工作负载的请求与限制
工作负载的请求与限制
Request:容器使用的最小资源需求,作为容器调度时资源分配的判断依赖。只有当节点上可分配资源量 >= 容器资源请求数时才允许将容器调度到该节点。但 Request 参数不限制容器的最大可使用资源值。 Limit: 容器能使用的资源最大值。
! 更多 Limit 和 Request 参数介绍,单击 查看详情。
CPU 限制说明
CPU 资源允许设置 CPU 请求和 CPU 限制的资源量,以核(U)为单位,允许为小数。
!
- CPU Request 作为调度时的依据,在创建时为该容器在节点上分配 CPU 使用资源,称为 “已分配 CPU” 资源。
- CPU Limit 限制容器 CPU 资源的上限,不设置表示不做限制(CPU Limit >= CPU Request)。
内存限制说明
内存资源只允许限制容器最大可使用内存量。以 MiB 为单位,允许为小数。
!
- 内存 Request 作为调度时的依据,在创建时为该容器在节点上分配内存,称为 “已分配内存” 资源。
- 内存资源为不可伸缩资源。当节点上所有容器使用内存均超量时,存在 OOM 的风险。因此不设置 Limit 时,默认 Limit = Request,保证容器的正常运作。
CPU 使用量和 CPU 使用率
- CPU 使用量为绝对值,表示实际使用的 CPU 的物理核数,CPU 资源请求和 CPU 资源限制的判断依据都是 CPU 使用量。
- CPU 使用率为相对值,表示 CPU 的使用量与 CPU 单核的比值(或者与节点上总 CPU 核数的比值)。
使用示例
一个简单的示例说明 Request 和 Limit 的作用,测试集群包括1个 4U4G 的节点、已经部署的两个 Pod ( Pod1,Pod2 ),每个 Pod 的资源设置为(CPU Requst,CPU Limit,Memory Requst,Memory Limit)=(1U,2U,1G,1G)。(1.0G = 1000MiB) 节点上 CPU 和内存的资源使用情况如下图所示: 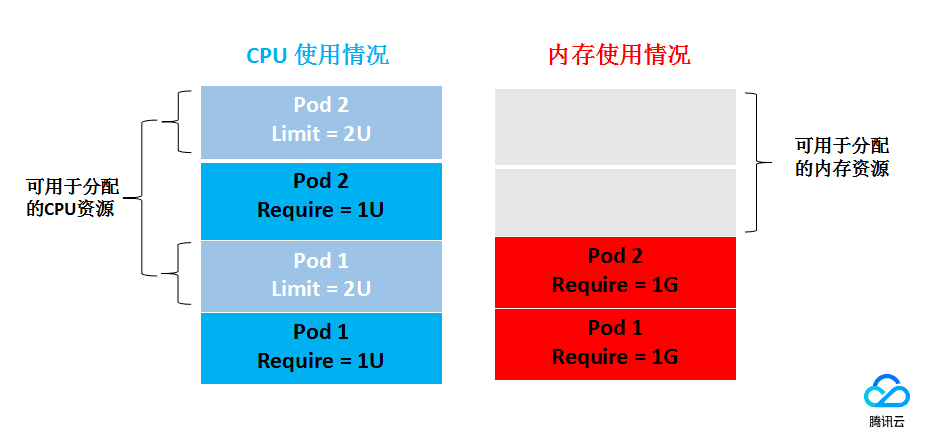 已经分配的 CPU 资源为:1U(分配 Pod1) + 1U(分配 Pod2) = 2U,剩余可以分配的 CPU 资源为2U。 已经分配的内存资源为:1G(分配 Pod1) + 1G(分配 Pod2) = 2G,剩余可以分配的内存资源为2G。 所以该节点可以再部署一个 ( CPU Requst, Memory Requst ) =( 2U,2G )的 Pod 部署,或者部署2个(CPU Requst,Memory Requst) = (1U,1G) 的 Pod 部署。
已经分配的 CPU 资源为:1U(分配 Pod1) + 1U(分配 Pod2) = 2U,剩余可以分配的 CPU 资源为2U。 已经分配的内存资源为:1G(分配 Pod1) + 1G(分配 Pod2) = 2G,剩余可以分配的内存资源为2G。 所以该节点可以再部署一个 ( CPU Requst, Memory Requst ) =( 2U,2G )的 Pod 部署,或者部署2个(CPU Requst,Memory Requst) = (1U,1G) 的 Pod 部署。
在资源限制方面,每个 Pod1 和 Pod2 使用资源的上限为 ( 2U,1G ),即在资源空闲的情况下,Pod 使用 CPU 的量最大能达到2U。
服务资源限制推荐
CCS 会根据您当前容器镜像的历史负载来推荐 Request 与 Limit 值,使用推荐值会保证您的容器更加平稳的运行,大大减小出现异常的概率。
推荐算法: 我们首先会取出过去7天当前容器镜像分钟级别负载,并辅以百分位统计第95%的值来最终确定推荐的 Request,Limit 为 Request 的2倍。
Request = Percentile(实际负载[7d],0.95)
Limit = Request * 2
如果当前的样本数量(实际负载)不满足推荐计算的数量要求,我们会相应的扩大样本取值范围,尝试重新计算。例如,去掉镜像 tag,namespace,serviceName 等筛选条件。若经过多次计算后同样未能得到有效值,则推荐值为空。
推荐值为空: 在使用过程中,您会发现有部分值暂无推荐的情况,可能由于以下几点造成: 1. 当前数据并不满足计算的需求,我们需要待计算的样本数量(实际负载)大于1440个,即有一天的数据。 2. 推荐值小于您当前容器已经配置的 Request 或者 Limit。
! 1. 由于推荐值是根据历史负载来计算的,原则上,容器镜像运行真实业务的时间越长,推荐的值越准确。 2. 使用推荐值创建服务,可能会因为集群资源不足造成容器无法调度成功。在保存时,须确认当前集群的剩余资源。 3. 推荐值是建议值,您可以根据自己业务的实际情况做相应的调整。