扩展组件
概念
这里用户可以管理集群扩展组件。
操作步骤
创建组件
- 登录 TKEStack。
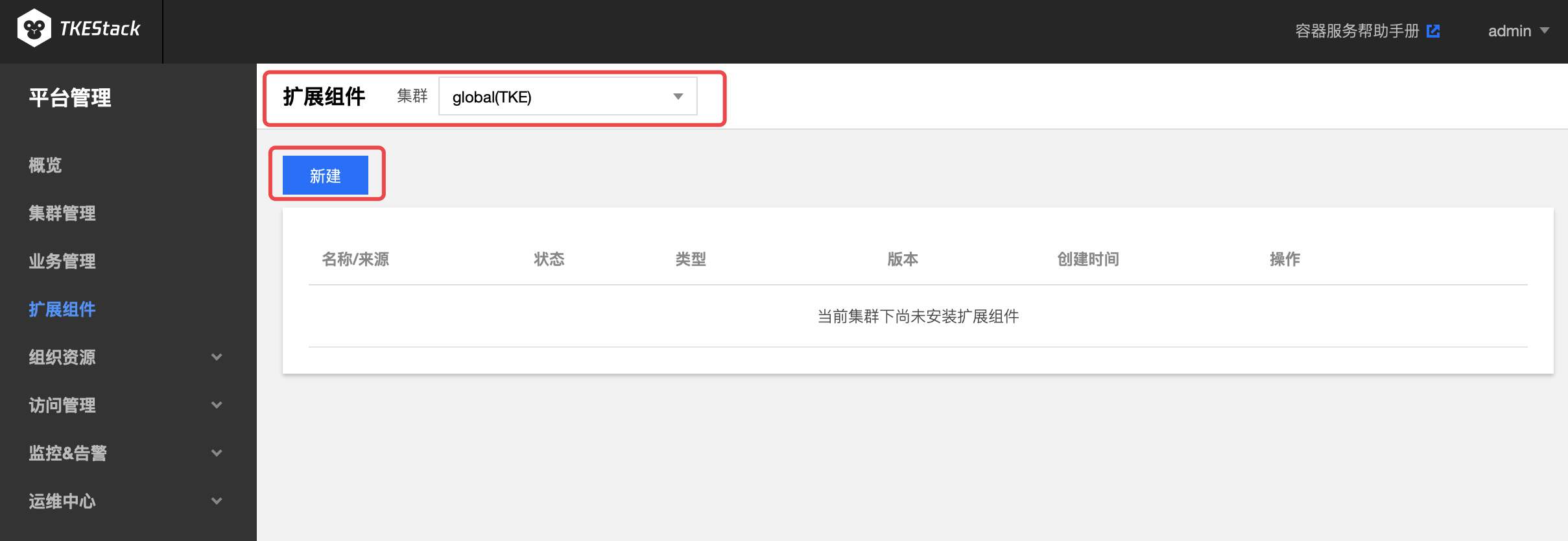
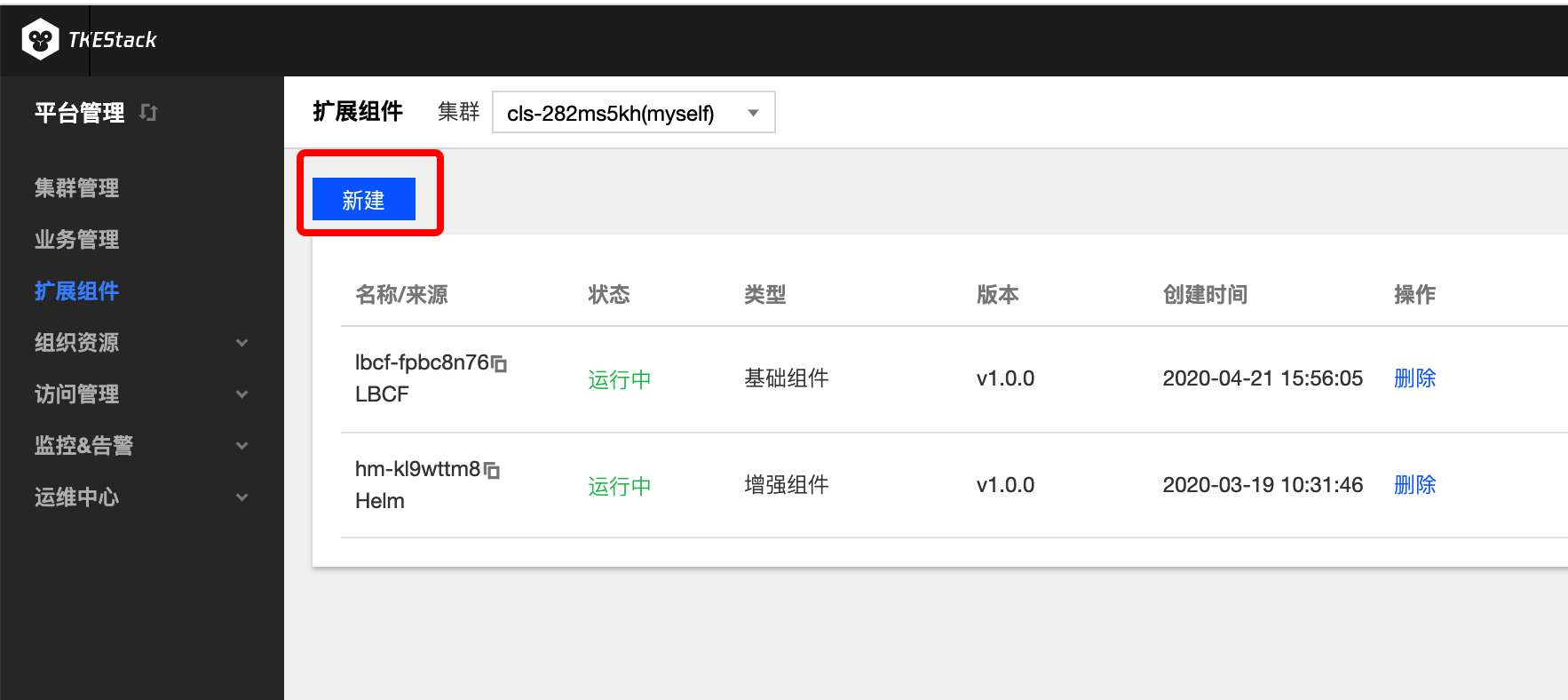
- 切换至 【平台管理】控制台,选择【扩展组件】页面。
- 选择需要安装组件的集群,点击【新建】按钮。如下图所示:
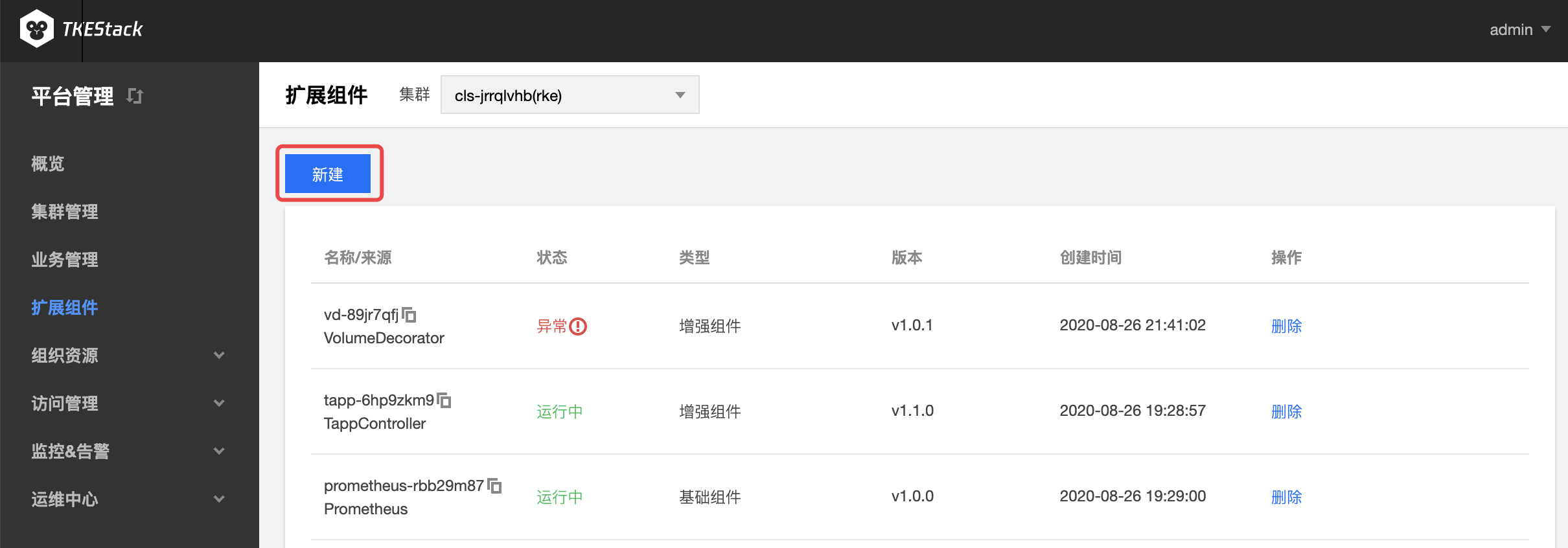
注意:此页面右边的【删除】按钮可以删除安装了的组件
- 在弹出的扩展组件列表里,选择要安装的组件。如下图所示:
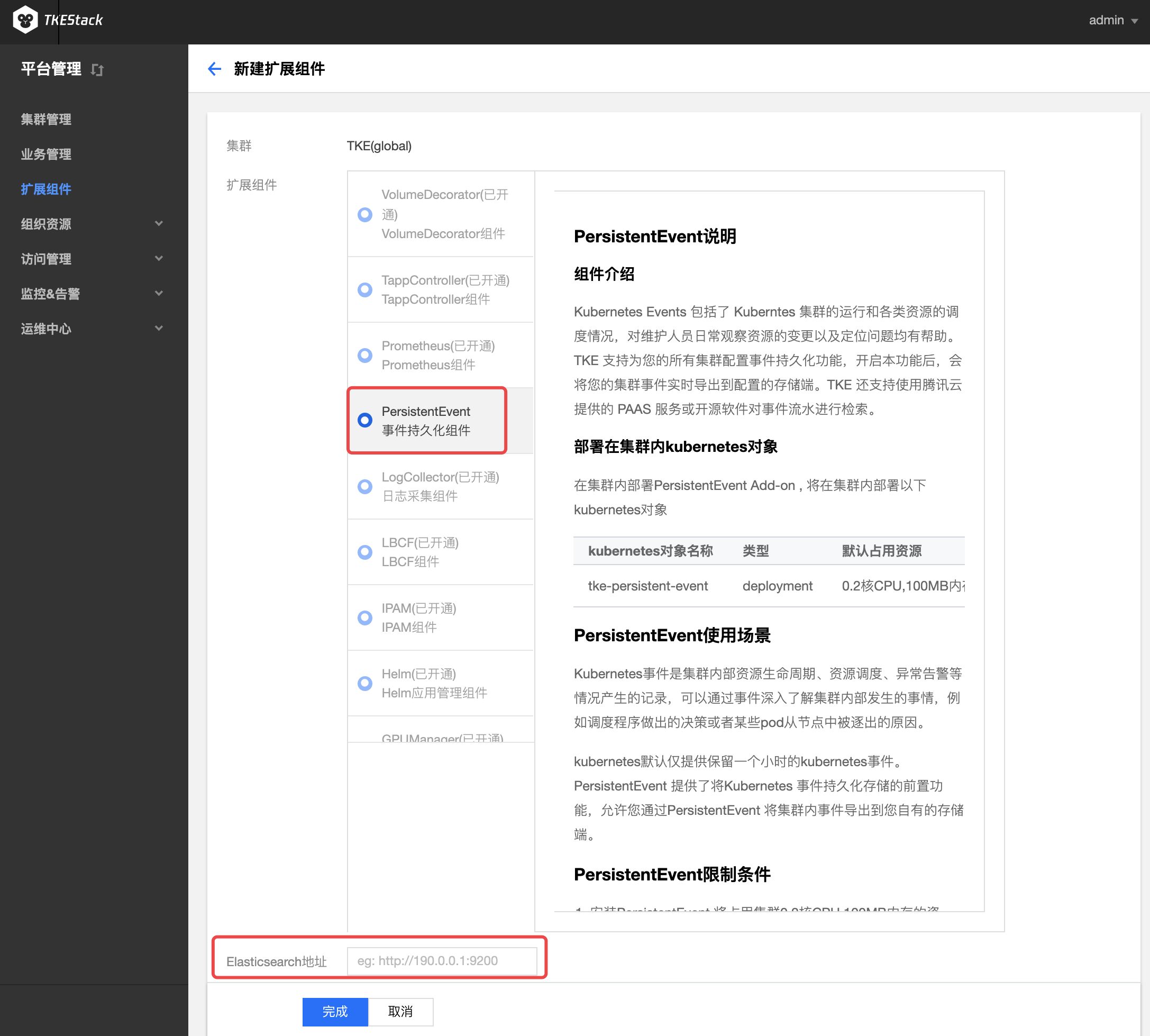
注意:如果选择的是PersistentEvent,需要在下方输入地址和索引。
- 单击【完成】。
这里用户可以管理集群扩展组件。
注意:此页面右边的【删除】按钮可以删除安装了的组件
注意:如果选择的是PersistentEvent,需要在下方输入地址和索引。
Kubernetes 现有应用类型(如:Deployment、StatefulSet等)无法满足很多非微服务应用的需求。比如:操作(升级、停止等)应用中的指定 Pod;应用支持多版本的 Pod。如果要将这些应用改造为适合于这些 Workload 的应用,需要花费很大精力,这将使大多数用户望而却步。
为解决上述复杂应用管理场景,TKEStack 基于 Kubernetes CRD 开发了一种新的应用类型 TApp,它是一种通用类型的 Workload,同时支持 service 和 batch 类型作业,满足绝大部分应用场景,它能让用户更好的将应用迁移到 Kubernetes 集群。
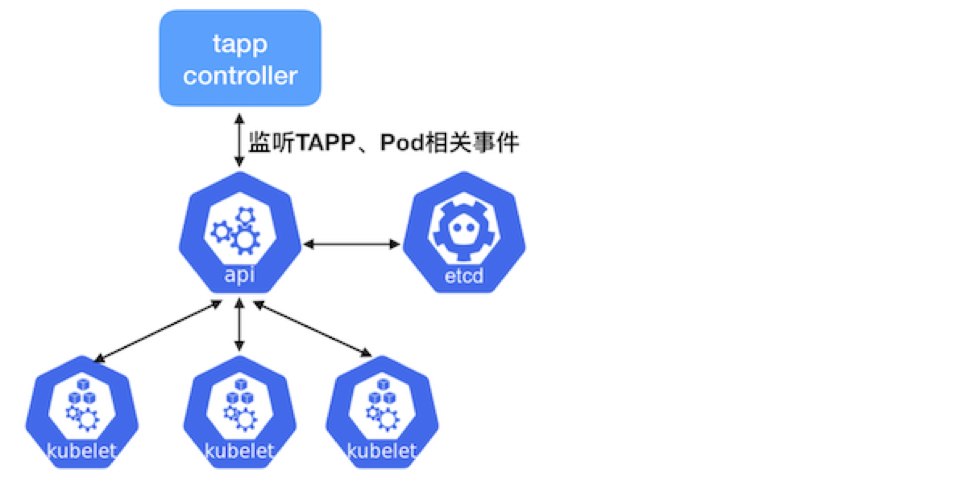
TAPP 其结构定义见 TAPP struct。TApp Controller 是 TApp 对应的Controller/operator,它通过 kube-apiserver 监听 TApp、Pod 相关的事件,根据 TApp 的 spec 和 status 进行相应的操作:创建、删除pod等。
Kubernetes 凭借其强大的声明式 API、丰富的特性和可扩展性,逐渐成为容器编排领域的霸主。越来越多的用户希望使用 Kubernetes,将现有的应用迁移到 Kubernetes 集群,但 Kubernetes 现有 Workload(如:Deployment、StatefulSet等)无法满足很多非微服务应用的需求,比如:操作(升级、停止等)应用中的指定 Pod、应用支持多版本的 Pod。如果要将这些应用改造为适合于这些 Workload的应用,需要花费很大精力,这将使大多数用户望而却步。
腾讯有着多年的容器编排经验,基于 Kuberentes CRD(Custom Resource Definition,使用声明式API方式,无侵入性,使用简单)开发了一种新的 Workload 类型 TApp,它是一种通用类型的 Workload,同时支持 service 和 batch 类型作业,满足绝大部分应用场景,它能让用户更好的将应用迁移到 Kubernetes 集群。如果用 Kubernetes 的 Workload 类比,TAPP ≈ Deployment + StatefulSet + Job ,它包含了 Deployment、StatefulSet、Job 的绝大部分功能,同时也有自己的特性,并且和原生 Kubernetes 相同的使用方式完全一致。经过这几年用户反馈, TApp 也得到了逐渐的完善。
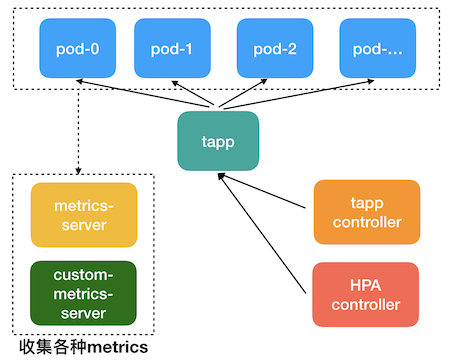
在集群内部署 TApp Add-on , 将在集群内部署以下 kubernetes 对象
| kubernetes 对象名称 | 类型 | 默认占用资源 | 所属Namespaces |
|---|---|---|---|
| tapp-controller | Deployment | 每节点1核CPU, 512MB内存 | kube-system |
| tapps.apps.tkestack.io | CustomResourceDefinition | / | / |
| tapp-controller | ServiceAccount | / | kube-system |
| tapp-controller | Service | / | kube-system |
| tapp-controller | ClusterRoleBinding(ClusterRole/cluster-admin) | / | / |
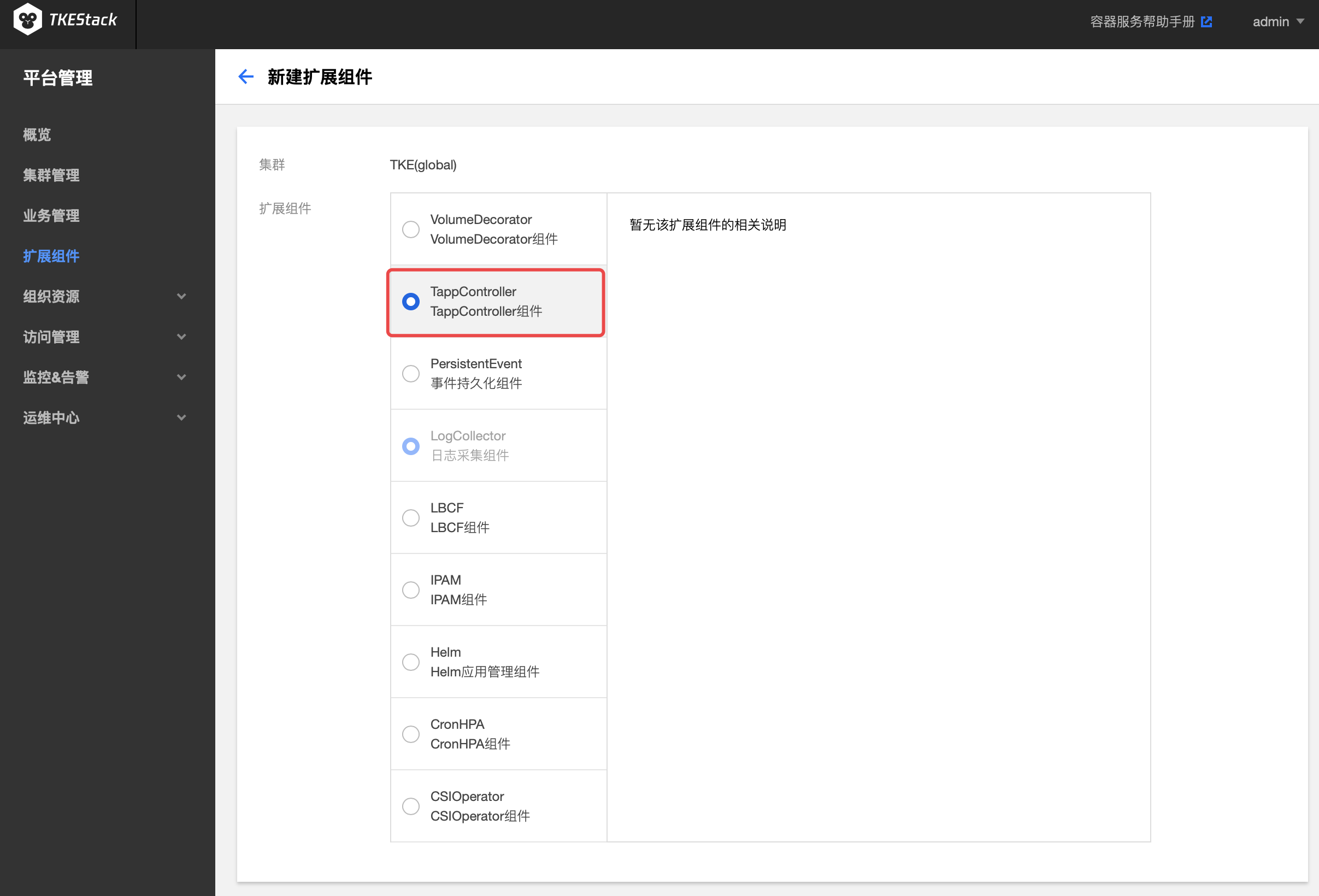
单击【完成】
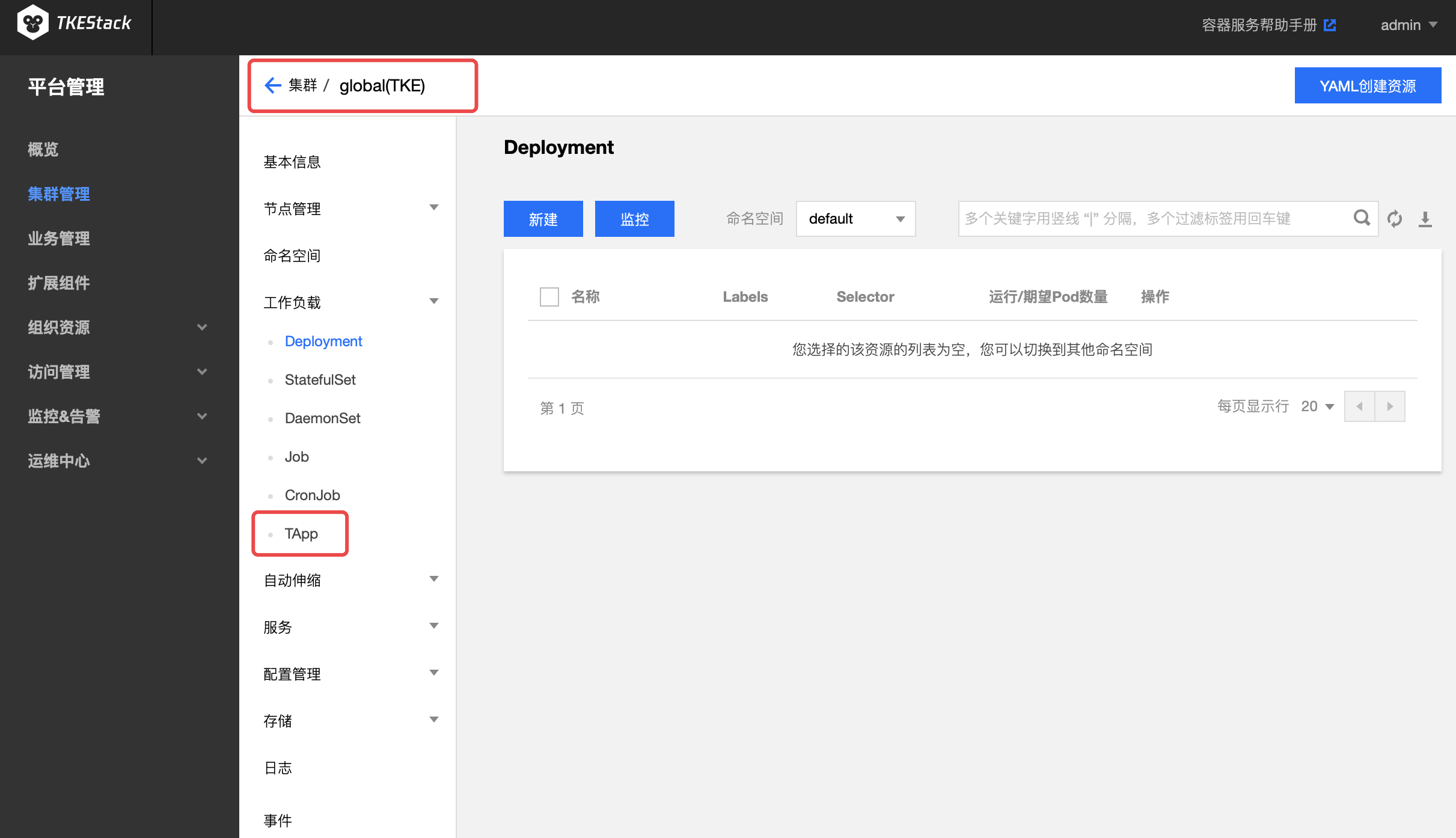
安装完成后会在刚刚安装了 TApp 扩展组件的集群里 【工作负载】下面出现【TApp】,如下图所示:
在 TKEStack 控制台上使用 TApp 使用请参考:TApp Workload
对 TApp 架构和命令行使用请参考:TApp Repository
git clone https://github.com/tkestack/tapp.git
cd tapp
make build
bin/tapp-controller --kubeconfig=$HOME/.kube/config
修改 spec.templatePool.{templateName}.spec.containers.image 的值实现原地升级。
挂在存储卷后的 Pod 依旧在 image 升级的时候没有任何影响,同时 PVC 也没有改变,唯一改变的只有镜像本身。
| 关键字 | 作用 |
|---|---|
| spec.templatePool | 模版池 |
| spec.templates | 以键值对(Pod 序号:模板池中的模板名)的形式具体声明每一个 Pod 的状态 |
| spec.template 等价于 spec.DefaultTemplateName | 默认模板(在spec.templates中没有定义的 Pod 序号将使用该模板) |
| updateStrategy.inPlaceUpdateStrategy | 原地升级策略 |
| spec.updateStrategy | 保留旧版本 Pod 的数量,默认为 0,类似于灰度发布 |
