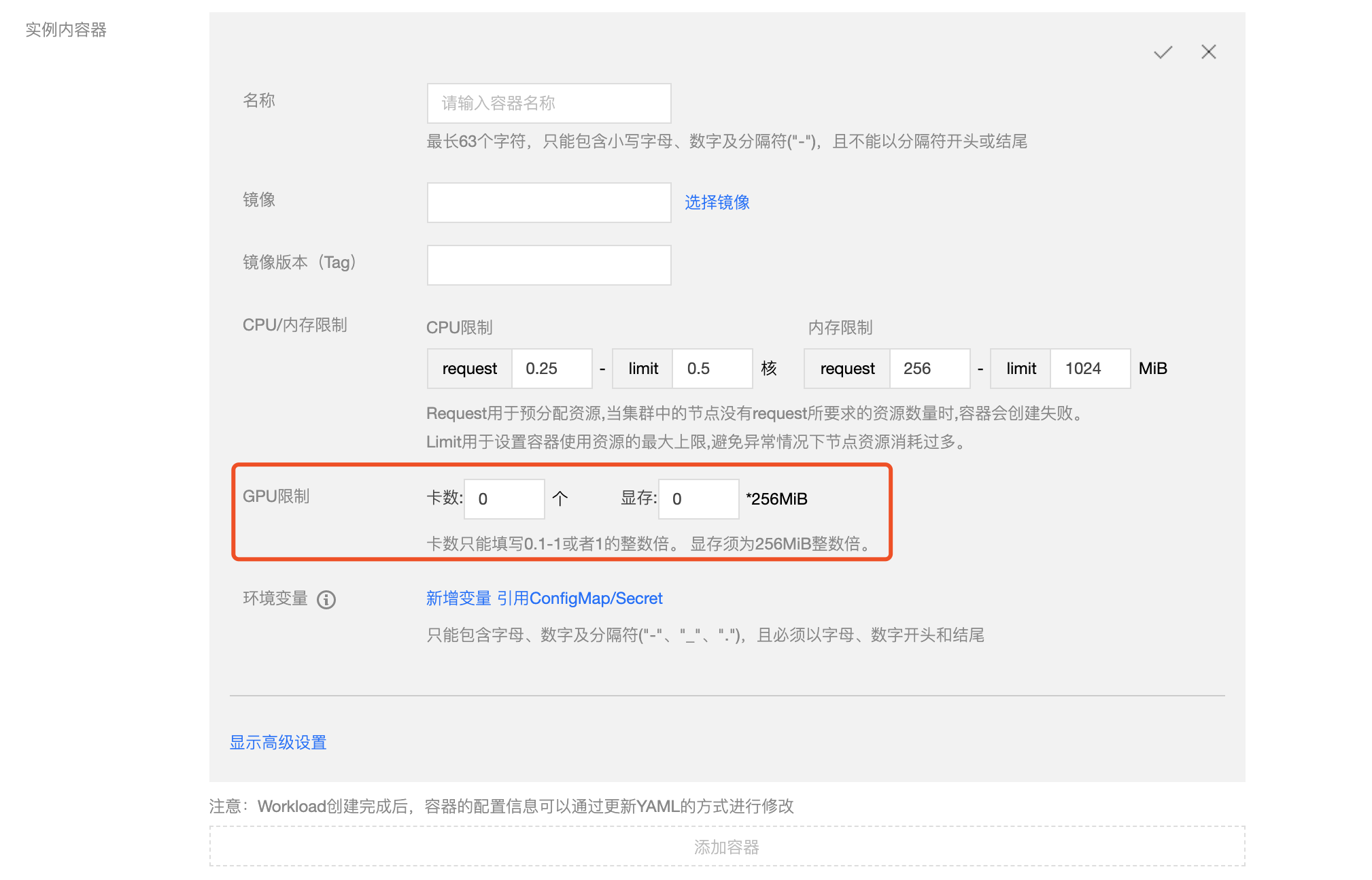
yaml创建
如果使用yaml创建工作负载,提交的时候需要在yaml为容器设置GPU的的使用资源, 核资源需要在resource上填写tencent.com/vcuda-core, 显存资源需要在resource上填写tencent.com/vcuda-memory,
- 使用1张卡
apiVersion: v1
kind: Pod
...
spec:
containers:
- name: gpu
resources:
tencent.com/vcuda-core: 100
- 使用0.3张卡, 5GiB显存的应用(20*256MB)
apiVersion: v1
kind: Pod
...
