产品使用指南
- 1: 切换控制台
- 2: 平台管理控制台
- 2.1: 概览
- 2.2: 集群管理
- 2.3: 业务管理
- 2.4: 扩展组件
- 2.4.1: TApp 介绍
- 2.4.2: CronHPA 介绍
- 2.4.3: 监控组件
- 2.4.4: LogAgent 介绍
- 2.4.5: GPUManager 介绍
- 2.4.6: CSIOperator 介绍
- 2.5: 组织资源
- 2.6: 访问管理
- 2.7: 监控&告警
- 2.8: 运维中心
- 3: 业务管理控制台
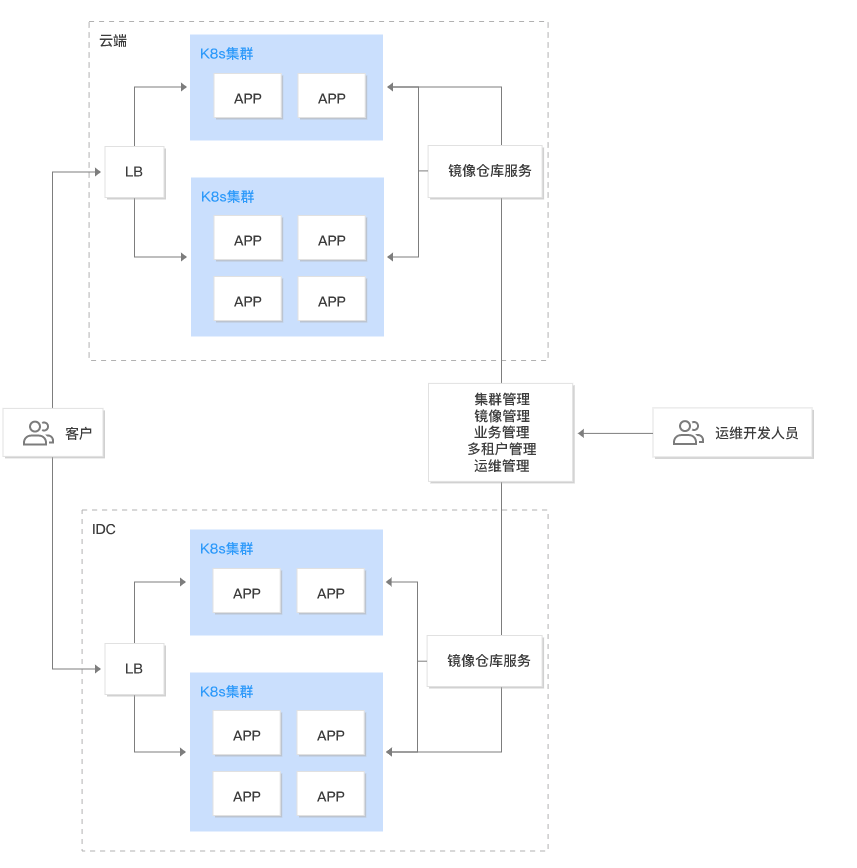
1 - 切换控制台
概念
这里用户可以自由切换控制面和业务面。
注意:只有当【平台管理】控制台中创建的业务的成员包含当前登录的用户,当前用户才会出现并可以切换至【业务管理】控制台,如下图所示。
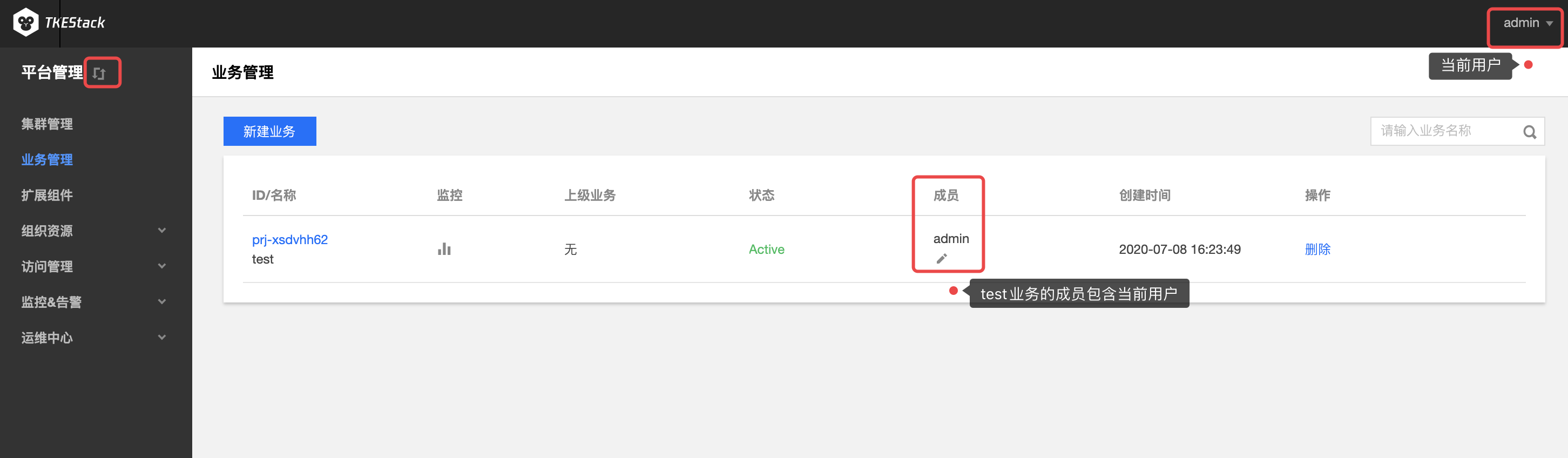
操作步骤
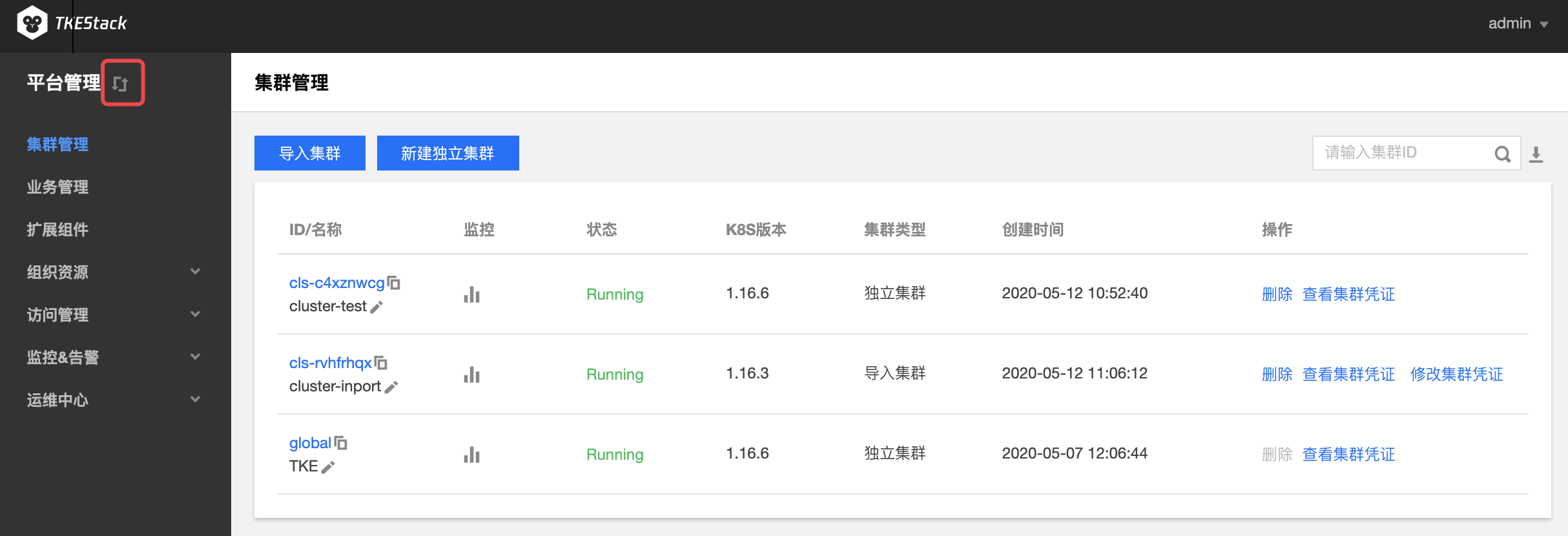
- 登录 TKEStack,默认显示【平台管理】控制台,鼠标移动到【平台管理】旁,会出现切换提示,如下图:
- 如果当前显示的是【业务管理】控制台,鼠标移动到【业务管理】旁,会出现切换提示,如下图:
- 点击【 切换图标】 即可实现【平台管理】和【业务管理】控制台切换。
2 - 平台管理控制台
2.1 - 概览
平台概览页面,可查看TKEStack控制台管理资源的概览。
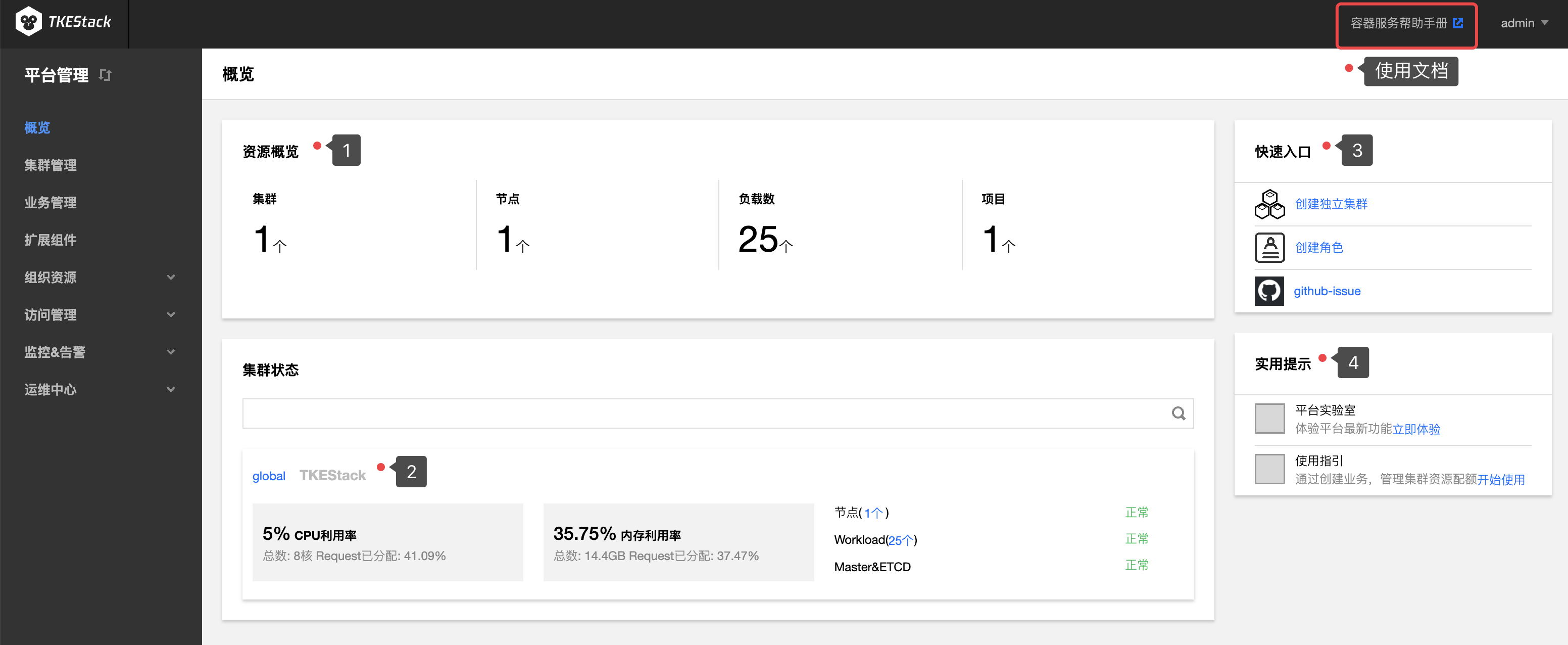
如下图所示,在【平台管理】页面点击【概览】,此处可以展现:
- 平台的资源概览
- 集群的资源状态
- 快速入口
- 实用提示
2.2 - 集群管理
概念
在这里可以管理你的 Kubernetes 集群
平台安装之后,可在【平台管理】控制台的【集群管理】中看到 global 集群,如下图所示: 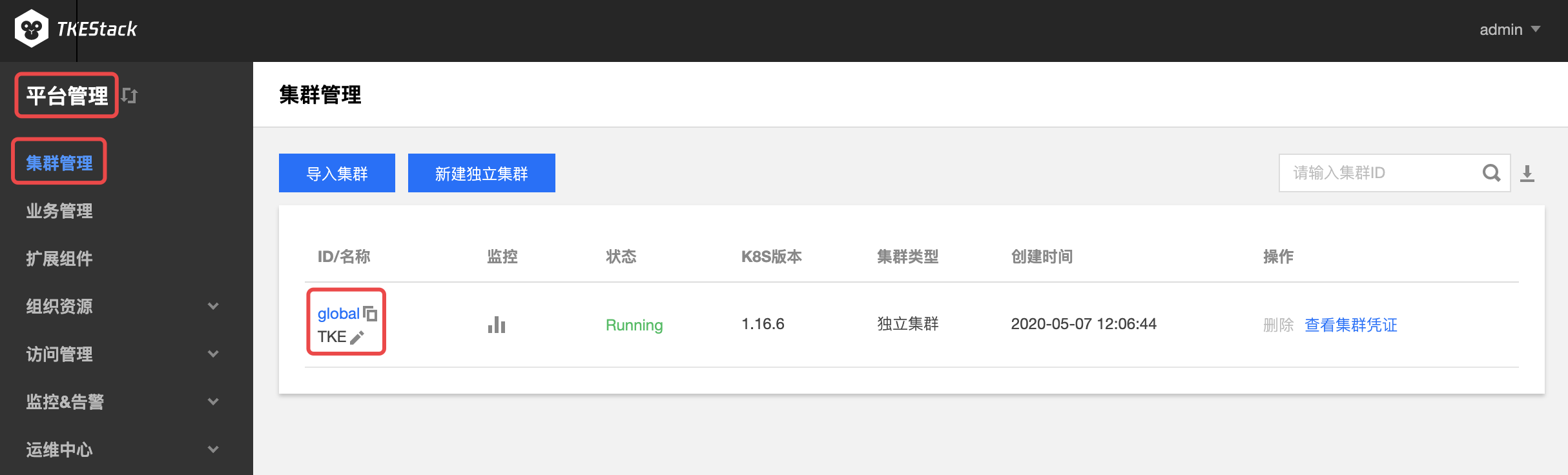
TKEStack还可以另外新建独立集群以及导入已有集群实现多集群的管理
注意:新建独立集群和导入已有集群都属于TKEStack架构中的业务集群。
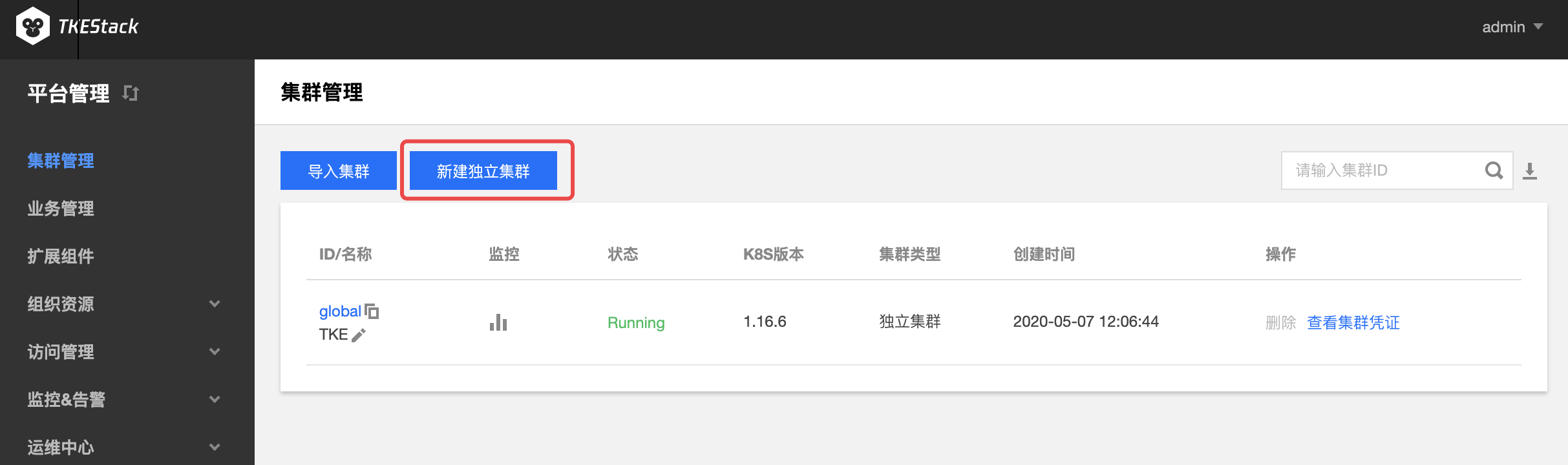
新建独立集群
登录 TKEStack,右上角会出现当前登录的用户名,示例为admin
切换至【平台管理】控制台
在“集群管理”页面中,单击【新建独立集群】,如下图所示:
在“新建独立集群”页面,填写集群的基本信息。新建的集群节点需满足部署环境要求,在满足需求之后,TKEStack的集群添加非常便利。如下图所示,只需填写【集群名称】、【目标机器】、【SSH端口】(默认22)、【密码】,其他保持默认即可添加新的集群。
注意:若【保存】按钮是灰色,单击页面空白处即可变蓝
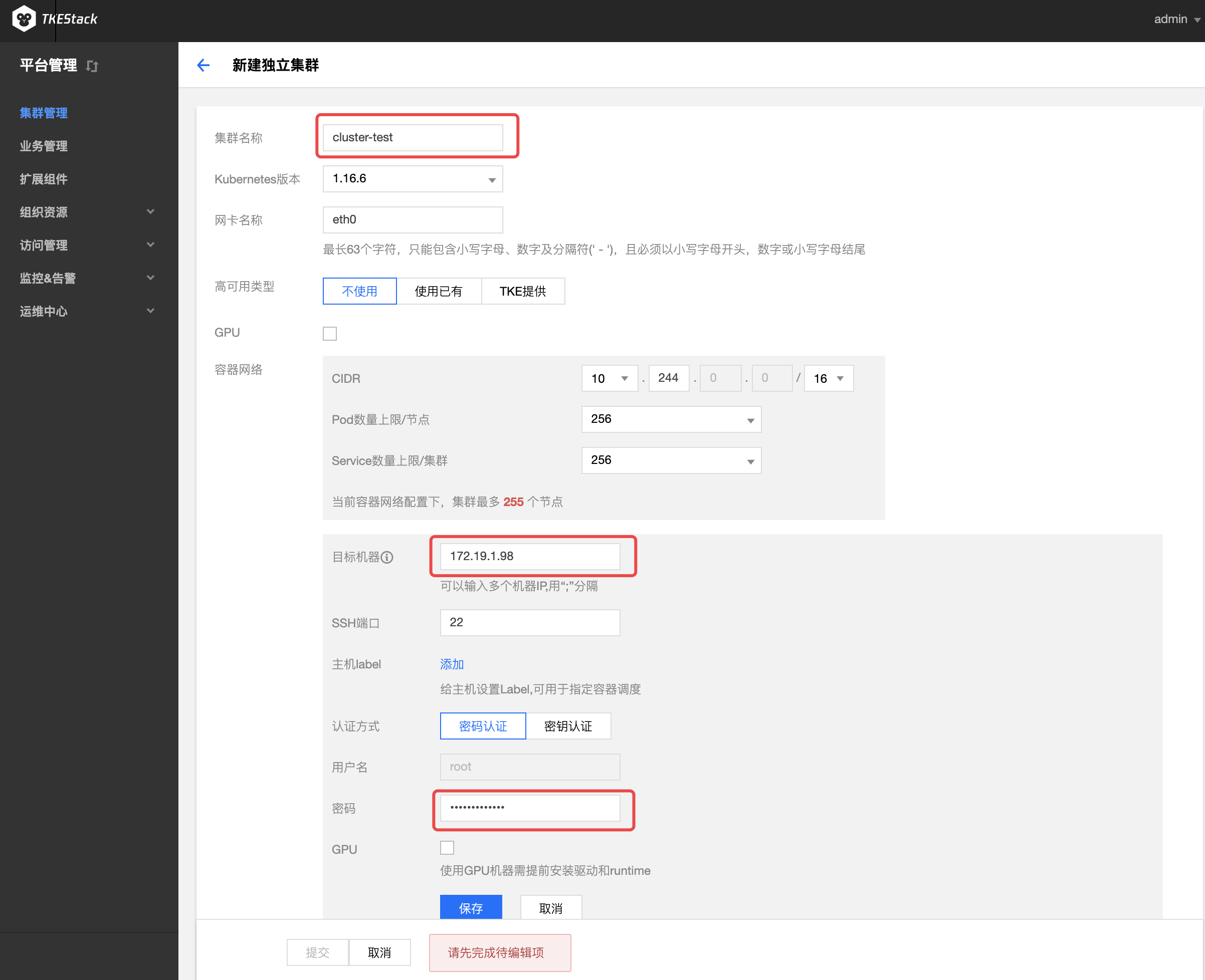
集群名称: 支持中文,小于60字符即可
Kubernetes版本: 选择合适的kubernetes版本,各版本特性对比请查看 Supported Versions of the Kubernetes Documentation(建议使用默认值)
网卡名称: 可以通过 ifconfig 查看设备的网卡名称,一般默认都是 eth0。但有一些特殊情况:如果非 eth0 一定要填入正确的网卡名称,否则跨设备通信容易出现问题
高可用类型 :高可用 VIP 地址(按需使用)
注意:如果使用高可用,至少需要三个 master 节点才可组成高可用集群,否则会出现 脑裂 现象。
- 不设置:第一台 master 节点的 IP 地址作为 APIServer 地址
TKE 提供:用户只需提供高可用的 IP 地址。TKE 部署 Keepalive,配置该 IP 为 Global 集群所有 Master 节点的VIP,以实现 Global 集群和控制台的高可用,此时该 VIP 和所有 Master 节点 IP 地址都是 APIServer 地址
- 使用已有:对接配置好的外部 LB 实例。VIP 绑定 Global 集群所有 Master 节点的 80(TKEStack 控制台)、443(TKEStack 控制台)、6443(kube-apiserver 端口)、31138(tke-auth-api 端口)端口,同时确保该 VIP 有至少两个 LB 后端(Master 节点),以避免 LB 单后端不可用风险
GPU:选择是否安装 GPU 相关依赖。(按需使用)
注意:使用 GPU 首先确保节点有物理 GPU 卡,选择 GPU 类型后,平台将自动为节点安装相应的 GPU 驱动和运行时工具
- pGPU:平台会自动为集群安装 GPUManager 扩展组件,此时可以给负载分配任意整数张卡
- vGPU:平台会自动为集群安装 Nvidia-k8s-device-plugin,此时GPU可以被虚拟化,可以给负载分配非整数张GPU卡,例如可以给一个负载分配0.3个GPU
容器网络 :将为集群内容器分配在容器网络地址范围内的 IP 地址,您可以自定义三大私有网段作为容器网络, 根据您选择的集群内服务数量的上限,自动分配适当大小的 CIDR 段用于 kubernetes service;根据您选择 Pod 数量上限/节点,自动为集群内每台云服务器分配一个适当大小的网段用于该主机分配 Pod 的 IP 地址。(建议使用默认值)
- CIDR: 集群内 Sevice、 Pod 等资源所在网段,注意:CIDR不能与目标机器IP段重叠, 否则会造成初始化失败
- Pod数量上限/节点: 决定分配给每个 Node 的 CIDR 的大小
- Service数量上限/集群:决定分配给 Sevice 的 CIDR 大小
Master :输入目标机器信息后单击保存,若保存按钮是灰色,单击网页空白处即可变蓝
注意:如果在之前选择了高可用,至少需要三个 master 节点才可组成高可用集群,否则会出现 脑裂 现象。
目标机器:Master 节点内网 IP,请配置至少 8 Cores & 16G 内存 及以上的机型,否则会部署失败。注意:如上图所示,如果节点密码一样,这里可以通过英文的分号“;”分隔多个 IP 地址实现快速添加多个节点
SSH 端口: 请确保目标机器安全组开放 22 端口和 ICMP 协议,否则无法远程登录和 ping 通云服务器。(建议使用默认值22)
主机label:给主机设置 Label,可用于指定容器调度。(按需使用)
认证方式:连接目标机器的方式
- 密码认证:
- 密码:目标机器密码
- 密钥认证:
- 密码:目标机器密码
- 证书:目标机器登陆证书
- 密码认证:
GPU: 使用 GPU 机器需提前安装驱动和 runtime。(按需使用)
添加机器:可以通过节点下面的**【添加】**蓝色字体增加不同密码的master节点(**按需添加**)
提交: 集群信息填写完毕后,【提交】按钮变为可提交状态,单击即可提交。
导入已有集群
- 登录 TKEStack
- 切换至【平台管理】控制台
- 在“集群管理”页面,单击【导入集群】,如下图所示:
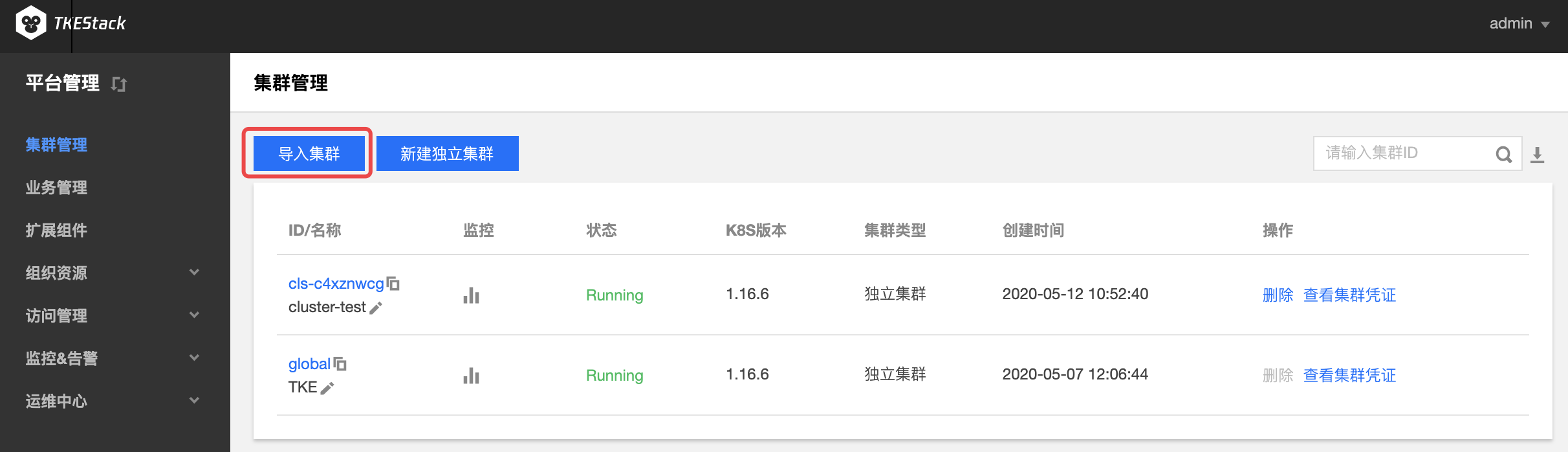
- 在“导入集群”页面,填写被导入的集群信息,如下图所示:
名称: 被导入集群的名称,最长60字符
API Server: 被导入集群的 API Server 的域名或 IP 地址
CertFile: 输入被导入集群的 CertFile 文件内容
Token: 输入被导入集群创建时的 token 值
注意:若不清楚集群的这些信息如何获取,可以参照下面导入 TKE/ACK/RKE 的方式导入自己的集群。
- 单击最下方 【提交】 按钮
TKEStack 导入腾讯的 TKE 集群
首先需要在 TKE 控制台所要导入的集群“基本信息”页里开启内/外网访问