| spec.updateStrategy.template | 要设置 maxUnavailable 值的 template 名 |
| spec.updateStrategy.maxUnavailable | 最大的不可用 Pod 数量(默认为1,可设置成一个自然数,或者一个百分比,例如 50%) |
| spec.statuses | 明确 Pod 的状态,TApp 会实现该状态 |
apiVersion: apps.tkestack.io/v1
kind: TApp
metadata:
name: example-tapp
spec:
replicas: 3
# 默认模板
template:
metadata:
labels:
app: example-tapp
spec:
containers:
- name: nginx
image: nginx:latest
# 模板池
templatePool:
# 模板池中的模板
"test2":
metadata:
labels:
app: example-tapp
spec:
containers:
- name: nginx
image: nginx:1.7.9
# 要使用模板池中模板的 Pod
templates:
# Pod 序号:模板池中的模板
"1": "test2"
"2": "test2"
# 更新策略
updateStrategy:
# 更新指定模板。test2该模板有过修改,或者是在模板池里新增的,都可以通过 updateStrategy 设置模板来进行滚动更新
template: test2
# 使用该模板的 Pod 在更新时最大不可用的数量
maxUnavailable: 1
# 明确 Pod 的状态,TApp 会实现该状态
statuses:
# 编号为1的 Pod 将被 Kill
"1": "Killed"
Cron Horizontal Pod Autoscaler(CronHPA) 可让用户利用 CronTab 实现对负载(Deployment、StatefulSet、TApp 这些支持扩缩容的资源对象)定期自动扩缩容。
CronTab 格式说明如下:
# 文件格式说明
# ——分钟(0 - 59)
# | ——小时(0 - 23)
# | | ——日(1 - 31)
# | | | ——月(1 - 12)
# | | | | ——星期(0 - 6)
# | | | | |
# * * * * *
CronHPA 定义了一个新的 CRD,cron-hpa-controller 是该 CRD 对应的 Controller/operator,它解析 CRD 中的配置,根据系统时间信息对相应的工作负载进行扩缩容操作。
以游戏服务为例,从星期五晚上到星期日晚上,游戏玩家数量暴增。如果可以将游戏服务器在星期五晚上扩大规模,并在星期日晚上缩放为原始规模,则可以为玩家提供更好的体验。这就是游戏服务器管理员每周要做的事情。
其他一些服务也会存在类似的情况,这些产品使用情况会定期出现高峰和低谷。CronHPA 可以自动化实现提前扩缩 Pod,为用户提供更好的体验。
在集群内部署 CronHPA Add-on , 将在集群内部署以下 kubernetes 对象:
| kubernetes 对象名称 | 类型 | 默认占用资源 | 所属 Namespaces |
|---|---|---|---|
| cron-hpa-controller | Deployment | 每节点1核 CPU, 512MB内存 | kube-system |
| cronhpas.extensions.tkestack.io | CustomResourceDefinition | / | / |
| cron-hpa-controller | ClusterRoleBinding(ClusterRole/cluster-admin) | / | / |
| cron-hpa-controller | ServiceAccount | / | kube-system |
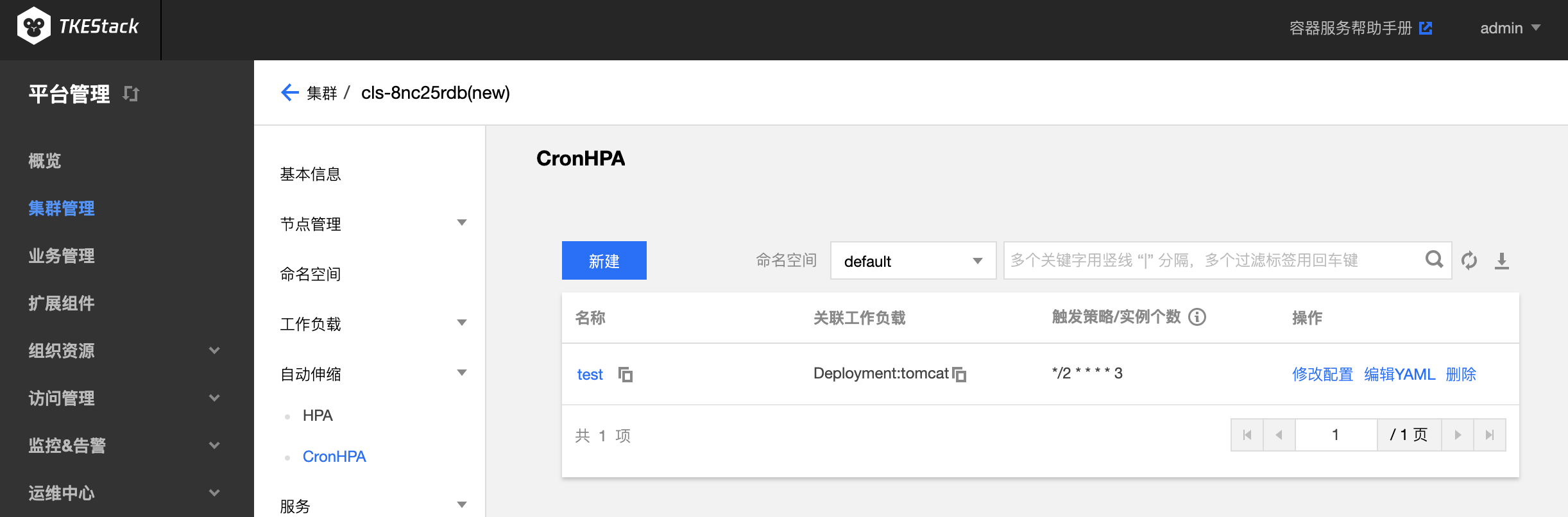
TKEStack 已经支持在页面多处位置为负载配置 CronHPA
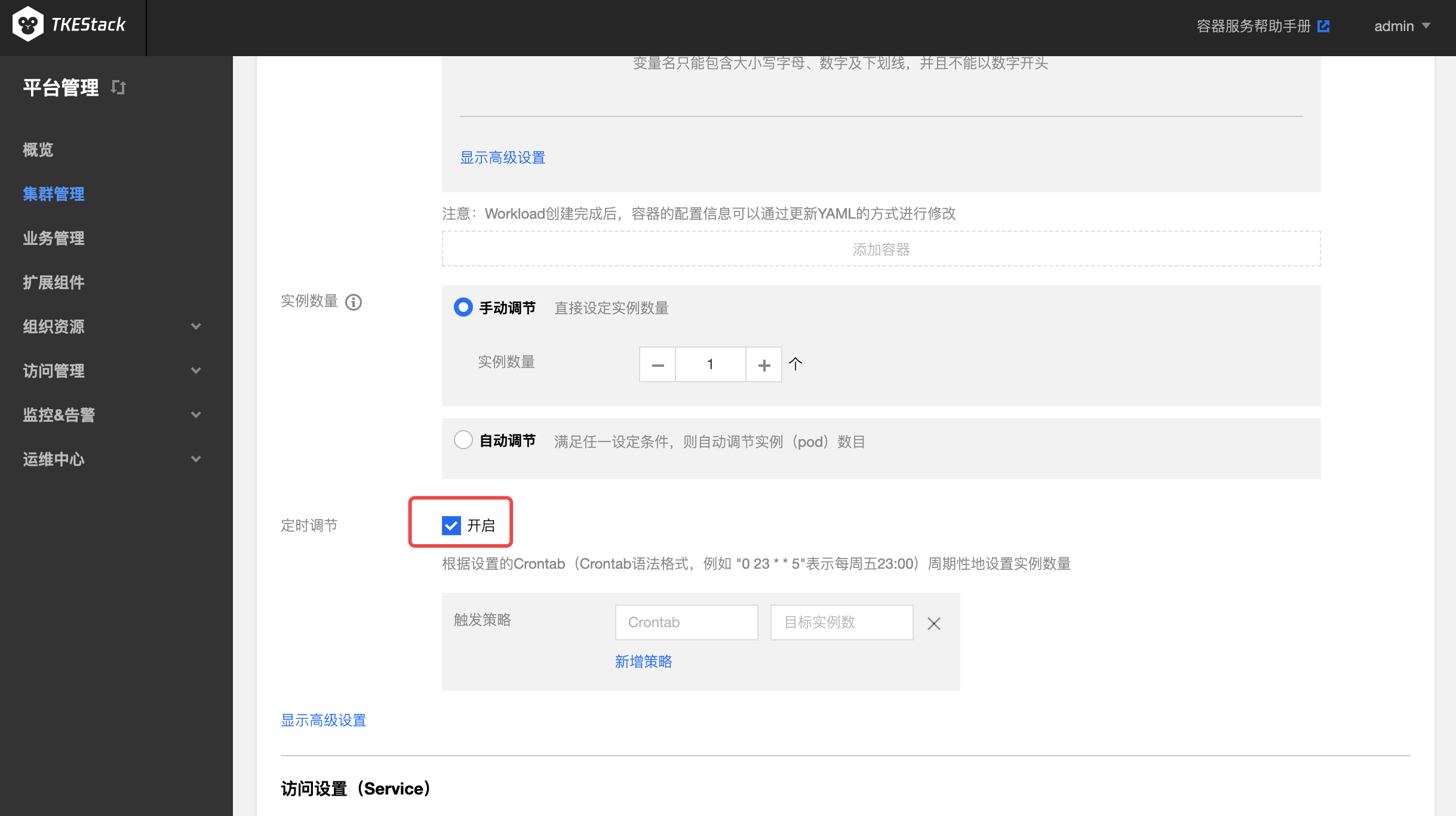
每条触发策略由两条字段组成
示例1:指定 Deployment 每周五20点扩容到60个实例,周日23点缩容到30个实例
apiVersion: extensions.tkestack.io/v1
kind: CronHPA
metadata:
name: example-cron-hpa # CronHPA 名
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment # CronHPA 操作的负载类型
name: demo-deployment # CronHPA 操作的负载类型名
crons:
- schedule: "0 20 * * 5" # Crontab 语法格式
targetReplicas: 60 # 负载副本(Pod)的目标数量
- schedule: "0 23 * * 7"
targetReplicas: 30
示例2:指定 Deployment 每天8点到9点,19点到21点扩容到60,其他时间点恢复到10
apiVersion: extensions.tkestack.io/v1
kind: CronHPA
metadata:
name: web-servers-cronhpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: web-servers
crons:
- schedule: "0 8 * * *"
targetReplicas: 60
- schedule: "0 9 * * *"
targetReplicas: 10
- schedule: "0 19 * * *"
targetReplicas: 60
- schedule: "0 21 * * *"
targetReplicas: 10
# kubectl get cronhpa
NAME AGE
example-cron-hpa 104s
# kubectl get cronhpa example-cron-hpa -o yaml
apiVersion: extensions.tkestack.io/v1
kind: CronHPA
...