spec:
containers:
- name: gpu
resources:
tencent.com/vcuda-core: 30
tencent.com/vcuda-memory: 20
5 - LBCF说明
组件介绍 : Load Balancer Controlling Framework (LBCF)
LBCF是一款部署在Kubernetes内的通用负载均衡控制面框架,旨在降低容器对接负载均衡的实现难度,并提供强大的扩展能力以满足业务方在使用负载均衡时的个性化需求。
部署在集群内kubernetes对象
在集群内部署LBCF Add-on , 将在集群内部署以下kubernetes对象
| kubernetes对象名称 | 类型 | 默认占用资源 | 所属Namespaces |
|---|---|---|---|
| lbcf-controller | Deployment | / | kube-system |
| lbcf-controller | ServiceAccount | / | kube-system |
| lbcf-controller | ClusterRole | / | / |
| lbcf-controller | ClusterRoleBinding | / | / |
| lbcf-controller | Secret | / | kube-system |
| lbcf-controller | Service | / | kube-system |
| backendrecords.lbcf.tkestack.io | CustomResourceDefinition | / | / |
| backendgroups.lbcf.tkestack.io | CustomResourceDefinition | / | / |
| loadbalancers.lbcf.tkestack.io | CustomResourceDefinition | / | / |
| loadbalancerdrivers.lbcf.tkestack.io | CustomResourceDefinition | / | / |
| lbcf-mutate | MutatingWebhookConfiguration | / | / |
| lbcf-validate | ValidatingWebhookConfiguration | / | / |
LBCF使用场景
LBCF对K8S内部晦涩的运行机制进行了封装并以Webhook的形式对外暴露,在容器的全生命周期中提供了多达8种Webhook。通过实现这些Webhook,开发人员可以轻松实现下述功能:
- 对接任意负载均衡/名字服务,并自定义对接过程
- 实现自定义灰度升级策略
- 容器环境与其他环境共享同一个负载均衡
- 解耦负载均衡数据面与控制面
LBCF使用方法
- 通过扩展组件安装LBCF
- 开发或选择安装LBCF Webhook规范的要求实现Webhook服务器
- 以下按腾讯云CLB开发的webhook服务器为例
详细的使用方法和帮助文档,请参考lb-controlling-framework文档
使用示例
使用已有四层CLB
本例中使用了id为lb-7wf394rv的负载均衡实例,监听器为四层监听器,端口号为20000,协议类型TCP。
注: 程序会以端口号20000,协议类型TCP为条件查询监听器,若不存在,会自动创建新的
apiVersion: lbcf.tkestack.io/v1beta1
kind: LoadBalancer
metadata:
name: example-of-existing-lb
namespace: kube-system
spec:
lbDriver: lbcf-clb-driver
lbSpec:
loadBalancerID: "lb-7wf394rv"
listenerPort: "20000"
listenerProtocol: "TCP"
ensurePolicy:
policy: Always
创建新的七层CLB
本例在vpc vpc-b5hcoxj4中创建了公网(OPEN)负载均衡实例,并为之创建了端口号为9999的HTTP监听器,最后会在监听器中创建mytest.com/index.html的转发规则
apiVersion: lbcf.tkestack.io/v1beta1
kind: LoadBalancer
metadata:
name: example-of-create-new-lb
namespace: kube-system
spec:
lbDriver: lbcf-clb-driver
lbSpec:
vpcID: vpc-b5hcoxj4
loadBalancerType: "OPEN"
listenerPort: "9999"
listenerProtocol: "HTTP"
domain: "mytest.com"
url: "/index.html"
ensurePolicy:
policy: Always
设定backend权重
本例展示了Service NodePort的绑定。被绑定Service的名称为svc-test,service port为80(TCP),绑定到CLB的每个Node:NodePort的权重都是66
apiVersion: lbcf.tkestack.io/v1beta1
kind: BackendGroup
metadata:
name: web-svc-backend-group
namespace: kube-system
spec:
lbName: test-clb-load-balancer
service:
name: svc-test
port:
portNumber: 80
parameters:
weight: "66"
附录
腾讯云CLB LBCF driver
ConfigMap:
apiVersion: v1
kind: ConfigMap
metadata:
name: trusted-tencentcloudapi
namespace: kube-system
data:
tencentcloudapi.pem: |
-----BEGIN CERTIFICATE-----
.............
-----END CERTIFICATE-----
Deployment
apiVersion: lbcf.tkestack.io/v1beta1
kind: LoadBalancerDriver
metadata:
name: lbcf-clb-driver
namespace: kube-system
spec:
driverType: Webhook
url: "http://lbcf-clb-driver.kube-system.svc"
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: lbcf-clb-driver
namespace: kube-system
spec:
replicas: 1
selector:
matchLabels:
lbcf.tkestack.io/component: lbcf-clb-driver
template:
metadata:
labels:
lbcf.tkestack.io/component: lbcf-clb-driver
spec:
priorityClassName: "system-node-critical"
containers:
- name: driver
image: ${image-name}
args:
- "--region=${your-region}"
- "--vpc-id=${your-vpc-id}"
- "--secret-id=${your-account-secret-id}"
- "--secret-key=${your-account-secret-key}"
ports:
- containerPort: 80
name: insecure
imagePullPolicy: Always
volumeMounts:
- name: trusted-ca
mountPath: /etc/ssl/certs
readOnly: true
volumes:
- name: trusted-ca
configMap:
name: trusted-tencentcloudapi
Service:
apiVersion: v1
kind: Service
metadata:
labels:
name: lbcf-clb-driver
namespace: kube-system
spec:
ports:
- name: insecure
port: 80
targetPort: 80
selector:
lbcf.tkestack.io/component: lbcf-clb-driver
sessionAffinity: None
type: ClusterIP