APIServer 地址:即上图中的访问地址,也可以根据上图中 kubeconfig 文件里的“server”字段内容填写。
CertFile:集群证书,kubeconfig 中“certificate-authority-data”字段内容。
Token:由于目前 TKE 没有自动创建具有 admin 权限的 token,这里需要手动创建,具体方式如下:
生成 kubernetes 集群最高权限 admin 用户的 token
cat <<EOF | kubectl apply -f - kind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1beta1 metadata: name: admin annotations: rbac.authorization.kubernetes.io/autoupdate: "true" roleRef: kind: ClusterRole name: cluster-admin apiGroup: rbac.authorization.k8s.io subjects: - kind: ServiceAccount name: admin namespace: kube-system --- apiVersion: v1 kind: ServiceAccount metadata: name: admin namespace: kube-system labels: kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile EOF创建完成后获取 secret 中 token 的值
# 获取admin-token的secret名字 $ kubectl -n kube-system get secret|grep admin-token admin-token-nwphb kubernetes.io/service-account-token 3 6m # 获取token的值 $ kubectl -n kube-system describe secret admin-token-nwphb | grep token Name: admin-token-w4wcd Type: kubernetes.io/service-account-token token: 非常长的字符串
TKEStack 中导入 Rancher 的 RKE 集群
特别注意:RKE 集群的 kubeconfig 中 clusters 字段里面的第一个 cluster 一般都是 Rancher 平台,而不是 RKE 集群。输入以下信息时,要确定选择正确的集群。
获取 RKE 的 kubeconfig 文件
APIServer 地址:获取文件里面的“cluster”字段下“server”的内容。注意是引号里的全部内容
CertFile:集群证书,在上面的“server”地址的正下方,有集群证书字段“certificate-authority-data”。
注意,Rancher 的 kubeconfig 这里的字段内容默认有“\”换行符,需要手动把内容里的换行符和空格全部去除。
Token:在“user”字段里面拥有用户的 token
TKEStack 中导入阿里的 ACK 集群
- 和 TKE 一样,需要获取开启外网访问的 ACK 的 kubeconfig 文件
- APIServer 地址:获取文件里面的“cluster”字段下“server”的内容
- CertFile:集群证书,在上面的“server”地址正下方有集群证书字段“certificate-authority-data”
- Token:获取方式同 TKE,需要手动创建
对集群的操作
基本信息
登录 TKEStack
切换至【平台管理】控制台
在“集群管理”页面中,点击要操作的集群ID,如下图“global”所示:
点击【基本信息】,可查看集群基础信息
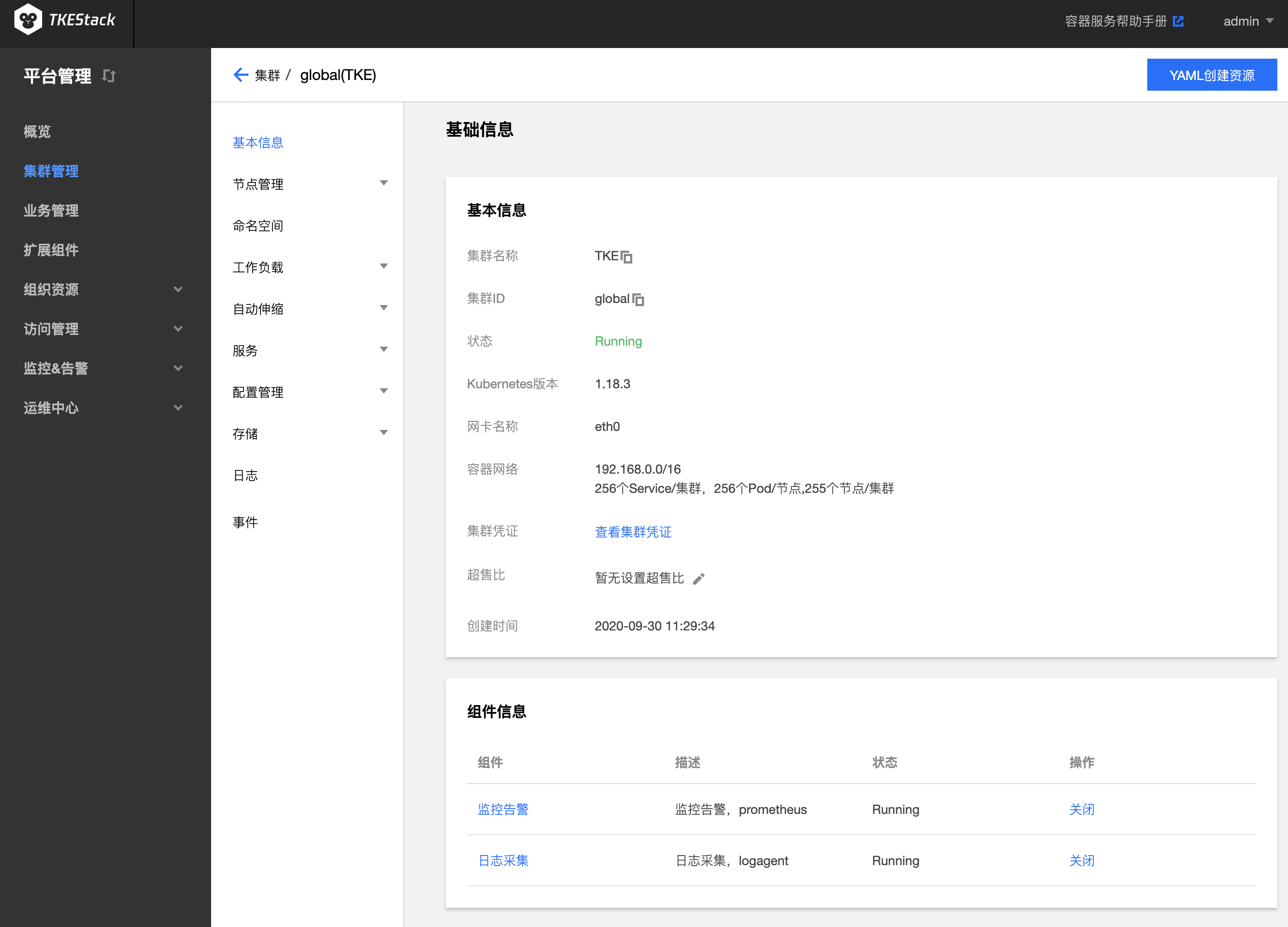
- 基本信息
- 集群名称:用户自定义,可以通过第3步“集群列表页”中 “ID/名称” 下的笔型图案修改
- 集群 ID :TKEStack 自动给每个集群一个唯一的 ID 标识符
- 状态:集群运行状态,Running 表示正常运行
- Kubernetes 版本:当前集群的 Kubernetes 版本
- 网卡名称:当前集群的网卡名称,默认为 eth0
- 容器网络:当前集群的容器网络
- 集群凭证:可以在本地配置 Kubectl 连接 当前 Kubernetes 集群
- 超售比:Kubernetes 对象在申请资源时,如果申请总额大于硬件配置,则无法申请,但是很多时候部分对象并没有占用这么多资源,因此可以设置超售比来扩大资源申请总额,以提高硬件资源利用率
- 创建时间:当前集群的创建时间
- 组件信息:这里可以开启或关闭集群的 日志采集 和 监控告警 功能
- 基本信息
节点管理
节点是容器集群组成的基本元素。节点取决于业务,既可以是虚拟机,也可以是物理机。每个节点都包含运行 Pod 所需要的基本组件,包括 Kubelet、Kube-proxy 等。
添加节点
登录 TKEStack
切换至【平台管理】控制台
在“集群管理”页面中,点击要操作的集群ID,如下图“global”所示:
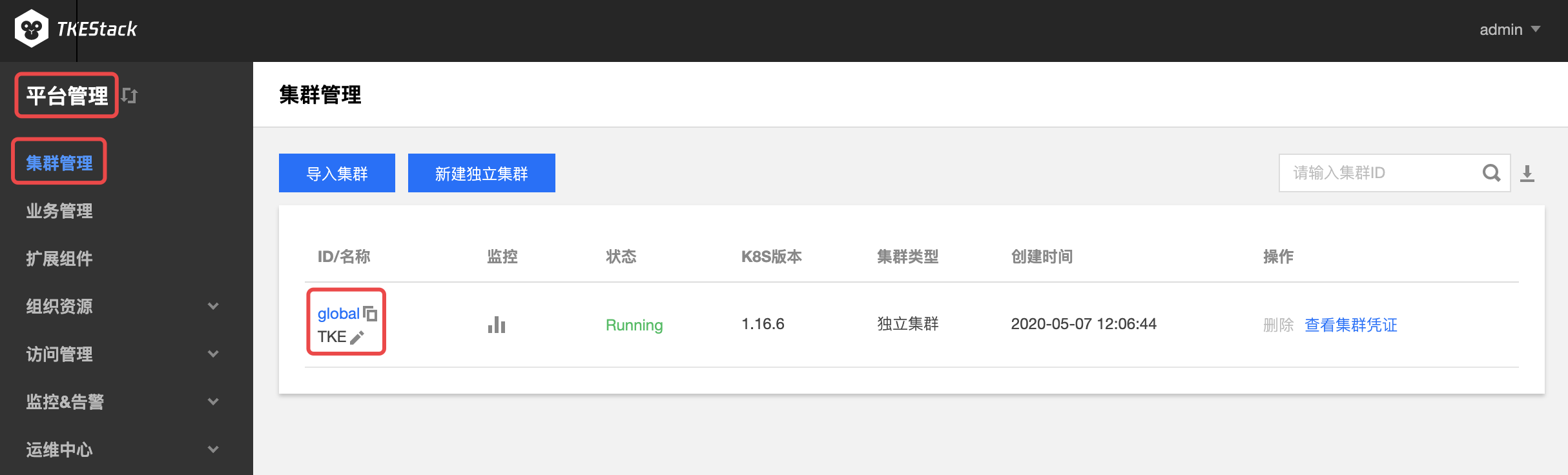
点击【节点管理】中的【节点】,可查看当前集群的“节点列表”
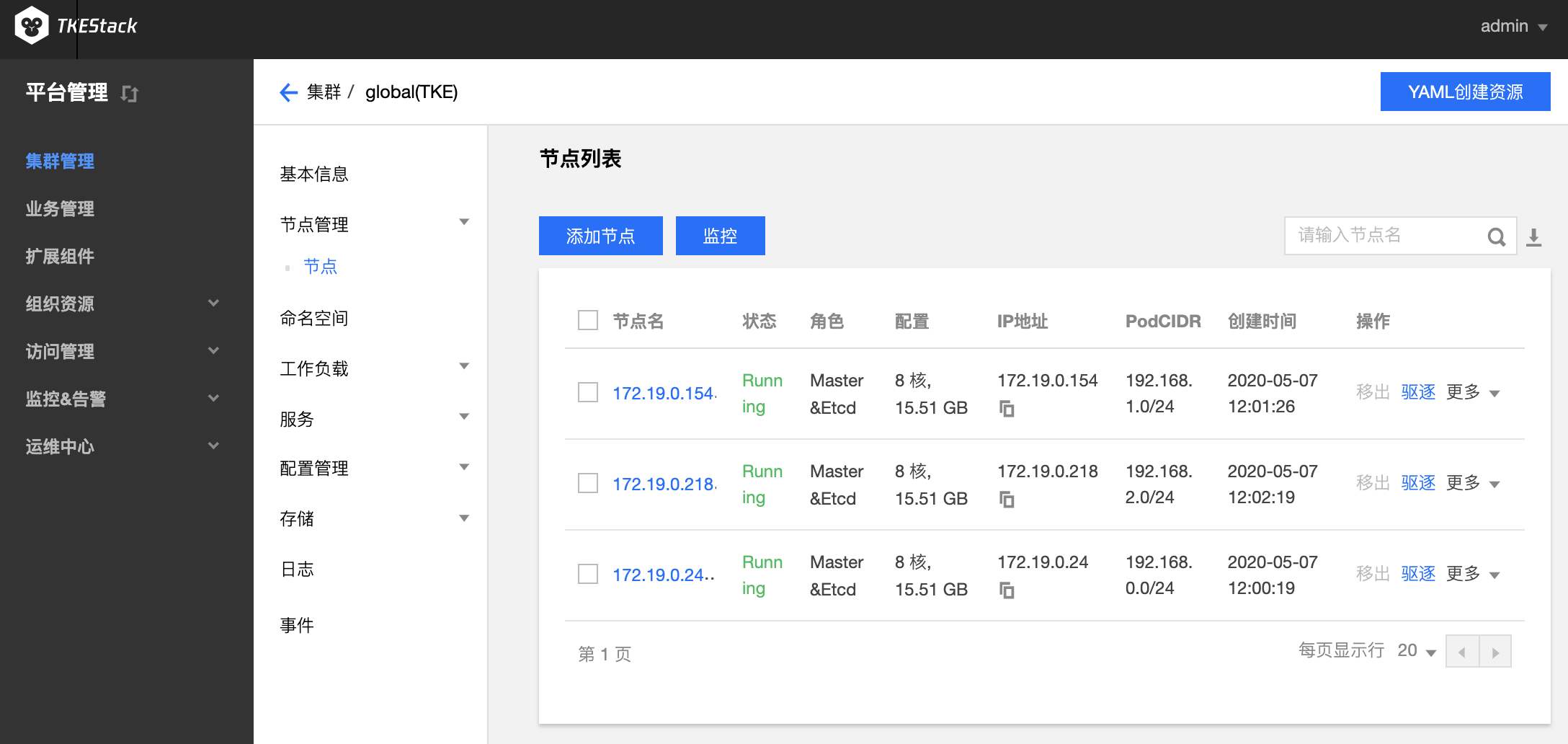
点击蓝色【添加节点】按钮可增加当前集群的 Worker 节点
- 目标机器:建议内网地址,要求添加的节点和当前集群的其他机器在同一内网。注意:如果节点密码一样,这里可以通过英文的分号“;”分隔多个 IP 地址实现快速添加多个节点
- SSH端口:默认 22
- 主机label:按需添加,给主机设置 Label,可用于指定容器调度
- 认证方式:连接目标机器的方式,根据实际情况设置
- 用户名:默认 root
- 密码:目标机器用户名为 root 的密码
- GPU:按需选择,使用 GPU 机器需提前安装驱动和 runtime
- 添加机器:可以通过节点下面的**【添加】**蓝色字体增加不同密码的节点(按需添加)
节点监控
点击上图中的蓝色【监控】按钮可监控节点,可以从Pod、CPU、内存、硬盘、网络等维度监控。
前提:在集群的 基本信息 页里开启了 监控告警
节点操作
对节点的可以的操作如下图所示:
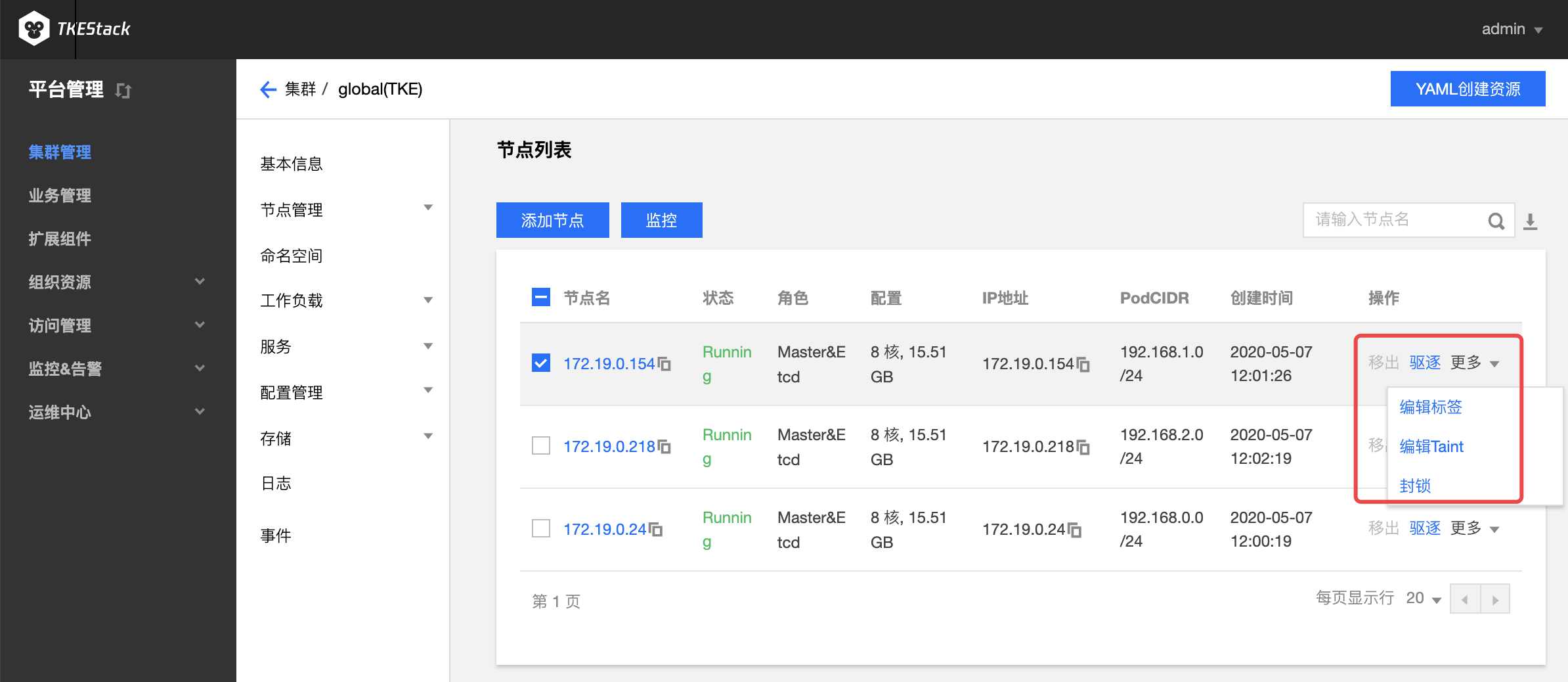
移出:仅针对 worker 节点,将节点移出集群
驱逐:节点驱逐后,将会把节点内的所有 Pod(不包含 DaemonSet 管理的 Pod)从节点中驱逐到集群内其他节点,并将节点设置为封锁状态
注意:本地存储的 Pod 被驱逐后数据将丢失,请谨慎操作
编辑标签:编辑节点标签
编辑 Taint:编辑 Taint 后,新的 pod 不能被调度到该节点,但可以通过编辑 pod 的 toleration 使其可以调度到具有匹配的 taint 节点上
封锁:封锁节点后,将不接受新的Pod调度到该节点,需要手动取消封锁的节点
节点 Pod 管理
点击其中一个节点名,例如上图中的【172.19.0.154】,可以看到该节点更多的信息,具体包括:
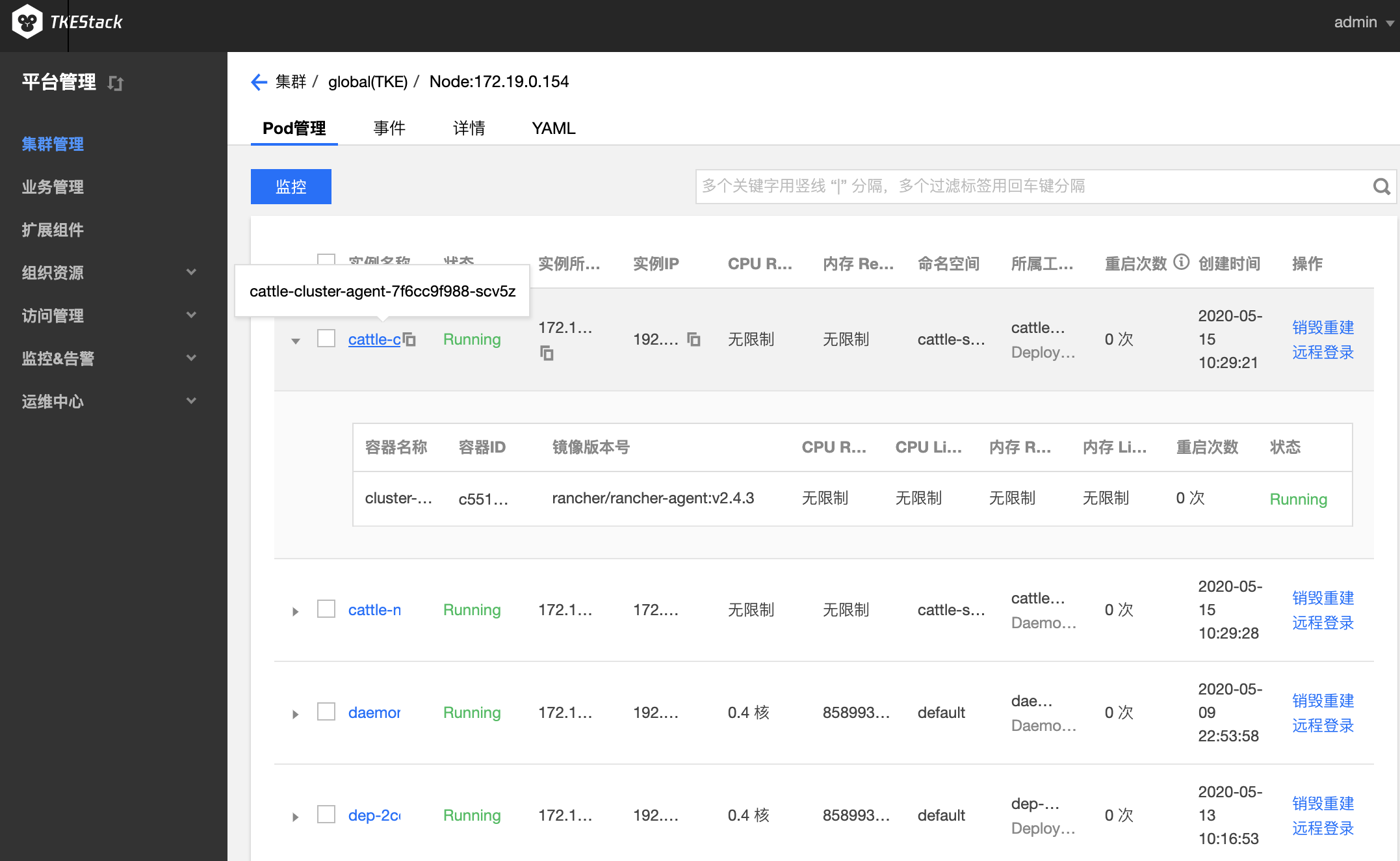
- Pod 管理:可查看当前节点下的 pod
- 销毁重建:销毁该 pod,重新新建该 pod
- 远程登录:登录到该 pod 里
- 事件:关于该节点上资源的事件,资源事件只在 ETCD 里保存最近1小时内发生的事件,请尽快查阅
- 详情:包括节点主机信息以及 Kubernetes 信息
- YAML:此处可以查看节点的 YAML 文件,点击【编辑YAML】可以手动修改节点的 YAML 文件
其他操作
注意:由于【平台管理】控制台下对集群的大多数操作与【业务管理】控制台完全一致,因此除了集群的【基本信息】和【节点管理】之外,其他栏目(包括 命名空间、负载、服务、配置、存储、日志、事件)请参考【业务管理】控制台下【应用管理】的相应部分。
2.3 - 业务管理
概念
在这里用户可以管理线上业务。
操作步骤
新建业务
注:业务可以实现跨集群资源的使用
登录 TKEStack。
在【平台管理】控制台的【业务管理】中,单击 【新建业务】。如下图所示:
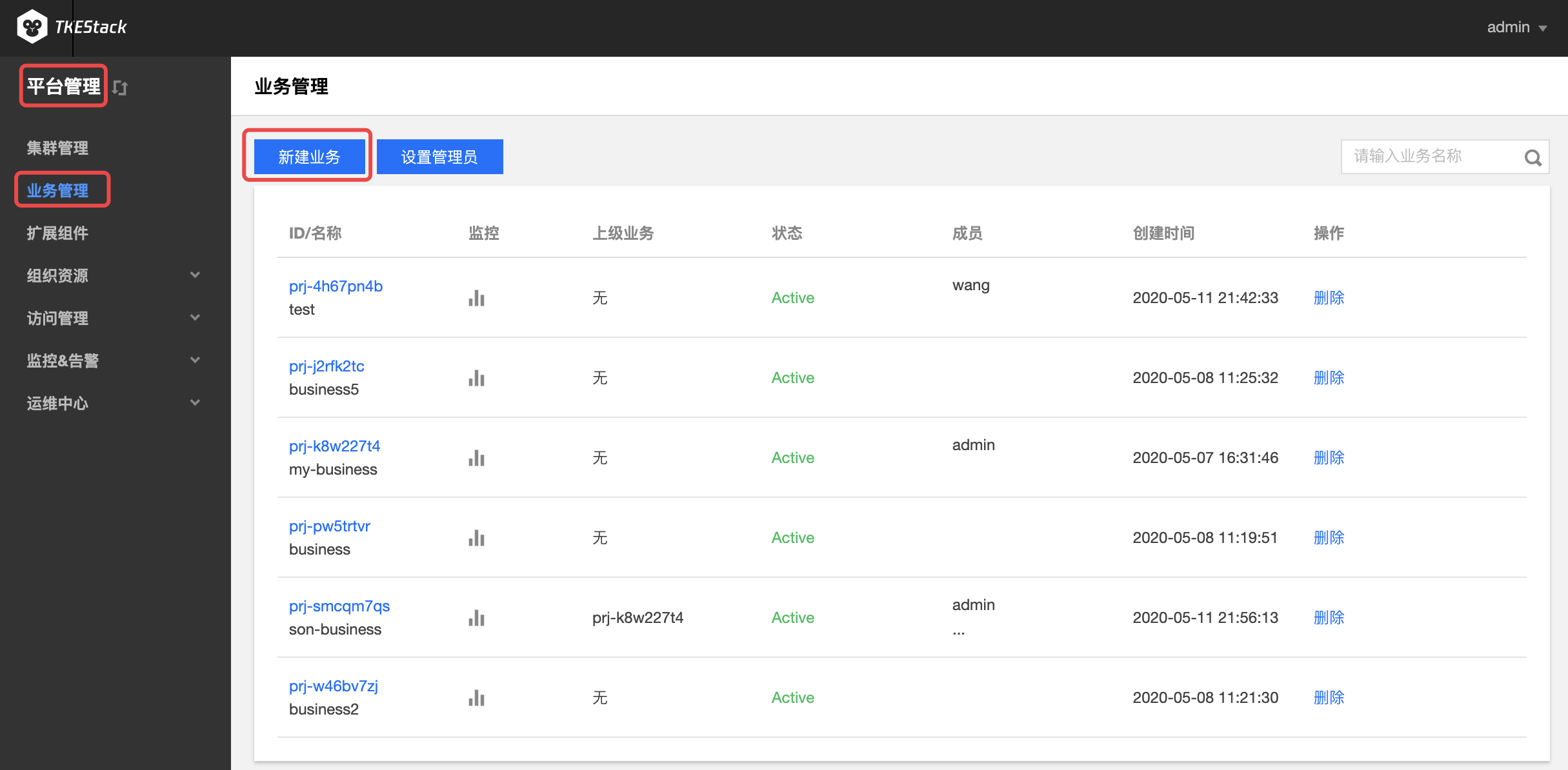
在“新建业务”页面,填写业务信息。如下图所示:
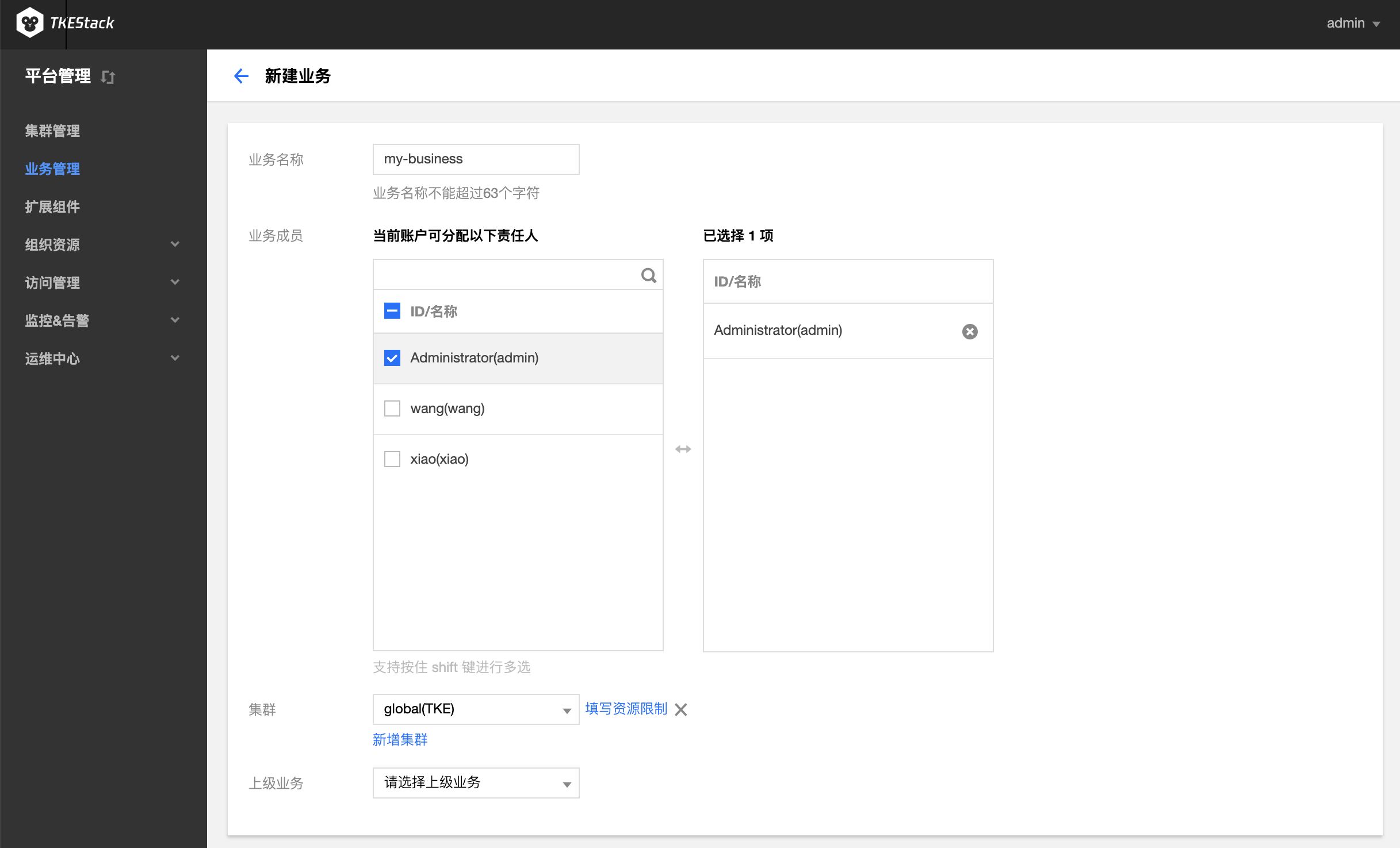
业务名称:不能超过63个字符,这里以
my-business为例业务成员: 【访问管理】中【用户管理】中的用户,这里以
admin例,即该用户可以访问这个业务。集群:
- 【集群管理】中的集群,这里以
gobal集群为例 - 【填写资源限制】可以设置当前业务使用该集群的资源上限(可不限制)
- 【新增集群】可以添加多个集群,此业务可以使用多个集群的资源(按需添加)
- 【集群管理】中的集群,这里以
上级业务:支持多级业务管理,按需选择(可不选)
单击最下方 【完成】 按钮即可创建业务。
添加业务成员
登录 TKEStack。
切换至 【平台管理】控制台,点击【业务管理】。
在“业务管理”页面中,可以看到已创建的业务列表。鼠标移动到要修改的业务上(无需点击),成员列会出现修改图标按钮。如下图所示:
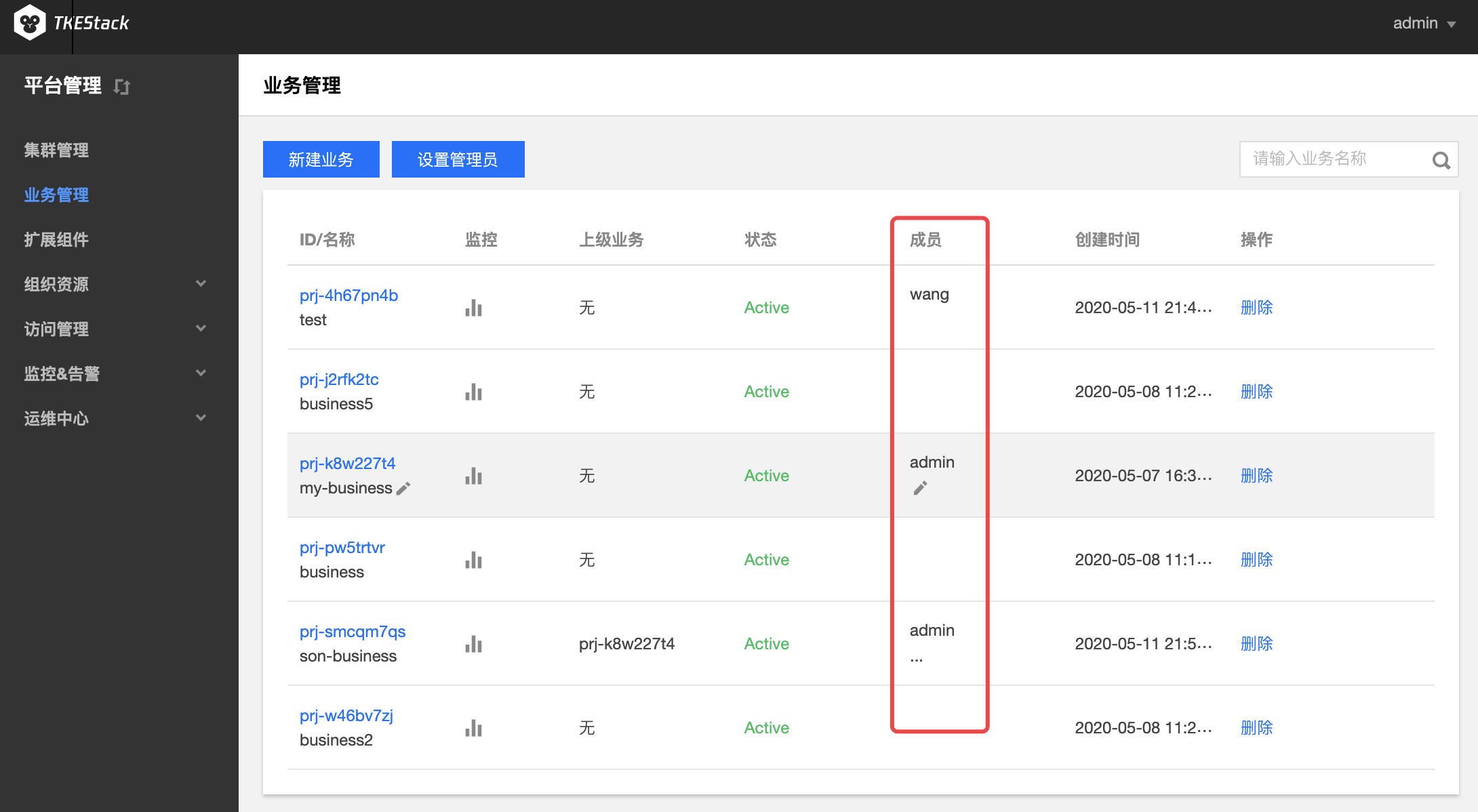
注意:修改业务成员仅限状态为Active的业务,这里可以新建和删除成员。
查看业务监控
登录 TKEStack。
切换至 【管理】控制台,点击【业务管理】。
在“业务管理”页面中,可以看到已创建的业务列表。点击监控按钮,如下图所示:
在右侧弹出窗口里查看业务监控情况,如下图所示:
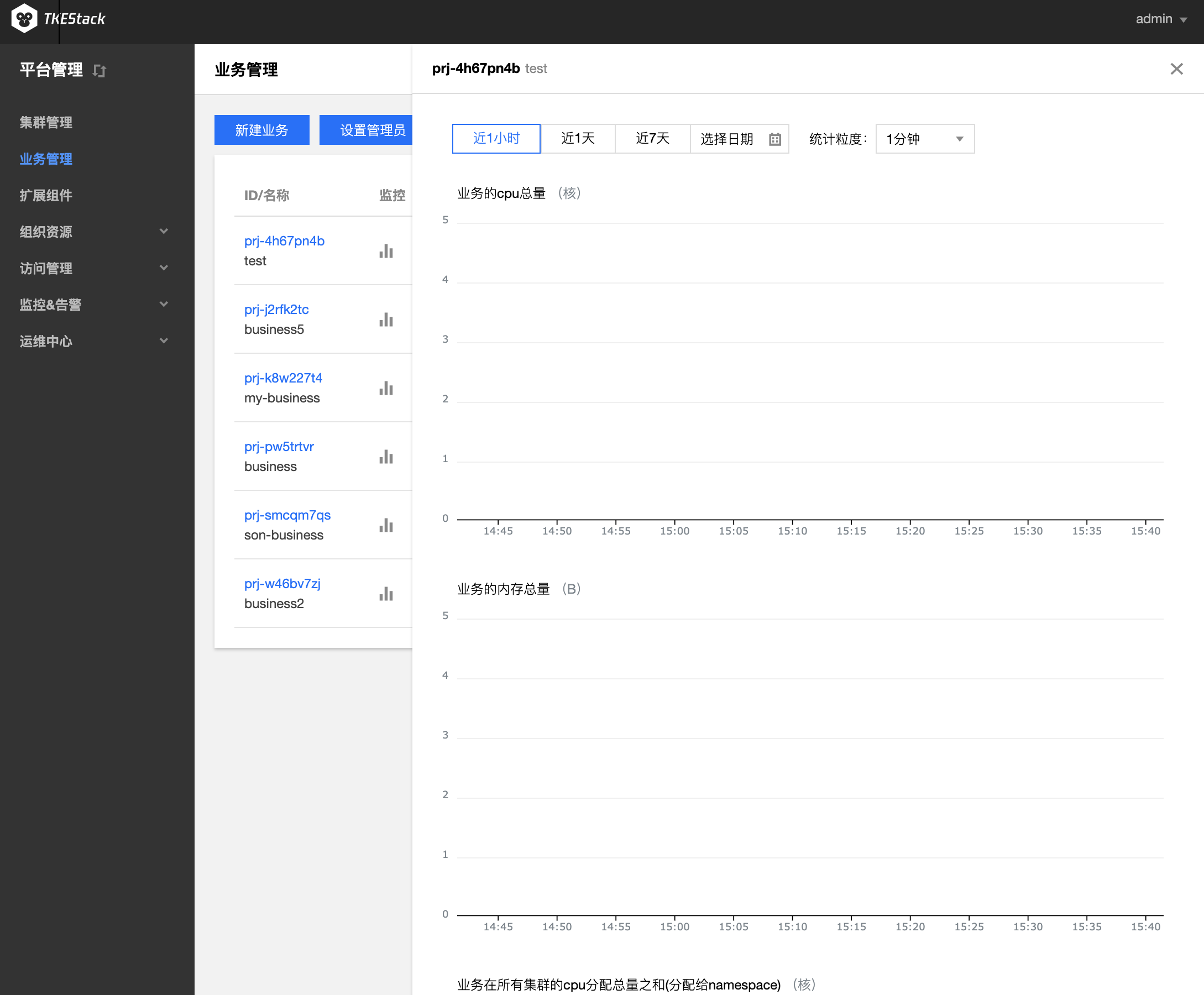
删除业务
登录 TKEStack。
切换至 【平台管理】控制台,点击【业务管理】。
在“业务管理”页面中,可以看到已创建的业务列表。点击删除按钮,如下图所示:
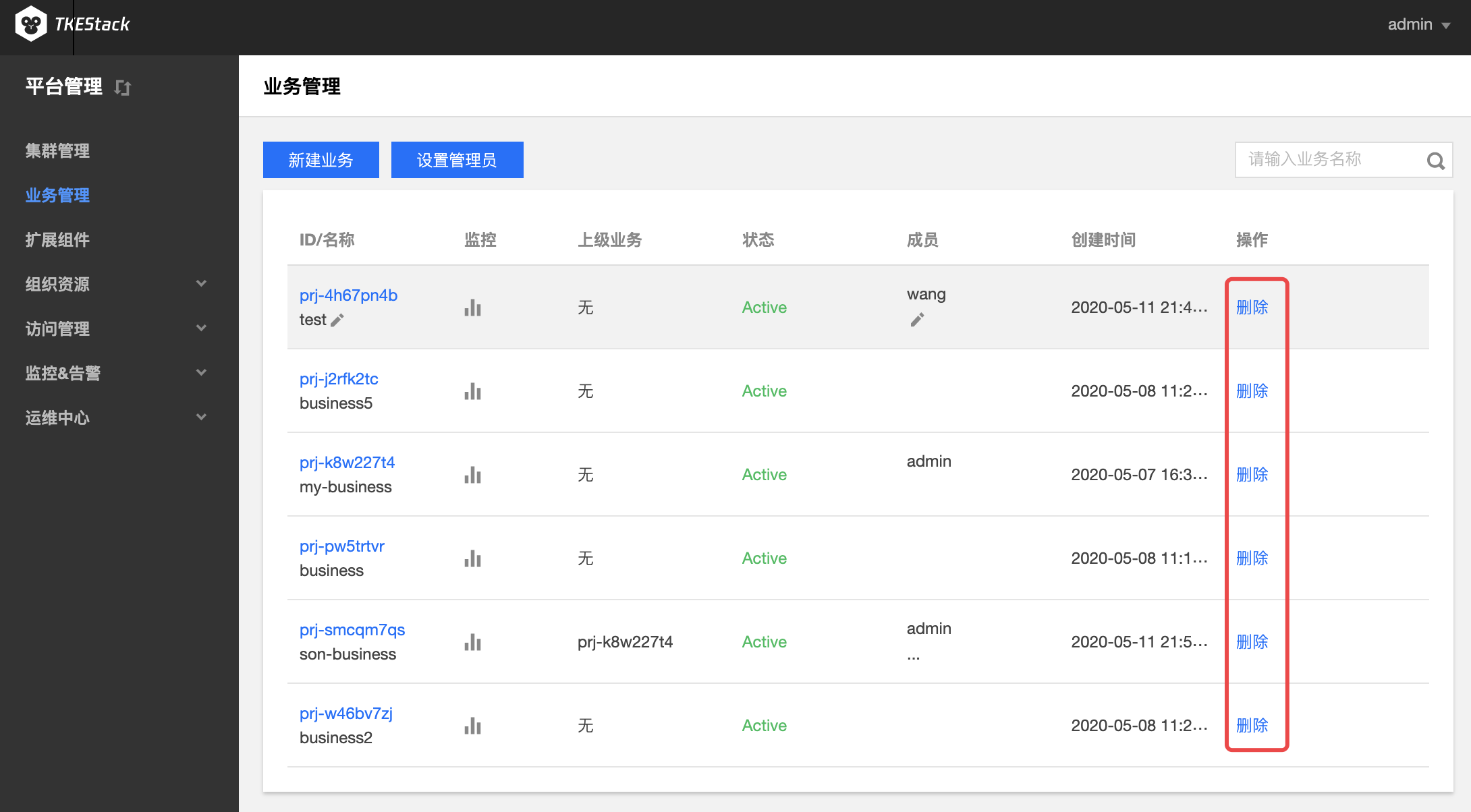
注意:删除业务成员仅限状态为Active的业务
对业务的操作
登录 TKEStack。
在【平台管理】控制台的【业务管理】中,单击【业务id】。如下图所示:
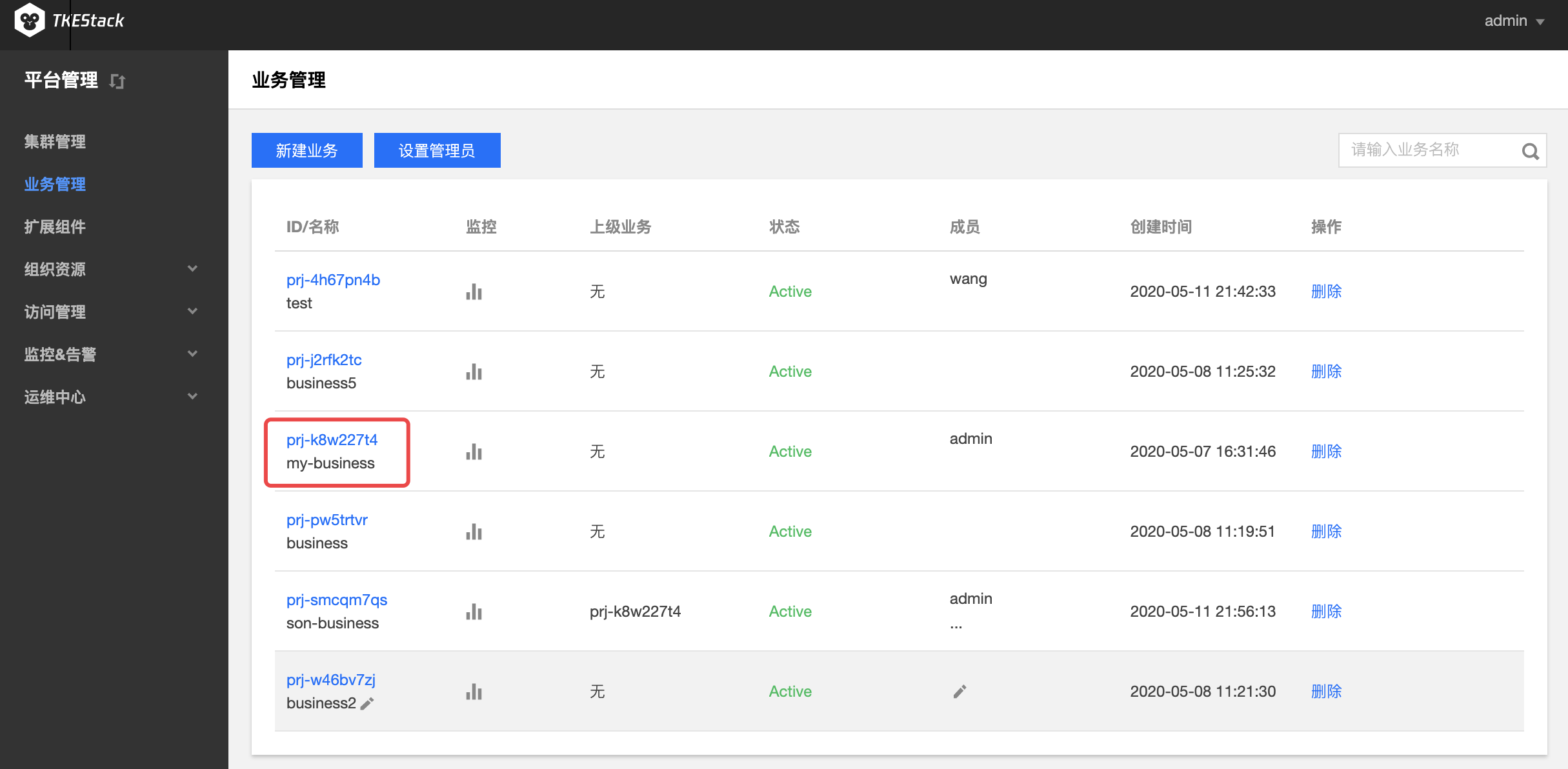
a. 业务信息: 在这里可以对业务名称、关联的集群、关联集群的资源进行限制等操作。
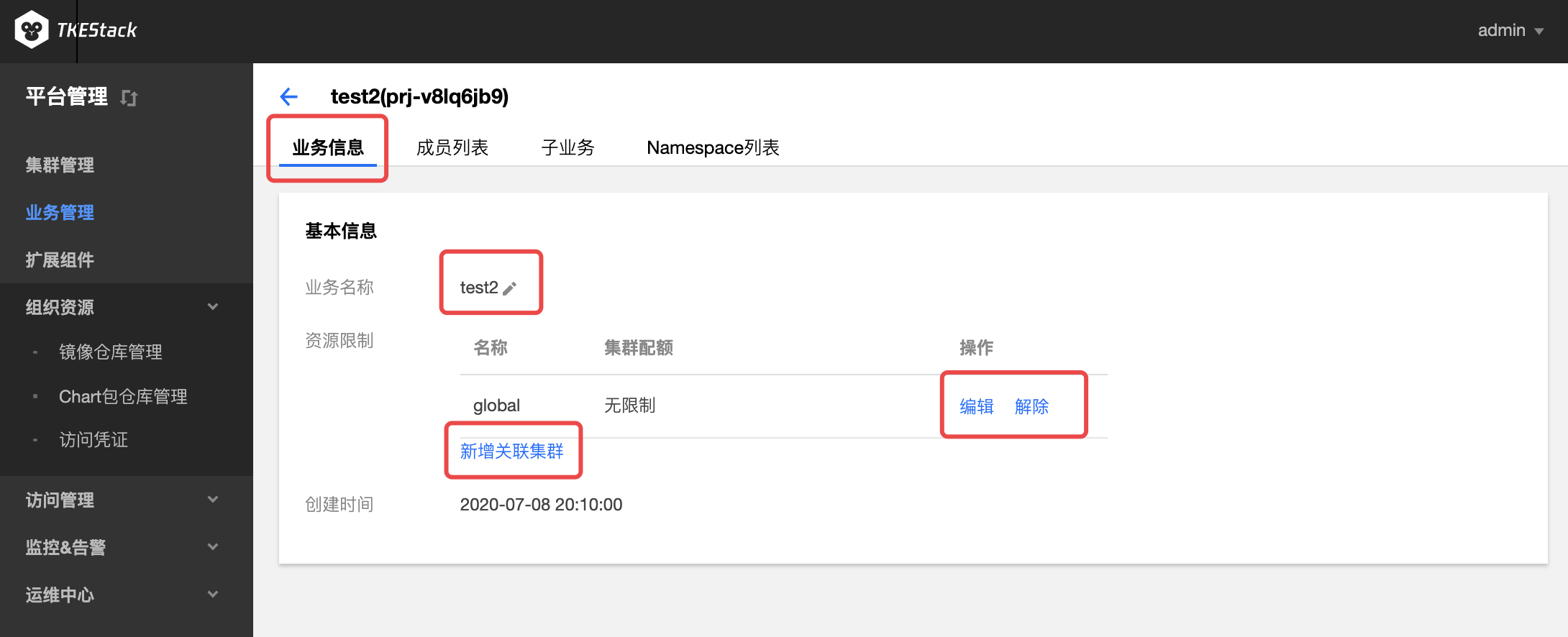
b. 成员列表: 在这里可以对业务名称、关联的集群、关联集群的资源进行限制等操作。
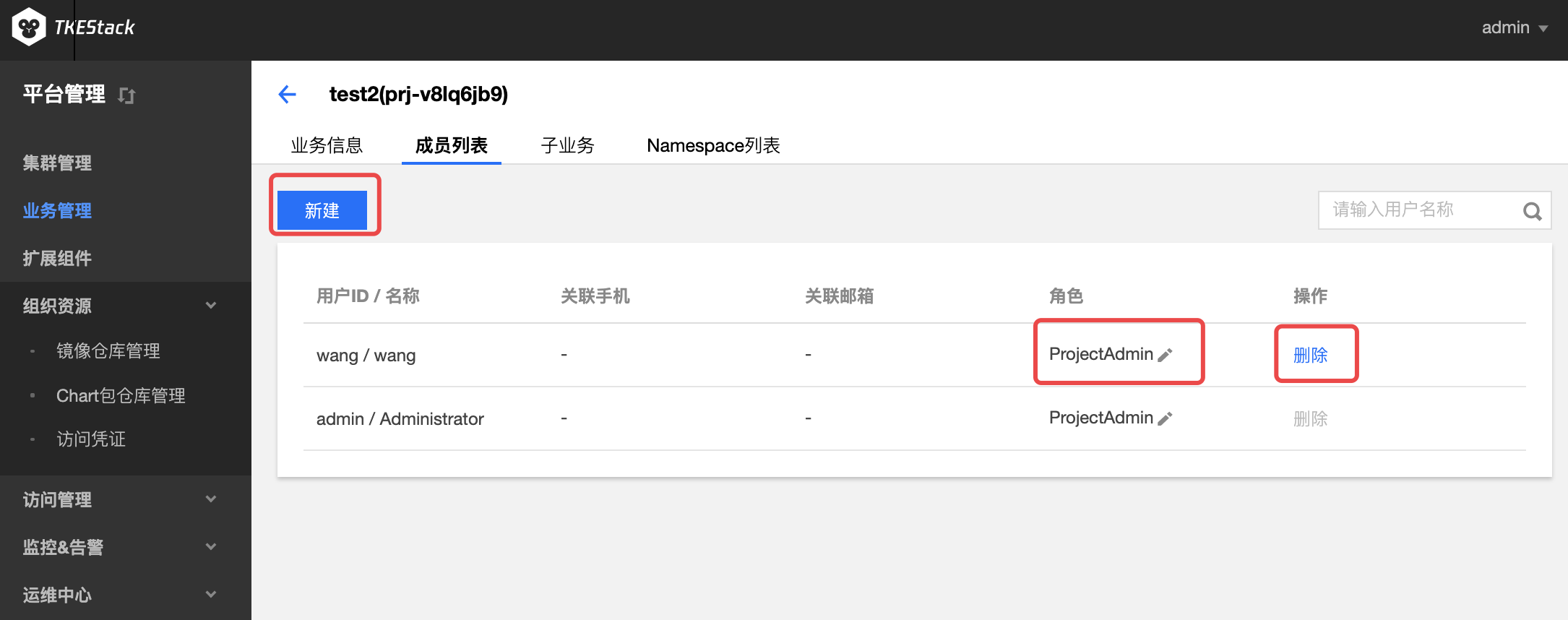
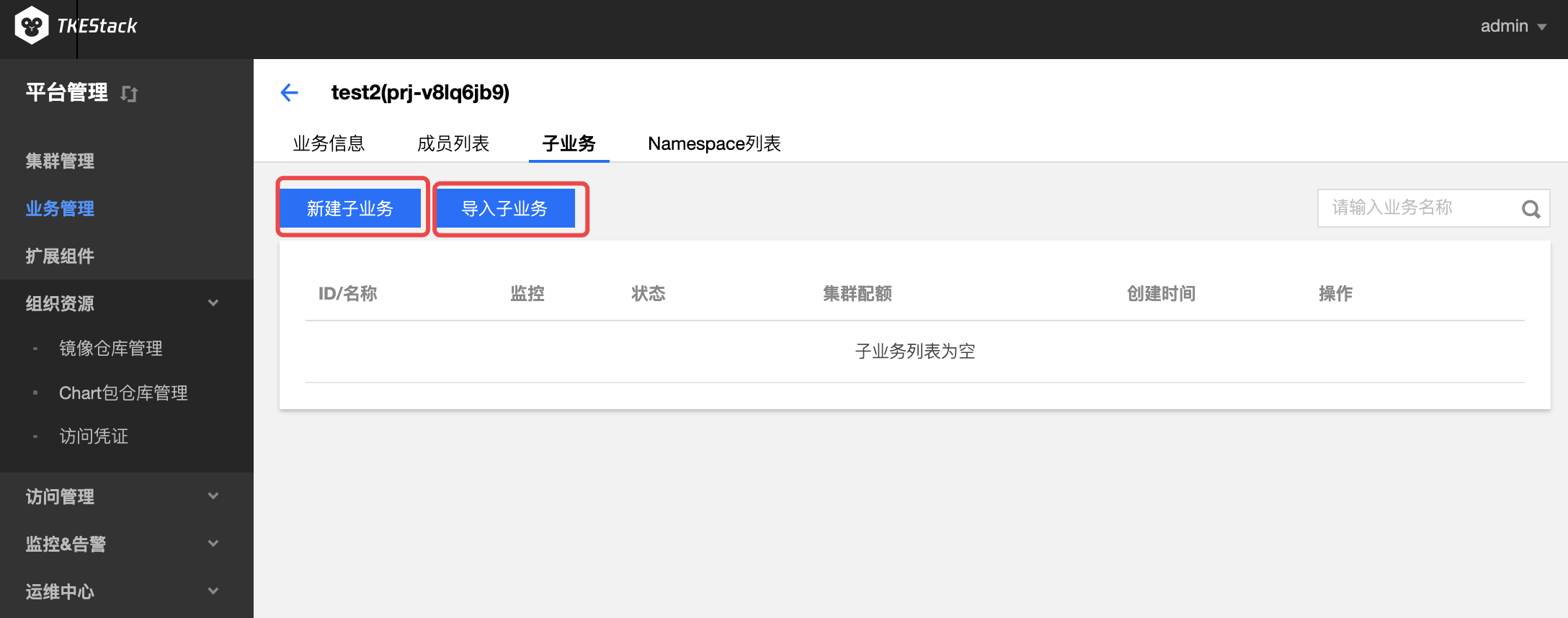
c. 子业务: 在这里可以新建本业务的子业务或通过导入子业务将已有业务变成本业务的子业务
d. 业务下Namespace列表: 这里可以管理业务下的Namespace
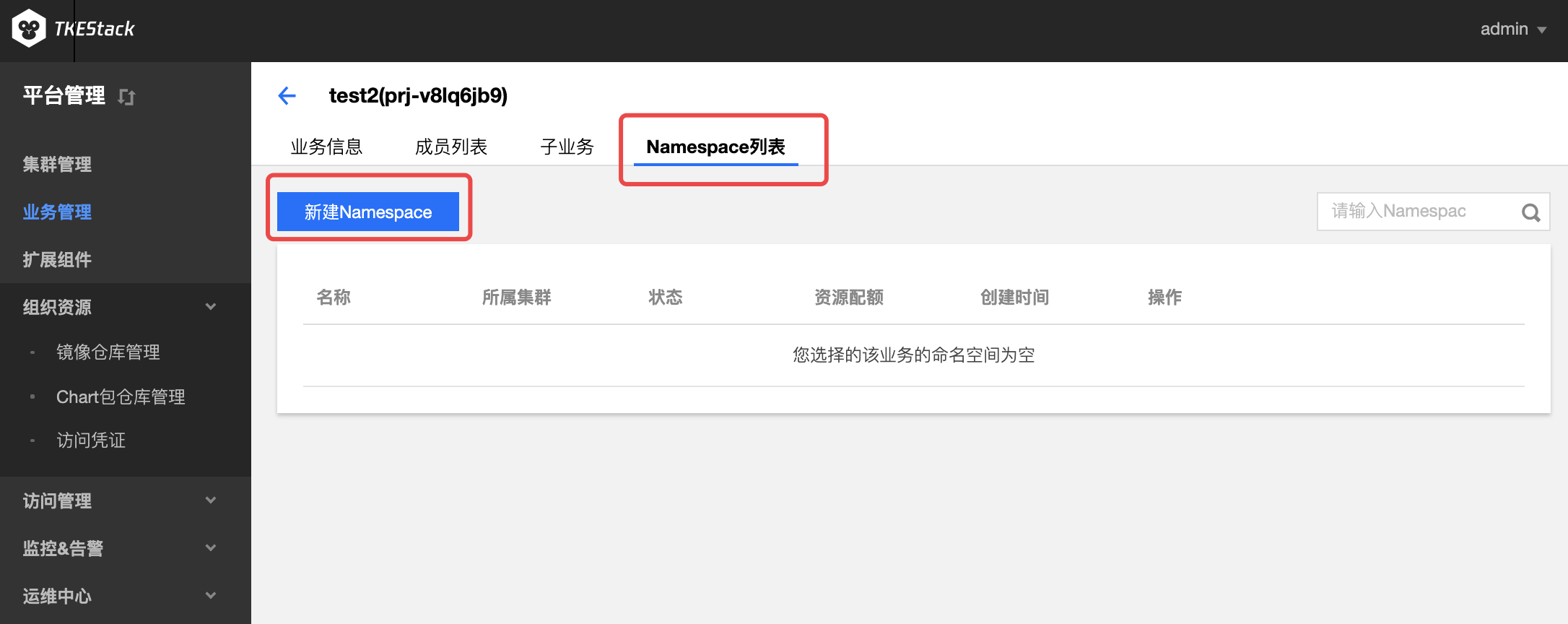
单击【新建Namespace】。在“新建Namespace”页面中,填写相关信息。如下图所示:
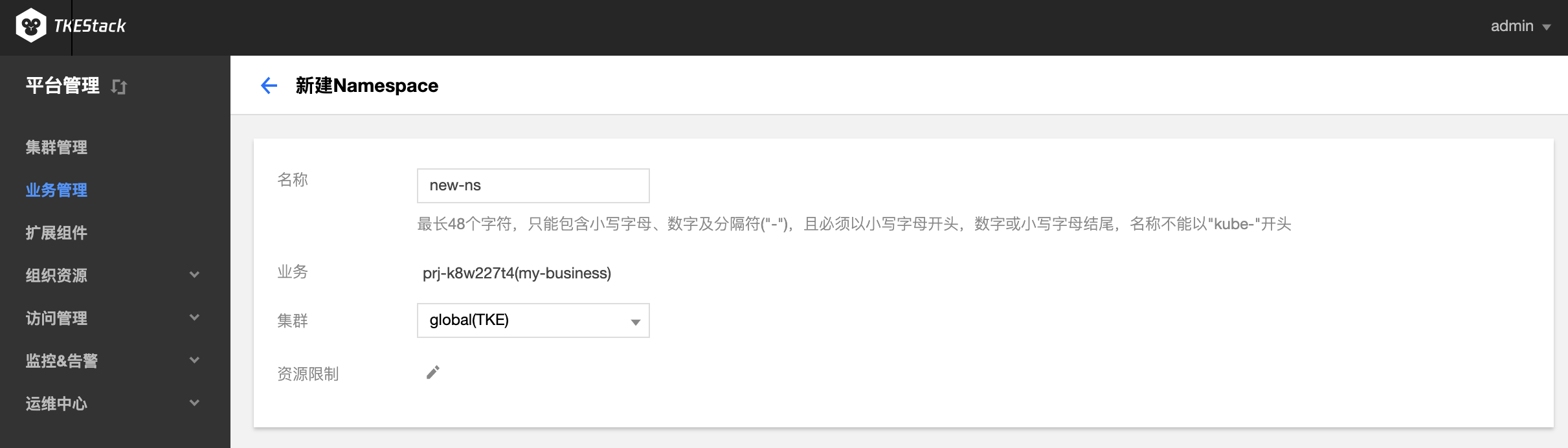
名称:不能超过63个字符,这里以
new-ns为例 集群:
my-business业务中的集群,这里以global集群为例 资源限制*:这里可以限制当前命名空间下各种资源的使用量,可以不设置。
2.4 - 扩展组件
扩展组件
概念
这里用户可以管理集群扩展组件。
操作步骤
创建组件
- 登录 TKEStack。
- 切换至 【平台管理】控制台,选择【扩展组件】页面。
- 选择需要安装组件的集群,点击【新建】按钮。如下图所示:

注意:此页面右边的【删除】按钮可以删除安装了的组件
- 在弹出的扩展组件列表里,选择要安装的组件。如下图所示:

注意:如果选择的是PersistentEvent,需要在下方输入地址和索引。
- 单击【完成】。
2.4.1 - TApp 介绍
TApp 介绍
Kubernetes 现有应用类型(如:Deployment、StatefulSet等)无法满足很多非微服务应用的需求。比如:操作(升级、停止等)应用中的指定 Pod;应用支持多版本的 Pod。如果要将这些应用改造为适合于这些 Workload 的应用,需要花费很大精力,这将使大多数用户望而却步。
为解决上述复杂应用管理场景,TKEStack 基于 Kubernetes CRD 开发了一种新的应用类型 TApp,它是一种通用类型的 Workload,同时支持 service 和 batch 类型作业,满足绝大部分应用场景,它能让用户更好的将应用迁移到 Kubernetes 集群。
TApp 架构
TAPP 其结构定义见 TAPP struct。TApp Controller 是 TApp 对应的Controller/operator,它通过 kube-apiserver 监听 TApp、Pod 相关的事件,根据 TApp 的 spec 和 status 进行相应的操作:创建、删除pod等。

TApp 使用场景
Kubernetes 凭借其强大的声明式 API、丰富的特性和可扩展性,逐渐成为容器编排领域的霸主。越来越多的用户希望使用 Kubernetes,将现有的应用迁移到 Kubernetes 集群,但 Kubernetes 现有 Workload(如:Deployment、StatefulSet等)无法满足很多非微服务应用的需求,比如:操作(升级、停止等)应用中的指定 Pod、应用支持多版本的 Pod。如果要将这些应用改造为适合于这些 Workload的应用,需要花费很大精力,这将使大多数用户望而却步。
腾讯有着多年的容器编排经验,基于 Kuberentes CRD(Custom Resource Definition,使用声明式API方式,无侵入性,使用简单)开发了一种新的 Workload 类型 TApp,它是一种通用类型的 Workload,同时支持 service 和 batch 类型作业,满足绝大部分应用场景,它能让用户更好的将应用迁移到 Kubernetes 集群。如果用 Kubernetes 的 Workload 类比,TAPP ≈ Deployment + StatefulSet + Job ,它包含了 Deployment、StatefulSet、Job 的绝大部分功能,同时也有自己的特性,并且和原生 Kubernetes 相同的使用方式完全一致。经过这几年用户反馈, TApp 也得到了逐渐的完善。
TApp 特点
- 同时支持 service 和 batch 类型作业。通过 RestartPolicy 来对这两种作业进行区分。RestartPolicy值有三种:RestartAlways、Never、OnFailure
- RestartAlways:表示 Pod 会一直运行,如果结束了也会被重新拉起(适合 service 类型作业)
- Never:表示 Pod 结束后就不会被拉起了(适合 batch 类型作业)
- OnFailure:表示 Pod 结束后,如果 exit code 非0,将会被拉起,否则不会(适合 batch 类型作业)
- 固定ID:每个实例(Pod)都有固定的 ID(0, 1, 2 … N-1,其中N为实例个数),它们的名字由 TApp 名字+ID 组成,因此名字也是唯一的。 有了固定的ID和名字后,我们便可以实现如下能力:
- 将实例用到的各种资源(将实例用到的存储资源(如:云硬盘),或者是IP)和实例一一对应起来,这样即使实例发生迁移,实例对应的各种资源也不会变
- 通过固定 ID,我们可以为实例分配固定的 IP(float ip)。
- 唯一的实例名字还可用来跟踪实例完整的生命周期,对于同一个实例,可以由于机器故障发生了迁移、重启等操作,虽然不是一个 Pod 了,但是我们用实例 ID 串联起来,就获得了实例真正的生命周期的跟踪,对于判断业务和系统是否正常服务具有特别重要的意义
- 操作指定实例:有了固定的 ID,我们就能操作指定实例。我们遵循了 Kubernetes 声明式的 API,在 spec 中 statuses 记录实例的目标状态, instances 记录实例要使用的 template,用于停止、启动、升级指定实例。
- 支持多版本实例:在 TApp spec 中,不同的实例可以指定不同的配置(image、resource 等)、不同的启动命令等,这样一个应用可以存在多个版本实例。
- 原地更新(in place update):Kubernetes 的更新策略是删除旧 Pod,新建一个 Pod,然后调度等一系列流程,才能运行起来,而且 Pod原先的绑定的资源(本地磁盘、IP 等)都会变化。TApp 对此进行了优化:如果只修改了 container 的 image,TApp 将会对该 Pod 进行本地更新,原地重启受影响的容器,本地磁盘不变,IP 不变,最大限度地降低更新带来的影响,这能极大地减少更新带来的性能损失以及服务不可用。
- 云硬盘:云硬盘的底层由分布式存储 Ceph 支持,能很好地支持有状态的作业。在实例发生跨机迁移时,云硬盘能跟随实例一起迁移。TApp 提供了多种云硬盘类型供选择。
- 多种升级发布方式:TApp除了支持常规的蓝绿布署、滚动发布、金丝雀部署等升级发布方式,还有其特有的升级发布方式:用户可以指定升级任意的实例。
- 自动扩缩容:根据 CPU/MEM/用户自定义指标对 TAPP 进行自动扩缩容。 除了自动扩缩容,我们还开发了周期性扩缩容 CronHPA 支持对 TApp 等(包括 Kubernetes 原生的 Deployment 和 StatefulSet)进行周期性扩缩容,支持 CronTab 语法格式,满足对资源使用有周期性需求的业务。
- Gang scheduling:有些应用必须要等到获取到资源能运行的实例达到一定数量后才开始运行,TApp 提供的 Gang scheduling 正是处理这种情况的。