spec:
crons:
- schedule: 0 20 * * 5
targetReplicas: 60
- schedule: 0 23 * * 7
targetReplicas: 30
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: demo-deployment
kubectl delete cronhpa example-cron-hpa
CronHPA 项目请参考 CronHPA Repository
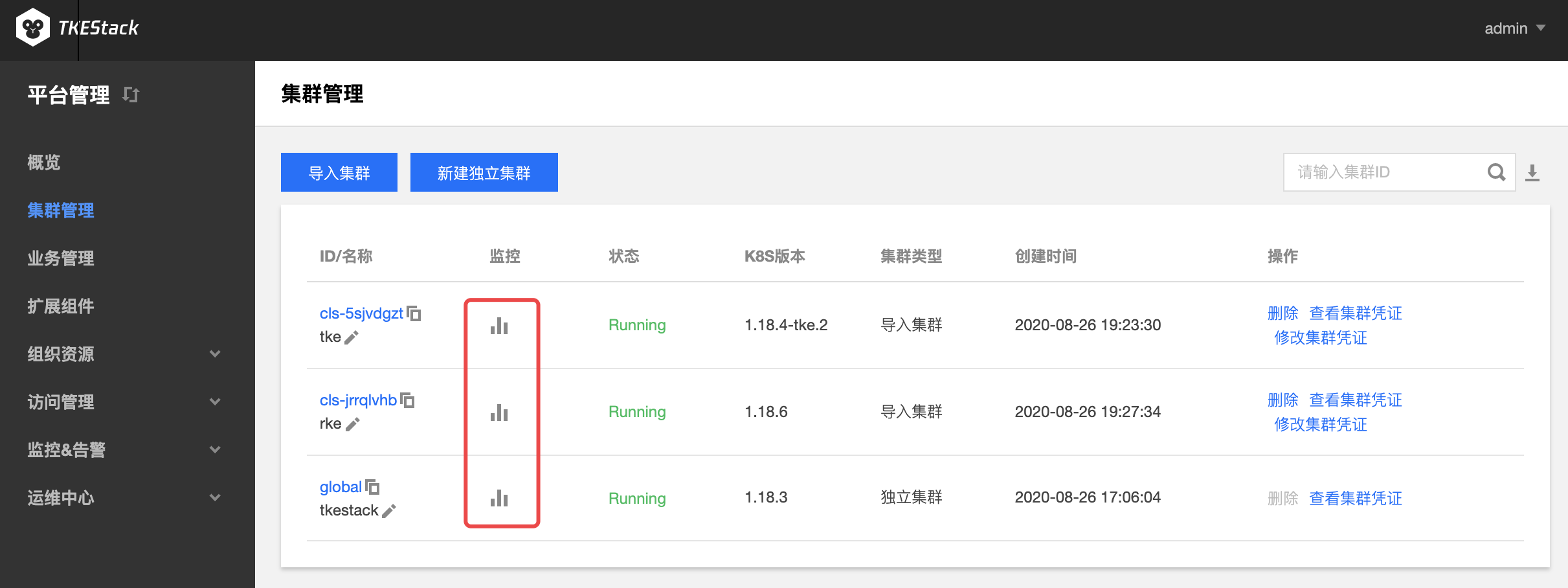
良好的监控环境为 TKEStack 高可靠性、高可用性和高性能提供重要保证。您可以方便为不同资源收集不同维度的监控数据,能方便掌握资源的使用状况,轻松定位故障。
TKEStack 使用开源的 Prometheus 作为监控组件,免去您部署和配置 Prometheus 的复杂操作,TKEStack 提供高可用性和可扩展性的细粒度监控系统,实时监控 CPU,GPU,内存,显存,网络带宽,磁盘 IO 等多种指标并自动绘制趋势曲线,帮助运维人员全维度的掌握平台运行状态。
TKEStack 使用 Prometheus 的架构和原理可以参考 Prometheus 组件
指标具体含义可参考:监控 & 告警指标列表
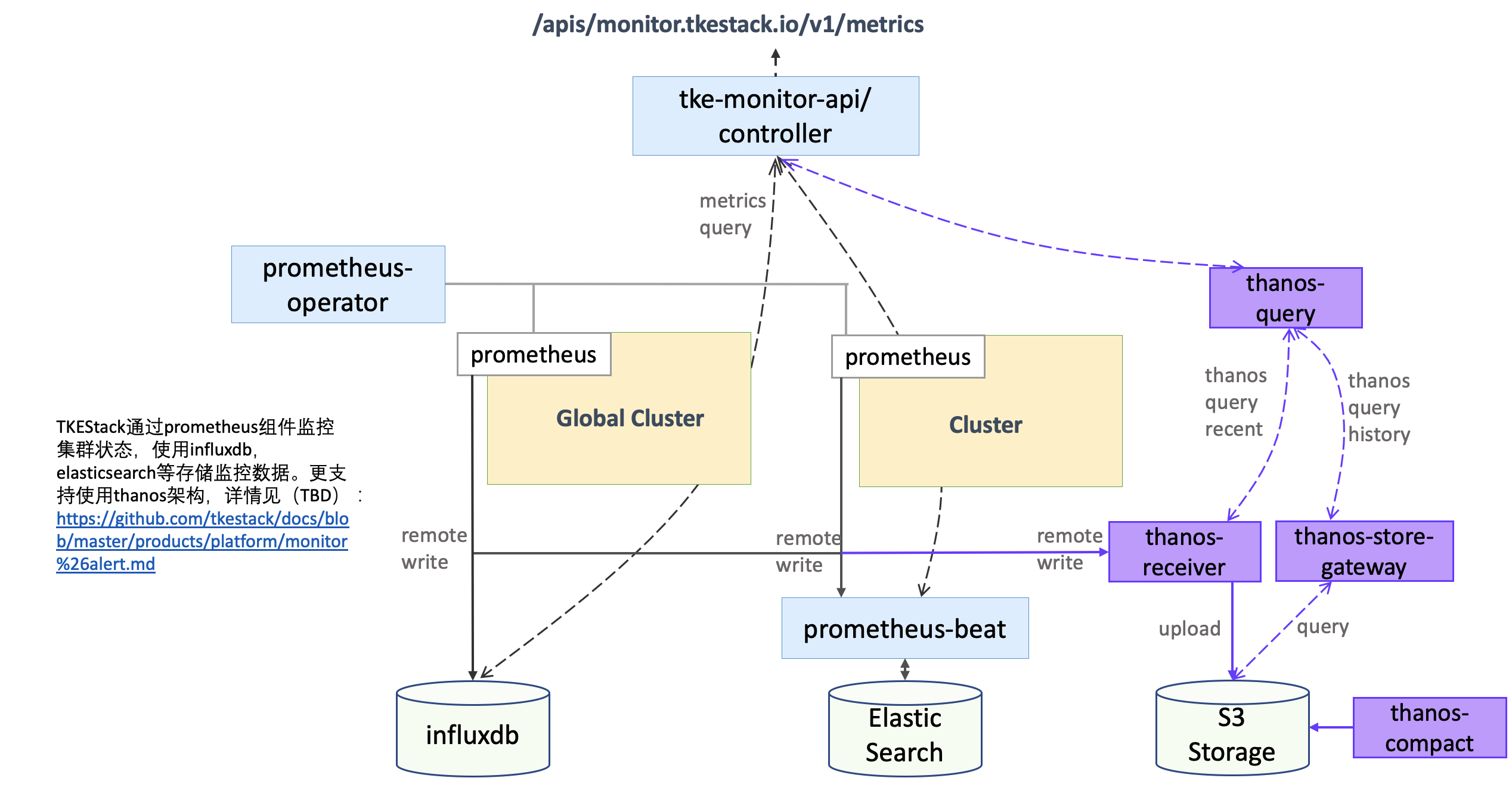
TKEStack 通过 Prometheus 组件监控集群状态,Prometheus 组件通过 addon 扩展组件自动完成安装和配置,使用 InfluxDB,ElasticSearch 等存储监控数据。监控数据和指标融入到平台界面中以风格统一图表的风格展示,支持以不同时间,粒度等条件,查询集群,节点,业务,Workload 以及容器等多个层级的监控数据,全维度的掌握平台运行状态。
同时针对在可用性和可扩展性方面,支持使用 Thanos 架构提供可靠的细粒度监控和警报服务,构建具有高可用性和可扩展性的细粒度监控能力。
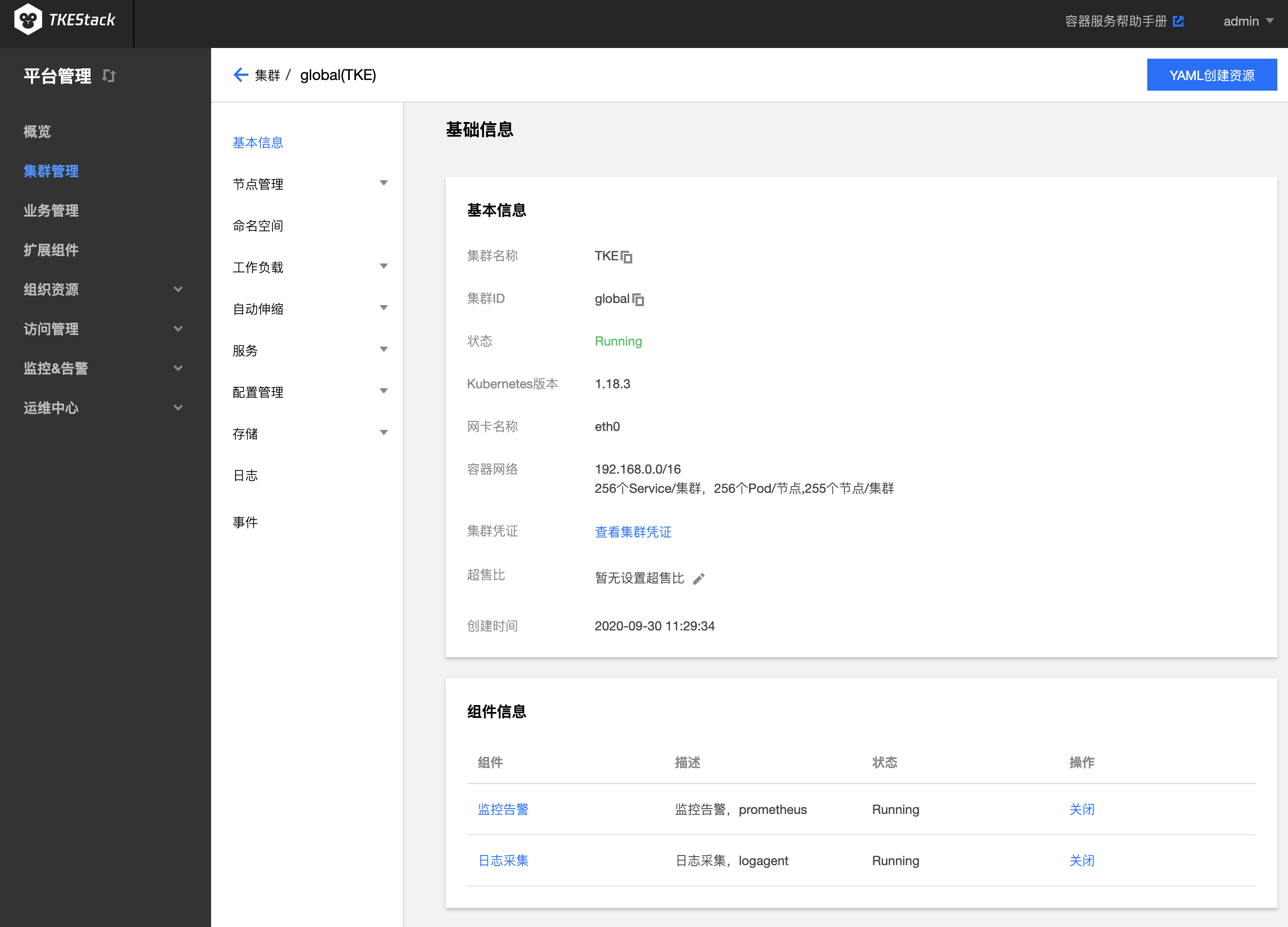
Prometheus 为 TKEStack 扩展组件,需要在集群的 【基本信息】 页下面开启 “监控告警”。
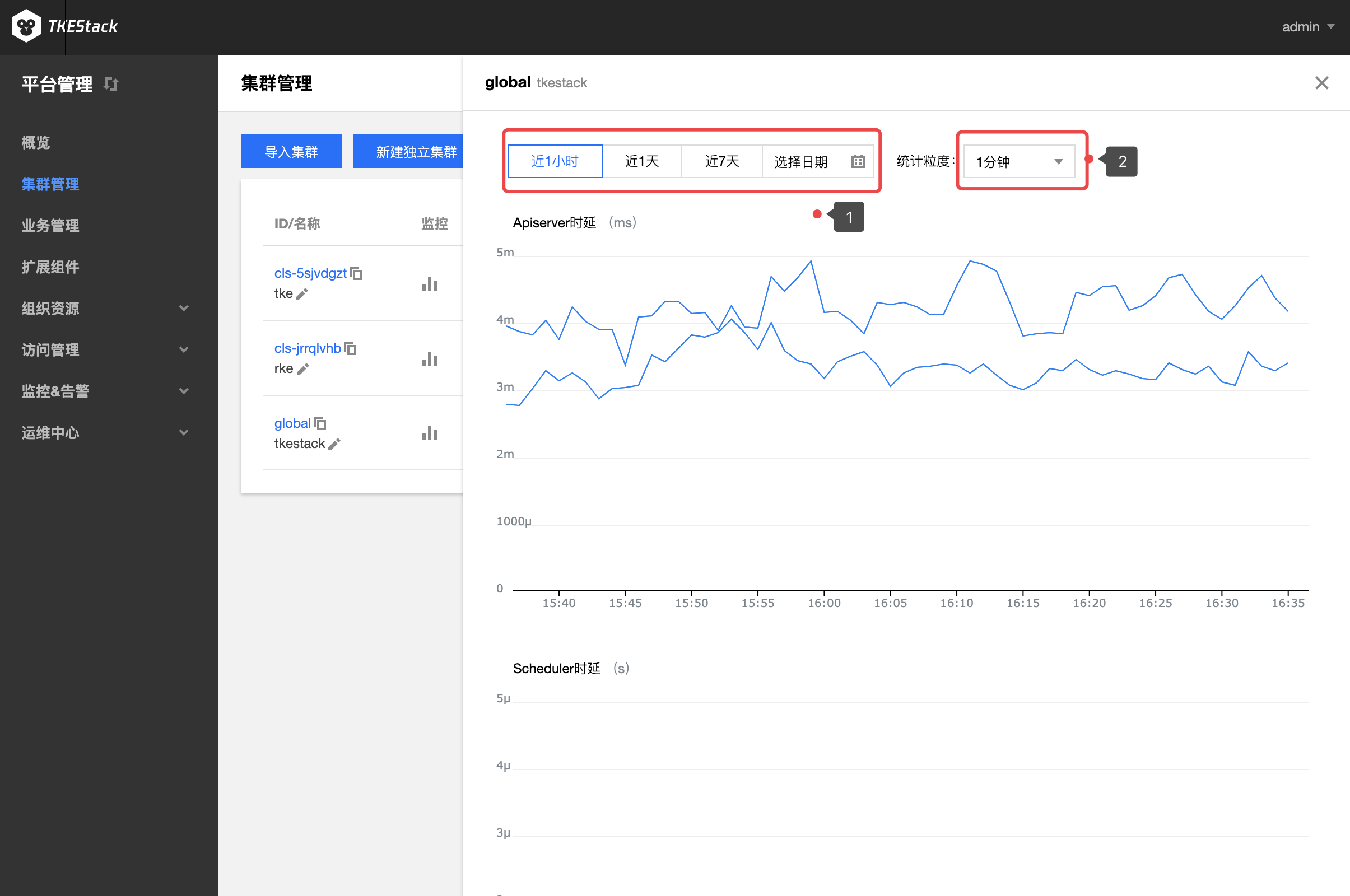
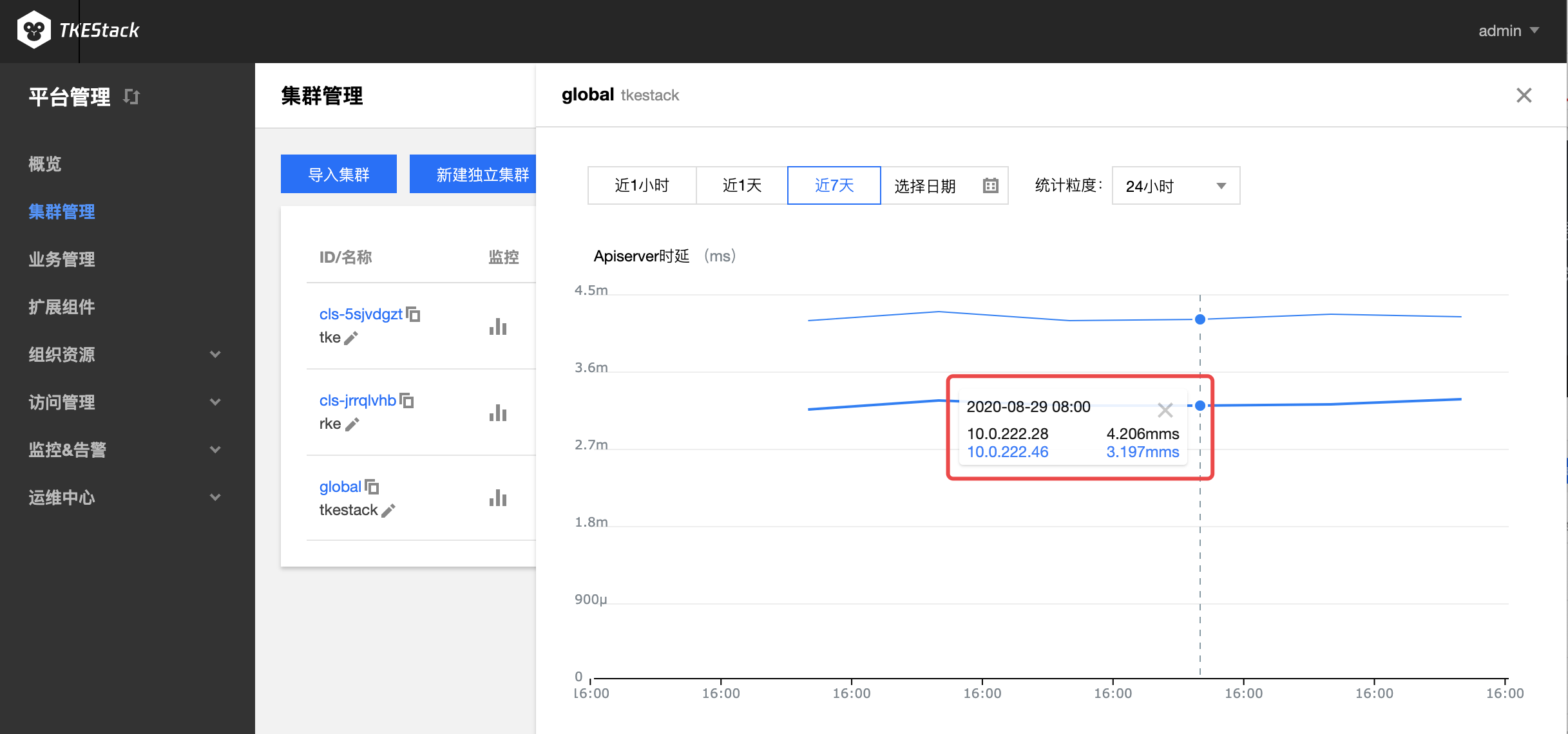
指标具体含义可参考:监控 & 告警指标列表
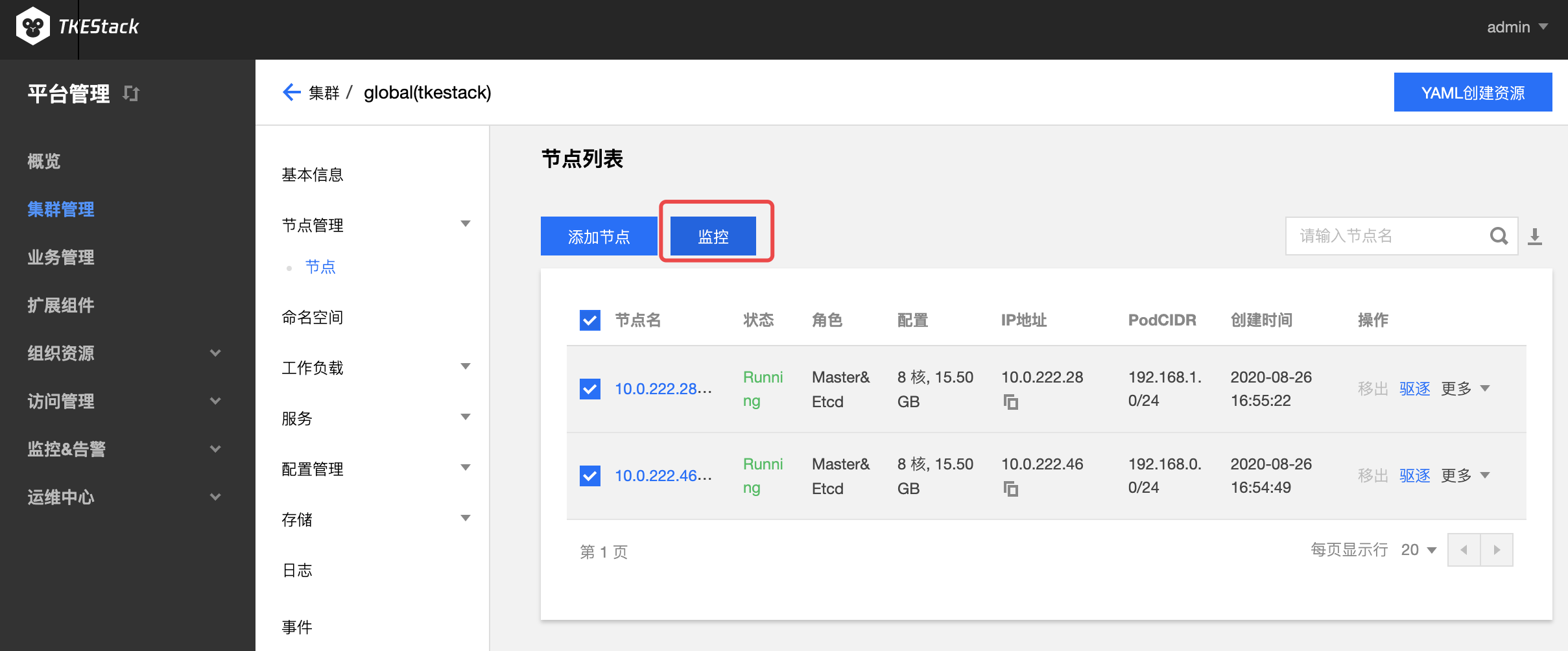
具体查看方式和集群监控完全一致
指标具体含义可参考:监控 & 告警指标列表
此处还可以查看节点下的 Pod 监控
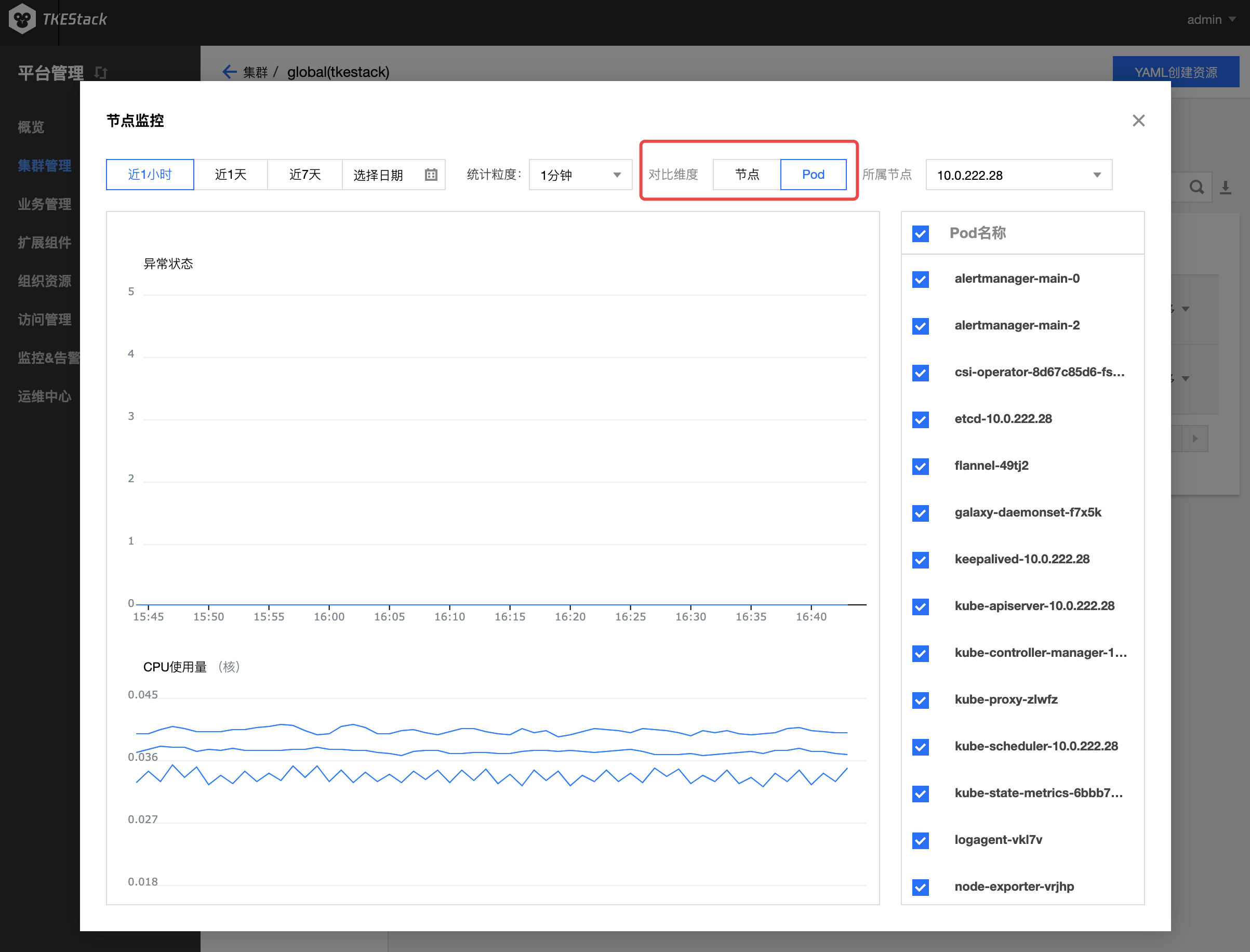
有两种方式
注意:此处还可以查看节点下的 Container 监控
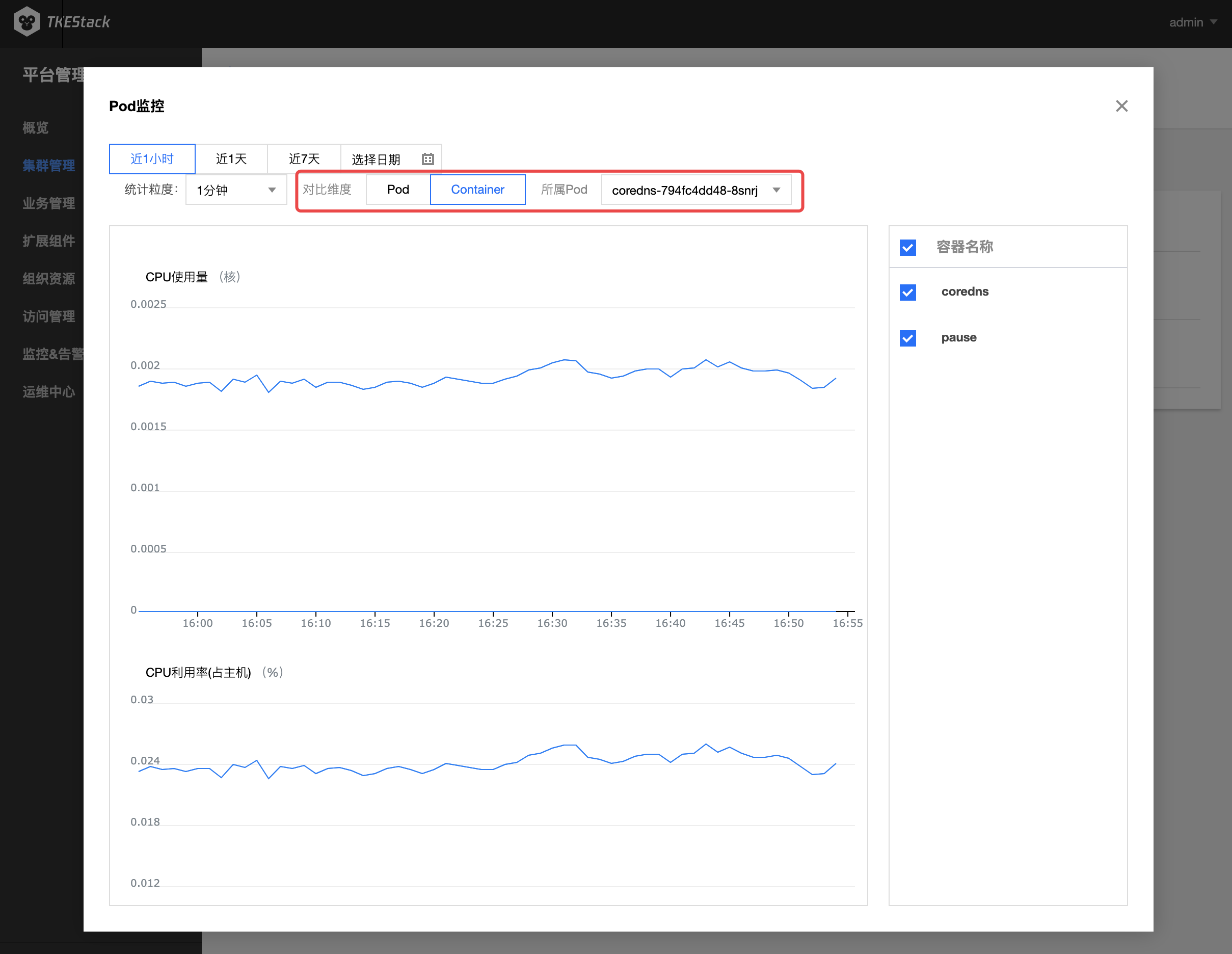
- 如下图所示,对比维度可选择 Pod 或 Container
- 选择 Container ,需要在其右侧选择 Container 所属 Pod
指标具体含义可参考:监控 & 告警指标列表
登录 TKEStack
切换至【平台管理】控制台,选择【集群管理】
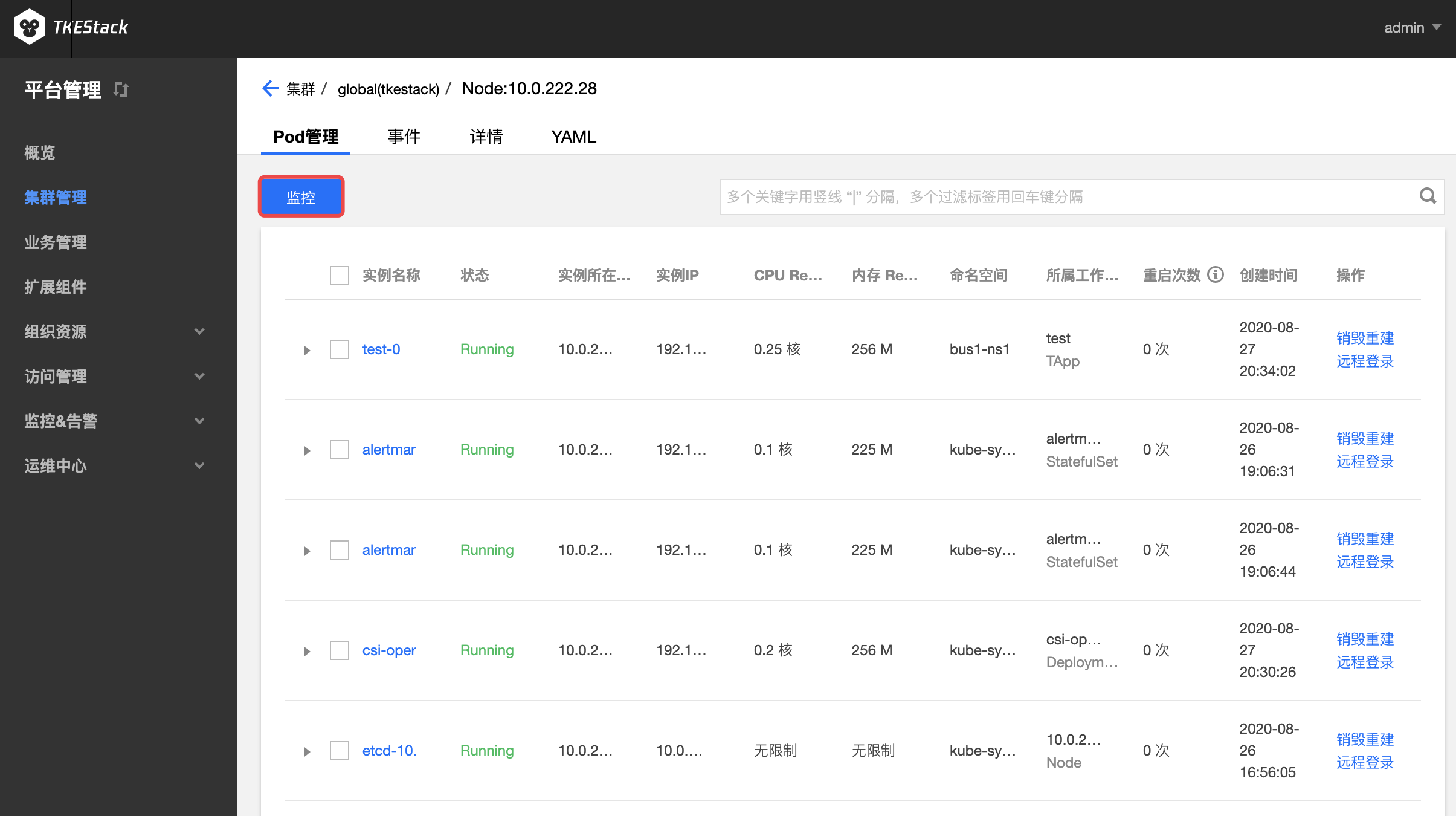
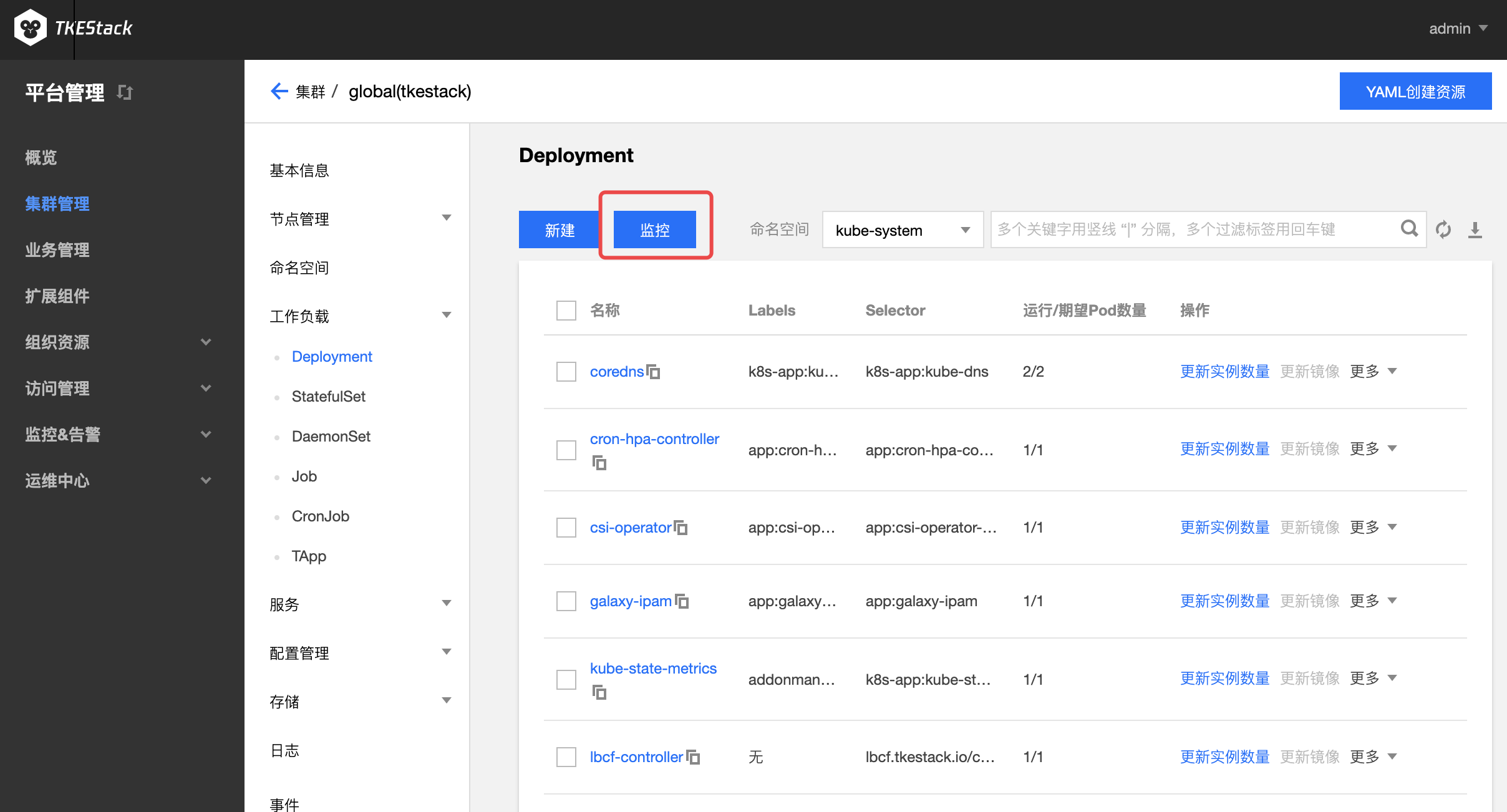
点击【集群 ID】 -> 【工作负载】->【选择一种负载,例如 Deployment】->【监控】图标,如下图所示:
具体查看方式和集群监控完全一致
指标具体含义可参考:监控 & 告警指标列表
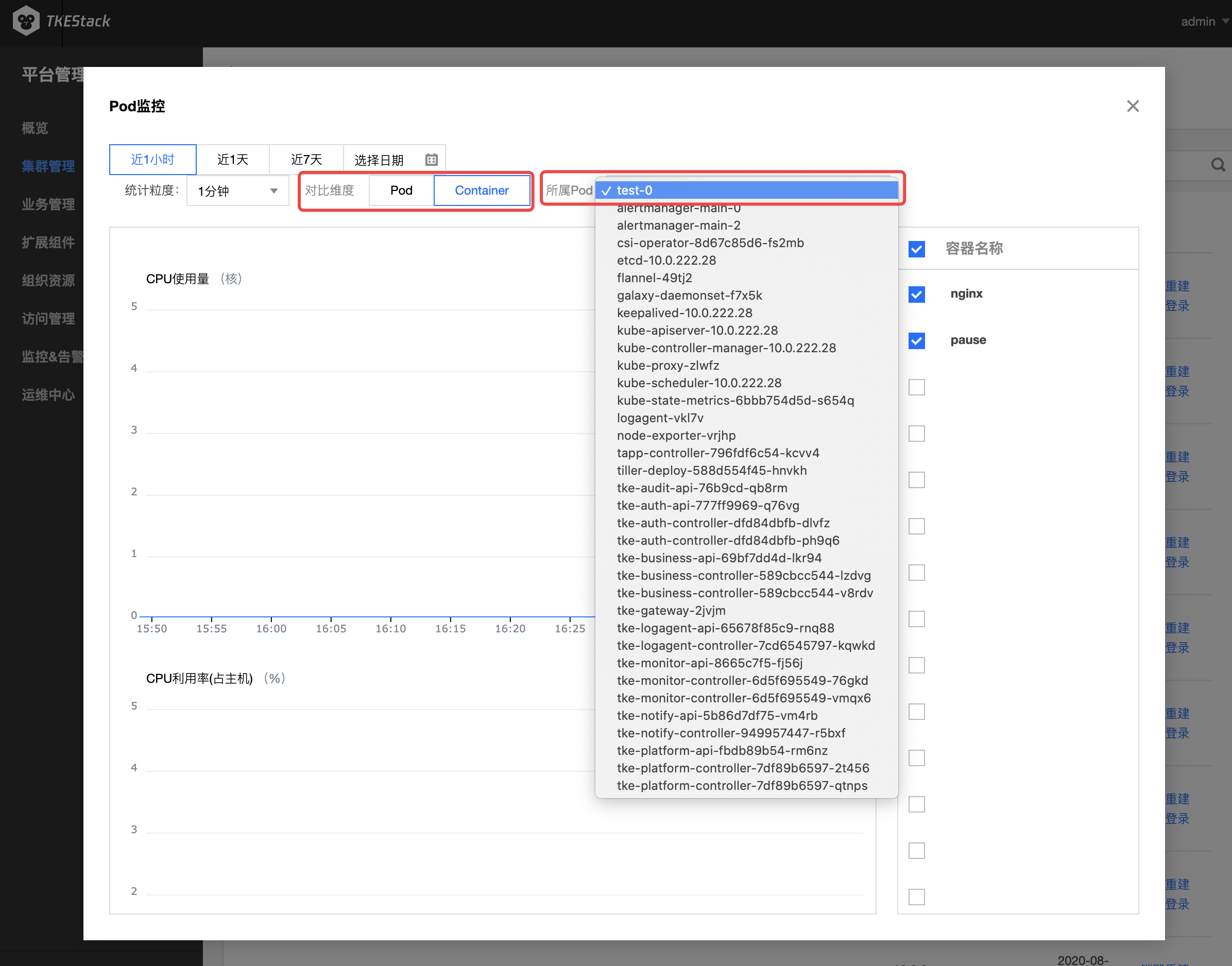
注意:此处还可以查看负载下的 Container 监控
- 如下图所示,对比维度可选择 Pod 或 Container
- 选择 Container ,需要在其右侧选择 Container 所属 Pod 指标具体含义可参考:监控 & 告警指标列表
TKEStack 使用 Prometheus 的架构和原理可以参考 Prometheus 组件
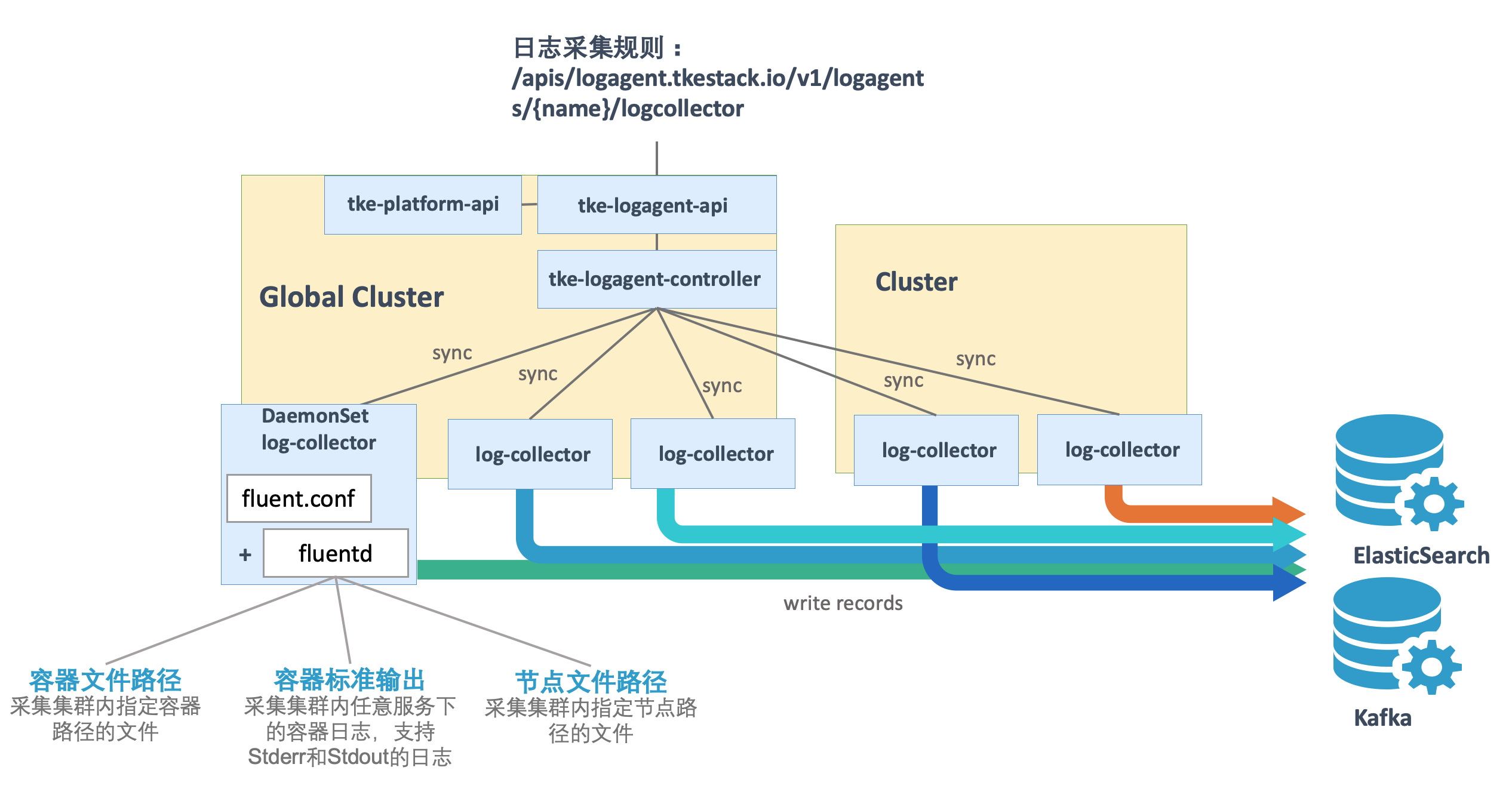