部署在集群内 kubernetes 对象
在集群内部署 TApp Add-on , 将在集群内部署以下 kubernetes 对象
| kubernetes 对象名称 | 类型 | 默认占用资源 | 所属Namespaces |
|---|---|---|---|
| tapp-controller | Deployment | 每节点1核CPU, 512MB内存 | kube-system |
| tapps.apps.tkestack.io | CustomResourceDefinition | / | / |
| tapp-controller | ServiceAccount | / | kube-system |
| tapp-controller | Service | / | kube-system |
| tapp-controller | ClusterRoleBinding(ClusterRole/cluster-admin) | / | / |
TApp 使用方法
安装 TApp 组件
- 登录 TKEStack
- 切换至 平台管理 控制台,选择扩展组件页面
- 选择需要安装组件的集群,点击【新建】按钮。如下图所示:

- 在弹出的扩展组件列表里,滑动列表窗口找到tapp组件。如下图所示:

单击【完成】
安装完成后会在刚刚安装了 TApp 扩展组件的集群里 【工作负载】下面出现【TApp】,如下图所示:

使用 TApp 组件
在 TKEStack 控制台上使用 TApp 使用请参考:TApp Workload
对 TApp 架构和命令行使用请参考:TApp Repository
参考
手动部署 TApp
git clone https://github.com/tkestack/tapp.git
cd tapp
make build
bin/tapp-controller --kubeconfig=$HOME/.kube/config
原地升级
修改 spec.templatePool.{templateName}.spec.containers.image 的值实现原地升级。
挂在存储卷后的 Pod 依旧在 image 升级的时候没有任何影响,同时 PVC 也没有改变,唯一改变的只有镜像本身。
部分关键字解释
| 关键字 | 作用 |
|---|---|
| spec.templatePool | 模版池 |
| spec.templates | 以键值对(Pod 序号:模板池中的模板名)的形式具体声明每一个 Pod 的状态 |
| spec.template 等价于 spec.DefaultTemplateName | 默认模板(在spec.templates中没有定义的 Pod 序号将使用该模板) |
| updateStrategy.inPlaceUpdateStrategy | 原地升级策略 |
| spec.updateStrategy | 保留旧版本 Pod 的数量,默认为 0,类似于灰度发布 |
| spec.updateStrategy.template | 要设置 maxUnavailable 值的 template 名 |
| spec.updateStrategy.maxUnavailable | 最大的不可用 Pod 数量(默认为1,可设置成一个自然数,或者一个百分比,例如 50%) |
| spec.statuses | 明确 Pod 的状态,TApp 会实现该状态 |
apiVersion: apps.tkestack.io/v1
kind: TApp
metadata:
name: example-tapp
spec:
replicas: 3
# 默认模板
template:
metadata:
labels:
app: example-tapp
spec:
containers:
- name: nginx
image: nginx:latest
# 模板池
templatePool:
# 模板池中的模板
"test2":
metadata:
labels:
app: example-tapp
spec:
containers:
- name: nginx
image: nginx:1.7.9
# 要使用模板池中模板的 Pod
templates:
# Pod 序号:模板池中的模板
"1": "test2"
"2": "test2"
# 更新策略
updateStrategy:
# 更新指定模板。test2该模板有过修改,或者是在模板池里新增的,都可以通过 updateStrategy 设置模板来进行滚动更新
template: test2
# 使用该模板的 Pod 在更新时最大不可用的数量
maxUnavailable: 1
# 明确 Pod 的状态,TApp 会实现该状态
statuses:
# 编号为1的 Pod 将被 Kill
"1": "Killed"
2.4.2 - CronHPA 介绍
CronHPA 介绍
Cron Horizontal Pod Autoscaler(CronHPA) 可让用户利用 CronTab 实现对负载(Deployment、StatefulSet、TApp 这些支持扩缩容的资源对象)定期自动扩缩容。
CronTab 格式说明如下:
# 文件格式说明
# ——分钟(0 - 59)
# | ——小时(0 - 23)
# | | ——日(1 - 31)
# | | | ——月(1 - 12)
# | | | | ——星期(0 - 6)
# | | | | |
# * * * * *
CronHPA 定义了一个新的 CRD,cron-hpa-controller 是该 CRD 对应的 Controller/operator,它解析 CRD 中的配置,根据系统时间信息对相应的工作负载进行扩缩容操作。
CronHPA 使用场景
以游戏服务为例,从星期五晚上到星期日晚上,游戏玩家数量暴增。如果可以将游戏服务器在星期五晚上扩大规模,并在星期日晚上缩放为原始规模,则可以为玩家提供更好的体验。这就是游戏服务器管理员每周要做的事情。
其他一些服务也会存在类似的情况,这些产品使用情况会定期出现高峰和低谷。CronHPA 可以自动化实现提前扩缩 Pod,为用户提供更好的体验。
部署在集群内 kubernetes 对象
在集群内部署 CronHPA Add-on , 将在集群内部署以下 kubernetes 对象:
| kubernetes 对象名称 | 类型 | 默认占用资源 | 所属 Namespaces |
|---|---|---|---|
| cron-hpa-controller | Deployment | 每节点1核 CPU, 512MB内存 | kube-system |
| cronhpas.extensions.tkestack.io | CustomResourceDefinition | / | / |
| cron-hpa-controller | ClusterRoleBinding(ClusterRole/cluster-admin) | / | / |
| cron-hpa-controller | ServiceAccount | / | kube-system |
CronHPA 使用方法
安装 CronHPA
- 登录 TKEStack
- 切换至【平台管理】控制台,选择【扩展组件】页面
- 选择需要安装组件的集群,点击【新建】按钮,如下图所示:

- 在弹出的扩展组件列表里,滑动列表窗口找到 CronHPA 组件
- 单击【完成】
在控制台上使用 CronHPA
TKEStack 已经支持在页面多处位置为负载配置 CronHPA
- 新建负载页(负载包括Deployment、StatefulSet、TApp)这里新建负载时将会同时新建与负载同名的 CronHPA 对象:

每条触发策略由两条字段组成
- Crontab :例如 “0 23 * * 5"表示每周五23:00,详见crontab
- 目标实例数 :设置实例数量
- 自动伸缩的 CronHPA 列表页。此处可以查看/修改/新建 CronHPA:

通过 YAML 使用 CronHPA
创建 CronHPA 对象
示例1:指定 Deployment 每周五20点扩容到60个实例,周日23点缩容到30个实例
apiVersion: extensions.tkestack.io/v1
kind: CronHPA
metadata:
name: example-cron-hpa # CronHPA 名
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment # CronHPA 操作的负载类型
name: demo-deployment # CronHPA 操作的负载类型名
crons:
- schedule: "0 20 * * 5" # Crontab 语法格式
targetReplicas: 60 # 负载副本(Pod)的目标数量
- schedule: "0 23 * * 7"
targetReplicas: 30
示例2:指定 Deployment 每天8点到9点,19点到21点扩容到60,其他时间点恢复到10
apiVersion: extensions.tkestack.io/v1
kind: CronHPA
metadata:
name: web-servers-cronhpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: web-servers
crons:
- schedule: "0 8 * * *"
targetReplicas: 60
- schedule: "0 9 * * *"
targetReplicas: 10
- schedule: "0 19 * * *"
targetReplicas: 60
- schedule: "0 21 * * *"
targetReplicas: 10
查看已有 CronHPA
# kubectl get cronhpa
NAME AGE
example-cron-hpa 104s
# kubectl get cronhpa example-cron-hpa -o yaml
apiVersion: extensions.tkestack.io/v1
kind: CronHPA
...
spec:
crons:
- schedule: 0 20 * * 5
targetReplicas: 60
- schedule: 0 23 * * 7
targetReplicas: 30
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: demo-deployment
删除已有 CronHPA
kubectl delete cronhpa example-cron-hpa
CronHPA 项目请参考 CronHPA Repository
2.4.3 - 监控组件
Prometheus
良好的监控环境为 TKEStack 高可靠性、高可用性和高性能提供重要保证。您可以方便为不同资源收集不同维度的监控数据,能方便掌握资源的使用状况,轻松定位故障。
TKEStack 使用开源的 Prometheus 作为监控组件,免去您部署和配置 Prometheus 的复杂操作,TKEStack 提供高可用性和可扩展性的细粒度监控系统,实时监控 CPU,GPU,内存,显存,网络带宽,磁盘 IO 等多种指标并自动绘制趋势曲线,帮助运维人员全维度的掌握平台运行状态。
TKEStack 使用 Prometheus 的架构和原理可以参考 Prometheus 组件
指标具体含义可参考:监控 & 告警指标列表

TKEStack 通过 Prometheus 组件监控集群状态,Prometheus 组件通过 addon 扩展组件自动完成安装和配置,使用 InfluxDB,ElasticSearch 等存储监控数据。监控数据和指标融入到平台界面中以风格统一图表的风格展示,支持以不同时间,粒度等条件,查询集群,节点,业务,Workload 以及容器等多个层级的监控数据,全维度的掌握平台运行状态。
同时针对在可用性和可扩展性方面,支持使用 Thanos 架构提供可靠的细粒度监控和警报服务,构建具有高可用性和可扩展性的细粒度监控能力。
安装 Prometheus
Prometheus 为 TKEStack 扩展组件,需要在集群的 【基本信息】 页下面开启 “监控告警”。

集群监控
- 登录 TKEStack
- 切换至【平台管理】控制台,选择【集群管理】
- 点击【监控】图标,如下图所示:

- 监控数据展示
- 通过下图中的1可以选择监控数据时间段
- 通过下图中的2可以选择统计粒度,以下图中“APIServer时延”为例,下图中的每个数据表示前1分钟“APIServer时延”平均数

- 上下滑动曲线图可以获得更多监控指标
- 点击曲线图,会弹出具体时间点的具体监控数据

指标具体含义可参考:监控 & 告警指标列表
节点监控
- 登录 TKEStack
- 切换至【平台管理】控制台,选择【集群管理】
- 点击【集群 ID】 -> 【节点管理】->【节点】->【监控】图标,如下图所示:

具体查看方式和集群监控完全一致
指标具体含义可参考:监控 & 告警指标列表
此处还可以查看节点下的 Pod 监控
- 如下图所示,对比维度可选择 节点 或 Pod
- 选择 Pod ,需要在其右侧选择 Pod 所属节点

节点下的 Pod & Container 监控
有两种方式
- 节点监控 下选择 Pod 进行监控
- 在节点列表里,点击节点名,进入节点的 Pod 管理页,如下图所示,点击上方的【监控】按钮,实现对节点下的 Pod 监控

注意:此处还可以查看节点下的 Container 监控
- 如下图所示,对比维度可选择 Pod 或 Container
- 选择 Container ,需要在其右侧选择 Container 所属 Pod

指标具体含义可参考:监控 & 告警指标列表
负载监控
登录 TKEStack
切换至【平台管理】控制台,选择【集群管理】
点击【集群 ID】 -> 【工作负载】->【选择一种负载,例如 Deployment】->【监控】图标,如下图所示:
具体查看方式和集群监控完全一致
指标具体含义可参考:监控 & 告警指标列表
负载下 Pod & Container 监控
- 登录 TKEStack
- 切换至【平台管理】控制台,选择【集群管理】
- 点击【集群 ID】 -> 【工作负载】->【选择一种负载】,例如 Deployment】->【点击一个负载名】->【监控】图标,如下图所示:

注意:此处还可以查看负载下的 Container 监控
- 如下图所示,对比维度可选择 Pod 或 Container
- 选择 Container ,需要在其右侧选择 Container 所属 Pod 指标具体含义可参考:监控 & 告警指标列表

TKEStack 使用 Prometheus 的架构和原理可以参考 Prometheus 组件
2.4.4 - LogAgent 介绍
日志采集
LogAgent 介绍
TKESTack 通过 logagent 提供的集群内日志采集功能,支持将集群内服务或集群节点特定路径文件的日志发送至 Kafka、Elasticsearch 等消费端,支持采集容器标准输出日志,容器内文件日志以及主机内文件日志。更提供事件持久化、审计等功能,实时记录集群事件及操作日志记录,帮助运维人员存储和分析集群内部资源生命周期、资源调度、异常告警等情况。

TKEStack 老版本日志使用 LogCollector 扩展组件。LogAgent 用于替换 LogCollector,新版本统一用 LogAgent 完成日志采集功能。
日志收集功能需要为每个集群手动开启。日志收集功能开启后,日志收集组件 logagent 会在集群内以 Daemonset 的形式运行。用户可以通过日志收集规则配置日志的采集源和消费端,日志收集 Agent 会从用户配置的采集源进行日志收集,并将日志内容发送至用户指定的消费端。需要注意的是,使用日志收集功能需要您确认 Kubernetes 集群内节点能够访问日志消费端。
- 采集容器标准输出日志 :采集集群内指定容器的 Stderr 和 Stdout 日志。,采集到的日志信息将会以 JSON 格式输出到用户指定的消费端,并会自动附加相关的 Kubernetes metadata, 包括容器所属 Pod 的 label 和 annotation 等信息。
- 采集容器内文件日志 :采集集群内指定容器内文件路径的日志,用户可以根据自己的需求,灵活的配置所需的容器和路径,采集到的日志信息将会以 JSON 格式输出到用户指定的消费端, 并会附加相关的 Kubernetes metadata,包括容器所属 Pod 的 label 和 annotation 等信息。
- 采集主机内文件日志 :采集集群内所有节点的指定主机文件路径的日志,logagent 会采集集群内所有节点上满足指定路径规则的文件日志,以 JSON 格式输出到用户指定的输出端, 并会附加用户指定的 metadata,包括日志来源文件的路径和用户自定义的 metadata。
部署在集群内 kubernetes 对象
在集群内部署 logagent Add-on , 将在集群内部署以下 kubernetes 对象
| kubernetes 对象名称 | 类型 | 默认占用资源 | 所属Namespaces |
|---|---|---|---|
| logagent | DaemonSet | 每节点0.3核 CPU, 250MB 内存 | kube-system |
| logagent | ServiceAccount | kube-system |
使用日志采集服务
注意:日志采集对接外部 Kafka 或 Elasticsearch,该功能需要额外开启,位置在集群 基本信息 下面,点击开启“日志采集”服务。

业务管理侧
- 登录 TKEStack
- 切换至【业务管理】控制台,选择 【运维中心】->【日志采集】
- 选择相应【业务】和【命名空间】,单击【新建】按钮,如下图所示:

- 在“新建日志采集”页面填写日志采集信息,如下图所示:

- 收集规则名称: 输入规则名,1~63字符,只能包含小写字母、数字及分隔符("-"),且必须以小写字母开头,数字或小写字母结尾
- 业务: 选择所属业务(业务管理侧才会出现)
- 集群: 选择所属集群(平台管理侧才会出现)
- 类型: 选择采集类型
- 容器标准输出: 容器 Stderr 和 Stdout 日志信息采集
- 日志源: 可以选择所有容器或者某个 Namespace 下的所有容器/工作负载
- 所有容器: 所有容器
- 指定容器: 某个 Namespace 下的所有容器或者工作负载
- 日志源: 可以选择所有容器或者某个 Namespace 下的所有容器/工作负载
- 容器文件路径: 容器内文件内容采集
日志源: 可以采集具体容器内的某个文件路径下的文件内容
- 工作负载选项: 选择某个 Namespace 下的某种工作负载类型下的某个工作负载
- 配置采集路径: 选择某个容器下的某个文件路径
- 文件路径若输入
stdout,则转为容器标准输出模式 - 可配置多个路径。路径必须以
/开头和结尾,文件名支持通配符(*)。文件路径和文件名最长支持63个字符 - 请保证容器的日志文件保存在数据卷,否则收集规则无法生效,详见指定容器运行后的日志目录
- 节点文件路径: 收集节点上某个路径下的文件内容,不会重复采集,因为采集器会记住之前采集过的日志文件的位点,只采集增量部分
- 日志源: 可以采集具体节点内的某个文件路径下的文件内容
- 收集路径: 节点上日志收集路径。路径必须以
/开头和结尾,文件名支持通配符(*)。文件路径和文件名最长支持63个字符 - metadata: key:value 格式,收集的日志会带上 metadata 信息上报给消费端
- 收集路径: 节点上日志收集路径。路径必须以
- 日志源: 可以采集具体节点内的某个文件路径下的文件内容
- 容器标准输出: 容器 Stderr 和 Stdout 日志信息采集
- 消费端: 选择日志消费端
- Kafka:
- 访问地址: Kafka IP 和端口
- 主题(Topic): Kafka Topic 名
- Elasticsearch:
Elasticsearch 地址: ES 地址,如:http://190.0.0.1:200
注意:当前只支持未开启用户登录认证的 ES 集群
索引: ES索引,最长60个字符,只能包含小写字母、数字及分隔符("-"、"_"、"+"),且必须以小写字母开头
- Kafka:
- 单击【完成】按钮
平台管理侧
在平台管理侧也支持日志采集规则的创建,创建方式和业务管理处相同。详情可点击平台侧的日志采集。
指定容器运行后的日志目录
LogAgent 除了支持日志规则的创建,也支持指定容器运行后的日志目录,可实现日志文件展示和下载。
前提:需要在创建负载时挂载数据卷,并指定日志目录

创建负载以后,在容器内的/data/logdir目录下的所有文件可以展示并下载,例如我们在容器的/data/logdir下新建一个名为a.log的文件,如果有内容的话,也可以在这里展示与下载:

2.4.5 - GPUManager 介绍
GPUManager 介绍
GPUManager 提供一个 All-in-One 的 GPU 管理器, 基于 Kubernets Device Plugin 插件系统实现,该管理器提供了分配并共享 GPU,GPU 指标查询,容器运行前的 GPU 相关设备准备等功能,支持用户在 Kubernetes 集群中使用 GPU 设备。
GPU-Manager 包含如下功能:
- 拓扑分配:提供基于 GPU 拓扑分配功能,当用户分配超过1张 GPU 卡的应用,可以选择拓扑连接最快的方式分配GPU设备
- GPU 共享:允许用户提交小于1张卡资源的的任务,并提供 QoS 保证
- 应用 GPU 指标的查询:用户可以访问主机的端口(默认为5678)的
/metrics路径,可以为 Prometheus 提供 GPU 指标的收集功能,/usage路径可以提供可读性的容器状况查询
GPU-Manager 使用场景
在 Kubernetes 集群中运行 GPU 应用时,可以解决 AI 训练等场景中申请独立卡造成资源浪费的情况,让计算资源得到充分利用。
GPU-Manager 限制条件
该组件基于 Kubernetes DevicePlugin 实现,只能运行在支持 DevicePlugin 的 kubernetes版本(Kubernetes 1.10 之上的版本)
使用 GPU-Manager 要求集群内包含 GPU 机型节点
TKEStack 的 GPU-Manager 将每张 GPU 卡视为一个有100个单位的资源
特别注意:
- 当前仅支持 0-1 的小数张卡,如 20、35、50;以及正整数张卡,如200、500等;不支持类似150、250的资源请求
- 显存资源是以 256MiB 为最小的一个单位的分配显存
部署在集群内 kubernetes 对象
在集群内部署 GPU-Manager,将在集群内部署以下 kubernetes 对象:
| kubernetes 对象名称 | 类型 | 建议预留资源 | 所属 Namespaces |
|---|---|---|---|
| gpu-manager-daemonset | DaemonSet | 每节点1核 CPU, 1Gi内存 | kube-system |
| gpu-quota-admission | Deployment | 1核 CPU, 1Gi内存 | kube-system |
GPU-Manager 使用方法
安装 GPU-Manager
集群部署阶段选择 vGPU,平台会为集群部署 GPU-Manager ,如下图新建独立集群所示,Global 集群的也是如此安装。

在节点安装 GPU 驱动
集群部署阶段添加 GPU 节点时有勾选 GPU 选项,平台会自动为节点安装 GPU 驱动,如下图所示:
注意:如果集群部署阶段节点没有勾选 GPU,需要自行在有 GPU 的节点上安装 GPU 驱动

工作负载使用 GPU
通过控制台使用
在安装了 GPU-Manager 的集群中,创建工作负载时可以设置 GPU 限制,如下图所示:
注意:
- 卡数只能填写 0.1 到 1 之间的两位小数或者是所有自然数,例如:0、0.3、0.56、0.7、0.9、1、6、34,不支持 1.5、2.7、3.54
- 显存只能填写自然数 n,负载使用的显存为 n*256MiB

通过 YAML 使用
如果使用 YAML 创建使用 GPU 的工作负载,提交的时候需要在 YAML 为容器设置 GPU 的使用资源。
- CPU 资源需要在 resource 上填写
tencent.com/vcuda-core - 显存资源需要在 resource 上填写
tencent.com/vcuda-memory
例1:使用1张卡的 Pod
apiVersion: v1
kind: Pod
...
spec:
containers:
- name: gpu
resources:
limits:
tencent.com/vcuda-core: 100
requests:
tencent.com/vcuda-core: 100
例2,使用 0.3 张卡、5GiB 显存的应用(5GiB = 20*256MB)
apiVersion: v1
kind: Pod
...
spec:
containers:
- name: gpu
resources:
limits:
tencent.com/vcuda-core: 30
tencent.com/vcuda-memory: 20
requests:
tencent.com/vcuda-core: 30
tencent.com/vcuda-memory: 20
GPU 监控数据查询
通过控制台查询
前提:在集群的【基本信息】页里打开“监控告警”
可以通过集群多个页面的监控按钮里查看到 GPU 的相关监控数据,下图以 集群管理 页对集群的监控为例:

通过后台手动查询
手动获取 GPU 监控数据方式(需要先安装 socat):
kubectl port-forward svc/gpu-manager-metric -n kube-system 5678:5678 &
curl http://127.0.0.1:5678/metric
结果示例:

GPUManager 项目请参考:GPUManager Repository
2.4.6 - CSIOperator 介绍
CSIOperator
CSIOperator 介绍
Container Storage Interface Operator(CSIOperator)用于部署和更新 Kubernetes 集群中的 CSI 驱动和外部存储组件。
CSIOperator 使用场景
CSIOperator 用于支持集群方便的使用存储资源,当前支持的存储插件包括 RBD、CephFS、TencentCBS 和 TencentCFS(TencentCFS 正在测试中)
- 其中 RBD 和 CephFS 主要用于部署在 IDC 环境的集群
- TencentCBS 和 TencentCFS 用于部署在腾讯云环境的集群
部署在集群内 kubernetes 对象
在集群内部署 CSIOperator,将在集群内部署以下 kubernetes 对象
| kubernetes 对象名称 | 类型 | 默认占用资源 | 所属 Namespaces |
|---|---|---|---|
| csi-operator | Deployment | 每节点0.2核 CPU, 256MB内存 | kube-system |
CSIOperator 使用方法
安装 CSIOperator
- 登录 TKEStack
- 切换至 【平台管理】控制台,选择 【扩展组件】 页面
- 选择需要安装组件的集群,点击【新建】按钮。如下图所示:

- 在弹出的扩展组件列表里,滑动列表窗口找到 CSIOperator
- 单击【完成】进行安装
通过 CSIOperator 使用腾讯云存储资源
- 登录 TKEStack
- 切换至 【平台管理】控制台,选择 【集群管理】 页面,如下图1所示:
- 点击安装了 CSIOperator 组件的【集群ID】,进入要管理的集群,如下图2所示:
- 点击【YAML创建资源】,如下图3所示:

文件中指定各自存储插件镜像的名称,这里以
tencentcbs的 YAML 为例:(前提:需要拥有腾讯云账号)apiVersion: storage.tkestack.io/v1 kind: CSI metadata: name: tencentcbsv1 namespace: kube-system spec: driverName: com.tencent.cloud.csi.cbs version: "v1" parameters: secretID: "xxxxxx" secretKey: "xxxxxx"- secretID、secretKey 来源于 腾讯云控制台 -> 账号中心 -> 访问管理 -> 访问秘钥 -> API密钥管理
创建完 CSIOperator 的 CRD 对象,同时会为每个存储插件创建默认的 StorageClass 对象(tencentcbs 的 StorageClass 对象名为 cbs-basic-prepaid),如下图:

其 YAML 如下:

tencentcbs 的 provisioner 名称指定为:
com.tencent.cloud.csi.cbstencentcfs 的 provisioner 名称指定为:
com.tencent.cloud.csi.cfs,tencentcfs 仍在测试中,目前仅支持 tencentcbs对于磁盘类型(在 StorageClass 的
diskType中指定)和大小的限制:- 普通云硬(
CLOUD_BASIC)盘提供最小 100 GB 到最大 16000 GB 的规格选择,支持 40-100MB/s 的 IO 吞吐性能和 数百-1000 的随机 IOPS 性能 - 高性能云硬盘(
CLOUD_PREMIUM)提供最小 50 GB 到最大 16000 GB 的规格选择 - SSD 云硬盘(
CLOUD_SSD)提供最小 100 GB 到最大 16000 GB 的规格选择,单块 SSD 云硬盘最高可提供 24000 随机读写IOPS、260MB/s吞吐量的存储性能
- 普通云硬(
默认创建的磁盘类型为普通云硬盘,如果用户希望使用该 StorageClass,可以直接创建使用了该 StorageClass 的 PVC 对象:
apiVersion: v1 kind: PersistentVolumeClaim metadata: name: test-tencentcbs namespace: kube-system spec: accessModes: - ReadWriteOnce storageClassName: cbs-basic-prepaid resources: requests: storage: 10Gi
详情请见 CSIOperator Example
2.5 - 组织资源
组织资源
概念
这里用户可以管理镜像仓库和凭据。
2.5.1 - 镜像仓库管理
镜像仓库管理
镜像仓库概述
镜像仓库:用于存放 Docker 镜像,Docker 镜像可用于部署容器服务,每个镜像有特定的唯一标识(镜像的 Registry 地址+镜像名称+镜像 Tag)
镜像类型:目前镜像支持 Docker Hub 官方镜像和用户私有镜像
镜像生命周期:主要包含镜像版本的生成、上传和删除
新建命名空间
- 登录 TKEStack
- 切换至【平台管理】控制台,选择 【组织资源】->【镜像仓库管理】
- 点击【新建】按钮,如下图所示:

- 在弹出的“新建命名空间”页面,填写命名空间信息,如下图所示:

- 名称: 命名空间名字,不超过63字符
- 描述: 命名空间描述信息(可选)
- 权限类型: 选择命名空间权限类型
- 公有: 所有人均可访问该命名空间下的镜像
- 私有: 个人用户命名空间
- 单击【确认】按钮
删除命名空间
- 登录 TKEStack
- 切换至 【平台管理】控制台,选择 【组织资源】->【镜像仓库管理】。点击列表最右侧【删除】按钮,如下图所示:

镜像上传
- 登录 TKEStack
- 切换至 【平台管理】控制台,选择 【组织资源】->【镜像仓库管理】,查看命名空间列表,点击列表中命名空间【名称】,如下图所示:

此时进入了“镜像列表”页面,点击【镜像上传指引】按钮,如下图所示:
注意:此页面可以通过上传的镜像最右边的【删除】按钮来删除上传的镜像

- 根据指引内容,在物理节点上执行相应命令,如下图所示:

2.5.2 - Helm模板
应用功能是 TKEStack 集成的 Helm 3.0 相关功能,为您提供创建 helm chart、容器镜像、软件服务等各种产品和服务的能力。已创建的应用将在您指定的集群中运行,为您带来相应的能力。
模板
- 登录 TKEStack
- 切换至 【平台管理】控制台,选择 【组织资源】->【 Helm模板】,点击【模板】

- 所有模板:包含下列所有模板
- 用户模板:权限范围为“指定用户”的仓库下的所有模板
- 业务模板:权限范围为“指定业务”的仓库下的所有模板
- 公共模板:权限范围为“公共”的仓库下的所有模板
仓库
- 登录 TKEStack
- 切换至 【平台管理】控制台,选择 【组织资源】->【 Helm模板】,点击【仓库】
- 点击【新建】按钮,如下图所示:

- 在弹出的 “新建仓库” 页面,填写 仓库 信息,如下图所示:

仓库名称: 仓库名字,不超过60个字符
权限访问
- 指定用户:选择当前仓库可以被哪些平台的用户访问
- 指定业务:选择当前仓库可以被哪些平台的业务访问,业务下的成员对该仓库的访问权限在【业务管理】中完成
- 公共:平台所有用户都能访问该仓库
导入第三方仓库: 若已有仓库想导入 TKEStack 中使用,请勾选
- 第三方仓库地址:请输入第三方仓库地址
- 第三方仓库用户名:若第三方仓库开启了鉴权,需要输入第三方仓库的用户名
- 第三方仓库密码:若第三方仓库开启了鉴权,需要输入第三方仓库的密码
仓库描述: 请输入仓库描述,不超过255个字符
单击【确认】按钮
删除仓库
登录 TKEStack
切换至 【平台管理】控制台,选择 【组织资源】-> 【 Helm 模板】,点击【仓库】,查看 “helm模板仓库”列表
点击列表最右侧【删除】按钮,如下图所示:

Chart 上传指引
- 登录 TKEStack
- 切换至 【平台管理】控制台,选择 【组织资源】-> 【 Helm模板】,点击【仓库】,查看 “helm模板仓库”列表
- 点击列表最右侧【上传指引】按钮,如下图所示:

- 根据指引内容,在物理节点上执行相应命令,如下图所示:

同步导入仓库
- 登录 TKEStack
- 切换至 【平台管理】控制台,选择 【组织资源】->【 Helm模板】,点击【仓库】
- 点击导入仓库的【同步仓库】按钮,如下图所示:

2.5.3 - 访问凭证
访问凭证
这里用户可以管理自己的凭据,用来登陆平台创建的镜像仓库和应用仓库。
新建访问凭证
- 登录 TKEStack
- 切换至 【平台管理】控制台,选择 【组织资源】下的【访问凭证】,点击【新建】按钮,如下图所示:

- 在弹出创建访问凭证页面,填写凭证信息,如下图所示:

- 凭证描述: 描述当前凭证信息
- 过期时间: 填写过期时间,选择小时/分钟为单位
- 单击【确认】按钮
使用指引
- 登录 TKEStack
- 切换至 【平台管理】控制台,选择 【组织资源】下的【访问凭证】,点击【新建】按钮,如下图所示:

- 根据指引内容,在物理节点上执行相应命令
停用/启用/删除访问凭证
登录 TKEStack
切换至 【平台管理】控制台,选择 【组织资源】-> 【访问凭证】,查看“访问凭证”列表,单击列表右侧【禁用】/【启用】/【删除】按钮。如下图所示:
注意:点击【禁用】之后,【禁用】按钮就变成了【启用】

- 单击【确认】按钮
2.6 - 访问管理
2.6.1 - 策略管理
策略管理
平台策略
新建策略
- 登录 TKEStack
- 切换至【平台管理】控制台,选择【访问管理】->【策略管理】
- 点击【新建】按钮,如下图所示:

- 在弹出的新建策略窗口输入策略信息。如下图所示:

- 策略名称: 长度需要小于256个字符
- 效果: 策略动作,允许/拒绝
- 服务: 选择策略应用于哪项服务
- 操作: 选择对应服务的各项操作权限
- 资源: 输入资源label,支持模糊匹配,策略将应用于匹配到的资源
- 描述: 输入策略描述
- 单击【保存】按钮
关联用户和用户组
- 登录 TKEStack
- 切换至【平台管理】控制台,选择【访问管理】->【策略管理】,查看策略列表
- 点击列表中最右侧【关联用户】或【关联用户组】按钮,如下图所示:

- 在弹出的关联用户窗口选择用户或用户组,这里以用户组为例。如下图所示:

- 单击【确定】按钮
编辑策略基本信息
- 登录 TKEStack
- 切换至【平台管理】控制台,选择【访问管理】->【策略管理】,查看策略列表
- 点击列表中的策略名称,如下图所示:

- 在策略基本信息页面,单击 “基本信息” 旁的【编辑】按钮,如下图所示:

- 在弹出的信息框内编辑策略名称和描述
- 单击【保存】按钮
业务策略
新建策略
- 登录 TKEStack
- 切换至【平台管理】控制台,选择【访问管理】->【策略管理】->【业务策略】
- 点击【新建】按钮,如下图所示:

- 在弹出的新建策略窗口输入策略信息,如下图所示:

- 策略名称: 长度需要小于256个字符
- 效果: 策略动作,允许/拒绝
- 服务: 选择策略应用于哪项服务
- 操作: 选择对应服务的各项操作权限
- 资源: 输入资源label,支持模糊匹配,策略将应用于匹配到的资源
- 描述: 输入策略描述
- 单击【保存】按钮
编辑策略基本信息
- 登录 TKEStack
- 切换至【平台管理】控制台,选择【访问管理】->【策略管理】,查看策略列表
- 点击列表中的策略名称,如下图所示:

- 在策略基本信息页面,单击 “基本信息” 旁的【编辑】按钮,如下图所示:

- 在弹出的信息框内编辑策略名称和描述
- 单击【保存】按钮
- 此页面还可以编辑策略语法
2.6.2 - 用户管理
用户管理
用户
新建用户
- 登录 TKEStack
- 切换至【平台管理】控制台,选择【访问管理】->【用户管理】
- 点击【新建】按钮,如下图所示:

- 在弹出的添加用户窗口填写用户信息,如下图所示:

- 用户账号: 长度3~32位字符,小写字母或数字开头结尾,中间包含小写字母、数字、-
- 用户名称: 长度需小于256字符,用户名称会显示在页面右上角
- 用户密码: 10~16位字符,需包括大小写字母及数字
- 确认密码: 再次输入密码
- 手机号: 输入用户手机号
- 邮箱: 输入用户邮箱
- 平台角色:
- 管理员: 平台预设角色,允许访问和管理所有平台和业务的功能和资源
- 平台用户: 平台预设角色,允许访问和管理大部分平台功能,可以新建集群及业务
- 租户: 平台预设角色,不绑定任何平台权限,仅能登录
- 自定义: 通过勾选下面的策略给用户自定义独立的权限
- 单击【保存】按钮
修改密码
- 登录 TKEStack
- 切换至【平台管理】控制台,选择【访问管理】->【用户管理】,查看用户列表
- 点击用户列表最右侧的【修改密码】按钮,如下图所示:

- 在弹出的修改密码窗口里输入新的密码并确认,如下图所示:

- 单击【保存】按钮
编辑用户基本信息
- 登录 TKEStack
- 切换至【平台管理】控制台,选择【访问管理】->【用户管理】,查看用户列表
- 点击列表中的用户名称,如下图所示:

- 在用户基本信息页面,单击 基本信息 旁的【编辑】按钮,如下图所示:

- 在弹出的用户信息框内编辑用户信息
- 单击【保存】按钮
- 此页面下面可以查看当前用户的 已管理策略、已关联用户组 和 已关联角色
用户组
新建用户组
- 登录 TKEStack
- 切换至【平台管理】控制台,选择【访问管理】->【用户管理】-> 【用户组】
- 点击【新建】按钮,如下图所示:

- 在弹出的添加用户窗口填写用户信息,如下图所示:

- 用户组名称: 长度需小于60位字符,小写字母或数字开头结尾,中间包含小写字母、数字、-
- 用户组描述: 长度需小于255字符
- 关联用户: 点按用户ID/名称前面的方框可以关联相应的用户,支持全选和按住shift键多选
- 平台角色:
- 管理员: 平台预设角色,允许访问和管理所有平台和业务的功能和资源
- 平台用户: 平台预设角色,允许访问和管理大部分平台功能,可以新建集群及业务
- 租户: 平台预设角色,不绑定任何平台权限,仅能登录
- 自定义: 通过勾选下面的策略给用户自定义独立的权限
- 单击【提交】按钮
编辑用户组基本信息
- 登录 TKEStack
- 切换至【平台管理】控制台,选择【访问管理】->【用户组管理】,查看用户组列表
- 点击列表中的用户组名称,如下图1所示:

此界面也可以更改关联用户,如上图中的2所示,和 新建用户组 ->添加用户组 中一样的步骤来关联用户
- 在用户组基本信息页面,单击 基本信息 旁的【编辑】按钮,如下图1所示:

在弹出的信息框内可以编辑 用户组名称 和 用户组描述,此时会出现【提交】按钮,点击后可更改用户组基本信息。
如上图中的2所示,此界面也可以更改关联用户,点击蓝色【关联用户】按钮后,和 新建用户组 ->添加用户组 中一样的操作来关联用户。这里还可以点击查看【已关联角色】和【已关联策略】
删除用户组
- 登录 TKEStack
- 切换至【平台管理】控制台,选择【访问管理】->【用户组管理】,查看用户组列表
- 点击用户组列表最右侧的【删除】按钮,如下图所示:

- 在弹出的确认删除窗口,单击【确认】
2.7 - 监控&告警
2.7.1 - 告警记录
概念
这里可以查看历史告警记录
查看历史告警记录
- 登录 TKEStack
- 切换至【平台管理】控制台,选择 【监控&告警】->【告警记录】查看“历史告警记录”列表,如下图所示:

2.7.2 - 通知设置
通知设置
概念
这里用户配置平台通知
通知渠道
新建通知渠道
- 登录 TKEStack
- 切换至【平台管理】控制台,选择 【监控&告警】->【通知设置】->【通知渠道】,查看“通知渠道”列表
- 点击【新建】按钮,如下图所示:

- 在“新建通知渠道”页面填写渠道信息,如下图所示:

- 名称: 填写渠道名称
- 渠道: 选择渠道类型,输入渠道信息
- 邮件: 邮件类型
- email: 邮件发送放地址
- password: 邮件发送方密码
- smtpHost: smtp IP 地址
- smtpPort: smtp 端口
- tls: 是否使用tls加密
- 短信: 短信方式
- appKey: 短信发送方的 appKey
- sdkAppID: sdkAppID
- extend: extend 信息
- 微信公众号: 微信公众号方式
- appID: 微信公众号 appID
- appSecret: 微信公众号 appSecret
- Webhook: Webhook 方式
- URL:Webhook 的 URL
- Headers: 自定义 Header
- 邮件: 邮件类型
- 单击【保存】按钮
编辑通知渠道
- 登录 TKEStack
- 切换至【平台管理】控制台,选择 【监控&告警】->【通知设置】->【通知渠道】,查看“通知渠道”列表
- 单击渠道名称,如下图所示:

- 在“基本信息”页面,单击【基本信息】右侧的【编辑】按钮,如下图所示:

- 在“更新渠道通知”页面,编辑渠道信息
- 单击【保存】按钮
删除通知渠道
- 登录 TKEStack
- 切换至【平台管理】控制台,选择 【监控&告警】->【通知设置】->【通知渠道】,查看“通知渠道”列表
- 选择要删除的渠道,点击【删除】按钮,如下图所示:

- 单击删除窗口的【确定】按钮
通知模板
新建通知模版
- 登录 TKEStack
- 切换至【平台管理】控制台,选择 【监控&告警】->【通知设置】->【通知模板】,查看“通知模板”列表
- 点击【新建】按钮,如下图所示:

- 在“新建通知模版”页面填写模版信息,如下图所示:

- 名称: 模版名称
- 渠道: 选择已创建的渠道
- body: 填写消息 body
- header: 填写消息 header
- 单击【保存】按钮
编辑通知模版
- 登录 TKEStack
- 切换至【平台管理】控制台,选择 【监控&告警】->【通知设置】->【通知模板】,查看“通知模板”列表
- 单击模版名称,如下图所示:

- 在基本信息页面,单击【基本信息】右侧的【编辑】按钮,如下图所示:

- 在“更新通知模版”页面,编辑模版信息
- 单击【保存】按钮
删除通知模版
- 登录 TKEStack
- 切换至【平台管理】控制台,选择 【监控&告警】->【通知设置】->【通知模板】,查看"通知模板"列表
- 选择要删除的模版,点击【删除】按钮,如下图所示:

- 单击删除窗口的【确定】按钮
接收人
新建接收人
- 登录 TKEStack
- 切换至【平台管理】控制台,选择 【监控&告警】->【通知设置】->【接收人】,查看"接收人"列表
- 点击【新建】按钮,如下图所示:

- 在“新建接收人”页面填写模版信息,如下图所示:

- 显示名称: 接收人显示名称
- 用户名: 接收人用户名
- 移动电话: 手机号
- 电子邮件: 接收人邮箱
- 微信OpenID: 接收人微信ID
- 单击【保存】按钮
编辑接收人信息
- 登录 TKEStack
- 切换至【平台管理】控制台,选择 【监控&告警】->【通知设置】->【接收人】,查看“接收人”列表
- 单击接收人名称,如下图所示:

- 在“基本信息”页面,单击【基本信息】右侧的【编辑】按钮,如下图所示:

- 在“更新接收人”页面,编辑接收人信息
- 单击【保存】按钮
删除接收人
- 登录 TKEStack
- 切换至【平台管理】控制台,选择 【监控&告警】->【通知设置】->【接收人】,查看“接收人”列表
- 选择要删除的接收人,点击【删除】按钮,如下图所示:

- 单击删除窗口的【确定】按钮
接收组
新建接收组
- 登录 TKEStack
- 切换至【平台管理】控制台,选择 【监控&告警】->【通知设置】->【接收组】,查看“接收组”列表
- 点击【新建】按钮,如下图所示:

- 在“新建接收组”页面填写模版信息,如下图所示:

- 名称: 接收组显示名称
- 接收组: 从列表里选择接收人。如没有想要的接收人,请在接收人里创建
- 单击【保存】按钮
编辑接收组信息
- 登录 TKEStack
- 切换至【平台管理】控制台,选择 【监控&告警】->【通知设置】->【接收组】,查看“接收组”列表
- 单击接收组名称,如下图所示:

- 在“基本信息”页面,单击【基本信息】右侧的【编辑】按钮,如下图所示:

- 在“更新接收组”页面,编辑接收组信息
- 单击【保存】按钮
删除接收组
- 登录 TKEStack
- 切换至【平台管理】控制台,选择 【监控&告警】->【通知设置】->【接收组】,查看“接收组”列表
- 选择要删除的接收组,点击【删除】按钮,如下图所示:

- 单击删除窗口的【确定】按钮
2.7.3 - 告警设置
告警设置
概念
这里用户配置平台告警
前提条件
需要设置告警的集群应该先在其 基本信息 页里开启监控告警
新建告警设置
- 登录 TKEStack
- 切换至【平台管理】控制台,选择 【监控&告警】下的【告警设置】,查看“告警设置”列表
- 选择相应【集群】,点击【新建】按钮,如下图所示:

- 在“新建策略”页面填写告警策略信息,如下图所示:

- 告警策略名称: 输入告警策略名称,最长60字符
- 策略类型: 选择告警策略应用类型
- 集群: 集群监控告警
- Pod: Pod 监控告警
- 告警对象: 选择 Pod 相关的告警对象,支持对 namespace 下不同的 deployment、stateful和daemonset 进行监控报警
- 按工作负载选择: 选择 namespace 下的某个工作负载
- 全部选择: 不区分 namespace,全部监控
- 告警对象: 选择 Pod 相关的告警对象,支持对 namespace 下不同的 deployment、stateful和daemonset 进行监控报警
- 节点: 节点监控告警
- 统计周期: 选择数据采集周期,支持1、2、3、4、5分钟
- 指标: 选择告警指标,支持对监测值与指标值进行【大于/小于】比较,选择结果持续周期,如下图。指标具体含义可参考:[监控&告警指标含义](../../../../FAQ/Platform/alert&monitor-metrics)

- 接收组: 选择接收组,当出现满足条件当报警信息时,向组内人员发送消息。接收组需要先在 用户管理 创建
- 通知方式: 选择通知渠道和消息模版。通知渠道 和 消息模版需要先在 通知设置 创建
- 添加通知方式 :如需要添加多种通知方式,点击该按钮
- 单击【提交】按钮
复制告警设置
- 登录 TKEStack
- 切换至【平台管理】控制台,选择 【监控&告警】下的【告警设置】,查看“告警设置”列表
- 选择相应【集群】,点击告警设置列表最右侧的【复制】按钮,如下图所示:

- 在“复制策略”页面,编辑告警策略信息
- 单击【提交】按钮
编辑告警设置
- 登录 TKEStack
- 切换至【平台管理】控制台,选择 【监控&告警】下的【告警设置】,查看“告警设置”列表
- 选择相应【集群】,点击【告警名称】,如下图所示:

- 在“告警策略详情”页面,单击【基本信息】右侧的【编辑】按钮,如下图所示:

- 在“更新策略”页面,编辑策略信息
- 单击【提交】按钮
删除告警设置
- 登录 TKEStack
- 切换至【平台管理】控制台,选择 【监控&告警】下的【告警设置】,查看“告警设置”列表
- 选择相应【集群】,点击列表最右侧的【删除】按钮,如下图所示:

- 在弹出的删除告警窗口,单击【确定】按钮
批量删除告警设置
- 登录 TKEStack
- 切换至【平台管理】控制台,选择 【监控&告警】下的【告警设置】,查看“告警设置”列表
- 选择相应【集群】,选择多个告警策略,单击告警设置下方的【删除】按钮。如下图所示:

- 在弹出的删除告警窗口,单击【确定】按钮
2.8 - 运维中心
运维中心
概念
这里用户可以管理 Helm 应用、日志和集群事件持久化。
2.8.1 - Helm应用
应用功能是 TKEStack 集成的 Helm 3.0 相关功能,为您提供创建 helm chart、容器镜像、软件服务等各种产品和服务的能力。已创建的应用将在您指定的集群中运行,为您带来相应的能力。
新建 Helm 应用
- 登录 TKEStack
- 切换至【平台管理】控制台,选择【运维中心】->【 Helm 应用】
- 选择相应【集群】,单击【新建】按钮,如下图所示:

- 在“新建 Helm 应用”页面填写Helm应用信息,如下图所示:

- 应用名称: 输入应用名,1~63字符,只能包含小写字母、数字及分隔符("-"),且必须以小写字母开头,数字或小写字母结尾
- 运行集群: 选择应用所在集群
- 命名空间: 选择应用所在集群的命名空间
- 类型: 当前仅支持 HelmV3
- Chart: 选择需要部署的 chart
- Chart版本: 选择 chart 的版本
- 参数: 更新时如果选择不同版本的 Helm Chart,参数设置将被覆盖
- 拟运行: 会返回模板渲染清单,即最终将部署到集群的 YAML 资源,不会真正执行安装
- 单击【完成】按钮
删除 Helm 应用
- 登录 TKEStack
- 切换至【平台管理】控制台,选择【运维中心】->【 Helm 应用】
- 点击【删除】

查看 Helm 应用资源列表
- 登录 TKEStack
- 切换至【平台管理】控制台,选择【运维中心】->【 Helm 应用】
- 点击【应用名】后,点击【资源列表】,可查看该应用所有 Kubernetes 资源对象
查看 Helm 应用详情
- 登录 TKEStack
- 切换至【平台管理】控制台,选择【运维中心】->【 Helm 应用】
- 点击【应用名】后,点击【应用详情】

查看 Helm 应用版本历史
- 登录 TKEStack
- 切换至【平台管理】控制台,选择【运维中心】->【 Helm 应用】
- 点击【应用名】后,点击【版本历史】,可查看该应用所部署的历史版本。可以通过选择不同的版本进行参数对比查看其版本区别

2.8.2 - 日志采集
日志采集
概念
TKESTack 提供的集群内日志采集功能,支持将集群内服务或集群节点特定路径文件的日志发送至 Kafka、Elasticsearch 等消费端,支持采集容器标准输出日志,容器内文件日志以及主机内文件日志。更提供事件持久化、审计等功能,实时记录集群事件及操作日志记录,帮助运维人员存储和分析集群内部资源生命周期、资源调度、异常告警等情况。

日志收集功能需要为每个集群手动开启。日志收集功能开启后,日志收集组件 logagent 会在集群内以 Daemonset 的形式运行。用户可以通过日志收集规则配置日志的采集源和消费端,日志收集 Agent 会从用户配置的采集源进行日志收集,并将日志内容发送至用户指定的消费端。需要注意的是,使用日志收集功能需要您确认 Kubernetes 集群内节点能够访问日志消费端。
- 采集容器标准输出日志 :采集集群内指定容器的标准输出日志,采集到的日志信息将会以 JSON 格式输出到用户指定的消费端,并会自动附加相关的 Kubernetes metadata, 包括容器所属 pod 的 label 和 annotation 等信息。
- 采集容器内文件日志 :采集集群内指定 pod 内文件的日志,用户可以根据自己的需求,灵活的配置所需的容器和路径,采集到的日志信息将会以 JSON 格式输出到用户指定的消费端, 并会附加相关的 Kubernetes metadata,包括容器所属 pod 的 label 和 annotation 等信息。
- 采集主机内文件日志 :采集集群内所有节点的指定主机路径的日志,logagent 会采集集群内所有节点上满足指定路径规则的文件日志,以 JSON 格式输出到用户指定的输出端, 并会附加用户指定的 metadata,包括日志来源文件的路径和用户自定义的 metadata。
注意:日志采集对接外部 Kafka 或 Elasticsearch,该功能需要额外开启,位置在集群 基本信息 下面,点击开启“日志采集”服务。

新建日志采集规则
- 登录 TKEStack
- 切换至【平台管理】控制台,选择 【运维中心】->【日志采集】
- 选择相应【集群】和【命名空间】,单击【新建】按钮,如下图所示:

- 在“新建日志采集”页面填写日志采集信息,如下图所示:

- 收集规则名称: 输入规则名,1~63字符,只能包含小写字母、数字及分隔符("-"),且必须以小写字母开头,数字或小写字母结尾
- 所属集群: 选择所属集群
- 类型: 选择采集类型
- 容器标准输出: 容器Stdout信息采集
- 日志源: 可以选择所有容器或者某个namespace下的所有容器/工作负载
- 所有容器: 所有容器
- 指定容器: 某个Namespace下的所有容器或者工作负载
- 日志源: 可以选择所有容器或者某个namespace下的所有容器/工作负载
- 容器文件路径: 容器内文件内容采集
- 日志源: 可以采集具体容器内的某个文件路径下的文件内容
- 工作负载选项: 选择某个namespace下的某种工作负载类型下的某个工作负载
- 配置采集路径: 选择某个容器下的某个文件路径
- 日志源: 可以采集具体容器内的某个文件路径下的文件内容
- 节点文件路径: 收集节点上某个路径下的文件内容
- 日志源:
- 收集路径: 节点上日志收集路径
- metadata: key:value格式,收集的日志会带上metadata信息上报给消费端
- 日志源:
- 容器标准输出: 容器Stdout信息采集
- 消费端: 选择日志消费端
Kafka:
- 访问地址: kafka ip 和端口
- 主题(Topic): kafka topic 名
Elasticsearch:
注意:当前只支持未开启用户登录认证的 ES 集群
- Elasticsearch地址: ES 地址,如:http://190.0.0.1:200
- 索引: ES索引,最长60个字符,只能包含小写字母、数字及分隔符("-"、"_"、"+"),且必须以小写字母开头
- 单击【完成】按钮
指定容器运行后的日志目录
LogAgent 除了支持日志规则的创建,也支持指定容器运行后的日志目录,可实现日志文件展示和下载。
前提:需要在创建负载时挂载数据卷,并指定日志目

创建负载以后,在/data/logdir目录下的所有文件可以展示并下载,不仅是日志文件,例如我们在容器的/data/logdir下新建一个名为a.log的文件,如果有内容的话,也可以在这里展示与下载

2.8.3 - 审计记录
简介
TKEStack 集群审计是基于 Kubernetes Audit 对 kube-apiserver 产生的可配置策略的 JSON 结构日志的记录存储及检索功能。本功能记录了对 kube-apiserver 的访问事件,会按顺序记录每个用户、管理员或系统组件影响集群的活动。
功能优势
集群审计功能提供了区别于 metrics 的另一种集群观测维度。开启 TKEStack 集群审计后,会在集群里的 tke 命名空间下生成 tke-audit-api 的 Deployment,Kubernetes 可以记录每一次对集群操作的审计日志。每一条审计日志是一个 JSON 格式的结构化记录,包括元数据(metadata)、请求内容(requestObject)和响应内容(responseObject)三个部分。其中元数据(包含了请求的上下文信息,例如谁发起的请求、从哪里发起的、访问的 URI 等信息)一定会存在,请求和响应内容是否存在取决于审计级别。通过日志可以了解到以下内容:
- 集群里发生的活动
- 活动的发生时间及发生对象。
- 活动的触发时间、触发位置及观察点
- 活动的结果以及后续处理行为
阅读审计日志
{
"kind":"Event",
"apiVersion":"audit.k8s.io/v1",
"level":"RequestResponse",
"auditID":0a4376d5-307a-4e16-a049-24e017******,
"stage":"ResponseComplete",
// 发生了什么
"requestURI":"/apis/apps/v1/namespaces/default/deployments",
"verb":"create",
// 谁发起的
"user":{
"username":"admin",
"uid":"admin",
"groups":[
"system:masters",
"system:authenticated"
]
},
// 从哪里发起
"sourceIPs":[
"10.0.6.68"
],
"userAgent":"kubectl/v1.16.3 (linux/amd64) kubernetes/ald64d8",
// 发生了什么
"objectRef":{
"resource":"deployments",
"namespace":"default",
"name":"nginx-deployment",
"apiGroup":"apps",
"apiVersion":"v1"
},
// 结果是什么
"responseStatus":{
"metadata":{
},
"code":201
},
// 请求及返回具体信息
"requestObject":Object{...},
"responseObject":Object{...},
// 什么时候开始/结束
"requestReceivedTimestamp":"2020-04-10T10:47:34.315746Z",
"stageTimestamp":"2020-04-10T10:47:34.328942Z",
// 请求被接收/拒绝的原因是什么
"annotations":{
"authorization.k8s.io/decision":"allow",
"authorization.k8s.io/reason":""
}
}
前提条件
在 Installer 安装页面的控制台安装的第5步中,如下图所示,已经开启平台审计功能,并配置好 ElasticSearch:
查看审计
- 登录 TKEStack
- 切换至【平台管理】控制台,选择 【运维中心】->【审计记录】,查看审计列表:

参考
TKEStack 关于审计的相关配置:
# kube-apiserver 地址:/etc/kubernetes/manifests/kube-apiserver.yaml
--audit-policy-file=/etc/kubernetes/audit-policy.yaml # 审计策略
--audit-webhook-config-file=/etc/kubernetes/audit-api-client-config.yaml # 指定 Webhook backend 的配置文件
# 获取 TKEStack 审计组件的详细信息
kubectl describe deploy -ntke tke-audit-api
# 获取 TKEStack 审计的相关配置
kubectl describe cm -ntke tke-audit-api
2.8.4 - 事件持久化
PersistentEvent
PersistentEvent 介绍
Kubernetes Events 包括了 Kuberntes 集群的运行和各类资源的调度情况,对维护人员日常观察资源的变更以及定位问题均有帮助。TKEStack 支持为您的所有集群配置事件持久化功能,开启本功能后,会将您的集群事件实时导出到 ElasticSearch 的指定索引。
PersistentEvent 使用场景
Kubernetes 事件是集群内部资源生命周期、资源调度、异常告警等情况产生的记录,可以通过事件深入了解集群内部发生的事情,例如调度程序做出的决策或者某些pod从节点中被逐出的原因。
kubernetes 默认仅提供保留一个小时的 kubernetes 事件到集群的 ETCD 里。 PersistentEvent 提供了将 Kubernetes 事件持久化存储的前置功能,允许您通过PersistentEvent 将集群内事件导出到您自有的存储端。
PersistentEvent 限制条件
- 注意:当前只支持版本号为5的 ElasticSearch,且未开启 ElasticSearch 集群的用户登录认证
- 安装 PersistentEvent 将占用集群0.2核 CPU,100MB 内存的资源
- 仅在1.8版本以上的 kubernetes 集群支持
部署在集群内kubernetes对象
在集群内部署PersistentEvent Add-on , 将在集群内部署以下kubernetes对象
| kubernetes对象名称 | 类型 | 默认占用资源 | 所属Namespaces |
|---|---|---|---|
| tke-persistent-event | deployment | 0.2核CPU,100MB内存 | kube-system |
PersistentEvent 使用方法
在 扩展组件 里使用
登录 TKEStack
切换至【平台管理】控制台,选择 【扩展组件】,选择需要安装事件持久化组件的集群,安装 PersistentEvent 组件,注意安装 PersistentEvent 时需要在页面下方指定 ElasticSearch 的地址和索引
注意:当前只支持版本号为5,且未开启用户登录认证的 ES 集群
在 运维中心 里使用
- 登录 TKEStack
- 切换至【平台管理】控制台,选择 【运维中心】->【事件持久化】,查看事件持久化列表
- 单击列表最右侧【设置】按钮,如下图所示:

- 在“设置事件持久化”页面填写持久化信息
事件持久化存储: 是否进行持久化存储
注意:当前只支持版本号为5,且未开启用户登录认证的 ES 集群
Elasticsearch地址: ES 地址,如:http://190.0.0.1:200
索引: ES索引,最长60个字符,只能包含小写字母、数字及分隔符("-"、"_"、"+"),且必须以小写字母开头
- 单击【完成】按钮
3 - 业务管理控制台
业务管理控制台
3.1 - 应用管理
应用管理
3.1.1 - 命名空间
Namespaces 是 Kubernetes 在同一个集群中进行逻辑环境划分的对象, 您可以通过 Namespaces 进行管理多个团队多个项目的划分。在 Namespaces 下,Kubernetes 对象的名称必须唯一。您可以通过资源配额进行可用资源的分配,还可以进行不同 Namespaces 网络的访问控制。
使用方法
- 通过 TKEStack 控制台使用:TKEStack 控制台提供 Namespaces 的增删改查功能。
- 【业务管理】平台下不支持对命名空间的直接操作,需在【平台管理】下【业务管理】中指定业务通过“创建业务下的命名空间”来实现。
- 通过 Kubectl 使用:更多详情可查看 Kubernetes 官网文档。
相关知识
通过 ResourceQuota 设置 Namespaces 资源的使用配额
一个命名空间下可以拥有多个 ResourceQuota 资源,每个 ResourceQuota 可以设置每个 Namespace 资源的使用约束。可以设置 Namespaces 资源的使用约束如下:
- 计算资源的配额,例如 CPU、内存。
- 存储资源的配额,例如请求存储的总存储。
- Kubernetes 对象的计数,例如 Deployment 个数配额。
不同的 Kubernetes 版本,ResourceQuota 支持的配额设置略有差异,更多详情可查看 Kubernetes ResourceQuota 官方文档。 ResourceQuota 的示例如下所示:
apiVersion: v1
kind: ResourceQuota
metadata:
name: object-counts
namespace: default
spec:
hard:
configmaps: "10" ## 最多10个 ConfigMap
replicationcontrollers: "20" ## 最多20个 replicationcontroller
secrets: "10" ## 最多10个 secret
services: "10" ## 最多10个 service
services.loadbalancers: "2" ## 最多2个 Loadbanlacer 模式的 service
cpu: "1000" ## 该 Namespaces 下最多使用1000个 CPU 的资源
memory: 200Gi ## 该 Namespaces 下最多使用200Gi的内存
3.1.2 - 工作负载
工作负载
3.1.2.1 - Deployment
Deployment 声明了 Pod 的模板和控制 Pod 的运行策略,适用于部署无状态的应用程序。您可以根据业务需求,对 Deployment 中运行的 Pod 的副本数、调度策略、更新策略等进行声明。
Deployment 控制台操作指引
创建 Deployment
- 登录TKEStack,切换到【业务管理】控制台,选择左侧导航栏中的【应用管理】。
- 选择需要创建Deployment的【业务】下相应的【命名空间】,展开【工作负载】下拉项,进入【Deployment】管理页面。如下图所示:

- 单击【新建】,进入 “新建Workload” 页面。根据实际需求,设置 Deployment 参数。关键参数信息如下,其中必填项为工作负载名、实例内容器的名称和镜像:
- 工作负载名:输入自定义名称。
- 标签:给工作负载添加标签
- 命名空间:根据实际需求进行选择。
- 类型:选择【Deployment(可扩展的部署 Pod)】。
- 数据卷:根据需求,为负载添加数据卷为容器提供存,目前支持临时路径、主机路径、云硬盘数据卷、文件存储NFS、配置文件、PVC,还需挂载到容器的指定路径中
- 临时目录:主机上的一个临时目录,生命周期和Pod一致
- 主机路径:主机上的真实路径,可以重复使用,不会随Pod一起销毁
- NFS盘:挂载外部NFS到Pod,用户需要指定相应NFS地址,格式:127.0.0.1:/data
- ConfigMap:用户在业务Namespace下创建的ConfigMap
- Secret:用户在业务namespace下创建的Secret
- PVC:用户在业务namespace下创建的PVC
- 实例内容器:根据实际需求,为 Deployment 的一个 Pod 设置一个或多个不同的容器。

- 名称:自定义
- 镜像:根据实际需求进行选择
镜像版本(Tag):根据实际需求进行填写,不填默认为
latestCPU/内存限制:可根据 Kubernetes 资源限制 进行设置 CPU 和内存的限制范围,提高业务的健壮性(建议使用默认值)
GPU限制:如容器内需要使用GPU,此处填GPU需求
环境变量:用于设置容器内的变量,变量名只能包含大小写字母、数字及下划线,并且不能以数字开头
新增变量:自己设定变量键值对
引用ConfigMap/Secret:引用已有键值对
高级设置:可设置 “工作目录”、“运行命令”、“运行参数”、“镜像更新策略”、“容器健康检查”和“特权级”等参数。这里介绍一下镜像更新策略。
镜像更新策略:提供以下3种策略,请按需选择
若不设置镜像拉取策略,当镜像版本为空或
latest时,使用 Always 策略,否则使用 IfNotPresent 策略- Always:总是从远程拉取该镜像
- IfNotPresent:默认使用本地镜像,若本地无该镜像则远程拉取该镜像
- Never:只使用本地镜像,若本地没有该镜像将报异常
- 实例数量:根据实际需求选择调节方式,设置实例数量。