TKESTack 通过 logagent 提供的集群内日志采集功能,支持将集群内服务或集群节点特定路径文件的日志发送至 Kafka、Elasticsearch 等消费端,支持采集容器标准输出日志,容器内文件日志以及主机内文件日志。更提供事件持久化、审计等功能,实时记录集群事件及操作日志记录,帮助运维人员存储和分析集群内部资源生命周期、资源调度、异常告警等情况。
TKEStack 老版本日志使用 LogCollector 扩展组件。LogAgent 用于替换 LogCollector,新版本统一用 LogAgent 完成日志采集功能。
日志收集功能需要为每个集群手动开启。日志收集功能开启后,日志收集组件 logagent 会在集群内以 Daemonset 的形式运行。用户可以通过日志收集规则配置日志的采集源和消费端,日志收集 Agent 会从用户配置的采集源进行日志收集,并将日志内容发送至用户指定的消费端。需要注意的是,使用日志收集功能需要您确认 Kubernetes 集群内节点能够访问日志消费端。
在集群内部署 logagent Add-on , 将在集群内部署以下 kubernetes 对象
| kubernetes 对象名称 | 类型 | 默认占用资源 | 所属Namespaces |
|---|---|---|---|
| logagent | DaemonSet | 每节点0.3核 CPU, 250MB 内存 | kube-system |
| logagent | ServiceAccount | kube-system |
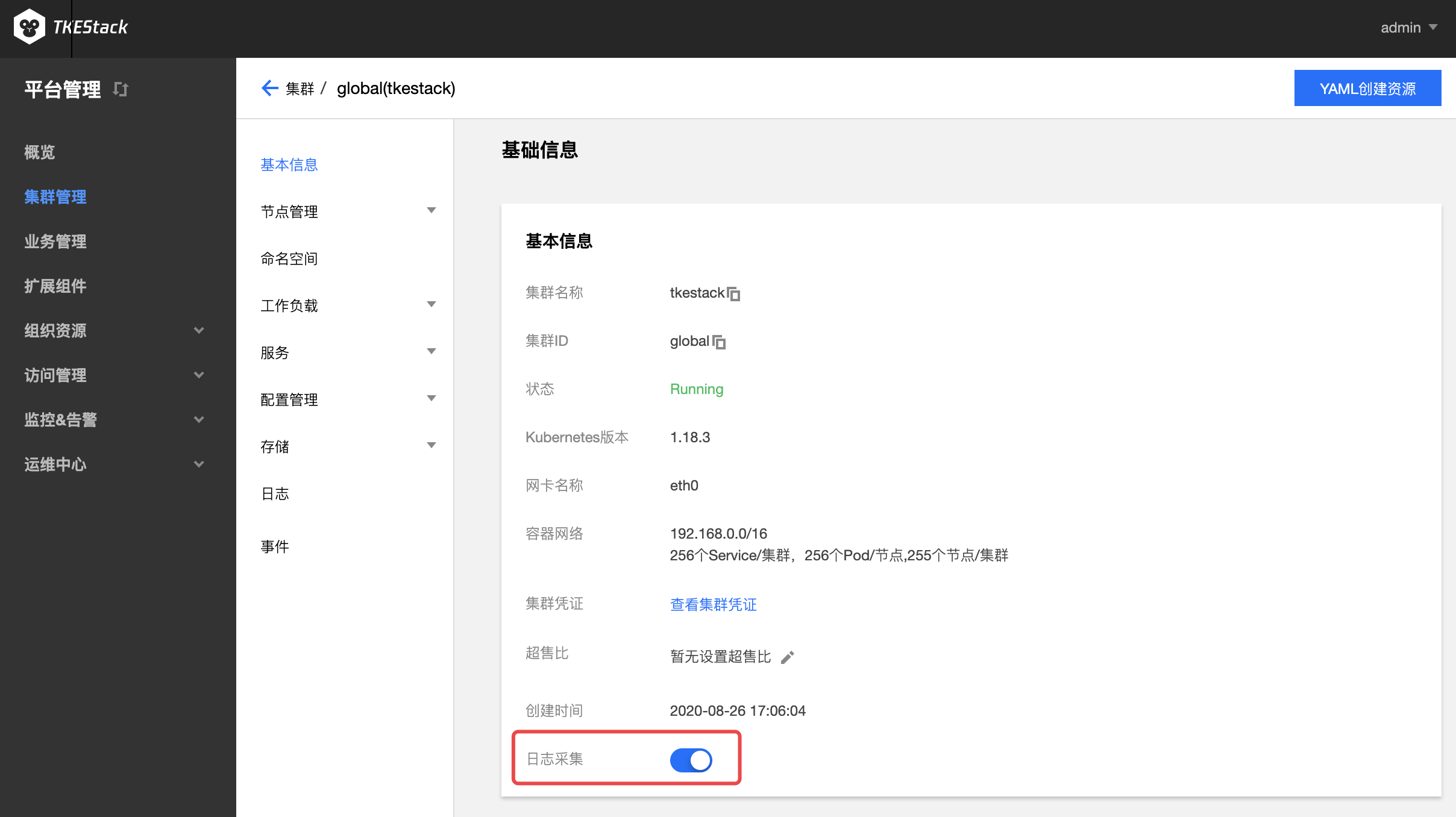
注意:日志采集对接外部 Kafka 或 Elasticsearch,该功能需要额外开启,位置在集群 基本信息 下面,点击开启“日志采集”服务。
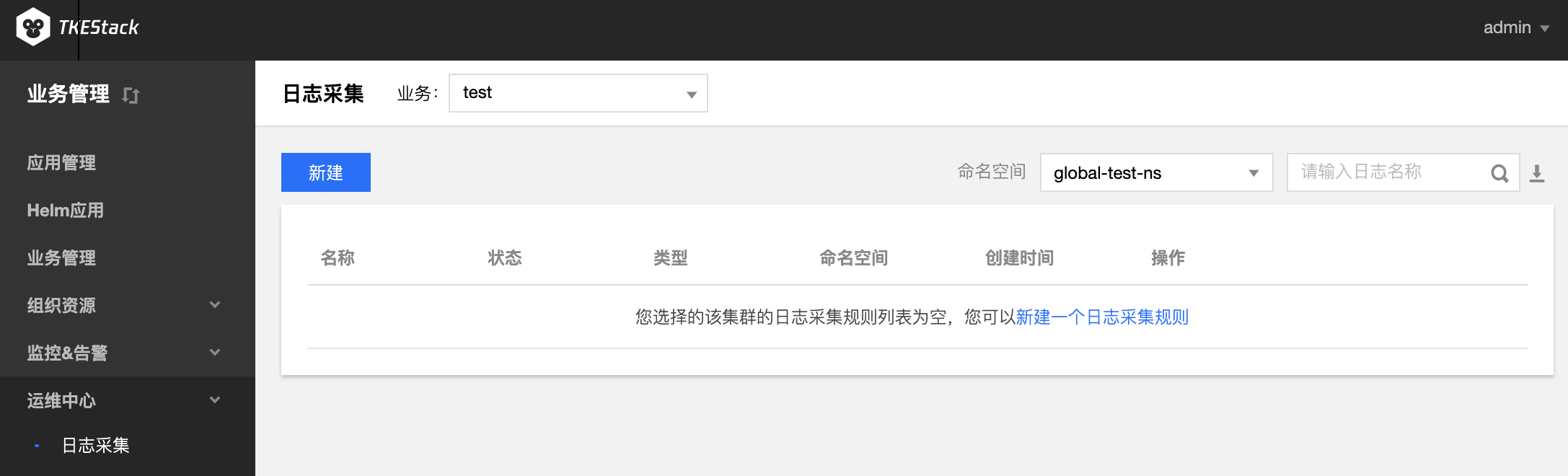
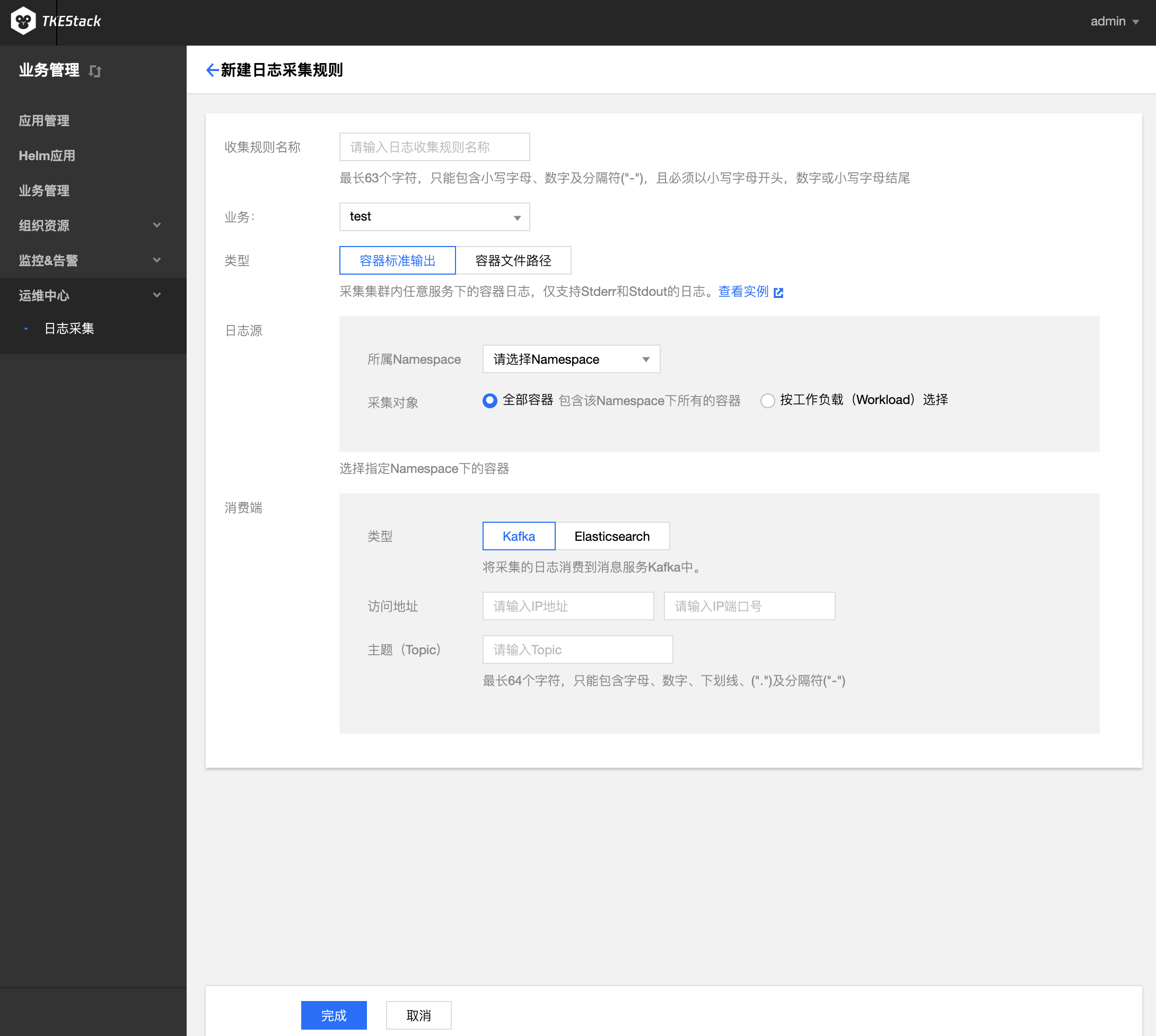
日志源: 可以采集具体容器内的某个文件路径下的文件内容
- 文件路径若输入
stdout,则转为容器标准输出模式- 可配置多个路径。路径必须以
/开头和结尾,文件名支持通配符(*)。文件路径和文件名最长支持63个字符- 请保证容器的日志文件保存在数据卷,否则收集规则无法生效,详见指定容器运行后的日志目录
/开头和结尾,文件名支持通配符(*)。文件路径和文件名最长支持63个字符Elasticsearch 地址: ES 地址,如:http://190.0.0.1:200
注意:当前只支持未开启用户登录认证的 ES 集群
索引: ES索引,最长60个字符,只能包含小写字母、数字及分隔符("-"、"_"、"+"),且必须以小写字母开头
在平台管理侧也支持日志采集规则的创建,创建方式和业务管理处相同。详情可点击平台侧的日志采集。
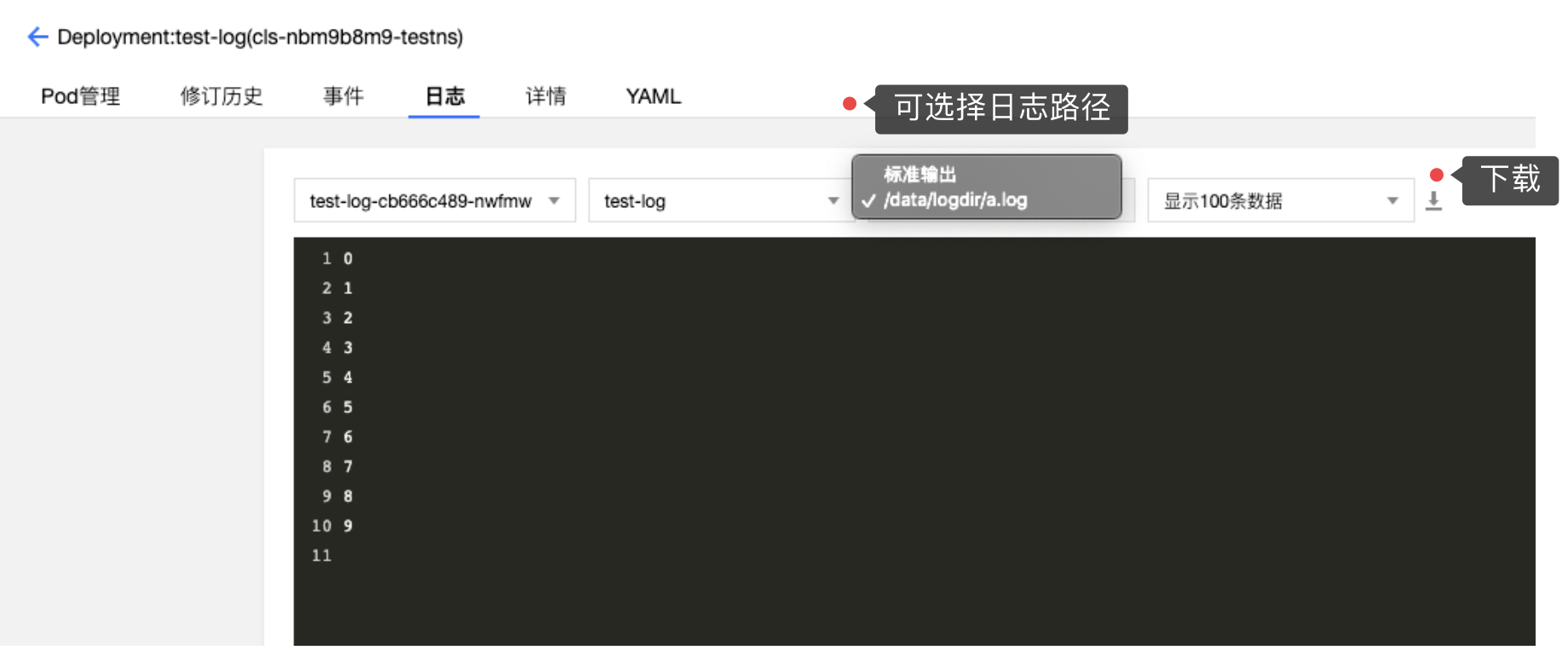
LogAgent 除了支持日志规则的创建,也支持指定容器运行后的日志目录,可实现日志文件展示和下载。
前提:需要在创建负载时挂载数据卷,并指定日志目录
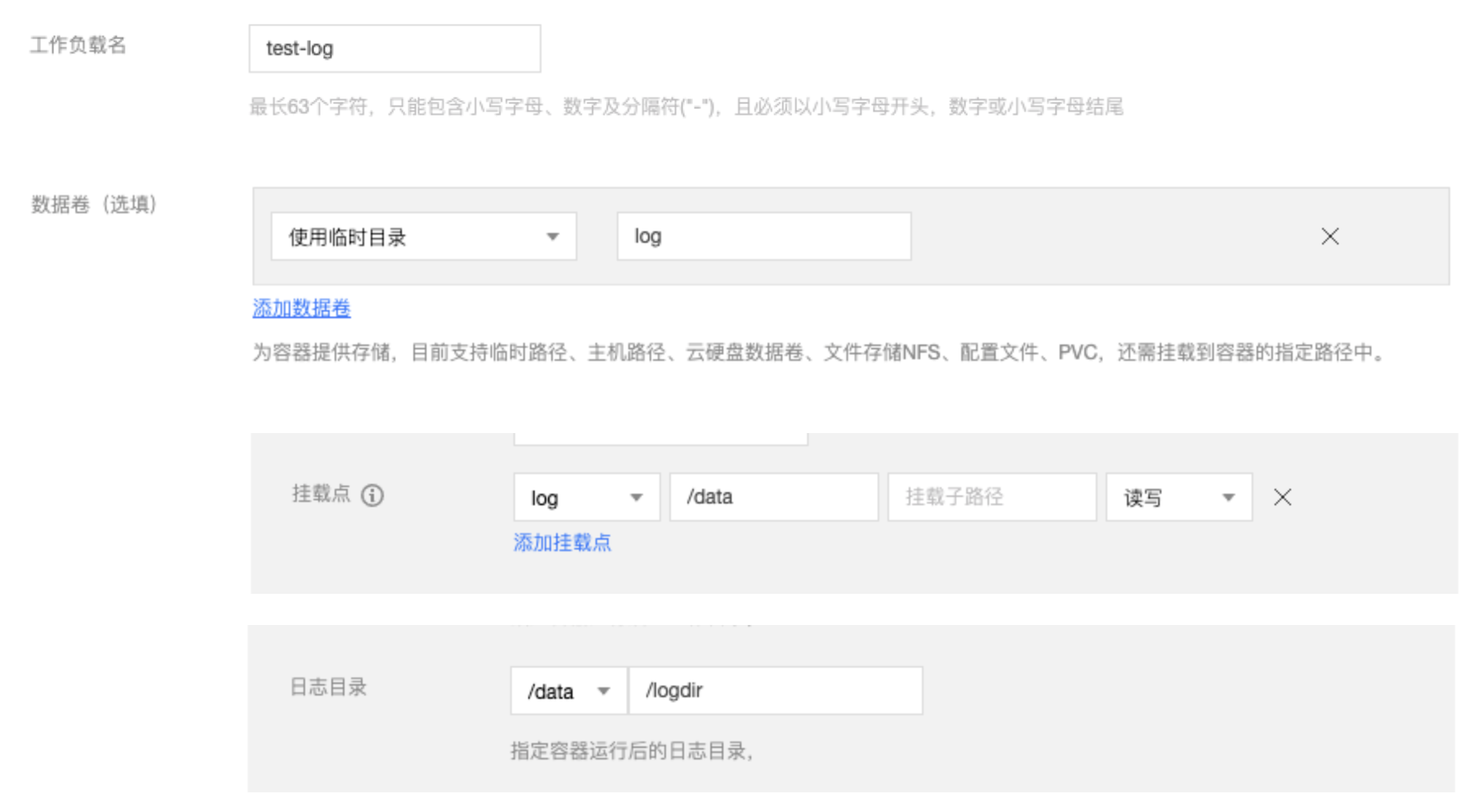
创建负载以后,在容器内的/data/logdir目录下的所有文件可以展示并下载,例如我们在容器的/data/logdir下新建一个名为a.log的文件,如果有内容的话,也可以在这里展示与下载:
GPUManager 提供一个 All-in-One 的 GPU 管理器, 基于 Kubernets Device Plugin 插件系统实现,该管理器提供了分配并共享 GPU,GPU 指标查询,容器运行前的 GPU 相关设备准备等功能,支持用户在 Kubernetes 集群中使用 GPU 设备。
GPU-Manager 包含如下功能:
/metrics 路径,可以为 Prometheus 提供 GPU 指标的收集功能,/usage 路径可以提供可读性的容器状况查询在 Kubernetes 集群中运行 GPU 应用时,可以解决 AI 训练等场景中申请独立卡造成资源浪费的情况,让计算资源得到充分利用。
该组件基于 Kubernetes DevicePlugin 实现,只能运行在支持 DevicePlugin 的 kubernetes版本(Kubernetes 1.10 之上的版本)
使用 GPU-Manager 要求集群内包含 GPU 机型节点
TKEStack 的 GPU-Manager 将每张 GPU 卡视为一个有100个单位的资源