- 手动调节:直接设定实例个数
- 自动调节:根据设定的触发条件自动调节实例个数,目前支持根据CPU、内存利用率和利用量出入带宽等调节实例个数
- 定时调节:根据Crontab 语法周期性设置实例个数
- imagePullSecrets:镜像拉取密钥,用于拉取用户的私有镜像
- 节点调度策略:根据配置的调度规则,将Pod调度到预期的节点。支持指定节点调度和条件选择调度
- 注释(Annotations):给Deployment添加相应Annotation,如用户信息等
- 网络模式:选择Pod网络模式
- OverLay(虚拟网络):基于 IPIP 和 Host Gateway 的 Overlay 网络方案
- FloatingIP(浮动 IP):支持容器、物理机和虚拟机在同一个扁平面中直接通过IP进行通信的 Underlay 网络方案。提供了 IP 漂移能力,支持 Pod 重启或迁移时 IP 不变
- NAT(端口映射):Kubernetes 原生 NAT 网络方案
- Host(主机网络):Kubernetes 原生 Host 网络方案
- Service:勾选【启用】按钮,配置负载端口访问

服务访问方式:选择是【仅在集群内部访问】该负载还是集群外部通过【主机端口访问】该负载
- 仅在集群内访问:使用 Service 的 ClusterIP 模式,自动分配 Service 网段中的 IP,用于集群内访问。数据库类等服务如 MySQL 可以选择集群内访问,以保证服务网络隔离
- 主机端口访问:提供一个主机端口映射到容器的访问方式,支持 TCP、UDP、Ingress。可用于业务定制上层 LB 转发到 Node
- Headless Service:不创建用于集群内访问的ClusterIP,访问Service名称时返回后端Pods IP地址,用于适配自有的服务发现机制。解析域名时返回相应 Pod IP 而不是 Cluster IP
端口映射:输入负载要暴露的端口并指定通信协议类型(容器和服务端口建议都使用80)
Session Affinity: 点击【显示高级设置】出现,会话保持,设置会话保持后,会根据请求IP把请求转发给这个IP之前访问过的Pod。默认None,按需使用
单击【创建Workload】,完成创建。如下图所示:
当“运行/期望Pod数量”相等时,即表示 Deployment 下的所有 Pod 已创建完成。

更新 Deployment
更新 YAML
- 登录TKEStack,切换到【业务管理】控制台,选择左侧导航栏中的【应用管理】。
- 选择需要更新的【业务】下相应的【命名空间】,展开【工作负载】列表,进入【Deployment】管理页面。如下图所示:

- 在需要更新 YAML 的 Deployment 行中,单击【更多】>【编辑YAML】,进入“更新 Deployment” 页面。如下图所示:

- 在 “更新Deployment” 页面,编辑 YAML,单击【完成】,即可更新 YAML。如下图所示:

回滚 Deployment
- 登录 TKEStack,切换到【业务管理】控制台,选择左侧导航栏中的【应用管理】。
- 选择要变更的业务下相应的【命名空间】,展开【工作负载】列表,进入【 Deployment】 管理页面,点击进入要回滚的 Deployment 详情页面,单击【修订历史】。如下图所示:

- 选择合适版本进行回顾。
- 在弹出的 “回滚资源” 提示框中,单击【确定】即可完成回滚。
调整 Pod 数量
- 登录 TKEStack,切换到【业务管理】控制台,选择左侧导航栏中的【应用管理】。
- 选择要变更的业务下相应的命名空间,展开工作负载列表,进入 Deployment 管理页面。
- 点击 Deployment 列表操作栏的【更新实例数量】按钮。如下图所示:

- 根据实际需求调整 Pod 数量,单击【更新实例数目】即可完成调整。
查看Deployment监控数据
- 登录 TKEStack,切换到【业务管理】控制台,选择左侧导航栏中的【应用管理】,。
- 选择要变更的业务下相应的【命名空间】,点击进入 【Deployment】 管理页面。
- 单击【监控】按钮,在弹出的工作负载监控页面选择工作负载查看监控信息。如下图所示:

Kubectl 操作 Deployment 指引
YAML 示例
apiVersion: apps/v1beta2
kind: Deployment
metadata:
name: nginx-deployment
namespace: default
labels:
app: nginx-deployment
spec:
replicas: 3
selector:
matchLabels:
app: nginx-deployment
template:
metadata:
labels:
app: nginx-deployment
spec:
containers:
- name: nginx
image: nginx:latest
ports:
- containerPort: 80
- kind:标识 Deployment 资源类型。
- metadata:Deployment 的名称、Namespace、Label 等基本信息。
- metadata.annotations:对 Deployment 的额外说明,可通过该参数设置腾讯云 TKE 的额外增强能力。
- spec.replicas:Deployment 管理的 Pod 数量。
- spec.selector:Deployment 管理 Seletor 选中的 Pod 的 Label。
- spec.template:Deployment 管理的 Pod 的详细模板配置。
更多参数详情可查看 Kubernetes Deployment 官方文档。
Kubectl 创建 Deployment
参考 YAML 示例,准备 Deployment YAML 文件。
安装 Kubectl,并连接集群。操作详情请参考 通过 Kubectl 连接集群。
执行以下命令,创建 Deployment YAML 文件。
kubectl create -f 【Deployment YAML 文件名称】例如,创建一个文件名为 nginx.Yaml 的 Deployment YAML 文件,则执行以下命令:
kubectl create -f nginx.yaml执行以下命令,验证创建是否成功。
kubectl get deployments返回类似以下信息,即表示创建成功。
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE first-workload 1 1 1 0 6h ng 1 1 1 1 42m
Kubectl 更新 Deployment
通过 Kubectl 更新 Deployment 有以下三种方法。其中,方法一 和 方法二 均支持 Recreate 和 RollingUpdate 两种更新策略。
- Recreate 更新策略为先销毁全部 Pod,再重新创建 Deployment。
- RollingUpdate 更新策略为滚动更新策略,逐个更新 Deployment 的 Pod。RollingUpdate 还支持暂停、设置更新时间间隔等。
方法一
执行以下命令,更新 Deployment。
kubectl edit deployment/【name】
此方法适用于简单的调试验证,不建议在生产环境中直接使用。您可以通过此方法更新任意的 Deployment 参数。
方法二
执行以下命令,更新指定容器的镜像。
kubectl set image deployment/【name】 【containerName】=【image:tag】
建议保持 Deployment 的其他参数不变,业务更新时,仅更新容器镜像。
方法三
执行以下命令,滚动更新指定资源。
kubectl rolling-update 【NAME】 -f 【FILE】
更多滚动更新可参见 滚动更新说明。
Kubectl 回滚 Deployment
执行以下命令,查看 Deployment 的更新历史。
kubectl rollout history deployment/【name】执行以下命令,查看指定版本详情。
kubectl rollout history deployment/【name】 --revision=【REVISION】执行以下命令,回滚到前一个版本。
kubectl rollout undo deployment/【name】如需指定回滚版本号,可执行以下命令。
kubectl rollout undo deployment/【name】 --to-revision=【REVISION】
Kubectl 调整 Pod 数量
手动更新 Pod 数量
执行以下命令,手动更新 Pod 数量。
kubectl scale deployment 【NAME】 --replicas=【NUMBER】
自动更新 Pod 数量
前提条件
开启集群中的 HPA 功能。TKE 创建的集群默认开启 HPA 功能。
操作步骤
执行以下命令,设置 Deployment 的自动扩缩容。
kubectl autoscale deployment 【NAME】 --min=10 --max=15 --cpu-percent=80
Kubectl 删除 Deployment
执行以下命令,删除 Deployment。
kubectl delete deployment 【NAME】
3.1.2.2 - StatefulSet
StatefulSet 主要用于管理有状态的应用,创建的 Pod 拥有根据规范创建的持久型标识符。Pod 迁移或销毁重启后,标识符仍会保留。 在需要持久化存储时,您可以通过标识符对存储卷进行一一对应。如果应用程序不需要持久的标识符,建议您使用 Deployment 部署应用程序。
StatefulSet 控制台操作指引
创建 StatefulSet
- 登录TKEStack,切换到【业务管理】控制台,选择左侧导航栏中的【应用管理】。
- 选择需要创建StatefulSet的【业务】下相应的【命名空间】,展开【工作负载】下拉项,进入【StatefulSet】管理页面。如下图所示:

单击【新建】,进入 “新建Workload” 页面。根据实际需求,设置 StatefulSet 参数。
关键参数信息如下,其中必填项为工作负载名、实例内容器的名称和镜像:
- 工作负载名:输入自定义名称。
- 标签:给工作负载添加标签
- 命名空间:根据实际需求进行选择。
- 类型:选择【StatefulSet】。
- 数据卷:根据需求,为负载添加数据卷为容器提供存,目前支持临时路径、主机路径、云硬盘数据卷、文件存储NFS、配置文件、PVC,还需挂载到容器的指定路径中
- 临时目录:主机上的一个临时目录,生命周期和Pod一致
- 主机路径:主机上的真实路径,可以重复使用,不会随Pod一起销毁
- NFS盘:挂载外部NFS到Pod,用户需要指定相应NFS地址,格式:127.0.0.1:/data
- ConfigMap:用户在业务Namespace下创建的ConfigMap
- Secret:用户在业务namespace下创建的Secret
- PVC:用户在业务namespace下创建的PVC
- 实例内容器:根据实际需求,为 StatefulSet的一个 Pod 设置一个或多个不同的容器。
- 名称:自定义
- 镜像:根据实际需求进行选择
- 镜像版本(Tag):根据实际需求进行填写,不填默认为
latest - CPU/内存限制:可根据 Kubernetes 资源限制 进行设置 CPU 和内存的限制范围,提高业务的健壮性(建议使用默认值)
- GPU限制:如容器内需要使用GPU,此处填GPU需求
- 环境变量:用于设置容器内的变量,变量名只能包含大小写字母、数字及下划线,并且不能以数字开头
- 新增变量:自己设定变量键值对
- 引用ConfigMap/Secret:引用已有键值对
- 高级设置:可设置 “工作目录”、“运行命令”、“运行参数”、“镜像更新策略”、“容器健康检查”和“特权级”等参数。这里介绍一下镜像更新策略。
镜像更新策略:提供以下3种策略,请按需选择
若不设置镜像拉取策略,当镜像版本为空或
latest时,使用 Always 策略,否则使用 IfNotPresent 策略- Always:总是从远程拉取该镜像
- IfNotPresent:默认使用本地镜像,若本地无该镜像则远程拉取该镜像
- Never:只使用本地镜像,若本地没有该镜像将报异常
- 镜像版本(Tag):根据实际需求进行填写,不填默认为
- 实例数量:根据实际需求选择调节方式,设置实例数量。
- 手动调节:直接设定实例个数
- 自动调节:根据设定的触发条件自动调节实例个数,目前支持根据CPU、内存利用率和利用量出入带宽等调节实例个数
- 定时调节:根据Crontab 语法周期性设置实例个数
- imagePullSecrets:镜像拉取密钥,用于拉取用户的私有镜像
- 节点调度策略:根据配置的调度规则,将Pod调度到预期的节点。支持指定节点调度和条件选择调度
- 注释(Annotations):给StatefulSet添加相应Annotation,如用户信息等
- 网络模式:选择Pod网络模式
- OverLay(虚拟网络):基于 IPIP 和 Host Gateway 的 Overlay 网络方案
- FloatingIP(浮动 IP):支持容器、物理机和虚拟机在同一个扁平面中直接通过IP进行通信的 Underlay 网络方案。提供了 IP 漂移能力,支持 Pod 重启或迁移时 IP 不变
- NAT(端口映射):Kubernetes 原生 NAT 网络方案
- Host(主机网络):Kubernetes 原生 Host 网络方案
- Service:勾选【启用】按钮,配置负载端口访问
注意:如果不勾选【启用】则不会创建Service
服务访问方式:选择是【仅在集群内部访问】该负载还是集群外部通过【主机端口访问】该负载
- 仅在集群内访问:使用 Service 的 ClusterIP 模式,自动分配 Service 网段中的 IP,用于集群内访问。数据库类等服务如 MySQL 可以选择集群内访问,以保证服务网络隔离
- 主机端口访问:提供一个主机端口映射到容器的访问方式,支持 TCP、UDP、Ingress。可用于业务定制上层 LB 转发到 Node
- Headless Service:不创建用于集群内访问的ClusterIP,访问Service名称时返回后端Pods IP地址,用于适配自有的服务发现机制。解析域名时返回相应 Pod IP 而不是 Cluster IP
端口映射:输入负载要暴露的端口并指定通信协议类型(容器和服务端口建议都使用80)
Session Affinity: 点击【显示高级设置】出现,会话保持,设置会话保持后,会根据请求IP把请求转发给这个IP之前访问过的Pod。默认None,按需使用
单击【创建Workload】,完成创建。
更新 StatefulSet
更新 YAML
- 登录TKEStack,切换到【业务管理】控制台,选择左侧导航栏中的【应用管理】。
- 选择需要更新的【业务】下相应的【命名空间】,展开【工作负载】列表,进入【StatefulSet】管理页面。
- 在需要更新 YAML 的 StatefulSet 行中,选择【更多】>【编辑YAML】,进入更新 StatefulSet 页面。
- 在 “更新StatefulSet” 页面编辑 YAML,并单击【完成】即可更新 YAML。
Kubectl 操作 StatefulSet 指引
YAML 示例
apiVersion: v1
kind: Service ## 创建一个 Headless Service,用于控制网络域
metadata:
name: nginx
namespace: default
labels:
app: nginx
spec:
ports:
- port: 80
name: web
clusterIP: None
selector:
app: nginx
---
apiVersion: apps/v1
kind: StatefulSet ### 创建一个 Nginx的StatefulSet
metadata:
name: web
namespace: default
spec:
selector:
matchLabels:
app: nginx
serviceName: "nginx"
replicas: 3 # by default is 1
template:
metadata:
labels:
app: nginx
spec:
terminationGracePeriodSeconds: 10
containers:
- name: nginx
image: nginx:latest
ports:
- containerPort: 80
name: web
volumeMounts:
- name: www
mountPath: /usr/share/nginx/html
volumeClaimTemplates:
- metadata:
name: www
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "cbs"
resources:
requests:
storage: 10Gi
- kind:标识 StatefulSet 资源类型。
- metadata:StatefulSet 的名称、Label等基本信息。
- metadata.annotations:对 StatefulSet 的额外说明,可通过该参数设置腾讯云 TKE 的额外增强能力。
- spec.template:StatefulSet 管理的 Pod 的详细模板配置。
- spec.volumeClaimTemplates:提供创建 PVC&PV 的模板。
更多参数详情可查看 Kubernetes StatefulSet 官方文档。
创建 StatefulSet
参考 YAML 示例,准备 StatefulSet YAML 文件。
安装 Kubectl,并连接集群。操作详情请参考 通过 Kubectl 连接集群。
执行以下命令,创建 StatefulSet YAML 文件。
kubectl create -f StatefulSet YAML 文件名称例如,创建一个文件名为 web.yaml 的 StatefulSet YAML 文件,则执行以下命令:
kubectl create -f web.yaml执行以下命令,验证创建是否成功。
kubectl get StatefulSet返回类似以下信息,即表示创建成功。
NAME DESIRED CURRENT AGE test 1 1 10s
更新 StatefulSet
执行以下命令,查看 StatefulSet 的更新策略类型。
kubectl get ds/<daemonset-name> -o go-template='{{.spec.updateStrategy.type}}{{"\n"}}'
StatefulSet 有以下两种更新策略类型:
- OnDelete:默认更新策略。该更新策略在更新 StatefulSet 后,需手动删除旧的 StatefulSet Pod 才会创建新的 StatefulSet Pod。
- RollingUpdate:支持 Kubernetes 1.7或更高版本。该更新策略在更新 StatefulSet 模板后,旧的 StatefulSet Pod 将被终止,并且以滚动更新方式创建新的 StatefulSet Pod(Kubernetes 1.7或更高版本)。
方法一
执行以下命令,更新 StatefulSet。
kubectl edit StatefulSet/[name]
此方法适用于简单的调试验证,不建议在生产环境中直接使用。您可以通过此方法更新任意的 StatefulSet 参数。
方法二
执行以下命令,更新指定容器的镜像。
kubectl patch statefulset <NAME> --type='json' -p='[{"op": "replace", "path": "/spec/template/spec/containers/0/image", "value":"<newImage>"}]'
建议保持 StatefulSet 的其他参数不变,业务更新时,仅更新容器镜像。
如果更新的 StatefulSet 是滚动更新方式的策略,可执行以下命令查看更新状态:
kubectl rollout status sts/<StatefulSet-name>
删除 StatefulSet
执行以下命令,删除 StatefulSet。
kubectl delete StatefulSet [NAME] --cascade=false
–cascade=false 参数表示 Kubernetes 仅删除 StatefulSet,且不删除任何 Pod。如需删除 Pod,则执行以下命令:
kubectl delete StatefulSet [NAME]
更多 StatefulSet 相关操作可查看 Kubernetes官方指引。
3.1.2.3 - DaomonSet
DaomonSet
DaemonSet 主要用于部署常驻集群内的后台程序,例如节点的日志采集。DaemonSet 保证在所有或部分节点上均运行指定的 Pod。 新节点添加到集群内时,也会有自动部署 Pod;节点被移除集群后,Pod 将自动回收。
调度说明
若配置了 Pod 的 nodeSelector 或 affinity 参数,DaemonSet 管理的 Pod 将按照指定的调度规则调度。若未配置 Pod 的 nodeSelector 或 affinity 参数,则将在所有的节点上部署 Pod。
DaemonSet 控制台操作指引
创建 DaemonSet
- 登录TKEStack,切换到【业务管理】控制台,选择左侧导航栏中的【应用管理】。
- 选择需要创建DaemonSet的【业务】下相应的【命名空间】,展开【工作负载】下拉项,进入【DaemonSet】管理页面。如下图所示:

单击【新建】,进入 “新建Workload” 页面。
根据实际需求,设置 DaemonSet 参数。关键参数信息如下:
- 工作负载名:输入自定义名称。
- 标签:给工作负载添加标签
- 命名空间:根据实际需求进行选择。
- 类型:选择【DaemonSet】。
- 数据卷:根据需求,为负载添加数据卷为容器提供存,目前支持临时路径、主机路径、云硬盘数据卷、文件存储NFS、配置文件、PVC,还需挂载到容器的指定路径中
- 临时目录:主机上的一个临时目录,生命周期和Pod一致
- 主机路径:主机上的真实路径,可以重复使用,不会随Pod一起销毁
- NFS盘:挂载外部NFS到Pod,用户需要指定相应NFS地址,格式:127.0.0.1:/data
- ConfigMap:用户在业务Namespace下创建的ConfigMap
- Secret:用户在业务namespace下创建的Secret
- PVC:用户在业务namespace下创建的PVC
- 实例内容器:根据实际需求,为 DaemonSet 的一个 Pod 设置一个或多个不同的容器。
- 名称:自定义。
- 镜像:根据实际需求进行选择。
- 镜像版本(Tag):根据实际需求进行填写。
- CPU/内存限制:可根据 Kubernetes 资源限制 进行设置 CPU 和内存的限制范围,提高业务的健壮性。
- GPU限制:如容器内需要使用GPU,此处填GPU需求
- 环境变量:用于设置容器内的变量,变量名只能包含大小写字母、数字及下划线,并且不能以数字开头
新增变量:自己设定变量键值对
引用ConfigMap/Secret:引用已有键值对
高级设置:可设置 “工作目录”、“运行命令”、“运行参数”、“镜像更新策略”、“容器健康检查”和“特权级”等参数。这里介绍一下镜像更新策略。
镜像更新策略:提供以下3种策略,请按需选择
若不设置镜像拉取策略,当镜像版本为空或
latest时,使用 Always 策略,否则使用 IfNotPresent 策略- Always:总是从远程拉取该镜像
- IfNotPresent:默认使用本地镜像,若本地无该镜像则远程拉取该镜像
- Never:只使用本地镜像,若本地没有该镜像将报异常
- imagePullSecrets:镜像拉取密钥,用于拉取用户的私有镜像
- 节点调度策略:根据配置的调度规则,将Pod调度到预期的节点。支持指定节点调度和条件选择调度
- 注释(Annotations):给DaemonSet添加相应Annotation,如用户信息等
- 网络模式:选择Pod网络模式
- OverLay(虚拟网络):基于 IPIP 和 Host Gateway 的 Overlay 网络方案
- FloatingIP(浮动 IP):支持容器、物理机和虚拟机在同一个扁平面中直接通过IP进行通信的 Underlay 网络方案。提供了 IP 漂移能力,支持 Pod 重启或迁移时 IP 不变
- NAT(端口映射):Kubernetes 原生 NAT 网络方案
- Host(主机网络):Kubernetes 原生 Host 网络方案
单击【创建Workload】,完成创建。
更新 DaemonSet
更新 YAML
- 登录TKEStack,切换到【业务管理】控制台,选择左侧导航栏中的【应用管理】。
- 选择需要更新的【业务】下相应的命名空间,展开【工作负载】列表,进入【DaemonSet】管理页面。
- 在需要更新 YAML 的 DaemonSet 行中,选择【更多】>【编辑YAML】,进入更新 DaemonSet 页面。
- 在 “更新DaemonSet” 页面编辑 YAML,并单击【完成】即可更新 YAML。
Kubectl 操作 DaemonSet 指引
YAML 示例
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd-elasticsearch
namespace: kube-system
labels:
k8s-app: fluentd-logging
spec:
selector:
matchLabels:
name: fluentd-elasticsearch
template:
metadata:
labels:
name: fluentd-elasticsearch
spec:
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
containers:
- name: fluentd-elasticsearch
image: k8s.gcr.io/fluentd-elasticsearch:1.20
resources:
limits:
memory: 200Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
!以上 YAML 示例引用于
https://kubernetes.io/docs/concepts/workloads/controllers/daemonset, 创建时可能存在容器镜像拉取不成功的情况,仅用于本文介绍 DaemonSet 的组成。
- kind:标识 DaemonSet 资源类型。
- metadata:DaemonSet 的名称、Label等基本信息。
- metadata.annotations:DaemonSet 的额外说明,可通过该参数设置腾讯云 TKE 的额外增强能力。
- spec.template:DaemonSet 管理的 Pod 的详细模板配置。
更多可查看 Kubernetes DaemonSet 官方文档。
Kubectl 创建 DaemonSet
参考 YAML 示例,准备 DaemonSet YAML 文件。
安装 Kubectl,并连接集群。操作详情请参考 通过 Kubectl 连接集群。
执行以下命令,创建 DaemonSet YAML 文件。
kubectl create -f DaemonSet YAML 文件名称例如,创建一个文件名为 fluentd-elasticsearch.yaml 的 DaemonSet YAML 文件,则执行以下命令:
kubectl create -f fluentd-elasticsearch.yaml执行以下命令,验证创建是否成功。
kubectl get DaemonSet返回类似以下信息,即表示创建成功。
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE frontend 0 0 0 0 0 app=frontend-node 16d
Kubectl 更新 DaemonSet
执行以下命令,查看 DaemonSet 的更新策略类型。
kubectl get ds/<daemonset-name> -o go-template='{{.spec.updateStrategy.type}}{{"\n"}}'
DaemonSet 有以下两种更新策略类型:
- OnDelete:默认更新策略。该更新策略在更新 DaemonSet 后,需手动删除旧的 DaemonSet Pod 才会创建新的DaemonSet Pod。
- RollingUpdate:支持 Kubernetes 1.6或更高版本。该更新策略在更新 DaemonSet 模板后,旧的 DaemonSet Pod 将被终止,并且以滚动更新方式创建新的 DaemonSet Pod。
方法一
执行以下命令,更新 DaemonSet。
kubectl edit DaemonSet/[name]
此方法适用于简单的调试验证,不建议在生产环境中直接使用。您可以通过此方法更新任意的 DaemonSet 参数。
方法二
执行以下命令,更新指定容器的镜像。
kubectl set image ds/[daemonset-name][container-name]=[container-new-image]
建议保持 DaemonSet 的其他参数不变,业务更新时,仅更新容器镜像。
Kubectl 回滚 DaemonSet
执行以下命令,查看 DaemonSet 的更新历史。
kubectl rollout history daemonset /[name]执行以下命令,查看指定版本详情。
kubectl rollout history daemonset /[name] --revision=[REVISION]执行以下命令,回滚到前一个版本。
kubectl rollout undo daemonset /[name]如需指定回滚版本号,可执行以下命令。
kubectl rollout undo daemonset /[name] --to-revision=[REVISION]
Kubectl 删除 DaemonSet
执行以下命令,删除 DaemonSet。
kubectl delete DaemonSet [NAME]
3.1.2.4 - Job
Job
Job 控制器会创建 1-N 个 Pod,这些 Pod 按照运行规则运行,直至运行结束。Job 可用于批量计算、数据分析等场景。通过设置重复执行次数、并行度、重启策略等满足业务述求。 Job 执行完成后,不再创建新的 Pod,也不会删除 Pod,您可在 “日志” 中查看已完成的 Pod 的日志。如果您删除了 Job,Job 创建的 Pod 也会同时被删除,将查看不到该 Job 创建的 Pod 的日志。
Job 控制台操作指引
创建 Job
登录TKEStack,切换到【业务管理】控制台,选择左侧导航栏中的【应用管理】。
选择需要创建 Job 的【业务】下相应的【命名空间】,展开【工作负载】下拉项,进入【 Job】 管理页面。
单击【新建】,进入 “新建Workload” 页面。如下图所示:

根据实际需求,设置 Job 参数。关键参数信息如下:
工作负载名:输入自定义名称。
标签:给工作负载添加标签
命名空间:根据实际需求进行选择。
类型:选择【Job(单次任务)】。
Job设置
- 重复执行次数:Job 管理的 Pod 需要重复执行的次数。
- 并行度:Job 并行执行的 Pod 数量。
- 失败重启策略:Pod下容器异常推出后的重启策略。
- Never:不重启容器,直至 Pod 下所有容器退出。
- OnFailure:Pod 继续运行,容器将重新启动。
数据卷:根据需求,为负载添加数据卷为容器提供存,目前支持临时路径、主机路径、云硬盘数据卷、文件存储NFS、配置文件、PVC,还需挂载到容器的指定路径中
临时目录:主机上的一个临时目录,生命周期和Pod一致
主机路径:主机上的真实路径,可以重复使用,不会随Pod一起销毁
NFS盘:挂载外部 NFS 到 Pod,用户需要指定相应 NFS 地址,格式:127.0.0.1:/data
ConfigMap:用户在业务Namespace下创建的ConfigMap
Secret:用户在业务namespace下创建的Secret
PVC:用户在业务namespace下创建的PVC
实例内容器:根据实际需求,为 Job 的一个 Pod 设置一个或多个不同的容器。
- 名称:自定义。
- 镜像:根据实际需求进行选择。
- 镜像版本(Tag):根据实际需求进行填写。
- CPU/内存限制:可根据 Kubernetes 资源限制 进行设置 CPU 和内存的限制范围,提高业务的健壮性。
- GPU限制:如容器内需要使用GPU,此处填GPU需求
- 环境变量:用于设置容器内的变量,变量名只能包含大小写字母、数字及下划线,并且不能以数字开头
新增变量:自己设定变量键值对
引用ConfigMap/Secret:引用已有键值对
高级设置:可设置 “工作目录”、“运行命令”、“运行参数”、“镜像更新策略”、“容器健康检查”和“特权级”等参数。这里介绍一下镜像更新策略。
镜像更新策略:提供以下3种策略,请按需选择
若不设置镜像拉取策略,当镜像版本为空或
latest时,使用 Always 策略,否则使用 IfNotPresent 策略- Always:总是从远程拉取该镜像
- IfNotPresent:默认使用本地镜像,若本地无该镜像则远程拉取该镜像
- Never:只使用本地镜像,若本地没有该镜像将报异常
imagePullSecrets:镜像拉取密钥,用于拉取用户的私有镜像
节点调度策略:根据配置的调度规则,将Pod调度到预期的节点。支持指定节点调度和条件选择调度
注释(Annotations):给Pod添加相应Annotation,如用户信息等
网络模式:选择Pod网络模式
- OverLay(虚拟网络):基于 IPIP 和 Host Gateway 的 Overlay 网络方案
- FloatingIP(浮动 IP):支持容器、物理机和虚拟机在同一个扁平面中直接通过IP进行通信的 Underlay 网络方案。提供了 IP 漂移能力,支持 Pod 重启或迁移时 IP 不变
- NAT(端口映射):Kubernetes 原生 NAT 网络方案
- Host(主机网络):Kubernetes 原生 Host 网络方案
单击【创建Workload】,完成创建。
查看 Job 状态
登录 TKEStack,切换到【业务管理】控制台,选择左侧导航栏中的【应用管理】。
选择需要创建 Job 的业务下相应的【命名空间】,展开【工作负载】下拉项,进入【 Job 】管理页面。
单击需要查看状态的【 Job 名称】,即可查看 Job 详情。
删除 Job
Job 执行完成后,不再创建新的 Pod,也不会删除 Pod,您可在【业务管理】控制台下的【应用管理】下的 【日志】 中查看已完成的 Pod 的日志。如果您删除了 Job,Job 创建的 Pod 也会同时被删除,将查看不到该 Job 创建的 Pod 的日志。
Kubectl 操作 Job 指引
YAML 示例
apiVersion: batch/v1
kind: Job
metadata:
name: pi
spec:
completions: 2
parallelism: 2
template:
spec:
containers:
- name: pi
image: perl
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: Never
backoffLimit: 4
- kind:标识 Job 资源类型。
- metadata:Job 的名称、Label等基本信息。
- metadata.annotations:Job 的额外说明,可通过该参数设置腾讯云 TKE 的额外增强能力。
- spec.completions:Job 管理的 Pod 重复执行次数。
- spec.parallelism:Job 并行执行的 Pod 数。
- spec.template:Job 管理的 Pod 的详细模板配置。
创建 Job
参考 YAML 示例,准备 Job YAML 文件。
安装 Kubectl,并连接集群。操作详情请参考 通过 Kubectl 连接集群。
创建 Job YAML 文件。
kubectl create -f Job YAML 文件名称例如,创建一个文件名为 pi.yaml 的 Job YAML 文件,则执行以下命令:
kubectl create -f pi.yaml执行以下命令,验证创建是否成功。
kubectl get job返回类似以下信息,即表示创建成功。
NAME DESIRED SUCCESSFUL AGE job 1 0 1m
删除 Job
执行以下命令,删除 Job。
kubectl delete job [NAME]
3.1.2.5 - CronJob
CronJob
一个 CronJob 对象类似于 crontab(cron table)文件中的一行。它根据指定的预定计划周期性地运行一个 Job,格式可以参考 Cron。 Cron 格式说明如下:
# 文件格式说明
# ——分钟(0 - 59)
# | ——小时(0 - 23)
# | | ——日(1 - 31)
# | | | ——月(1 - 12)
# | | | | ——星期(0 - 6)
# | | | | |
# * * * * *
CronJob 控制台操作指引
创建 CronJob
登录TKEStack,切换到【业务管理】控制台,选择左侧导航栏中的【应用管理】。
选择需要创建CronJob的业务下相应的【命名空间】,展开【工作负载】下拉项,进入【CronJob】管理页面。如下图所示:

单击【创建】按钮,进入 新建Workload页面。
根据实际需求,设置 CronJob 参数。关键参数信息如下:
- 工作负载名:输入自定义名称。
- 标签:给工作负载添加标签
- 命名空间:根据实际需求进行选择。
- 类型:选择【CronJob(按照Cron的计划定时运行)】。
- 执行策略:根据 Cron 格式设置任务的定期执行策略。
- Job设置
- 重复执行次数:Job 管理的 Pod 需要重复执行的次数。
- 并行度:Job 并行执行的 Pod 数量。
- 失败重启策略:Pod下容器异常推出后的重启策略。
- Never:不重启容器,直至 Pod 下所有容器退出。
- OnFailure:Pod 继续运行,容器将重新启动。
- 数据卷:根据需求,为负载添加数据卷为容器提供存,目前支持临时路径、主机路径、云硬盘数据卷、文件存储NFS、配置文件、PVC,还需挂载到容器的指定路径中
- 临时目录:主机上的一个临时目录,生命周期和Pod一致
- 主机路径:主机上的真实路径,可以重复使用,不会随Pod一起销毁
- NFS盘:挂载外部NFS到Pod,用户需要指定相应NFS地址,格式:127.0.0.1:/data
- ConfigMap:用户在业务Namespace下创建的ConfigMap
- Secret:用户在业务namespace下创建的Secret
- PVC:用户在业务namespace下创建的PVC
- 实例内容器:根据实际需求,为 CronJob 的一个 Pod 设置一个或多个不同的容器。
- 名称:自定义。
- 镜像:根据实际需求进行选择。
- 镜像版本(Tag):根据实际需求进行填写。
- CPU/内存限制:可根据 Kubernetes 资源限制 进行设置 CPU 和内存的限制范围,提高业务的健壮性。
- GPU限制:如容器内需要使用GPU,此处填GPU需求
- 环境变量:用于设置容器内的变量,变量名只能包含大小写字母、数字及下划线,并且不能以数字开头
新增变量:自己设定变量键值对
引用ConfigMap/Secret:引用已有键值对
高级设置:可设置 “工作目录”、“运行命令”、“运行参数”、“镜像更新策略”、“容器健康检查”和“特权级”等参数。这里介绍一下镜像更新策略。
镜像更新策略:提供以下3种策略,请按需选择
若不设置镜像拉取策略,当镜像版本为空或
latest时,使用 Always 策略,否则使用 IfNotPresent 策略- Always:总是从远程拉取该镜像
- IfNotPresent:默认使用本地镜像,若本地无该镜像则远程拉取该镜像
- Never:只使用本地镜像,若本地没有该镜像将报异常
- imagePullSecrets:镜像拉取密钥,用于拉取用户的私有镜像
- 节点调度策略:根据配置的调度规则,将Pod调度到预期的节点。支持指定节点调度和条件选择调度
- 注释(Annotations):给Pod添加相应Annotation,如用户信息等
- 网络模式:选择Pod网络模式
- OverLay(虚拟网络):基于 IPIP 和 Host Gateway 的 Overlay 网络方案
- FloatingIP(浮动 IP):支持容器、物理机和虚拟机在同一个扁平面中直接通过IP进行通信的 Underlay 网络方案。提供了 IP 漂移能力,支持 Pod 重启或迁移时 IP 不变
- NAT(端口映射):Kubernetes 原生 NAT 网络方案
- Host(主机网络):Kubernetes 原生 Host 网络方案
单击【创建Workload】,完成创建。
查看 CronJob 状态
- 登录TKEStack,切换到【业务管理】控制台,选择左侧导航栏中的【应用管理】。
- 选择需要创建CronJob的【业务】下相应的【命名空间】,展开【工作负载】下拉项,进入【CronJob】管理页面。
- 单击需要查看状态的 CronJob 名称,即可查看 CronJob 详情。
Kubectl 操作 CronJob 指引
YAML 示例
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: hello
spec:
schedule: "*/1 * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox
args:
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
restartPolicy: OnFailure
- kind:标识 CronJob 资源类型。
- metadata:CronJob 的名称、Label等基本信息。
- metadata.annotations:对 CronJob 的额外说明,可通过该参数设置腾讯云 TKE 的额外增强能力。
- spec.schedule:CronJob 执行的 Cron 的策略。
- spec.jobTemplate:Cron 执行的 Job 模板。
创建 CronJob
方法一
参考 YAML 示例,准备 CronJob YAML 文件。
安装 Kubectl,并连接集群。操作详情请参考 通过 Kubectl 连接集群。
执行以下命令,创建 CronJob YAML 文件。
kubectl create -f CronJob YAML 文件名称例如,创建一个文件名为 cronjob.yaml 的 CronJob YAML 文件,则执行以下命令:
kubectl create -f cronjob.yaml
方法二
通过执行
kubectl run命令,快速创建一个 CronJob。例如,快速创建一个不需要写完整配置信息的 CronJob,则执行以下命令:
kubectl run hello --schedule="*/1 * * * *" --restart=OnFailure --image=busybox -- /bin/sh -c "date; echo Hello"执行以下命令,验证创建是否成功。
kubectl get cronjob [NAME]返回类似以下信息,即表示创建成功。
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE cronjob * * * * * False 0 <none> 15s
删除 CronJob
!
- 执行此删除命令前,请确认是否存在正在创建的 Job,否则执行该命令将终止正在创建的 Job。
- 执行此删除命令时,已创建的 Job 和已完成的 Job 均不会被终止或删除。
- 如需删除 CronJob 创建的 Job,请手动删除。
执行以下命令,删除 CronJob。
kubectl delete cronjob [NAME]
3.1.2.6 - TApp
TApp
Kubernetes现有应用类型(如:Deployment、StatefulSet等)无法满足很多非微服务应用的需求,比如:操作(升级、停止等)应用中的指定pod、应用支持多版本的pod。如果要将这些应用改造为适合于这些workload的应用,需要花费很大精力,这将使大多数用户望而却步。
为解决上述复杂应用管理场景,TKEStack基于Kubernetes CRD开发了一种新的应用类型TAPP,它是一种通用类型的workload,同时支持service和batch类型作业,满足绝大部分应用场景,它能让用户更好的将应用迁移到Kubernetes集群。
查询TApp可查看更多相关信息
TApp控制台操作指引
创建 TApp
注意:使用前提,在【扩展组件】安装TApp
- 登录TKEStack,切换到【业务管理】控制台,选择左侧导航栏中的【应用管理】。
- 选择需要创建TApp的【业务】下相应的【命名空间】,展开【工作负载】下拉项,进入【TApp】管理页面。如下图所示:

单击【新建】,进入 “新建Workload” 页面。根据实际需求,设置 TApp 参数。关键参数信息如下,其中必填项为工作负载名、实例内容器的名称和镜像:
- 工作负载名:输入自定义名称。
- 标签:给工作负载添加标签
- 命名空间:根据实际需求进行选择。
- 类型:选择【TApp】。
- 节点异常策略
- 迁移,调度策略与Deployment一致,Pod会迁移到新的节点
- 不迁移,调度策略与StatefulSel一致,异常pod不会被迁移
- 数据卷:根据需求,为负载添加数据卷为容器提供存,目前支持临时路径、主机路径、云硬盘数据卷、文件存储NFS、配置文件、PVC,还需挂载到容器的指定路径中
- 临时目录:主机上的一个临时目录,生命周期和Pod一致
- 主机路径:主机上的真实路径,可以重复使用,不会随Pod一起销毁
- NFS盘:挂载外部NFS到Pod,用户需要指定相应NFS地址,格式:127.0.0.1:/data
- ConfigMap:用户在业务Namespace下创建的ConfigMap
- Secret:用户在业务namespace下创建的Secret
- PVC:用户在业务namespace下创建的PVC
- 实例内容器:根据实际需求,为 TApp 的一个 Pod 设置一个或多个不同的容器。
- 名称:自定义
- 镜像:根据实际需求进行选择
镜像版本(Tag):根据实际需求进行填写,不填默认为
latestCPU/内存限制:可根据 Kubernetes 资源限制 进行设置 CPU 和内存的限制范围,提高业务的健壮性(建议使用默认值)
GPU限制:如容器内需要使用GPU,此处填GPU需求
环境变量:用于设置容器内的变量,变量名只能包含大小写字母、数字及下划线,并且不能以数字开头
新增变量:自己设定变量键值对
引用ConfigMap/Secret:引用已有键值对
高级设置:可设置 “工作目录”、“运行命令”、“运行参数”、“镜像更新策略”、“容器健康检查”和“特权级”等参数。这里介绍一下镜像更新策略。
镜像更新策略:提供以下3种策略,请按需选择
若不设置镜像拉取策略,当镜像版本为空或
latest时,使用 Always 策略,否则使用 IfNotPresent 策略- Always:总是从远程拉取该镜像
- IfNotPresent:默认使用本地镜像,若本地无该镜像则远程拉取该镜像
- Never:只使用本地镜像,若本地没有该镜像将报异常
- 实例数量:根据实际需求选择调节方式,设置实例数量。
- 手动调节:直接设定实例个数
- 自动调节:根据设定的触发条件自动调节实例个数,目前支持根据CPU、内存利用率和利用量出入带宽等调节实例个数
- 定时调节:根据Crontab 语法周期性设置实例个数
- imagePullSecrets:镜像拉取密钥,用于拉取用户的私有镜像
- 节点调度策略:根据配置的调度规则,将Pod调度到预期的节点。支持指定节点调度和条件选择调度
- 注释(Annotations):给TApp添加相应Annotation,如用户信息等
- 网络模式:选择Pod网络模式
- OverLay(虚拟网络):基于 IPIP 和 Host Gateway 的 Overlay 网络方案
- FloatingIP(浮动 IP):支持容器、物理机和虚拟机在同一个扁平面中直接通过IP进行通信的 Underlay 网络方案。提供了 IP 漂移能力,支持 Pod 重启或迁移时 IP 不变
- NAT(端口映射):Kubernetes 原生 NAT 网络方案
- Host(主机网络):Kubernetes 原生 Host 网络方案
- Service:勾选【启用】按钮,配置负载端口访问
注意:如果不勾选【启用】则不会创建Service
服务访问方式:选择是【仅在集群内部访问】该负载还是集群外部通过【主机端口访问】该负载
- 仅在集群内访问:使用 Service 的 ClusterIP 模式,自动分配 Service 网段中的 IP,用于集群内访问。数据库类等服务如 MySQL 可以选择集群内访问,以保证服务网络隔离
- 主机端口访问:提供一个主机端口映射到容器的访问方式,支持 TCP、UDP、Ingress。可用于业务定制上层 LB 转发到 Node
- Headless Service:不创建用于集群内访问的ClusterIP,访问Service名称时返回后端Pods IP地址,用于适配自有的服务发现机制。解析域名时返回相应 Pod IP 而不是 Cluster IP
端口映射:输入负载要暴露的端口并指定通信协议类型(容器和服务端口建议都使用80)
Session Affinity: 点击【显示高级设置】出现,会话保持,设置会话保持后,会根据请求IP把请求转发给这个IP之前访问过的Pod。默认None,按需使用
单击【创建Workload】,完成创建。如下图所示:
当“运行/期望Pod数量”相等时,即表示 TApp 下的所有 Pod 已创建完成。

更新 TApp
更新 YAML
- 登录TKEStack,切换到【业务管理】控制台,选择左侧导航栏中的【应用管理】。
- 选择需要更新的【业务】下相应的【命名空间】,展开【工作负载】列表,进入【TApp】管理页面。在需要更新 YAML 的 TApp 行中,单击【更多】>【编辑YAML】,进入“更新 TApp” 页面。如下图所示:

- 在 “更新TApp” 页面,编辑 YAML,单击【完成】,即可更新 YAML。如下图所示:

调整 Pod 数量
- 登录 TKEStack,切换到【业务管理】控制台,选择左侧导航栏中的【应用管理】。
- 选择要变更的业务下相应的命名空间,展开工作负载列表,进入 TApp 管理页面。
- 点击 TApp 列表操作栏的【更新实例数量】按钮。如下图所示:

- 根据实际需求调整 Pod 数量,如3,单击页面下方的【更新实例数目】即可完成调整。
TApp特色功能-指定pod灰度升级
- 登录 TKEStack,切换到【业务管理】控制台,选择左侧导航栏中的【应用管理】。
- 选择要变更的业务下相应的【命名空间】,展开【工作负载】列表,进入【 TApp】 管理页面,点击进入要灰度升级的 TApp名称。如下图所示:

- 如下图标签1所示,可选指定需要灰度升级的pod,然后点击下图中标签2 的【灰度升级】即可升级指定pod。

在弹出的 “回滚资源” 提示框中,单击【确定】即可完成回滚。
注意:此页面同时可完成指定Pod监控和删除
查询TApp可查看更多相关信息
3.1.2.7 - 工作负载的请求与限制
工作负载的请求与限制
Request:容器使用的最小资源需求,作为容器调度时资源分配的判断依赖。只有当节点上可分配资源量 >= 容器资源请求数时才允许将容器调度到该节点。但 Request 参数不限制容器的最大可使用资源值。 Limit: 容器能使用的资源最大值。
! 更多 Limit 和 Request 参数介绍,单击 查看详情。
CPU 限制说明
CPU 资源允许设置 CPU 请求和 CPU 限制的资源量,以核(U)为单位,允许为小数。
!
- CPU Request 作为调度时的依据,在创建时为该容器在节点上分配 CPU 使用资源,称为 “已分配 CPU” 资源。
- CPU Limit 限制容器 CPU 资源的上限,不设置表示不做限制(CPU Limit >= CPU Request)。
内存限制说明
内存资源只允许限制容器最大可使用内存量。以 MiB 为单位,允许为小数。
!
- 内存 Request 作为调度时的依据,在创建时为该容器在节点上分配内存,称为 “已分配内存” 资源。
- 内存资源为不可伸缩资源。当节点上所有容器使用内存均超量时,存在 OOM 的风险。因此不设置 Limit 时,默认 Limit = Request,保证容器的正常运作。
CPU 使用量和 CPU 使用率
- CPU 使用量为绝对值,表示实际使用的 CPU 的物理核数,CPU 资源请求和 CPU 资源限制的判断依据都是 CPU 使用量。
- CPU 使用率为相对值,表示 CPU 的使用量与 CPU 单核的比值(或者与节点上总 CPU 核数的比值)。
使用示例
一个简单的示例说明 Request 和 Limit 的作用,测试集群包括1个 4U4G 的节点、已经部署的两个 Pod ( Pod1,Pod2 ),每个 Pod 的资源设置为(CPU Requst,CPU Limit,Memory Requst,Memory Limit)=(1U,2U,1G,1G)。(1.0G = 1000MiB) 节点上 CPU 和内存的资源使用情况如下图所示: 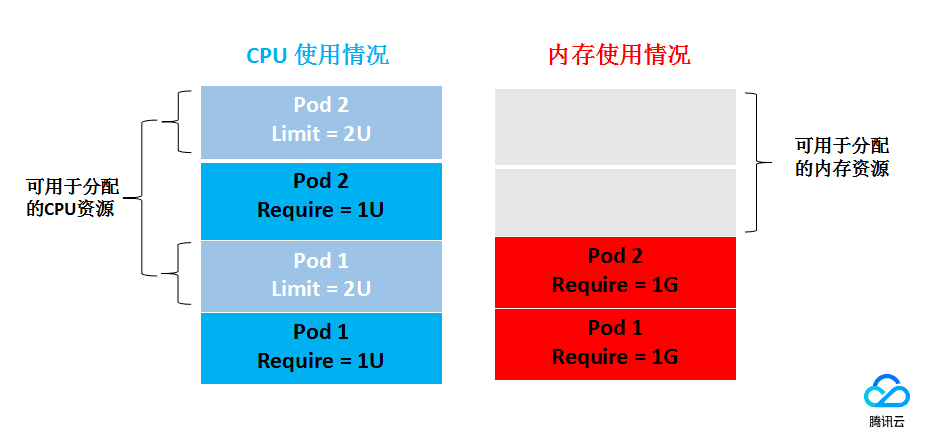 已经分配的 CPU 资源为:1U(分配 Pod1) + 1U(分配 Pod2) = 2U,剩余可以分配的 CPU 资源为2U。 已经分配的内存资源为:1G(分配 Pod1) + 1G(分配 Pod2) = 2G,剩余可以分配的内存资源为2G。 所以该节点可以再部署一个 ( CPU Requst, Memory Requst ) =( 2U,2G )的 Pod 部署,或者部署2个(CPU Requst,Memory Requst) = (1U,1G) 的 Pod 部署。
已经分配的 CPU 资源为:1U(分配 Pod1) + 1U(分配 Pod2) = 2U,剩余可以分配的 CPU 资源为2U。 已经分配的内存资源为:1G(分配 Pod1) + 1G(分配 Pod2) = 2G,剩余可以分配的内存资源为2G。 所以该节点可以再部署一个 ( CPU Requst, Memory Requst ) =( 2U,2G )的 Pod 部署,或者部署2个(CPU Requst,Memory Requst) = (1U,1G) 的 Pod 部署。
在资源限制方面,每个 Pod1 和 Pod2 使用资源的上限为 ( 2U,1G ),即在资源空闲的情况下,Pod 使用 CPU 的量最大能达到2U。
服务资源限制推荐
CCS 会根据您当前容器镜像的历史负载来推荐 Request 与 Limit 值,使用推荐值会保证您的容器更加平稳的运行,大大减小出现异常的概率。
推荐算法: 我们首先会取出过去7天当前容器镜像分钟级别负载,并辅以百分位统计第95%的值来最终确定推荐的 Request,Limit 为 Request 的2倍。
Request = Percentile(实际负载[7d],0.95)
Limit = Request * 2
如果当前的样本数量(实际负载)不满足推荐计算的数量要求,我们会相应的扩大样本取值范围,尝试重新计算。例如,去掉镜像 tag,namespace,serviceName 等筛选条件。若经过多次计算后同样未能得到有效值,则推荐值为空。
推荐值为空: 在使用过程中,您会发现有部分值暂无推荐的情况,可能由于以下几点造成: 1. 当前数据并不满足计算的需求,我们需要待计算的样本数量(实际负载)大于1440个,即有一天的数据。 2. 推荐值小于您当前容器已经配置的 Request 或者 Limit。
! 1. 由于推荐值是根据历史负载来计算的,原则上,容器镜像运行真实业务的时间越长,推荐的值越准确。 2. 使用推荐值创建服务,可能会因为集群资源不足造成容器无法调度成功。在保存时,须确认当前集群的剩余资源。 3. 推荐值是建议值,您可以根据自己业务的实际情况做相应的调整。
3.1.3 - 服务
服务
3.1.3.1 - Service
Service 定义访问后端 Pod 的访问方式,并提供固定的虚拟访问 IP。您可以在 Service 中通过设置来访问后端的 Pod,不同访问方式的服务可提供不同网络能力。 腾讯云容器服务(TKE)提供以下四种服务访问方式:
| 访问方式 | 说明 |
|---|---|
| 仅在集群内访问 |
|
| 主机端口访问 |
|
集群内进行 Service 访问时,建议不要通过负载均衡 IP 进行访问,以避免出现访问不通的情况。
一般情况下,4层负载均衡(LB)会绑定多台 Node 作为 real server(rs) ,使用时需要限制 client 和 rs 不能存在于同一台云服务器上,否则会有一定概率导致报文回环出不去。 当 Pod 去访问 LB 时,Pod 就是源 IP,当其传输到内网时 LB 也不会做 snat 处理将源 IP 转化成 Node IP,那么 LB 收到报文也就不能判断是从哪个 Node 发送的,LB 的避免回环策略也就不会生效,所有的 rs 都可能被转发。当转发到 client 所在的 Node 上时,LB 就无法收到回包,从而导致访问不通。
集群内访问时,支持Headless Service,解析服务名时直接返回对应Pod IP而不是Cluster IP,可以适配自有的服务发现机制。 两种访问方式均支持Session Affinity,设置会话保持后,会根据请求IP把请求转发给这个IP之前访问过的Pod.
Service 控制台操作指引
创建 Service
- 登录TKEStack,切换到【业务管理】控制台,选择左侧导航栏中的【应用管理】。
- 选择需要创建 Service 的【业务】下相应的【命名空间】,展开【服务】列表,进入【Service】管理页面。
- 单击【新建】,进入 “新建 Service” 页面。如下图所示:

- 根据实际需求,设置 Service 参数。关键参数信息如下:
- 服务名称:自定义。
- 命名空间:根据实际需求进行选择。
- 访问设置:请参考 简介 并根据实际需求进行设置。
- 单击【创建服务】,完成创建。
更新 Service
更新 YAML
- 登录TKEStack,切换到业务管理控制台,选择左侧导航栏中的【应用管理】。
- 选择需要创建Service的业务下相应的命名空间,展开服务列表,进入Service管理页面。
- 在需要更新 YAML 的 Service 行中,单击【编辑YAML】,进入更新 Service 页面。
- 在 “更新Service” 页面,编辑 YAML,单击【完成】,即可更新 YAML。
Kubectl 操作 Service 指引
YAML 示例
kind: Service
apiVersion: v1
metadata:
name: my-service
spec:
selector:
app: MyApp
ports:
- protocol: TCP
port: 80
targetPort: 9376
type: LoadBalancer
- kind:标识 Service 资源类型。
- metadata:Service 的名称、Label等基本信息。
- spec.type:标识 Service 的被访问形式
- ClusterIP:在集群内部公开服务,可用于集群内部访问。
- NodePort:使用节点的端口映射到后端 Service,集群外可以通过节点 IP:NodePort 访问。
- LoadBalancer:使用腾讯云提供的负载均衡器公开服务,默认创建公网 CLB, 指定 annotations 可创建内网 CLB。
- ExternalName:将服务映射到 DNS,仅适用于 kube-dns1.7及更高版本。
创建 Service
参考 YAML 示例,准备 StatefulSet YAML 文件。
安装 Kubectl,并连接集群。操作详情请参考 通过 Kubectl 连接集群。
执行以下命令,创建 Service YAML 文件。
kubectl create -f Service YAML 文件名称例如,创建一个文件名为 my-service.yaml 的 Service YAML 文件,则执行以下命令:
kubectl create -f my-service.yaml执行以下命令,验证创建是否成功。
kubectl get services返回类似以下信息,即表示创建成功。
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 172.16.255.1 <none> 443/TCP 38d
更新 Service
方法一
执行以下命令,更新 Service。
kubectl edit service/[name]
方法二
手动删除旧的 Service。
执行以下命令,重新创建 Service。
kubectl create/apply
删除 Service
执行以下命令,删除 Service。
kubectl delete service [NAME]
.params{margin-bottom:0px !important;}
3.1.3.2 - Ingress
Ingress 是允许访问到集群内 Service 的规则的集合,您可以通过配置转发规则,实现不同 URL 可以访问到集群内不同的 Service。
3.1.4 - 配置管理
配置管理
3.1.4.1 - ConfigMap
通过 ConfigMap 您可以将配置和运行的镜像进行解耦,使得应用程序有更强的移植性。ConfigMap 是有 key-value 类型的键值对,您可以通过控制台的 Kubectl 工具创建对应的 ConfigMap 对象,可以通过挂载数据卷、环境变量或在容器的运行命令中使用 ConfigMap。 ConfigMap 有两种使用方式,创建负载时做为数据卷挂载到容器和作为环境变量映射到容器。
ConfigMap 控制台操作指引
创建 ConfigMap
- 登录TKEStack,切换到【业务管理】控制台,选择左侧导航栏中的【应用管理】。
- 选择需要创建ConfigMap的【业务】下相应的【命名空间】,展开【配置管理】列表,进入ConfigMap管理页面。
- 单击【新建】,进入 “新建ConfigMap” 页面。如下图所示:

- 根据实际需求,设置 ConfigMap 参数。关键参数信息如下:
- 名称:自定义。
- 命名空间:根据实际需求进行选择命名空间类型
- 定义变量名和变量值。
- 单击【创建ConfigMap】,完成创建。
更新 ConfigMap
登录TKEStack,切换到业务管理控制台,选择左侧导航栏中的【应用管理】。
选择需要创建ConfigMap的业务下相应的命名空间,展开配置管理列表,进入ConfigMap管理页面。
在需要更新 YAML 的 ConfigMap 行中,单击【编辑YAML】,进入更新 ConfigMap 页面。
在 “更新ConfigMap” 页面,编辑 YAML,单击【完成】,即可更新 YAML。
如需修改 key-values,编辑 YAML 中 data 的参数值,单击【完成】,即可完成更新。
Kubectl 操作 ConfigMap 指引
YAML 示例
apiVersion: v1
data:
key1: value1
key2: value2
key3: value3
kind: ConfigMap
metadata:
name: test-config
namespace: default
- data:ConfigMap 的数据,以 key-value 形式呈现。
- kind:标识 ConfigMap 资源类型。
- metadata:ConfigMap 的名称、Label等基本信息。
- metadata.annotations:ConfigMap 的额外说明,可通过该参数设置腾讯云 TKE 的额外增强能力。
创建 ConfigMap
方式一:通过 YAML 示例文件方式创建
参考 YAML 示例,准备 ConfigMap YAML 文件。
安装 Kubectl,并连接集群。操作详情请参考 通过 Kubectl 连接集群。
执行以下命令,创建 ConfigMap YAML 文件。
kubectl create -f ConfigMap YAML 文件名称例如,创建一个文件名为 web.yaml 的 ConfigMap YAML 文件,则执行以下命令:
kubectl create -f web.yaml执行以下命令,验证创建是否成功。
kubectl get configmap返回类似以下信息,即表示创建成功。
NAME DATA AGE test 2 39d test-config 3 18d
方式二:通过执行命令方式创建
执行以下命令,在目录中创建 ConfigMap。
kubectl create configmap <map-name> <data-source>
- <map-name>:表示 ConfigMap 的名字。
- <data-source>:表示目录、文件或者字面值。
更多参数详情可参见 Kubernetes configMap 官方文档。
使用 ConfigMap
方式一:数据卷使用 ConfigMap 类型
YAML 示例如下:
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx:latest
volumeMounts:
name: config-volume
mountPath: /etc/config
volumes:
name: config-volume
configMap:
name: test-config ## 设置 ConfigMap 来源
## items: ## 设置指定 ConfigMap 的 Key 挂载
## key: key1 ## 选择指定 Key
## path: keys ## 挂载到指定的子路径
restartPolicy: Never
方式二:环境变量中使用 ConfigMap 类型
YAML 示例如下:
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx:latest
env:
- name: key1
valueFrom:
configMapKeyRef:
name: test-config ## 设置来源 ConfigMap 文件名
key: test-config.key1 ## 设置该环境变量的 Value 来源项
restartPolicy: Never
3.1.4.2 - Sercet
Sercet
Secret 可用于存储密码、令牌、密钥等敏感信息,降低直接对外暴露的风险。Secret 是 key-value 类型的键值对,您可以通过控制台的 Kubectl 工具创建对应的 Secret 对象,也可以通过挂载数据卷、环境变量或在容器的运行命令中使用 Secret。
Secret 控制台操作指引
创建 Secret
- 登录 TKEStack,切换到【业务管理】控制台,选择左侧导航栏中的【应用管理】。
- 选择需要创建 Secret 的【业务】下相应的【命名空间】,展开【配置管理】列表,进入 Secret 管理页面。
- 单击【新建】,进入“新建 Secret ”页面。
- 在“新建 Secret ”页面,根据实际需求,进行如下参数设置。如下图所示:

- 名称:请输入自定义名称。
- Secret类型:提供【Opaque】和【Dockercfg】两种类型,请根据实际需求进行选择。
- Opaque:适用于保存秘钥证书和配置文件,Value 将以 base64 格式编码。
- Dockercfg:适用于保存私有 Docker Registry 的认证信息。
- 生效范围:提供以下两种范围,请根据实际需求进行选择。
- 存量所有命名空间:不包括 kube-system、kube-public 和后续增量命名空间。
- 指定命名空间:支持选择当前集群下一个或多个可用命名空间。
- 内容:根据不同的 Secret 类型,进行配置。
- 当 Secret 类型为【Opaque】时:根据实际需求,设置变量名和变量值。
- 当 Secret 类型为【Dockercfg】时:
仓库域名:请根据实际需求输入域名或 IP。
用户名:请根据实际需求输入第三方仓库的用户名。
密码:请根据实际需求设置第三方仓库的登录密码。
如果本次为首次登录系统,则会新建用户,相关信息写入
~/.dockercrg文件中。
- 单击【创建 Secret】,即可完成创建。
使用 Secret
Secret 在 Workload中有三种使用场景: 1. 数据卷使用 Secret 类型 2. 环境变量中使用 Secret 类型 3. 使用第三方镜像仓库时引用
更新 Secret
登录 TKEStack,切换到业务管理控制台,选择左侧导航栏中的【应用管理】。
选择需要创建 Secret 的业务下相应的命名空间,展开配置管理列表,进入 Secret 管理页面。
在需要更新 YAML 的 Secret 行中,单击【编辑YAML】,进入更新 Secret 页面。
在“更新Secret”页面,编辑 YAML,并单击【完成】即可更新 YAML。
如需修改 key-values,则编辑 YAML 中 data 的参数值,并单击【完成】即可完成更新。
Kubectl 操作 Secret 指引
创建 Secret
方式一:通过指定文件创建 Secret
依次执行以下命令,获取 Pod 的用户名和密码。
$ echo -n 'username' > ./username.txt $ echo -n 'password' > ./password.txt执行 Kubectl 命令,创建 Secret。
$ kubectl create secret generic test-secret --from-file=./username.txt --from-file=./password.txt secret "testSecret" created执行以下命令,查看 Secret 详情。
kubectl describe secrets/ test-secret
方式二:YAML 文件手动创建
? 通过 YAML 手动创建 Secret,需提前将 Secret 的 data 进行 Base64 编码。
apiVersion: v1
kind: Secret
metadata:
name: test-secret
type: Opaque
data:
username: dXNlcm5hbWU= ## 由echo -n 'username' | base64生成
password: cGFzc3dvcmQ= ## 由echo -n 'password' | base64生成
使用 Secret
方式一: 数据卷使用 Secret 类型
YAML 示例如下:
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx:latest
volumeMounts:
name: secret-volume
mountPath: /etc/config
volumes:
name: secret-volume
secret:
name: test-secret ## 设置 secret 来源
## items: ## 设置指定 secret的 Key 挂载
## key: username ## 选择指定 Key
## path: group/user ## 挂载到指定的子路径
## mode: 256 ## 设置文件权限
restartPolicy: Never
方式二: 环境变量中使用 Secret 类型
YAML 示例如下:
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx:latest
env:
- name: SECRET_USERNAME
valueFrom:
secretKeyRef:
name: test-secret ## 设置来源 Secret 文件名
key: username ## 设置该环境变量的 Value 来源项
restartPolicy: Never
方法三:使用第三方镜像仓库时引用
YAML 示例如下:
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx:latest
imagePullSecrets:
- name: test-secret ## 设置来源 Secret 文件名
restartPolicy: Never
3.1.5 - 存储
存储
3.1.5.1 - PV和PVC
PersistentVolume(PV):集群内的存储资源。例如,节点是集群的资源。PV 独立于 Pod 的生命周期,根据不同的 StorageClass 类型创建不同类型的 PV。 PersistentVolumeClaim(PVC):集群内的存储请求。例如,PV 是 Pod 使用节点资源,PVC 则声明使用 PV 资源。当 PV 资源不足时,PVC 也可以动态创建 PV。
3.1.5.2 - StorageClass
StorageClass 描述存储的类型,集群管理员可以为集群定义不同的存储类别。可通过 StorageClass 配合 PersistentVolumeClaim 可以动态创建需要的存储资源。
3.1.6 - 事件
日志针对的是容器。包括了 Kuberntes 集群的运行容器的日志情况和各类资源的调度情况,对维护人员日常观察资源的变更以及定位问题均有帮助。
日志控制台操作指引
- 登录 TKEStack,切换到【业务管理】控制台,点击【应用管理】,选择【日志】。
- 进入“日志”页面。
- 可以按照不用的命名空间和资源类型进行筛选。