特别注意:
- 当前仅支持 0-1 的小数张卡,如 20、35、50;以及正整数张卡,如200、500等;不支持类似150、250的资源请求
- 显存资源是以 256MiB 为最小的一个单位的分配显存
在集群内部署 GPU-Manager,将在集群内部署以下 kubernetes 对象:
| kubernetes 对象名称 | 类型 | 建议预留资源 | 所属 Namespaces |
|---|---|---|---|
| gpu-manager-daemonset | DaemonSet | 每节点1核 CPU, 1Gi内存 | kube-system |
| gpu-quota-admission | Deployment | 1核 CPU, 1Gi内存 | kube-system |
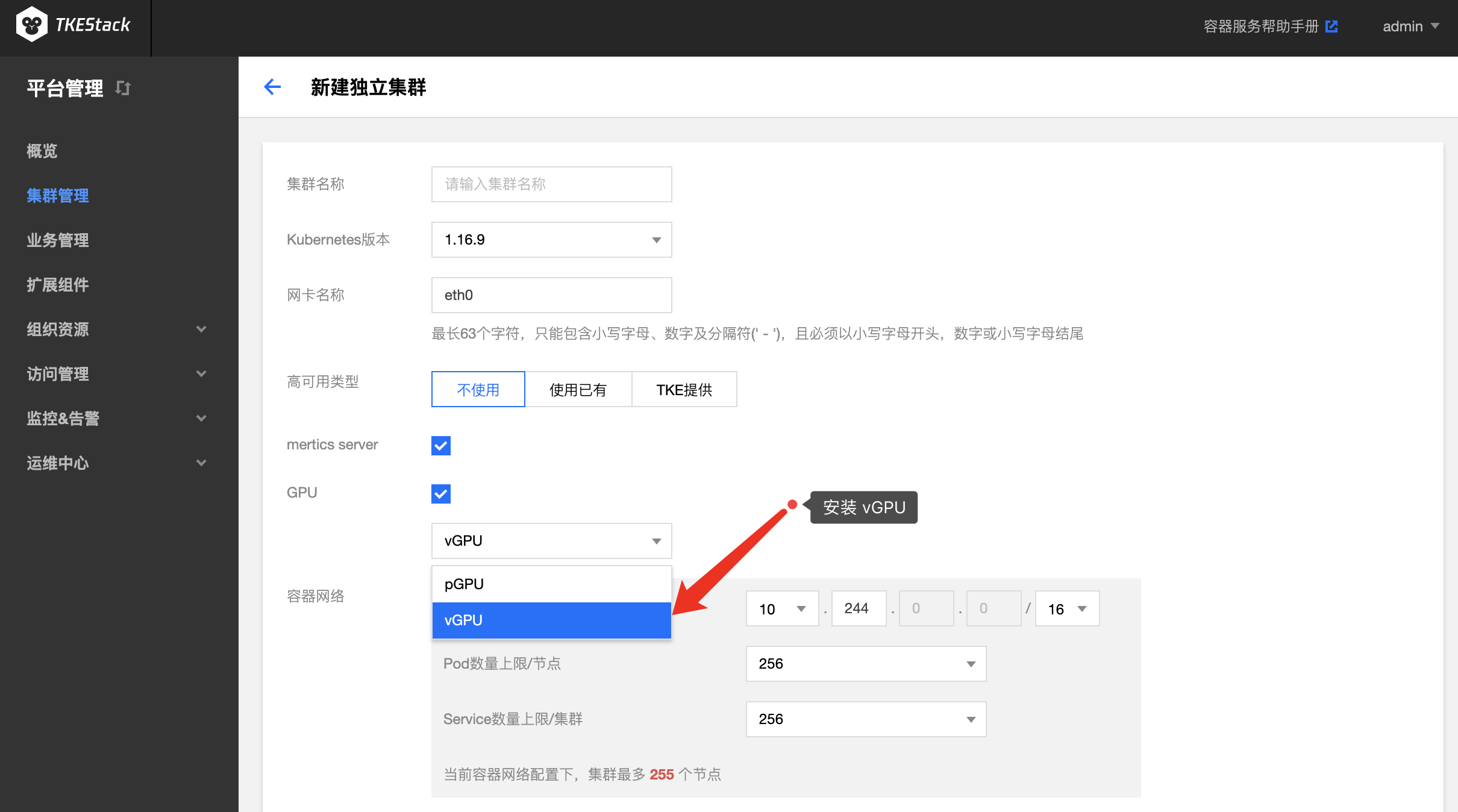
集群部署阶段选择 vGPU,平台会为集群部署 GPU-Manager ,如下图新建独立集群所示,Global 集群的也是如此安装。
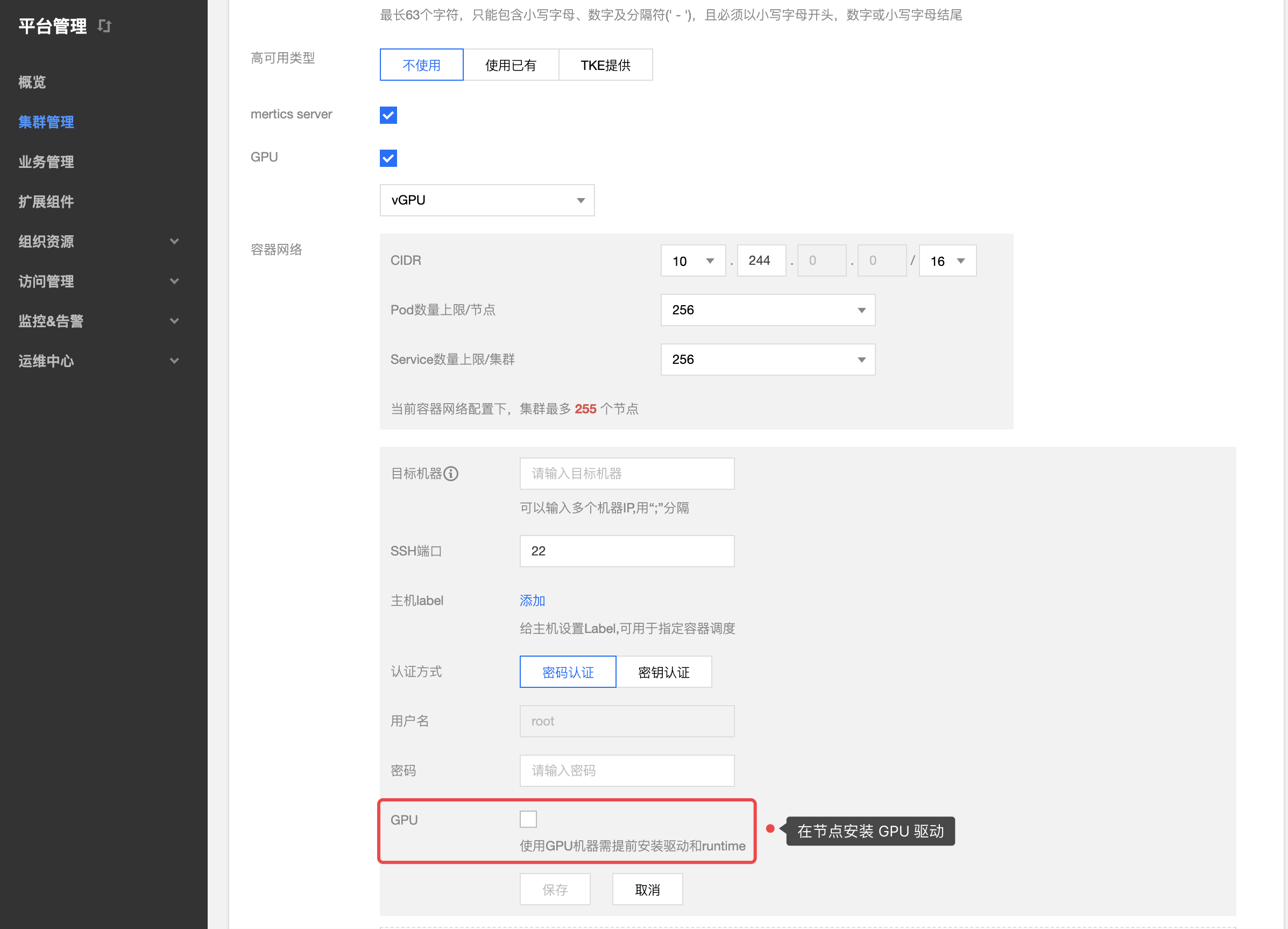
集群部署阶段添加 GPU 节点时有勾选 GPU 选项,平台会自动为节点安装 GPU 驱动,如下图所示:
注意:如果集群部署阶段节点没有勾选 GPU,需要自行在有 GPU 的节点上安装 GPU 驱动
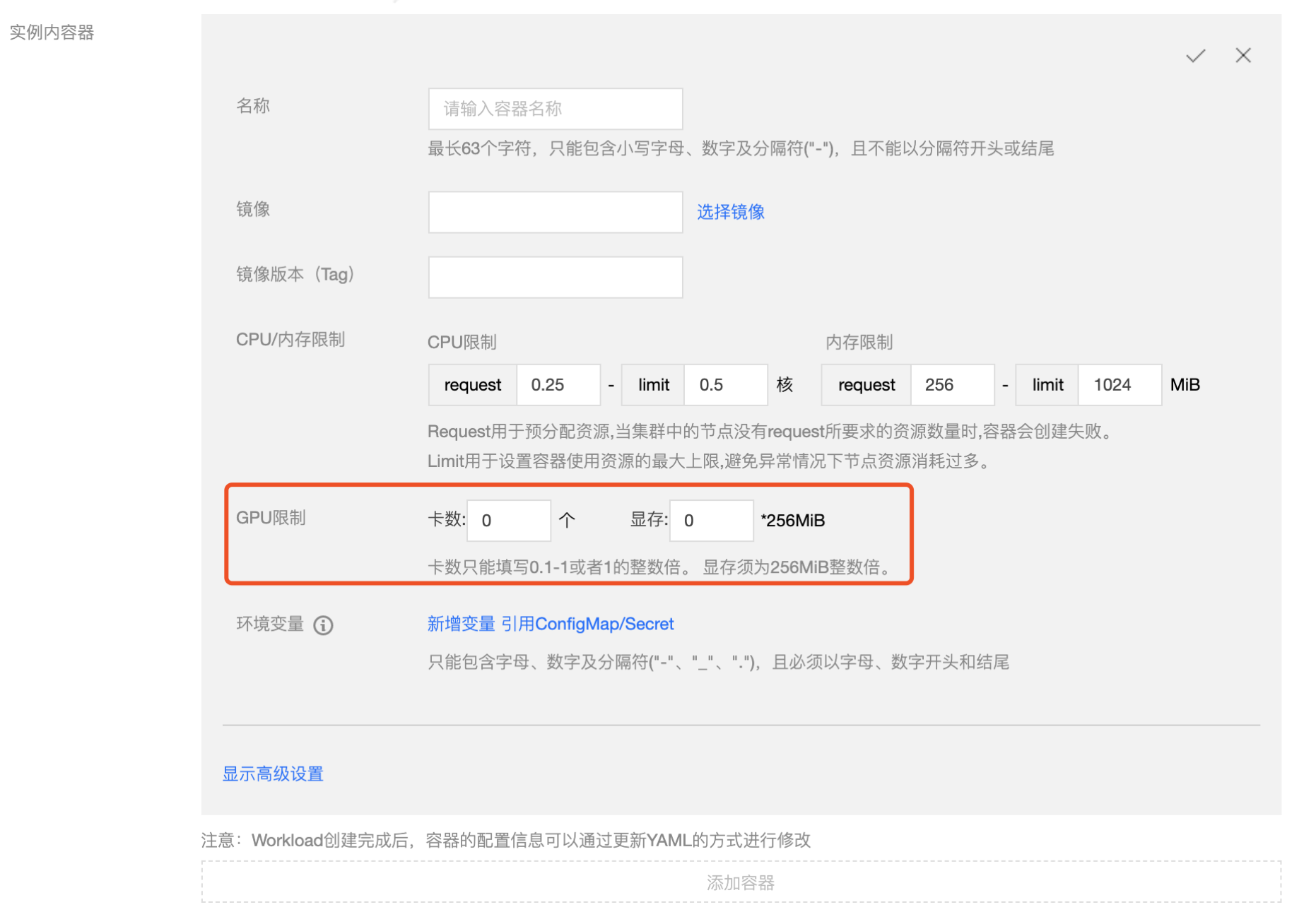
在安装了 GPU-Manager 的集群中,创建工作负载时可以设置 GPU 限制,如下图所示:
注意:
- 卡数只能填写 0.1 到 1 之间的两位小数或者是所有自然数,例如:0、0.3、0.56、0.7、0.9、1、6、34,不支持 1.5、2.7、3.54
- 显存只能填写自然数 n,负载使用的显存为 n*256MiB
如果使用 YAML 创建使用 GPU 的工作负载,提交的时候需要在 YAML 为容器设置 GPU 的使用资源。
tencent.com/vcuda-coretencent.com/vcuda-memory例1:使用1张卡的 Pod
apiVersion: v1
kind: Pod
...