注意:Kubernetes 默认只将最近一个小时的事件存储在 ETCD 中,若想实现事件的持久化存储和查询操作
您可以参考 事件持久化 将事件导入外部存储,实现事件的持久化存储
3.1.7 - 日志
时间针对的是负载。Kubernetes Events 包括了 Kuberntes 集群的运行和各类资源的调度情况,对维护人员日常观察资源的变更以及定位问题均有帮助。
Event 控制台操作指引
- 登录 TKEStack,切换到【业务管理】控制台,点击【应用管理】中的【事件】,进入“事件”页面。
- 可以按照不用的命名空间和资源类型进行筛选。

您可以参考 日志采集 将日志导入外部存储,实现日志的高级管理。
3.2 - 业务管理
这里用户可以管理业务。
更改业务成员
登录 TKEStack。
切换至 【业务管理】控制台,点击【业务管理】。
在“业务管理”页面中,可以看到已创建的业务列表。鼠标移动到要修改的业务上(无需点击),成员列会出现修改图标按钮。如下图所示:
注意:修改业务成员仅限状态为Active的业务,这里可以新建和删除成员。
查看业务监控
登录 TKEStack。
切换至 【业务管理】控制台,点击【业务管理】。
在“业务管理”页面中,可以看到已创建的业务列表。点击监控按钮,如下图所示:
在右侧弹出窗口里查看业务监控情况,如下图所示:
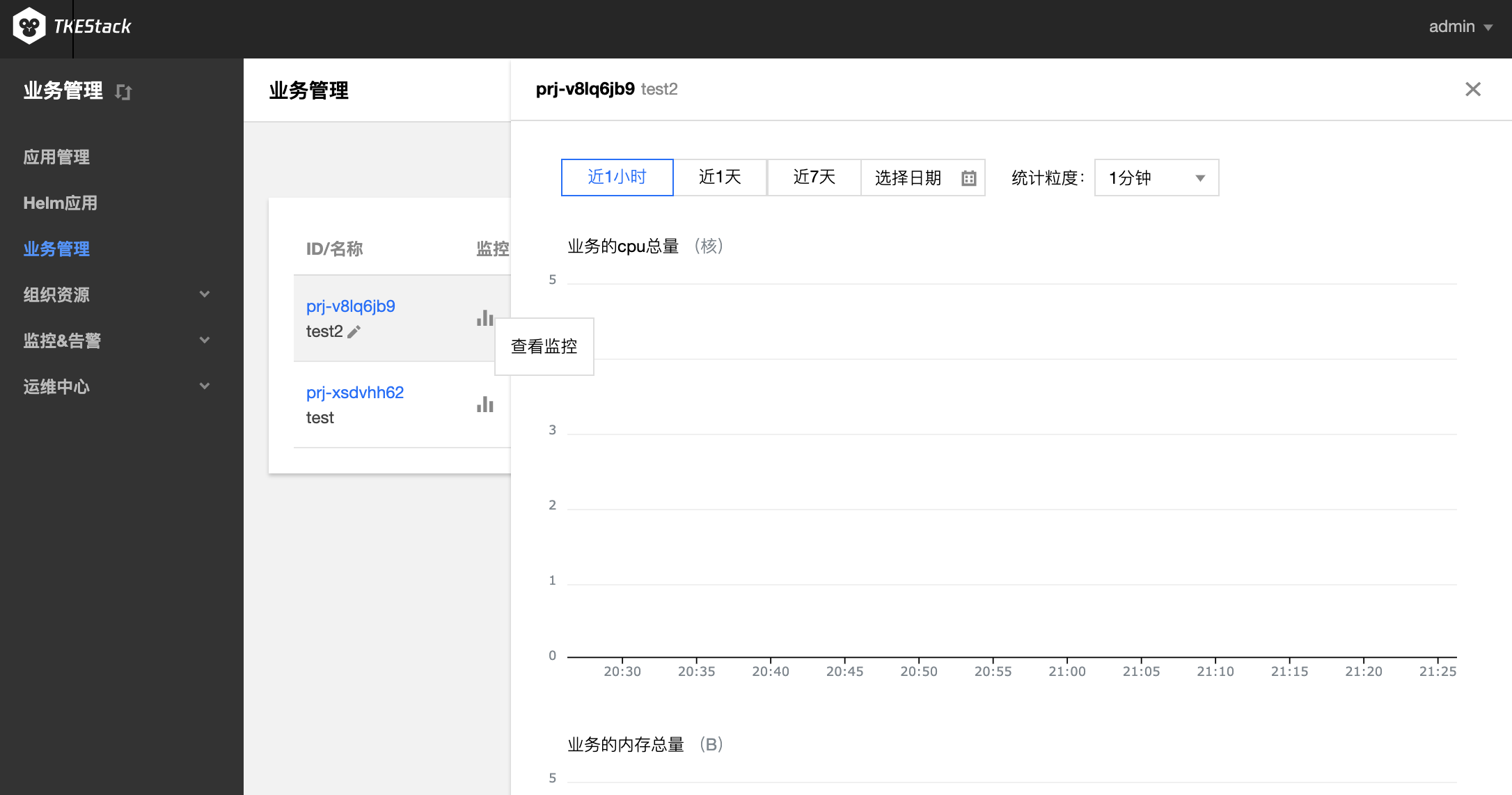
删除业务
登录 TKEStack。
切换至 【业务管理】控制台,点击【业务管理】。
在“业务管理”页面中,可以看到已创建的业务列表。点击删除按钮,如下图所示:
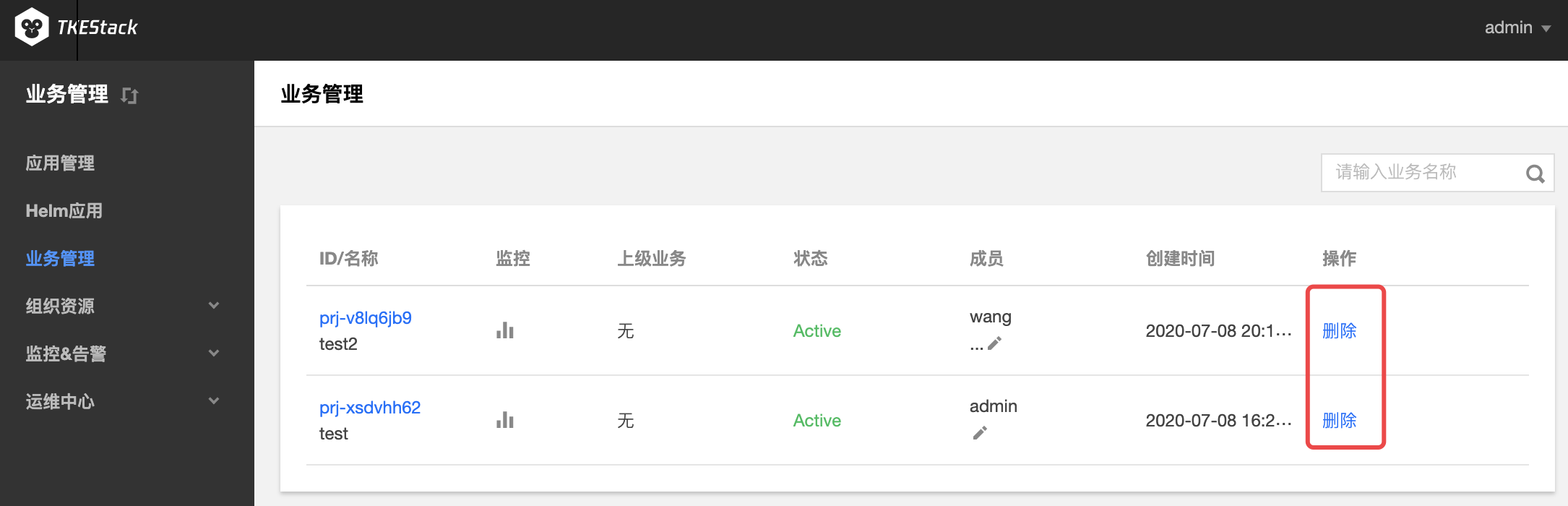
注意:删除业务成员仅限状态为Active的业务
对业务的操作
- 登录 TKEStack。
- 在【业务管理】控制台的【业务管理】中,单击【业务id】。如下图所示:
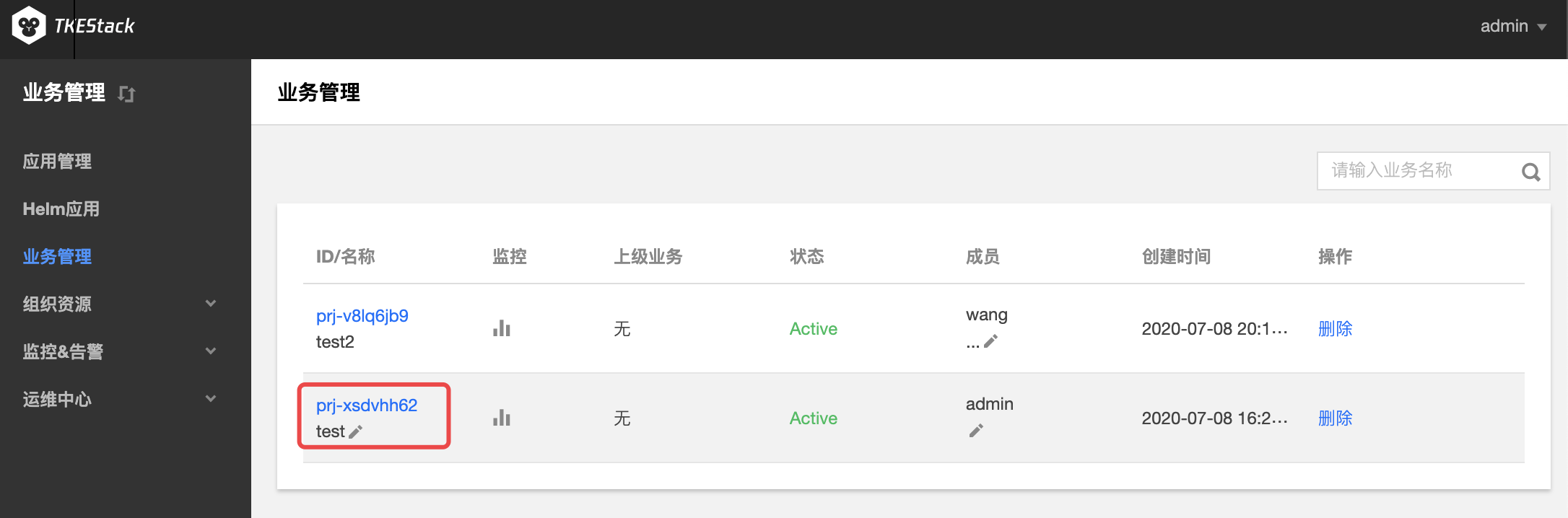
a. 业务信息: 在这里可以对业务名称、关联的集群、关联集群的资源进行限制等操作。
b. 成员列表: 在这里可以对业务名称、关联的集群、关联集群的资源进行限制等操作。
c. 子业务: 在这里可以新建本业务的子业务或通过导入子业务将已有业务变成本业务的子业务
d. 业务下Namespace列表: 这里可以管理业务下的Namespace
单击【新建Namespace】。在“新建Namespace”页面中,填写相关信息。如下图所示:
名称:不能超过63个字符,这里以new-ns为例
集群:my-business业务中的集群,这里以global集群为例
资源限制*:这里可以限制当前命名空间下各种资源的使用量,可以不设置。
3.3 - 组织资源
组织资源
3.3.1 - 镜像仓库管理
这里用户可以管理镜像仓库。
注意:TKEStack的【业务管理】控制台不支持命名空间的创建,可以在【平台管理】下的【组织资源】下的【镜像仓库管理】新建命名空间。
删除命名空间
- 登录 TKEStack。
- 切换至 【业务管理】控制台,选择 【组织资源】->【仓库管理】。点击列表最右侧【删除】按钮。如下图所示:
- 点击【确认】

镜像上传
- 登录 TKEStack。
- 切换至 【业务管理】控制台,选择 【组织资源】->【仓库管理】,查看“命名空间”列表。点击列表中命名空间【名称】。如下图所示:

此时进入了“镜像列表”页面,点击【镜像上传指引】按钮。如下图所示:
注意:此页面可以通过上传的镜像最右边的【删除】按钮来删除上传的镜像

- 根据指引内容,在物理节点上执行相应命令。如下图所示:

3.3.2 - Helm模板
应用功能是 TKEStack 集成的 Helm 3.0 相关功能,为您提供创建 helm chart、容器镜像、软件服务等各种产品和服务的能力。已创建的应用将在您指定的集群中运行,为您带来相应的能力。
模板
登录 TKEStack
切换至 【平台管理】控制台,选择 【组织资源】->【 Helm模板】,点击【模板】 1. 所有模板:包含下列所有模板 2. 用户模板:权限范围为“指定用户”的仓库下的所有模板 3. 业务模板:权限范围为“指定业务”的仓库下的所有模板 4. 公共模板:权限范围为“公共”的仓库下的所有模板
仓库
登录 TKEStack
切换至 【平台管理】控制台,选择 【组织资源】->【 Helm模板】,点击【仓库】
点击【新建】按钮,如下图所示:
在弹出的 “新建仓库” 页面,填写 仓库 信息,如下图所示:
仓库名称: 仓库名字,不超过60个字符
权限访问
- 指定用户:选择当前仓库可以被哪些平台的用户访问
- 指定业务:选择当前仓库可以被哪些平台的业务访问,业务下的成员对该仓库的访问权限在【业务管理】中完成
- 公共:平台所有用户都能访问该仓库
导入第三方仓库: 若已有仓库想导入 TKEStack 中使用,请勾选
- 第三方仓库地址:请输入第三方仓库地址
- 第三方仓库用户名:若第三方仓库开启了鉴权,需要输入第三方仓库的用户名
- 第三方仓库密码:若第三方仓库开启了鉴权,需要输入第三方仓库的密码
仓库描述: 请输入仓库描述,不超过255个字符
单击【确认】按钮
删除仓库
登录 TKEStack
切换至 【平台管理】控制台,选择 【组织资源】-> 【 Helm 模板】,点击【仓库】,查看 “helm模板仓库”列表
点击列表最右侧【删除】按钮,如下图所示:
Chart 上传指引
登录 TKEStack
切换至 【平台管理】控制台,选择 【组织资源】-> 【 Helm模板】,点击【仓库】,查看 “helm模板仓库”列表
点击列表最右侧【上传指引】按钮,如下图所示:
根据指引内容,在物理节点上执行相应命令,如下图所示:
同步导入仓库
登录 TKEStack
切换至 【平台管理】控制台,选择 【组织资源】->【 Helm模板】,点击【仓库】
点击导入仓库的【同步仓库】按钮,如下图所示:
3.3.3 - 访问凭证
这里用户可以管理自己的凭据。
新建访问凭证
- 登录 TKEStack。
- 切换至 【业务管理】控制台,选择【组织资源】->【访问凭证】,点击【新建】按钮。
- 在弹出“创建访问凭证”页面,填写凭证信息。如下图所示:
- 凭证描述:描述当前凭证信息
- 过期时间:填写过期时间,选择小时/分钟为单位
- 单击【确认】按钮


停用/启用/删除访问凭证
登录 TKEStack。
切换至 【业务管理】控制台,选择 【组织资源】-> 【访问凭证】,查看“访问凭证”列表。单击列表右侧【禁用】/【启用】/【删除】按钮。如下图所示:
注意:点击【禁用】之后,【禁用】按钮就变成了【启用】
单击【确认】按钮

3.4 - 监控与告警
监控与告警
3.4.1 - 设置告警
概念
这里用户配置平台告警。
前提条件
- 需要设置告警的命名空间所在的集群,应该先在【扩展组件】安装Prometheus组件
操作步骤
新建告警设置
- 登录 TKEStack。
- 切换至【业务管理】控制台,选择【监控&告警】-> 【告警设置】,查看“告警设置”列表。
- 选择相应【项目】和【namespace】,点击【新建】按钮。如下图所示:

- 在“新建策略”页面填写告警策略信息。如下图所示:

- 告警策略名称: 输入告警策略名称,最长60字符
- 策略类型: 选择告警策略应用类型
- 集群: 集群监控告警
- Pod: Pod 监控告警
- 告警对象: 选择Pod相关的告警对象,支持对namespace下不同对deployment、stateful和daemonset 进行监控报警
- 按工作负载选择: 选择namespace下的某个工作负载
- 全部选择: 不区分namespace,全部监控
- 告警对象: 选择Pod相关的告警对象,支持对namespace下不同对deployment、stateful和daemonset 进行监控报警
- 节点: 节点监控告警
- 统计周期: 选择数据采集周期,支持1、2、3、4、5分钟
- 指标: 选择告警指标,支持对监测值与指标值进行【大于/小于】比较,选择结果持续周期。如下图:

- 接收组: 选择接收组,当出现满足条件当报警信息时,向组内人员发送消息。接收组需要先在 通知设置 创建
- 通知方式: 选择通知渠道和消息模版。通知渠道 和 消息模版需要先在 通知设置 创建
- 添加通知方式 如需要添加多种通知方式,点击该按钮。
- 单击【提交】按钮。
- 添加通知方式 如需要添加多种通知方式,点击该按钮。
复制告警设置
- 登录 TKEStack。
- 切换至【业务管理】控制台,选择 【监控&告警】->【告警设置】,查看告警设置列表。
- 选择相应【项目】和【namespace】,点击“告警设置”列表最右侧的【复制】按钮。如下图所示:

在复制策略页面,编辑告警策略信息。
单击【提交】按钮。
编辑告警设置
登录 TKEStack。
切换至 【业务管理】控制台,选择 【监控&告警】->【告警设置】,查看告警设置列表。
选择相应【项目】和【namespace】,点击【告警名称】。如下图所示:

- 在“告警策略详情”页面,单击【基本信息】右侧的【编辑】按钮。如下图所示:

在更新策略页面,编辑策略信息。
单击【提交】按钮。
删除告警设置
登录 TKEStack。
切换至 【业务管理】控制台,选择 【监控&告警】->【告警设置】,查看“告警设置”列表。
选择相应【项目】和【namespace】,点击列表最右侧的【删除】按钮。如下图所示:

- 在弹出的删除告警窗口,单击【确定】按钮。
3.4.2 - 通知设置
概念
这里用户配置平台通知。
操作步骤
这部分和【平台管理】控制台下【监控&告警】下的【通知设置】完全一致。故这里使用【平台管理】控制台下的截图。
通知渠道
新建通知渠道
- 登录 TKEStack。
- 切换至【业务管理】控制台,选择 【监控&告警】->【通知设置】->【通知渠道】,查看“通知渠道”列表。
- 点击【新建】按钮。如下图所示:

- 在“新建通知渠道”页面填写渠道信息。如下图所示:

- 名称: 填写渠道名称
- 渠道: 选择渠道类型,输入渠道信息
- 邮件: 邮件类型
- email: 邮件发送放地址
- password: 邮件发送方密码
- smtpHost: smtp IP地址
- smtpPort: smtp端口
- tls: 是否tls加密
- 短信: 短信方式
- appKey: 短信发送方的appKey
- sdkAppID: sdkAppID
- extend: extend 信息
- 微信公众号: 微信公众号方式
- appID: 微信公众号appID
- appSecret: 微信公众号app密钥
- 单击【保存】按钮。
编辑通知渠道
- 登录 TKEStack。
- 切换至【业务管理】控制台,选择 【监控&告警】->【通知设置】->【通知渠道】,查看“通知渠道”列表。
- 单击渠道名称。如下图所示:

- 在“基本信息”页面,单击【基本信息】右侧的【编辑】按钮。如下图所示:

- 在“更新渠道通知”页面,编辑渠道信息。
- 单击【保存】按钮。
删除通知渠道
- 登录 TKEStack。
- 切换至【业务管理】控制台,选择 【监控&告警】->【通知设置】->【通知渠道】,查看“通知渠道”列表。
- 选择要删除的渠道,点击【删除】按钮。如下图所示:

- 单击删除窗口的【确定】按钮。
通知模板
新建通知模版
- 登录 TKEStack。
- 切换至【业务管理】控制台,选择 【监控&告警】->【通知设置】->【通知模板】,查看“通知模板”列表。
- 点击【新建】按钮。如下图所示:

- 在“新建通知模版”页面填写模版信息。如下图所示:

- 名称: 模版名称
- 渠道: 选择已创建的渠道
- body: 填写消息body体
- header: 填写消息标题
- 单击【保存】按钮。
编辑通知模版
- 登录 TKEStack。
- 切换至【业务管理】控制台,选择 【监控&告警】->【通知设置】->【通知模板】,查看“通知模板”列表。
- 单击模版名称。如下图所示:

- 在基本信息页面,单击【基本信息】右侧的【编辑】按钮。如下图所示:

- 在“更新通知模版”页面,编辑模版信息。
- 单击【保存】按钮。
删除通知模版
- 登录 TKEStack。
- 切换至【业务管理】控制台,选择 【监控&告警】->【通知设置】->【通知模板】,查看"通知模板"列表。
- 选择要删除的模版,点击【删除】按钮。如下图所示:

- 单击删除窗口的【确定】按钮。
接收人
新建接收人
- 登录 TKEStack。
- 切换至【业务管理】控制台,选择 【监控&告警】->【通知设置】->【接收人】,查看"接收人"列表。
- 点击【新建】按钮。如下图所示:

- 在“新建接收人”页面填写模版信息。如下图所示:

- 显示名称: 接收人显示名称
- 用户名: 接收人用户名
- 移动电话: 手机号
- 电子邮件: 接收人邮箱
- 微信OpenID: 接收人微信ID
- 单击【保存】按钮。
编辑接收人信息
- 登录 TKEStack。
- 切换至【业务管理】控制台,选择 【监控&告警】->【通知设置】->【接收人】,查看“接收人”列表。
- 单击接收人名称。如下图所示:

- 在“基本信息”页面,单击【基本信息】右侧的【编辑】按钮。如下图所示:

- 在“更新接收人”页面,编辑接收人信息。
- 单击【保存】按钮。
删除接收人
- 登录 TKEStack。
- 切换至【业务管理】控制台,选择 【监控&告警】->【通知设置】->【接收人】,查看“接收人”列表。
- 选择要删除的接收人,点击【删除】按钮。如下图所示:

- 单击删除窗口的【确定】按钮。
接收组
新建接收组
- 登录 TKEStack。
- 切换至【业务管理】控制台,选择 【监控&告警】->【通知设置】->【接收组】,查看“接收组”列表。
- 点击【新建】按钮。如下图所示:

- 在“新建接收组”页面填写模版信息。如下图所示:

- 名称: 接收组显示名称
- 接收组: 从列表里选择接收人。如没有想要的接收人,请在接收人里创建。
- 单击【保存】按钮。
编辑接收组信息
- 登录 TKEStack。
- 切换至【业务管理】控制台,选择 【监控&告警】->【通知设置】->【接收组】,查看“接收组”列表。
- 单击接收组名称。如下图所示:

- 在“基本信息”页面,单击【基本信息】右侧的【编辑】按钮。如下图所示:

- 在“更新接收组”页面,编辑接收组信息。
- 单击【保存】按钮。
删除接收组
- 登录 TKEStack。
- 切换至【业务管理】控制台,选择 【监控&告警】->【通知设置】->【接收组】,查看“接收组”列表。
- 选择要删除的接收组,点击【删除】按钮。如下图所示:

- 单击删除窗口的【确定】按钮。
3.5 - 运维中心
运维中心
3.5.1 - Helm应用
应用功能是 TKEStack 集成的 Helm 3.0 相关功能,为您提供创建 helm chart、容器镜像、软件服务等各种产品和服务的能力。已创建的应用将在您指定的集群中运行,为您带来相应的能力。
新建 Helm 应用
- 登录 TKEStack
- 切换至【平台管理】控制台,选择【运维中心】->【 Helm 应用】
- 选择相应【集群】,单击【新建】按钮,如下图所示:
- 在“新建 Helm 应用”页面填写Helm应用信息,如下图所示:
- 应用名称: 输入应用名,1~63字符,只能包含小写字母、数字及分隔符("-"),且必须以小写字母开头,数字或小写字母结尾
- 运行集群: 选择应用所在集群
- 命名空间: 选择应用所在集群的命名空间
- 类型: 当前仅支持 HelmV3
- Chart: 选择需要部署的 chart
- Chart版本: 选择 chart 的版本
- 参数: 更新时如果选择不同版本的 Helm Chart,参数设置将被覆盖
- 拟运行: 会返回模板渲染清单,即最终将部署到集群的 YAML 资源,不会真正执行安装
- 单击【完成】按钮
删除 Helm 应用
- 登录 TKEStack
- 切换至【平台管理】控制台,选择【运维中心】->【 Helm 应用】
- 点击【删除】
查看 Helm 应用资源列表
- 登录 TKEStack
- 切换至【平台管理】控制台,选择【运维中心】->【 Helm 应用】
- 点击【应用名】后,点击【资源列表】,可查看该应用所有 Kubernetes 资源对象
查看 Helm 应用详情
- 登录 TKEStack
- 切换至【平台管理】控制台,选择【运维中心】->【 Helm 应用】
- 点击【应用名】后,点击【应用详情】
查看 Helm 应用版本历史
- 登录 TKEStack
- 切换至【平台管理】控制台,选择【运维中心】->【 Helm 应用】
- 点击【应用名】后,点击【版本历史】,可查看该应用所部署的历史版本。可以通过选择不同的版本进行参数对比查看其版本区别
3.5.2 - 日志采集
TKESTack 提供的集群内日志采集功能,支持将集群内服务或集群节点特定路径文件的日志发送至 Kafka、Elasticsearch 等消费端,支持采集容器标准输出日志,容器内文件日志以及主机内文件日志。更提供事件持久化、审计等功能,实时记录集群事件及操作日志记录,帮助运维人员存储和分析集群内部资源生命周期、资源调度、异常告警等情况

日志收集功能需要为每个集群手动开启。日志收集功能开启后,日志收集组件 logagent 会在集群内以 Daemonset 的形式运行。用户可以通过日志收集规则配置日志的采集源和消费端,日志收集 Agent 会从用户配置的采集源进行日志收集,并将日志内容发送至用户指定的消费端。需要注意的是,使用日志收集功能需要您确认 Kubernetes 集群内节点能够访问日志消费端。
- 采集容器标准输出日志 :采集集群内指定容器的 Stderr 和 Stdout 日志。,采集到的日志信息将会以 JSON 格式输出到用户指定的消费端,并会自动附加相关的 Kubernetes metadata, 包括容器所属 Pod 的 label 和 annotation 等信息。
- 采集容器内文件日志 :采集集群内指定容器内文件路径的日志,用户可以根据自己的需求,灵活的配置所需的容器和路径,采集到的日志信息将会以 JSON 格式输出到用户指定的消费端, 并会附加相关的 Kubernetes metadata,包括容器所属 pod 的 label 和 annotation 等信息。
- 采集主机内文件日志 :采集集群内所有节点的指定主机文件路径的日志,logagent 会采集集群内所有节点上满足指定路径规则的文件日志,以 JSON 格式输出到用户指定的输出端, 并会附加用户指定的 metadata,包括日志来源文件的路径和用户自定义的 metadata。
注意:日志采集对接外部 Kafka 或 Elasticsearch,该功能需要额外开启,位置在集群 基本信息 下面,点击开启“日志采集”服务

使用日志采集服务
业务管理侧
- 登录 TKEStack
- 切换至【业务管理】控制台,选择 【运维中心】->【日志采集】
- 选择相应【业务】和【命名空间】,单击【新建】按钮,如下图所示:

- 在“新建日志采集”页面填写日志采集信息,如下图所示:

- 收集规则名称: 输入规则名,1~63字符,只能包含小写字母、数字及分隔符("-"),且必须以小写字母开头,数字或小写字母结尾
- 业务: 选择所属业务(业务管理侧才会出现)
- 集群: 选择所属集群(平台管理侧才会出现)
- 类型: 选择采集类型
- 容器标准输出: 容器 Stderr 和 Stdout 日志信息采集
- 日志源: 可以选择所有容器或者某个 Namespace 下的所有容器/工作负载
- 所有容器: 所有容器
- 指定容器: 某个 Namespace 下的所有容器或者工作负载
- 日志源: 可以选择所有容器或者某个 Namespace 下的所有容器/工作负载
- 容器文件路径: 容器内文件内容采集
日志源: 可以采集具体容器内的某个文件路径下的文件内容
- 工作负载选项: 选择某个 Namespace 下的某种工作负载类型下的某个工作负载
- 配置采集路径: 选择某个容器下的某个文件路径
- 文件路径若输入
stdout,则转为容器标准输出模式 - 可配置多个路径。路径必须以
/开头和结尾,文件名支持通配符(*)。文件路径和文件名最长支持63个字符 - 请保证容器的日志文件保存在数据卷,否则收集规则无法生效,详见指定容器运行后的日志目录
- 节点文件路径: 收集节点上某个路径下的文件内容
- 日志源: 可以采集具体节点内的某个文件路径下的文件内容
- 收集路径: 节点上日志收集路径。路径必须以
/开头和结尾,文件名支持通配符(*)。文件路径和文件名最长支持63个字符
- 收集路径: 节点上日志收集路径。路径必须以
- metadata: key:value 格式,收集的日志会带上 metadata 信息上报给消费端
- 日志源: 可以采集具体节点内的某个文件路径下的文件内容
- 容器标准输出: 容器 Stderr 和 Stdout 日志信息采集
- 消费端: 选择日志消费端
- Kafka:
- 访问地址: Kafka IP 和端口
- 主题(Topic): Kafka Topic 名
- Elasticsearch:
Elasticsearch 地址: ES 地址,如:http://190.0.0.1:200
注意:当前只支持未开启用户登录认证的 ES 集群
索引: ES索引,最长60个字符,只能包含小写字母、数字及分隔符("-"、"_"、"+"),且必须以小写字母开头
- Kafka:
- 单击【完成】按钮
平台管理侧
在平台管理侧也支持日志采集规则的创建,创建方式和业务管理处相同。详情可点击平台侧的日志采集。
指定容器运行后的日志目录
LogAgent 除了支持日志规则的创建,也支持指定容器运行后的日志目录,可实现日志文件展示和下载。
前提:需要在创建负载时挂载数据卷,并指定日志目

创建负载以后,在容器内的/data/logdir目录下的所有文件可以展示并下载,例如我们在容器的/data/logdir下新建一个名为a.log的文件,如果有内容的话,也可以在这里展示与下载

3.6 -
Helm应用
概念
这里业务端用户可以管理通过 helm 创建的应用。
操作步骤
新建Helm应用
- 登录 TKEStack。
- 切换至 【业务管理】控制台,选择【 Helm应用】。
- 选择相应【业务】和【namespace】,单击【新建】按钮。如下图所示:
- 在“新建Helm应用”页面填写Helm应用信息。如下图所示:
- 应用名: 输入应用名,1~63字符,只能包含小写字母、数字及分隔符("-"),且必须以小写字母开头,数字或小写字母结尾
- 命名空间: 选择该应用运行的命名空间
- Chart_Url: 输入Chart 文件地址
- 类型: 选择应用类型
- 公有: 公有类型
- 私有: 私有类型
- 用户名: 私有用户名
- 密码: 私有密码
- Key-Value: 通过Key-Value替换Chart包中默认配置。
- 单击【完成】按钮。