spec:
containers:
- name: gpu
resources:
limits:
tencent.com/vcuda-core: 100
requests:
tencent.com/vcuda-core: 100
例2,使用 0.3 张卡、5GiB 显存的应用(5GiB = 20*256MB)
apiVersion: v1
kind: Pod
...
spec:
containers:
- name: gpu
resources:
limits:
tencent.com/vcuda-core: 30
tencent.com/vcuda-memory: 20
requests:
tencent.com/vcuda-core: 30
tencent.com/vcuda-memory: 20
前提:在集群的【基本信息】页里打开“监控告警”
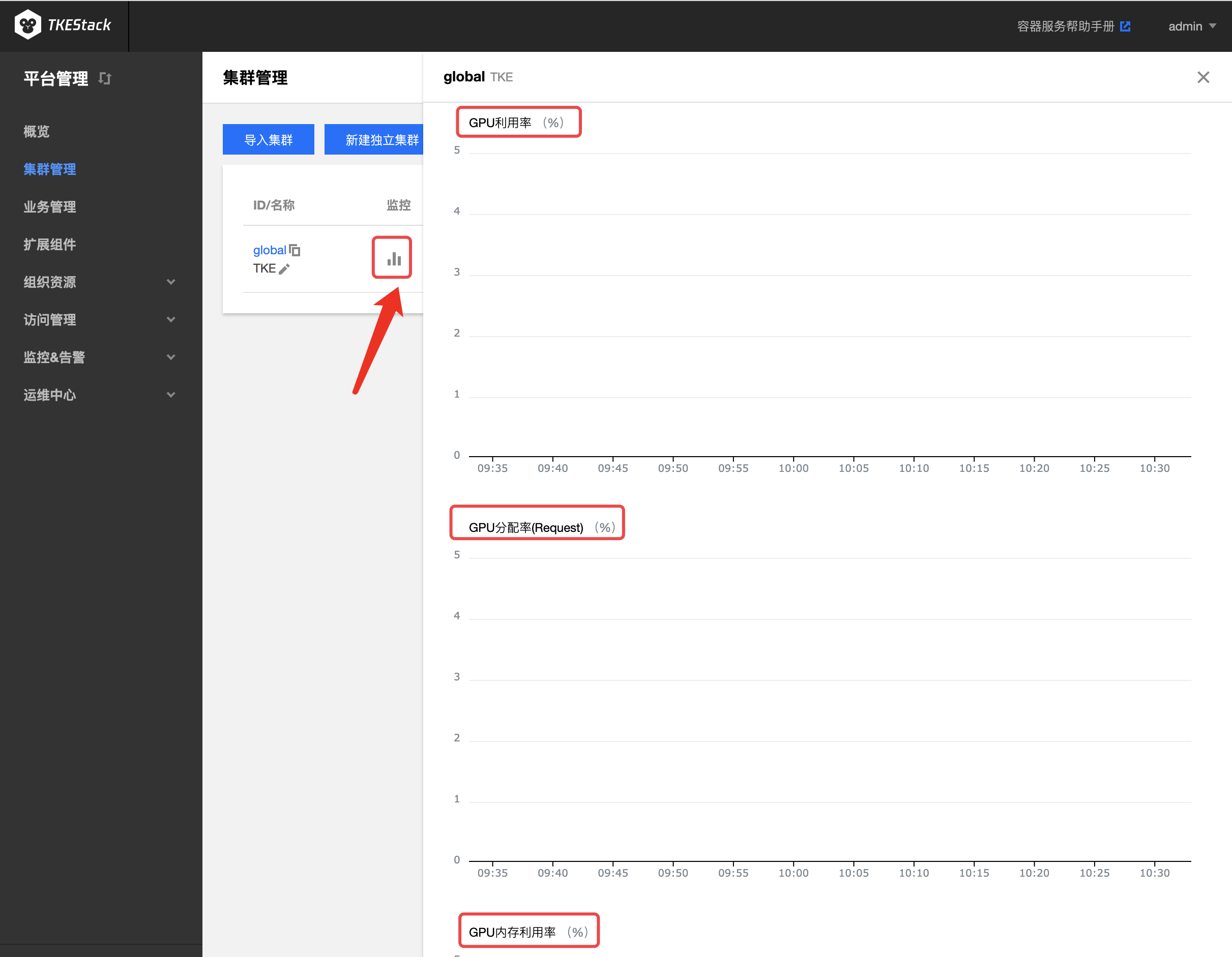
可以通过集群多个页面的监控按钮里查看到 GPU 的相关监控数据,下图以 集群管理 页对集群的监控为例:
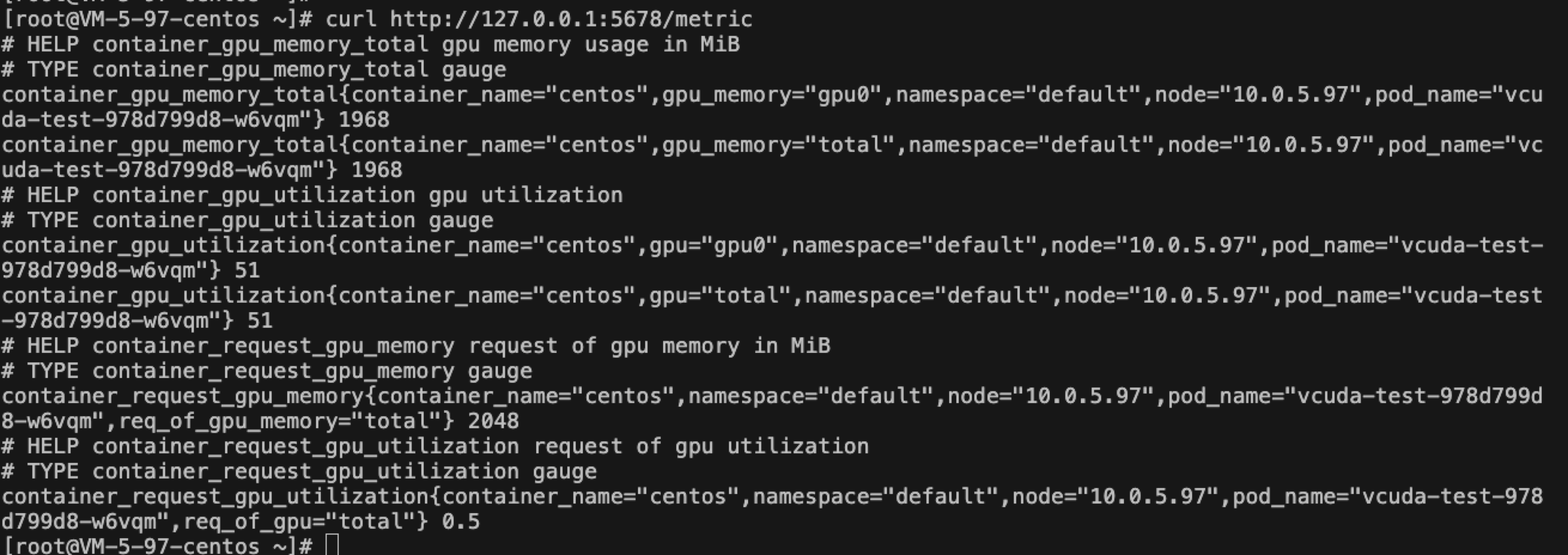
手动获取 GPU 监控数据方式(需要先安装 socat):
kubectl port-forward svc/gpu-manager-metric -n kube-system 5678:5678 &
curl http://127.0.0.1:5678/metric
结果示例:
GPUManager 项目请参考:GPUManager Repository
Container Storage Interface Operator(CSIOperator)用于部署和更新 Kubernetes 集群中的 CSI 驱动和外部存储组件。
CSIOperator 用于支持集群方便的使用存储资源,当前支持的存储插件包括 RBD、CephFS、TencentCBS 和 TencentCFS(TencentCFS 正在测试中)
在集群内部署 CSIOperator,将在集群内部署以下 kubernetes 对象
| kubernetes 对象名称 | 类型 | 默认占用资源 | 所属 Namespaces |
|---|---|---|---|
| csi-operator | Deployment | 每节点0.2核 CPU, 256MB内存 | kube-system |
文件中指定各自存储插件镜像的名称,这里以tencentcbs的 YAML 为例:(前提:需要拥有腾讯云账号)
apiVersion: storage.tkestack.io/v1
kind: CSI
metadata:
name: tencentcbsv1
namespace: kube-system
spec:
driverName: com.tencent.cloud.csi.cbs
version: "v1"
parameters:
secretID: "xxxxxx"
secretKey: "xxxxxx"
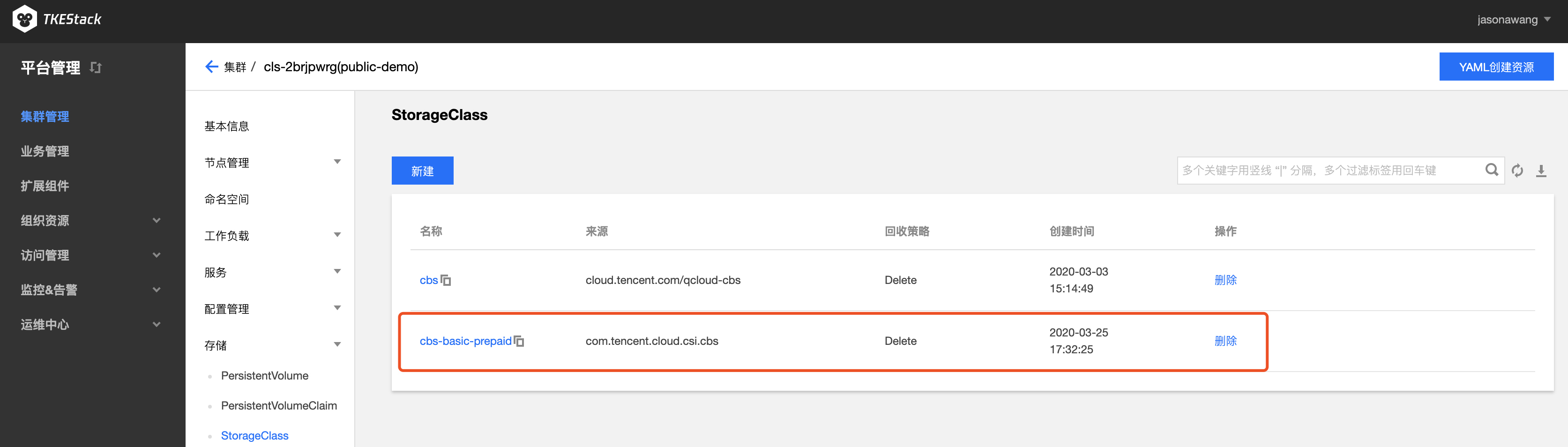
创建完 CSIOperator 的 CRD 对象,同时会为每个存储插件创建默认的 StorageClass 对象(tencentcbs 的 StorageClass 对象名为 cbs-basic-prepaid),如下图:
其 YAML 如下:
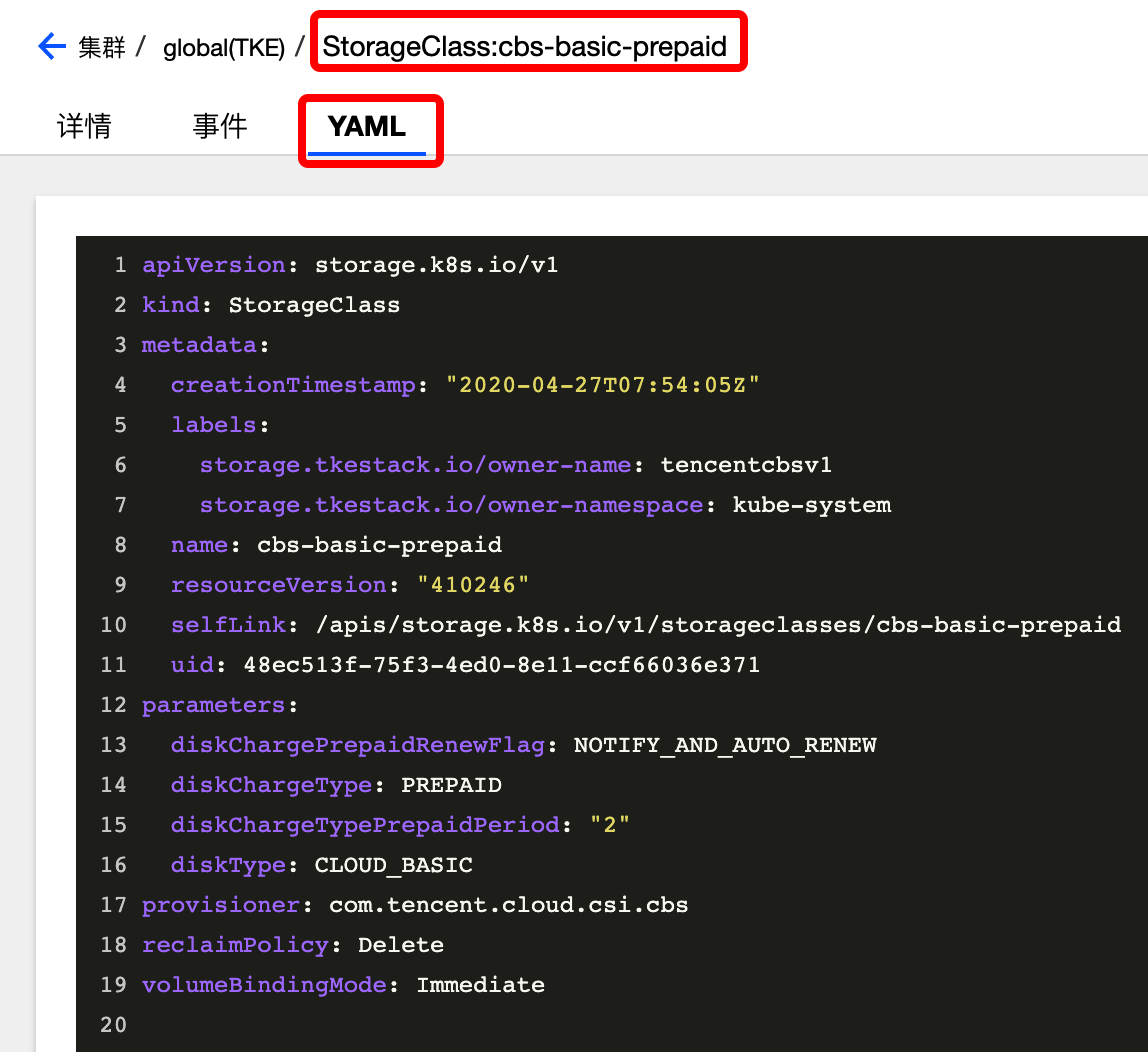
tencentcbs 的 provisioner 名称指定为:com.tencent.cloud.csi.cbs
tencentcfs 的 provisioner 名称指定为:com.tencent.cloud.csi.cfs,tencentcfs 仍在测试中,目前仅支持 tencentcbs
对于磁盘类型(在 StorageClass 的 diskType 中指定)和大小的限制:
CLOUD_BASIC )盘提供最小 100 GB 到最大 16000 GB 的规格选择,支持 40-100MB/s 的 IO 吞吐性能和 数百-1000 的随机 IOPS 性能CLOUD_PREMIUM)提供最小 50 GB 到最大 16000 GB 的规格选择CLOUD_SSD)提供最小 100 GB 到最大 16000 GB 的规格选择,单块 SSD 云硬盘最高可提供 24000 随机读写IOPS、260MB/s吞吐量的存储性能默认创建的磁盘类型为普通云硬盘,如果用户希望使用该 StorageClass,可以直接创建使用了该 StorageClass 的 PVC 对象:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: test-tencentcbs
namespace: kube-system
spec:
accessModes:
- ReadWriteOnce
storageClassName: cbs-basic-prepaid
resources:
requests:
storage: 10Gi
详情请见 CSIOperator Example